当前位置:网站首页>推荐收藏:跨云数据仓库(data warehouse)环境搭建,这货特别干!
推荐收藏:跨云数据仓库(data warehouse)环境搭建,这货特别干!
2022-07-04 22:45:00 【Wu_Candy】
目录结构
- 背景
- 方案
- 部署结构 1.测试环境部署结构 2.Canal服务部署结构
- 相关服务 1.平台 2.代码工程 3.部署机器 4.搭建服务
- 搭建步骤 1.机器资源准备 2.发布代码工程 3.安装依赖 4.配置调度任务 5.业务Mysql库配置 6.Canal配置 7.Mysql增量表配置
- K8s服务命令
- 搭建过程问题汇总
背景
数据测试环境只有一套,平时只用于日常的数据需求测试,无法满足用户 UAT 要求,因此需要重新搭建一套数据测试系统,作为用户的 UAT 环境。
方案
业务服务在腾讯云,在腾讯云机器上部署数据收集服务并将获取的业务数据打包上传至 sftp 供阿里云上的数据仓库服务经过 ETL 过程存储至 hive 库。
业务数据存储至 hive 库分为2个部分:
- 初始化数据:业务 mysql 库全量业务数据本地读取打包上传至 sftp
- 增量数据:canal 监听业务 mysql 的 binlog 进行增量数据同步、打包和上传至 sftp
部署结构
测试环境部署结构:
Canal服务部署结构:
- 整个框架结构是使用本地搭建的 RocketMQ 集群
- 数据同步是基于 canal.adapter 搭建,替代阿里云上的数据传输服务(DTS)功能
- 数据订阅使用搭建的 canal.admin 服务平台来进行管理
相关服务
1.平台
- canal.admin管理平台:创建 instance
- xxl-config配置平台:配置监听 instance
- xxl-job任务调度平台:增量数据同步任务执行与异常处理
- k8s发布平台:数据同步工程拉取 xxl-config 配置发布
- jenkins发布平台:发布除数据同步工程之外的工程
- etl任务调度平台:用于配置 etl 调度任务,自动执行入 hive 库
2.代码工程
- 调度server工程:data-platform-schedule
- 调度client工程:data-platform-schedule-client
- etl执行集成工具类工程:data-platform-etljet
- etl数据加工入hdfs工程:data-platform-etl
- 数据同步工程:data_sync_incr
3.部署机器
- 调度server与etl机器:l-test.beta4.dt.cn4
- 业务机器:l-test.beta4.ep.tx1
- k8s机器:l-test-k8s.ep.tx1
- canal.admin服务机器:l-test1.beta.plat.tp1
- canal.deploy/adapter服务机器:l-test2.beta.plat.tp2
4.搭建服务
新搭建一套 sftp 服务,用于跨云数据的中转传输
搭建步骤
1.机器资源准备
向运维部门申请新的数据仓库机器:
l-test.beta4.dt.cn4
与现有的 beta 环境数据仓库机器使用同一套 hadoop 集群资源,hdfs 存储路径新增 /user/test/hive/warehouse_uat 隔离环境数据
注释:
- k8s机器:l-test-k8s.ep.tx1,已存在且 data-sync-incr 服务正常运行
- canal.admin服务机器:l-test1.beta.plat.tp1,已存在且canal.admin服务正常运行
- canal.deploy/adapter服务机器:l-test2.beta.plat.tp2,已存在且canal.deploy和canal.adapter服务正常运行
2.发布代码工程
