当前位置:网站首页>Mapreduce实例(七):单表join
Mapreduce实例(七):单表join
2022-07-06 09:01:00 【笑看风云路】
大家好,我是风云,欢迎大家关注我的博客 或者 微信公众号【笑看风云路】,在未来的日子里我们一起来学习大数据相关的技术,一起努力奋斗,遇见更好的自己!
知识回顾
区分笛卡儿积,自然连接,等值连接,内连接,外连接 <= 回顾下数据库基础知识
实现思路
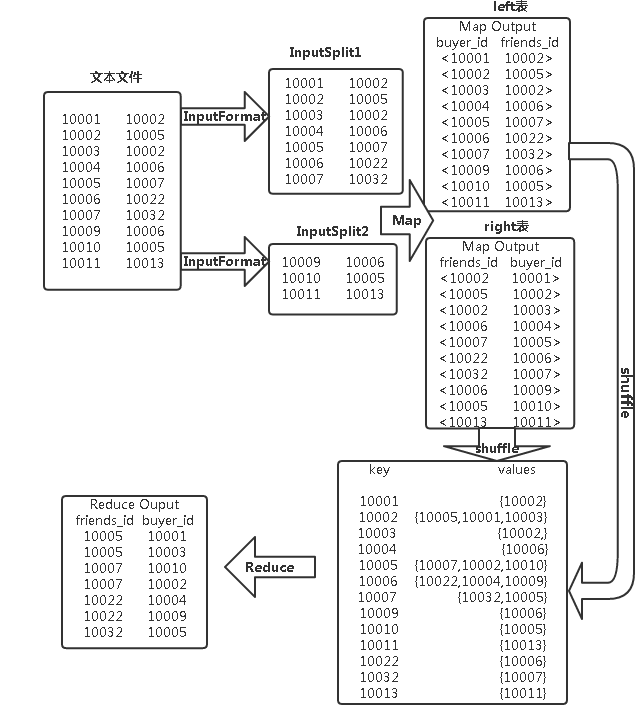
以本实验的buyer1(buyer_id,friends_id)表为例来阐述单表连接的实验原理。单表连接,连接的是左表的buyer_id列和右表的friends_id列,且左表和右表是同一个表。
因此,在map阶段将读入数据分割成buyer_id和friends_id之后,会将buyer_id设置成key,friends_id设置成value,直接输出并将其作为左表;再将同一对buyer_id和friends_id中的friends_id设置成key,buyer_id设置成value进行输出,作为右表。
为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表。这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。
reduce接收到连接的结果,其中每个key的value-list就包含了"buyer_idfriends_id–friends_idbuyer_id"关系。取出每个key的value-list进行解析,将左表中的buyer_id放入一个数组,右表中的friends_id放入一个数组,然后对两个数组求笛卡尔积就是最后的结果了。
代码编写
Map代码
public static class Map extends Mapper<Object,Text,Text,Text>{
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line = value.toString();
String[] arr = line.split("\t"); //按行截取
String mapkey=arr[0];
String mapvalue=arr[1];
String relationtype=new String(); //左右表标识
relationtype="1"; //输出左表
context.write(new Text(mapkey),new Text(relationtype+"+"+mapvalue));
//System.out.println(relationtype+"+"+mapvalue);
relationtype="2"; //输出右表
context.write(new Text(mapvalue),new Text(relationtype+"+"+mapkey));
//System.out.println(relationtype+"+"+mapvalue);
}
}
Map处理的是一个纯文本文件,Mapper处理的数据是由InputFormat将数据集切分成小的数据集InputSplit,并用RecordReader解析成<key/value>对提供给map函数使用。map函数中用split(“\t”)方法把每行数据进行截取,并把数据存入到数组arr[],把arr[0]赋值给mapkey,arr[1]赋值给mapvalue。用两个context的write()方法把数据输出两份,再通过标识符relationtype为1或2对两份输出数据的value打标记。
Reduce代码
public static class Reduce extends Reducer<Text, Text, Text, Text>{
//实现reduce函数
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
int buyernum=0;
String[] buyer=new String[20];
int friendsnum=0;
String[] friends=new String[20];
Iterator ite=values.iterator();
while(ite.hasNext()){
String record=ite.next().toString();
int len=record.length();
int i=2;
if(0==len){
continue;
}
//取得左右表标识
char relationtype=record.charAt(0);
//取出record,放入buyer
if('1'==relationtype){
buyer [buyernum]=record.substring(i);
buyernum++;
}
//取出record,放入friends
if('2'==relationtype){
friends[friendsnum]=record.substring(i);
friendsnum++;
}
}
//buyernum和friendsnum数组求笛卡尔积
if(0!=buyernum&&0!=friendsnum){
for(int m=0;m<buyernum;m++){
for(int n=0;n<friendsnum;n++){
if(buyer[m]!=friends[n]){
//输出结果
context.write(new Text(buyer[m]),new Text(friends[n]));
}
}
}
}
}
}
reduce端在接收map端传来的数据时已经把相同key的所有value都放到一个Iterator容器中values。reduce函数中,首先新建两数组buyer[]和friends[]用来存放map端的两份输出数据。然后Iterator迭代中hasNext()和Next()方法加while循环遍历输出values的值并赋值给record,用charAt(0)方法获取record第一个字符赋值给relationtype,用if判断如果relationtype为1则把用substring(2)方法从下标为2开始截取record将其存放到buyer[]中,如果relationtype为2时将截取的数据放到frindes[]数组中。然后用两个for循环嵌套遍历输出<key,value>,其中key=buyer[m],value=friends[n]。
完整代码
package mapreduce;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DanJoin {
public static class Map extends Mapper<Object,Text,Text,Text>{
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line = value.toString();
String[] arr = line.split("\t");
String mapkey=arr[0];
String mapvalue=arr[1];
String relationtype=new String();
relationtype="1";
context.write(new Text(mapkey),new Text(relationtype+"+"+mapvalue));
//System.out.println(relationtype+"+"+mapvalue);
relationtype="2";
context.write(new Text(mapvalue),new Text(relationtype+"+"+mapkey));
//System.out.println(relationtype+"+"+mapvalue);
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
int buyernum=0;
String[] buyer=new String[20];
int friendsnum=0;
String[] friends=new String[20];
Iterator ite=values.iterator();
while(ite.hasNext()){
String record=ite.next().toString();
int len=record.length();
int i=2;
if(0==len){
continue;
}
char relationtype=record.charAt(0);
if('1'==relationtype){
buyer [buyernum]=record.substring(i);
buyernum++;
}
if('2'==relationtype){
friends[friendsnum]=record.substring(i);
friendsnum++;
}
}
if(0!=buyernum&&0!=friendsnum){
for(int m=0;m<buyernum;m++){
for(int n=0;n<friendsnum;n++){
if(buyer[m]!=friends[n]){
context.write(new Text(buyer[m]),new Text(friends[n]));
}
}
}
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
String[] otherArgs=new String[2];
otherArgs[0]="hdfs://localhost:9000/mymapreduce7/in/buyer1";
otherArgs[1]="hdfs://localhost:9000/mymapreduce7/out";
Job job=new Job(conf," Table join");
job.setJarByClass(DanJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
-------------- end ----------------
微信公众号:扫描下方二维码或 搜索 笑看风云路 关注
边栏推荐
- 基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)
- LeetCode41——First Missing Positive——hashing in place & swap
- Le modèle sentinelle de redis
- Advanced Computer Network Review(5)——COPE
- Booking of tourism products in Gansu quadrupled: "green horse" became popular, and one room of B & B around Gansu museum was hard to find
- 基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
- postman之参数化详解
- Basic usage of xargs command
- Redis之主从复制
- QML type: overlay
猜你喜欢

