当前位置:网站首页>Loss function and positive and negative sample allocation: Yolo series
Loss function and positive and negative sample allocation: Yolo series
2022-07-02 15:29:00 【cartes1us】
Target detection algorithm is the most difficult to understand , The most complicated design is Positive and negative sample allocation and Loss function This one , These two will largely determine the training effect of the network , So the post is right yolo Make a summary of the series , The focus is also on these two , Absorb others' excellent blog content , To organize .

YOLO v1:
2016 CVPR There are two stars , One is resnet, The other is YOLO.
The above figure shows the network output , Notice that each grid inside predicts two Box, That is, in the paper B Set to 2, But only one group class probabilities, That is, each grid can only predict one object , Two Box To make everyone Box.
Loss in thesis :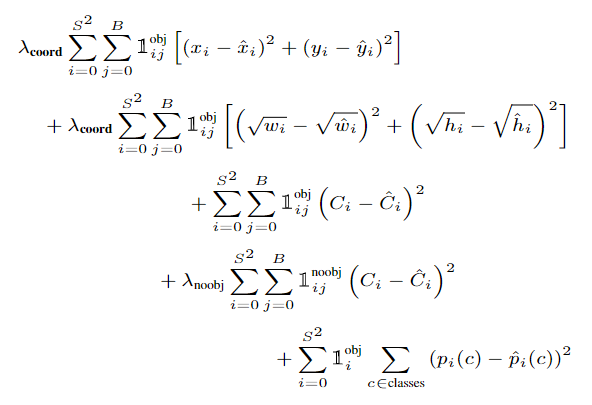
Brother Zihao of Tongji Notes :
- Positive and negative sample allocation : Some grid cell The predicted results are consistent with gt All target calculations in IoU,IoU The highest object is regarded as this grid cell The goal that should be predicted , namely yolo Each grid cell Only responsible for predicting one object , Because only 7*7 individual grid cell, therefore yolo The prediction effect of densely arranged targets is poor .
- Loss balance coefficient : λ c o o r d \lambda_{coord} λcoord It's a positive sample BBox Weight coefficient of loss , In the paper, it is set to 5. Negative samples are not calculated BBox Loss , Only calculate whether there is a target obj Loss , Its coefficient λ n o o b j \lambda_{noobj} λnoobj Set to 0.5, The loss weight of the positive sample is set to 1, Positive sample obj Loss tag C ^ i \hat{C}_i C^i No 1, It is the difference between the current prediction result and the assigned positive sample IoU, For negative samples, this item is 0.
- x,y,w,h:w,h Normalized to relative input size 0,1 Between ,x,y Is relative to this grid cell Offset of position , Also in the 0~1 Within the scope of .
- Yes w,h The reason for the root sign : We are right. BBox The evaluation index of prediction is IoU, but IoU Phase at the same time , Large framed w、h The loss obtained must be higher than the small box. The open root sign can be considered to increase sum-squared error (L2 loss) Scale invariance of .
- Classification is also used L2 Loss : According to several third-party code implementations I investigated , This p i ( c ) p_i (c) pi(c) And C i C_i Ci I haven't done softmax( I didn't see it ) or sigmoid, The last layer of the network is the linear layer , and p ^ i ( c ) \hat{p}_i (c) p^i(c) The labels of positive samples and negative samples are 1 and 0, In this way, if initialization is not good , At the beginning of training, there may be a gradient explosion , I don't know if my understanding is correct .
YOLO v2:
comparison v1, stay backbone There's an update on , Joined the BN layer , And there is one more detection head passthrough layer Short circuit of , But the final detection head is still only one , And used anchor box Mechanism , Because prediction offset is better to learn than direct prediction , Anchor frame shape And size are based on k-means Clustering results show that 5 Seed anchor frame . The title of the thesis 9000 It means that you can use the method in the text to make yolov2 Realization 9000 Detection of kinds of targets .