数据仓库机器:l-test.beta4.dt.cn4 部署以下服务 1.调度server工程:data-platform-schedule 2.调度client工程:data-platform-schedule-client 注意需要使用 hive 用户来启动 schedule-client 执行命令: /home/test/www/schedule/schedule-client task_loader_and_timeout_serviced start 3.etl执行集成工具类工程:data-platform-etljet 创建目录: /home/test/www/data-platform-etljet
在机器下开启 hive 用户的 crontab,crontab 需要先配置一个定时任务 例如: 0 3 30 * * echo "helloworld"
业务机器:l-test.beta4.ep.tx1 部署以下服务 1.调度client工程:data-platform-schedule-client (1).部署服务前,需创建目录: /home/test/www/schedule/schedule-client (2).配置环境变量: 在/etc/profile 文件中的path路径加入:/usr/local/bin/ 并追加以下内容
(3).注意需要使用 hive 用户来启动 schedule-client 执行命令: /home/test/www/schedule/schedule-client task_loader_and_timeout_serviced start
3.etl数据加工入 hdfs 工程:data-platform-etl 创建目录: /home/test/www/data-platform-etl/etl_task
k8s机器:l-test-k8s.ep.tx1 部署以下服务 数据同步工程:data_sync_incr namespace:dc-beta2 evn: betanew 对应的是业务系统 beta4 环境的增量数据
canal.admin服务机器:l-test1.beta.plat.tp1 部署以下服务 canal.admin
canal.deploy/adapter服务机器:l-test2.beta.plat.tp2 部署以下服务 canal.deploy canal.admin
3.安装依赖
(1).安装 python 因为 data-platform-schedule-client 工程是使用 python 起的进程,所以需要安装python,此处省略 python 安装方法与过程。
(2).安装 mysql 包 使用工具:
wget -q http://peak.telecommunity.com/dist/ez_setup.py
python ez_setup.py
easy_install mysql-connector
import mysql.connector
注意权限: python -m site 可找到包的安装地址,修改权限使 hive 用户可以访问
(3).安装 sftp 服务 因为跨云的架构,所以需要安装 sftp 服务用于数据中转传输,此处我是在数据仓库机器:l-test.beta4.dt.cn4 上安装的 sftp 服务,也可在其他机器上安装,注意关联调用服务机器之间的访问权限问题。
开通业务服务机器:l-test.beta4.ep.tx1 与 sftp 机器之间的通信(关闭防火墙限制) 开通数据仓库机器:l-test.beta4.dt.cn4 与 sftp 机器之间的通信(关闭防火墙限制)
4.配置调度任务
配置调度任务:http://l-test.beta4.dt.cn4:8088/project/queryList 页面展示如下
5.业务 Mysql 库配置
(1).新增 Mysql 的 binlog 消息订阅 开启业务数据库机器:l-test.beta4.ep.tx1 的 binlog日志,且是 row 格式。 开启完成使用sql语句:
show variables like '%log_bin%';
查看 binlog 状态应为 ON
(2).Mysql 创建同步账号 首先需要在数据库创建同步账号,执行如下命令创建同步账号:
CREATE USER canal IDENTIFIED BY '[email protected]';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
6.Canal 配置