Post training quantification of bminf

Digital people anchor 618 sign language with goods, convenient for 27.8 million people with hearing impairment

In depth analysis and encapsulation call of requests

Redis之连接redis服务命令
Blue Bridge Cup_ Single chip microcomputer_ PWM output
【图的三大存储方式】只会用邻接矩阵就out了

Pytest's collection use case rules and running specified use cases
Selenium+pytest automated test framework practice
![[OC foundation framework] - [set array]](/img/b5/5e49ab9d026c60816f90f0c47b2ad8.png)
[OC foundation framework] - [set array]
Advanced Computer Network Review(3)——BBR
随机推荐
[OC foundation framework] - [set array]
数据建模有哪些模型
Withdrawal of wechat applet (enterprise payment to change)
Seven layer network architecture
Advanced Computer Network Review(3)——BBR
Redis cluster
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth
Reids之删除策略
Global and Chinese markets for small seed seeders 2022-2028: Research Report on technology, participants, trends, market size and share
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
Pytest之收集用例规则与运行指定用例
英雄联盟轮播图手动轮播
Mise en œuvre de la quantification post - formation du bminf
Kratos战神微服务框架(三)
Redis' performance indicators and monitoring methods
[shell script] use menu commands to build scripts for creating folders in the cluster
CUDA implementation of self defined convolution attention operator
Selenium+Pytest自动化测试框架实战
Kratos ares microservice framework (II)