BN layer :
Every grid cell( grid ) Can predict at most 5 An object ,5 Represents five different anchor: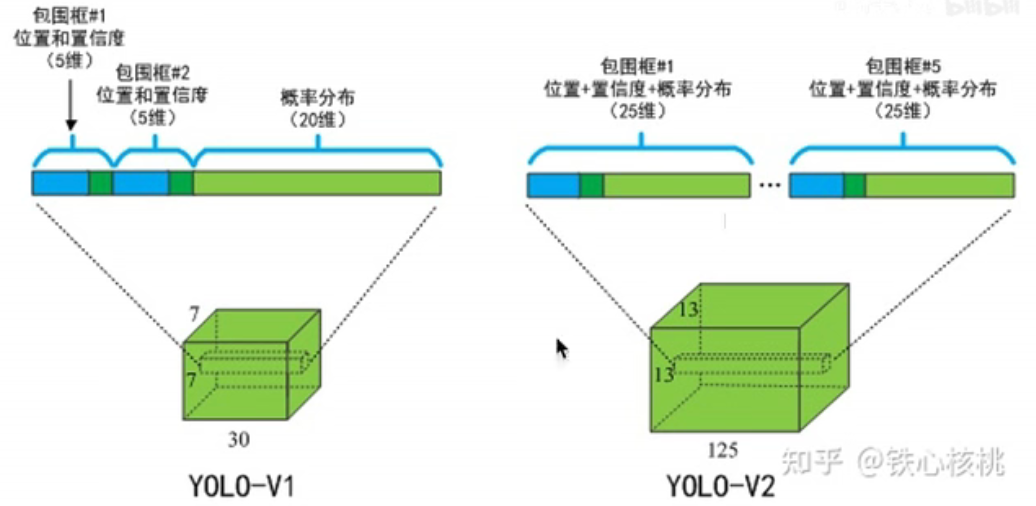
Calculation method in prediction :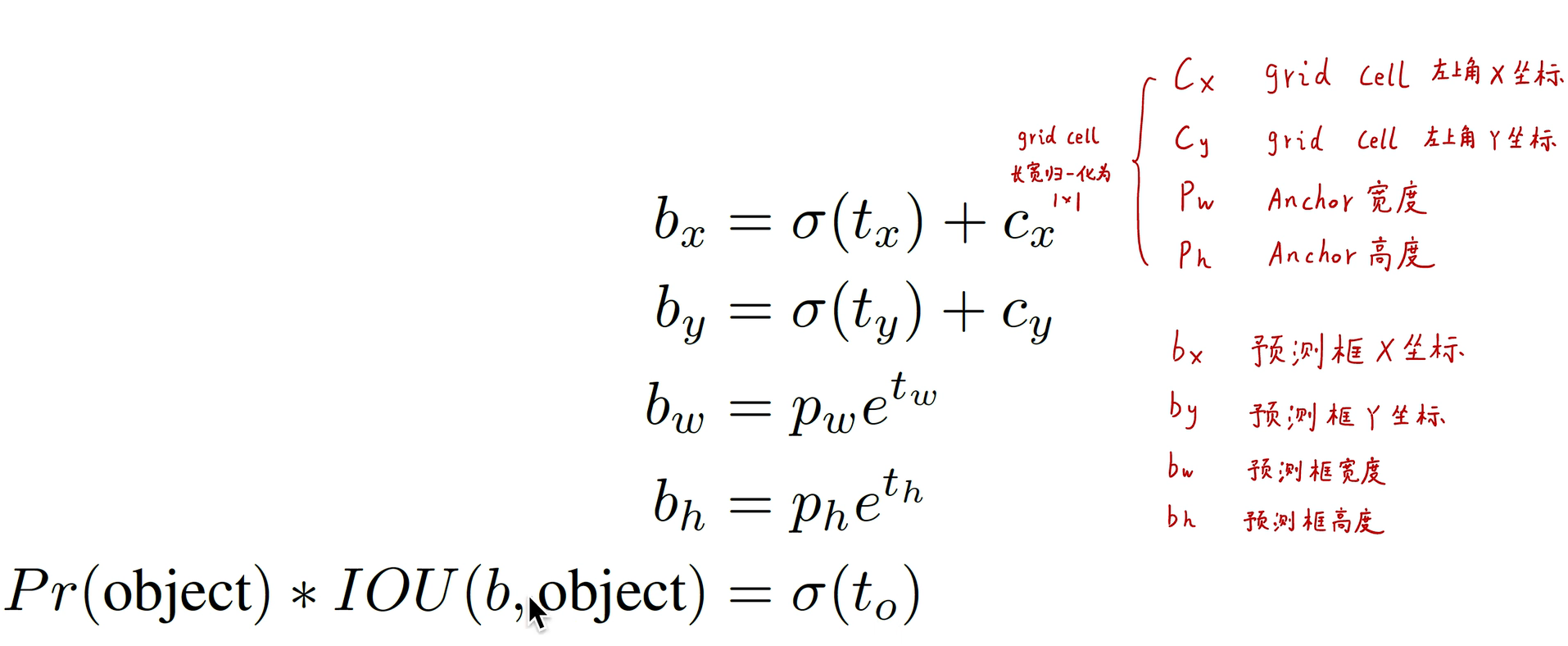
Among them sigmoid Function makes each cell The center of the prediction results of all fall in this cell in .