(1).canal.admin 配置监听 在 canal.admin 服务下的 http://10.7.80.80:8000/#/canalServer/canalInstances 新增监听的 instance 为:test-beta-tcp。
该 instance 所属集群和 server 均为:test-dev-tcp,需提前创建好,创建 instance时直接选择对应的集群和 server 即可。
配置的 instance.properties 信息如下:
instance name很重要,就是客户端拉取消息的目标,可以理解为 MQ 里面的主题。
beta 环境的 instance name 的格式为:环境类型_环境编号_数据库名_应用
例如:test_test4_db4_adapter, 表示 test 的 test4 的 db4 提供给 adapter 应用消费的消息。
应用目前取值有 adapter 和 sync。adapter 为一对一抽取的应用 canal.adapter。
sync 为通过监听 binlog 消息通过代码方式实现的个性化的同步逻辑,也是本次数据仓库搭建主要使用的数据同步方式。
新增的 instance 保存成功后选择该 instance 右侧的启动按钮,启动订阅。
启动成功后变成启动状态,然后可以在 mqadmin 查看下是否有消息投递到队列里面。 可以点击日志按钮查询启动日志是否正常。
(2).canal.adapter 修改 编辑配置文件/home/test/q/canal/canal.adapter/conf/application.yaml
server:
port: 8010
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: rocketMQ
mqServers: beta-mqns1:5432;beta-mqns2:5433
flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 10
timeout: 5000
accessKey:
secretKey:
namespace:
srcDataSources:
beta-test:
url: jdbc:mysql://l-test.beta4.ep.tx1:3306/?useUnicode=true
username: ****
password: ****
(3).重启client.adapter 默认会自动扫描新增的配置文件,但如果没有生效可以手动重启下。 必须以 tomcat 用户重启 client.adapter。
启动命令如下:
sudo su tomcat
cd /home/test/q/canal/canal.adapter/bin
./restart.sh
日志文件在/home/test/q/canal/canal.adapter/logs下,可以查看启动日志。
7.Mysql增量表配置
初始化增量表 & 配置任务
(1).确定增量表业务类型 现有组件只支持两种类型:
- test-story 类型,监听 test_main 表的 binLog 信息,然后通过 binLog 信息反查 test_detail 表,获取全量数据,以此数据作为增量表所需数据。
- 常规表类型,监听例如:person、person_individual 等表信息,直接以 binLog 信息中的数据为增量表所需数据,无需反查。
(2).配置增量表业务 在项目增量表数据库中,增加增量表业务配置,用于创建业务增量表使用。 例如:
INSERT INTO `dt_sync`.`init_table_config`( `table_name`, `delete_flag`, `create_time`, `update_time`) VALUES ( 'beta4_teachers_detail_inc_', 0, '2021-11-10 16:02:33', '2021-11-10 16:02:38');
主要配置 table_name、delete_flag 属性,table_name 即本次新增的增量表名称,delete_flag 表示本条记录是否生效,0——生效,1——不生效
(3).配置增量表执行策略 增量同步过程中,我们需要对同步的执行策略进行配置
INSERT INTO `dt_sync`.`inc_sync_strategy_config`( `execute_strategy`, `match_rule`, `execute_rule`, `create_time`, `update_time`, `delete_flag`) VALUES ( 'detail', '{\"defaultRule\":{\"instance\":\"test-beta-tcp\",\"dataBase\":\"people\",\"table\":\"teacher\",\"opType\":\"in:INSERT,UPDATE,DELETE\"},\"additionalRule\":{\"columnName\":\"teacher_id\",\"ruleType\":\"prefix\",\"ruleContent\":\"1\"}}\n', '{\"pkColumn\":\"teacher_id\",\"pkRule\":\"PK_COLUMN\",\"monitorBizType\":\"reservation\",\"localTargetTableName\":\"beta4_teachers_detail_inc_\",\"converts\":[{\"field\":\"data\",\"type\":\"json\",\"operation\":[{\"operationName\":\"uncompress\",\"priority\":1},{\"operationName\":\"convertJson\",\"priority\":2}]}]}\n', '2021-11-07 14:24:41', '2021-12-02 16:21:53', 0);
主要关注:[1]、execute_strategy - 执行策略 目前只有(NORMAL、ENTITY_DETAIL)两者选其一
[2]、match_rule - 匹配规则
属性解释:
a、defaultRule - 默认匹配规则(必填):
instance: 业务表所属的实例(适用于表达式支持——canalServer 中配置的instance信息)
dataBase: 业务表所属的原始数据库(适用于表达式支持)
table: 业务表所属的原始数据表(适用于表达式支持)
opType: binlog监听业务表的有效操作(目前只支持INSERT, UPDATE, DELETE)(适用于表达式支持)
b、additionalRule - 额外的匹配规则(主要是data级别的,非必填)
columnName: 列名
ruleType: 规则类型(目前支持前缀 - prefix、后缀 - postfix)
ruleContent: 规则匹配文本内容
示例: 如果要添加额外如 teacher_id 需要是50开头的才能命中执行本策略配置,那么配置如下:columnName = teacher_id , ruleType = prefix , ruleContent = 50
[3]、execute_rule - 增量同步过程中的执行规则 以 t_teacher 增量业务表实例:
{
"pkColumn":"id",字段含义——原始表的唯一业务id(必填),用于增量同步业务使用
"pkRule":"TABLE_SUFFIX_COLUMN_COMBINATION",字段含义——增量表数据的id生成规则(必填)——目前只有两种方式:
方式1、PK_COLUMN——(以pkColumn列的值作为增量表的主键id,一般没有分库分表的业务建议使用这种方式)
方式2、TABLE_SUFFIX_COLUMN_COMBINATION——(以原始表后缀 + ,一般分库分表的业务建议使用这种方式)
"localTargetTableName":"test_t_teacher_detail_inc_",字段含义——本次配置属于哪条增量业务表,与步骤二中的 table_name 配置保持一致(必填)
"monitorBizType":"t_teacher",字段含义——监控埋点的业务类型(必填)