Loss function :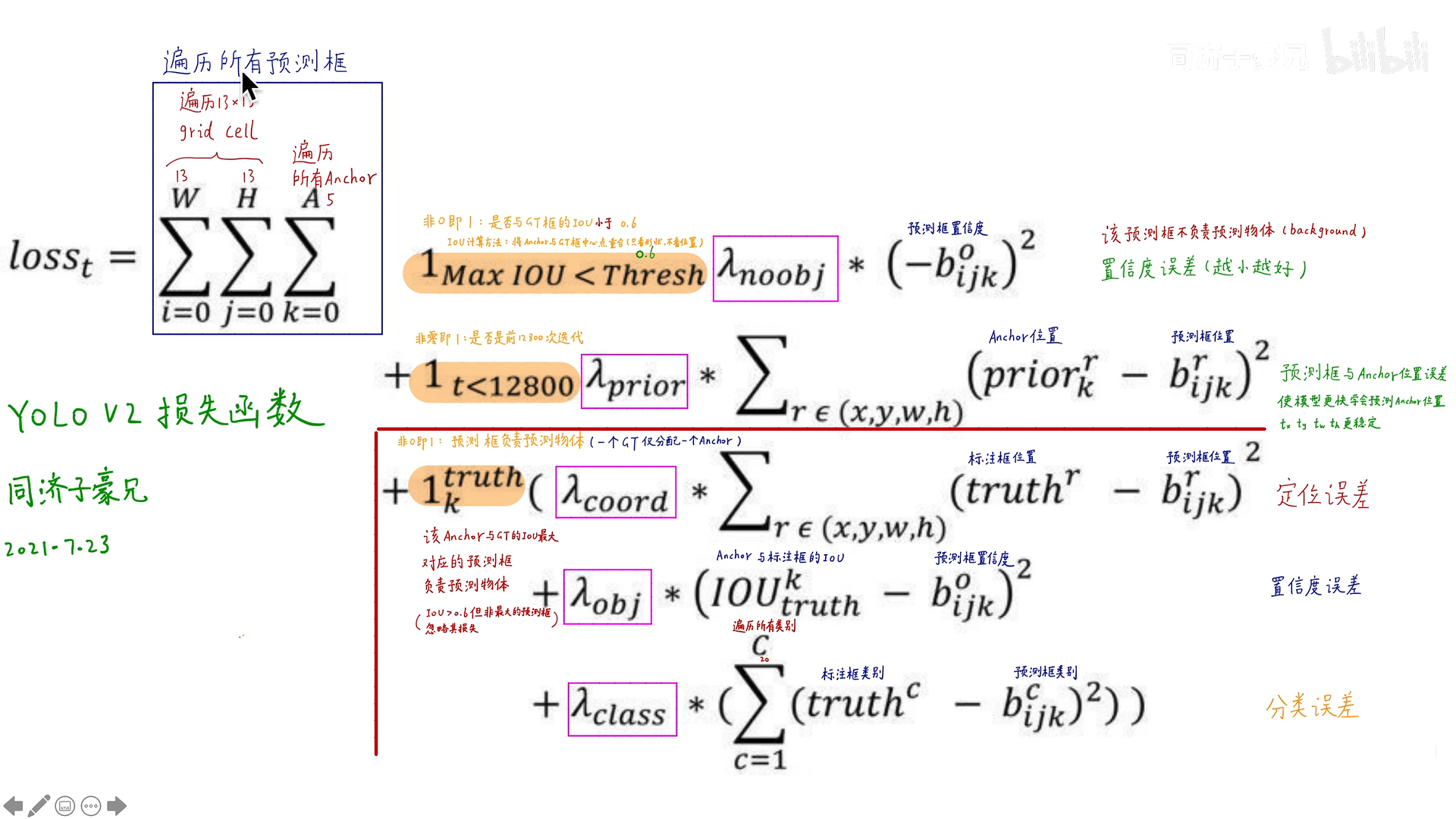
The above picture is based on yolov2 The loss function of code collation , In the formula b i j k o b_{ijk}^{o} bijko yes obj Degree of confidence , b i j k r b_{ijk}^{r} bijkr It's predicted BBox Location information , among r ∈ ( x , y , w , h ) , b i j k c r\in (x,y,w,h),b_{ijk}^{c} r∈(x,y,w,h),bijkc Is the category of the predicted box . p r i o r k r prior_{k}^{r} priorkr yes anchor The location of , Because of every cell Five of them anchor It's all the same , So the subscript only needs to know anchor Belong to these five anchor Which information of . t r u t h r truth^{r} truthr Is the location information of the callout box . t r u t h c truth^{c} truthc Is the category information of the callout box . I O U t r u t h k IOU_{truth}^{k} IOUtruthk yes anchor With the dimension box IOU.
loss It's made up of three parts , The part marked yellow is not 0 namely 1.
The first part is marked with yellow , Penalty for negative samples , Represents the prediction box and dimension box IOU If less than threshold 0.6, It is considered that the prediction box matches the negative sample , Value 1, Instead of 0, The latter part represents the label 0 And confidence b i j k o b_{ijk}^{o} bijko Of L2 Loss . This IoU The calculation of is based only on size and shape , It's not about location , That is, first put a grid cell Of anchor and gt(ground truth) The center position coincides , Calculate again IoU.
The second part is marked with yellow , It means to be in 12800 Before the next iteration , take anchor Add loss with position error of prediction frame , It can make the model learn to predict in the early stage anchor Location , Make the output t x , t y , t w , t h t^{x},t^{y},t^{w},t^{h} tx,ty,tw,th A more stable ;( My understanding of this item is not very clear )