"converts":[//字段含义: 属性转换器,对指定的属性进行一系列的转换操作(非必填){
"field":"detail",字段含义——原始表中需要操作的列名
"type":"json",字段含义——数据类型
"operation":[//字段含义——转换的操作集合(目前只有解压的操作)
"uncompress"
]
}
]
}
create_time: 字段含义——本次记录的创建时间
update_time: 字段含义——本次记录的修改时间
delete_flag: 字段含义——本条记录的逻辑删除标识,0未删除,1已删除,已删除的数据不生效
表达式支持:
in表达式——in: instanceA, instanceB
regex表达式——regex: regex:t_teacher_\d+
equal表达式——t_teacher_info
any表达式——*
[4]、配置所需数据源 如果是常规表类型则忽略此步骤 如果是非常规类型,则需要配置反查的数据源
INSERT INTO `dt_sync`.`data_source_config`( `data_source_name`, `url`, `user_name`, `password`, `delete_flag`, `connection_pool`, `create_time`, `update_time`) VALUES ( 'people', 'jdbc:mysql://l-test.beta4.ep.tx1:3306/people?characterencoding=utf-8&zerodatetimebehavior=converttonull&autoreconnect=true&generatesimpleparametermetadata=true', 'beta4', '123456', 0, 'a', '2021-10-17 15:01:25', '2021-10-17 15:01:25');
[5]、配置数据源和 instance 的映射关系 为什么需要配置? 因为在增量同步的过程中,存在多数据源问题,需要通过 instance 动态路由到对应的数据源获取数据
INSERT INTO `dt_sync`.`instance_datasource_relation_config`(`data_source_name`, `instance_name`, `create_time`, `update_time`, `delete_flag`) VALUES ( 'people', 'test-beta-tcp', '2021-10-25 15:06:01', '2021-10-17 15:37:43', 0);
K8s服务命令
查看 namespace 为:dc-beta2 下所有正在运行的实例
命令如下:
kubectl get po -n dc-beta2
查看实例 data-sync-incr-54549d7567-98pch 下的 log 信息
命令如下:
kubectl logs -f --tail=100 data-sync-incr-54549d7567-98pch -n dc-beta2
查看实例 data-sync-incr-54549d7567-98pch 的具体内容
命令如下:
kubectl exec -ti data-sync-incr-54549d7567-98pch -n dc-beta2 bash
k8s查看 pod 的 ip 地址(连接数据库会用到)
命令如下:
kubectl get pods -n 命名空间 -o wide |grep pod名称
示例:
kubectl get pods -n dc-beta2 -o wide |grep data-sync-incr-54549d7567-98pch
搭建过程问题汇总
1.问题:缺少 python 安装包:threadpool 解决方法: step1:使用命令:
python -m pip install threadpool
step2:安装成功后进入python下的客户端使用命令
import threadpool
检查是否安装成功
step3:设置 site-packages 目录下文件的访问权限,全部放开
sudo chmod 777 -R /usr/lib64/python3.6/site-packages
2.问题:找不到lftp命令 解决方法: step1:使用命令:
yum install lftp
安装,提示:Error: rpmdb open failed
step2:进入rpmdb目录,命令:
cd /var/lib/rpm
step3:清除原rpmdb文件,命令:
rm -f __db.*
step4:重建rpm数据库,命令:
rpm --rebuilddb
step5:清除所有yum的缓存,命令:
yum clean all
step6:使用命令:
yum install lftp
安装,无报错
3.问题:hive 用户写入 crontab 失败报错 报错:You (hive) are not allowed to access to (crontab) because of pam configuration
问题排查思路: step1、检查 crond 权限。
1、cat /etc/corn.deny,文件是空的。
2、ll /usr/bin/crontab,具备S权限位,正常。
step2、检查 PAM 模块。
cat /etc/pam.d/crond
文件配置正常,与其他主机上的无异常。
step3、查看系统日志
cat /var/log/secure
日志中显示有用户密码过期! 解决方法:
chage -M 99999 hive
chage -l hive
4.问题:test 业务库数据更新,数据没有进入 dt_sync 目标表 原因: uat 环境配置监听的 instance 为:test-beta-tcp,对应的 namespace 为:dc-beta2
在 namespace 为:dc-beta1 或其他 namespace 里不能同时也监听:test-beta-tcp
此处出现问题的原因是 dc-beta1 也监听了该 instance
这里的 namespace 体现在 conf 配置页面如下图右上角的可选列表中,下图中的beta2(betanew) 对应的 namespace 为:dc-beta2
在k8s部署时需要注意环境的选择,如下第二张图所示:namespace 与env 是一组参数 namespace:dc-beta1 env:beta namespace:dc-beta2 env:betanew
解决方法: 将除 namespace:dc-beta2 之外的其他监听 test-beta-tcp的 namespace 中去掉监听的这个配置,修改位置如上第一张图所示 修改完配置后,需要重新发布,使其配置修改生效。 保证1个 instance 只被1个 namespace 监听。
end
边栏推荐
- Redis introduction complete tutorial: detailed explanation of ordered collection
- Is Huatai Securities a nationally recognized securities firm? Is it safe to open an account?
- Google Earth engine (GEE) -- take modis/006/mcd19a2 as an example to batch download the daily mean, maximum, minimum, standard deviation, statistical analysis of variance and CSV download of daily AOD
- Unity vscode emmylua configuration error resolution
- Advanced area a of attack and defense world misc Masters_ good_ idea
- 为什么信息图会帮助你的SEO
- Sword finger offer 65 Add without adding, subtracting, multiplying, dividing
- Google Earth engine (GEE) - tasks upgrade enables run all to download all images in task types with one click
- 剑指 Offer 65. 不用加减乘除做加法
- How to send a reliable request before closing the page
猜你喜欢
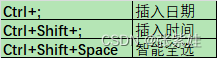
Excel 快捷键-随时补充
D3.js+Three. JS data visualization 3D Earth JS special effect
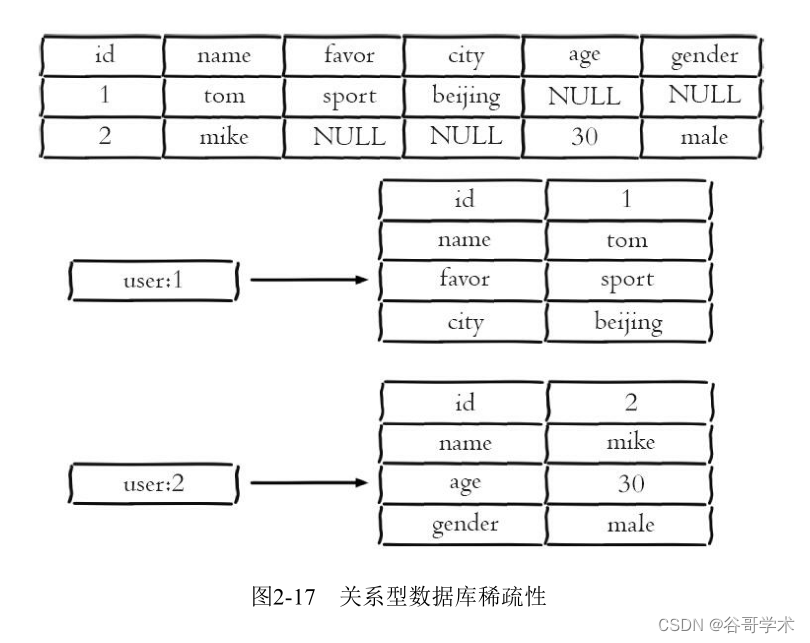
Redis getting started complete tutorial: hash description
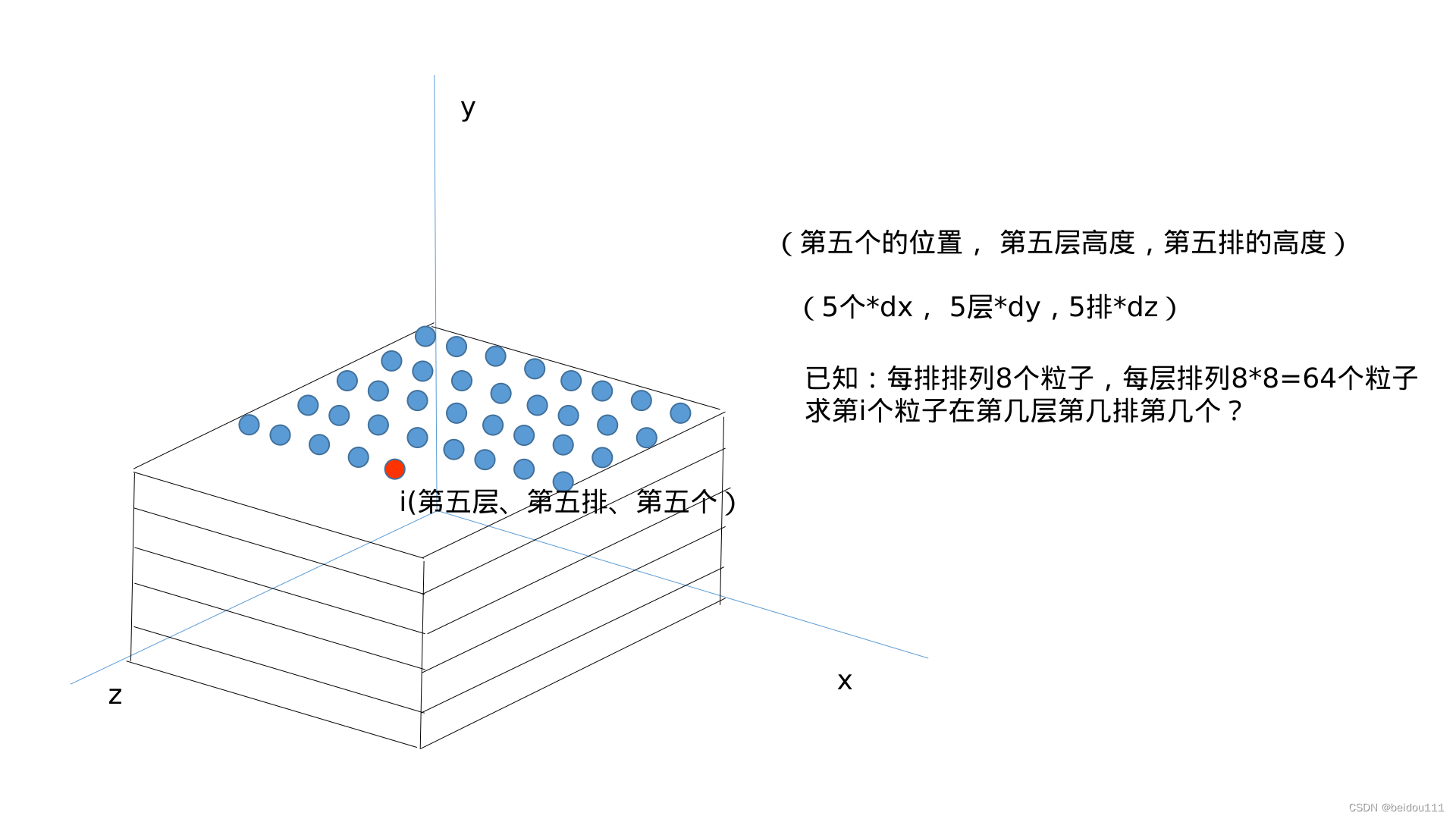
SPH中的粒子初始排列问题(两张图解决)
![[sword finger offer] questions 1-5](/img/54/b70d5290978e842939db99645c6ada.png)
[sword finger offer] questions 1-5
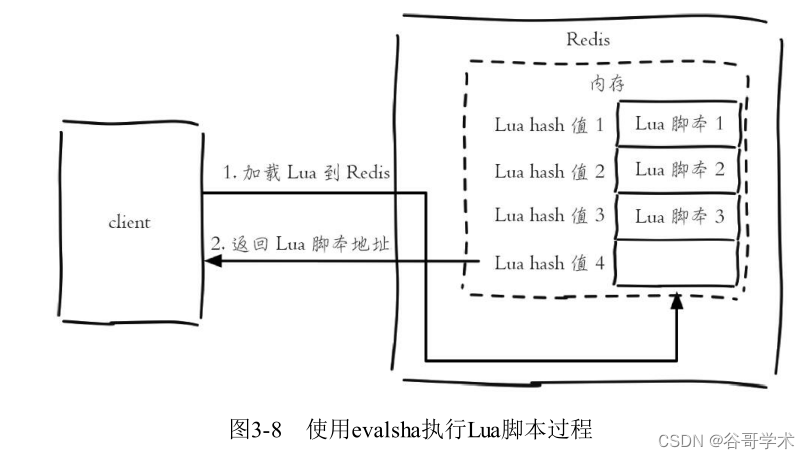
A complete tutorial for getting started with redis: transactions and Lua

攻防世界 MISC 进阶区 hong
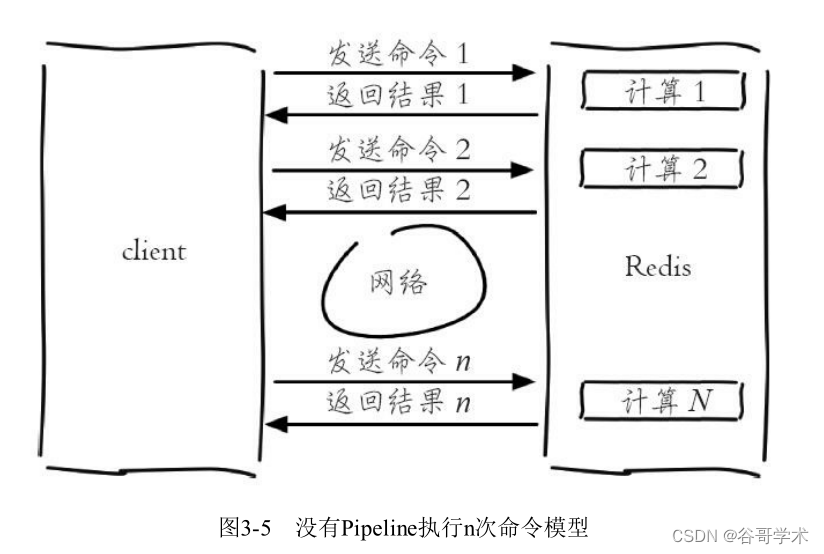
A complete tutorial for getting started with redis: Pipeline
Attack and defense world misc advanced area can_ has_ stdio?
Unity Xiuxian mobile game | Lua dynamic sliding function (specific implementation of three source codes)
随机推荐
Advanced area of attack and defense world misc 3-11
OSEK标准ISO_17356汇总介绍
攻防世界 MISC 进阶区 hit-the-core
Explanation of bitwise operators
Redis入门完整教程:发布订阅
攻防世界 MISC 进阶区 can_has_stdio?
PS style JS webpage graffiti board plug-in
Three stage operations in the attack and defense drill of the blue team
Talk about Middleware
On-off and on-off of quality system construction
MySQL Architecture - user rights and management
A complete tutorial for getting started with redis: redis usage scenarios
【剑指offer】1-5题
Feature scaling normalization
Redis入门完整教程:慢查询分析
The overview and definition of clusters can be seen at a glance
A complete tutorial for getting started with redis: Pipeline
微信小程序显示样式知识点总结
Attack and defense world misc master advanced zone 001 normal_ png
剑指 Offer 65. 不用加减乘除做加法