The third part is marked with yellow , Indicates whether the prediction box is responsible for predicting objects , The anchor With the dimension box IoU The largest corresponding prediction box is responsible for predicting objects (IOU>0.6 But the non maximum prediction box is ignored ), The first item represents the positioning error between the prediction box and the dimension box , The second term represents the confidence of the prediction box and the sum of the dimension box anchor Of IoU The error of the , Indicates the error between the classification result of the prediction box and the category information of the annotation box , This prediction category results in all the codes I see softmax Of .
There are five more in the picture λ \lambda λ, Represents the balance coefficient of each loss .
YOLO v3:
边栏推荐
- 21_Redis_浅析Redis缓存穿透和雪崩
- MD5 encryption
- 2022 年辽宁省大学生数学建模A、B、C题(相关论文及模型程序代码网盘下载)
- 07_哈希
- 党史纪实主题公益数字文创产品正式上线
- 21_ Redis_ Analysis of redis cache penetration and avalanche
- Real estate market trend outlook in 2022
- Equipped with Ti am62x processor, Feiling fet6254-c core board is launched!
- 原则、语言、编译、解释
- PHP method to get the index value of the array item with the largest key value in the array
猜你喜欢
基于RZ/G2L | OK-G2LD-C开发板存储读写速度与网络实测

Build your own semantic segmentation platform deeplabv3+
03_線性錶_鏈錶
MySQL calculate n-day retention rate
03_线性表_链表

Learn the method code example of converting timestamp to uppercase date using PHP
Kibana basic operation

Case introduction and problem analysis of microservice

Map introduction
02_线性表_顺序表
随机推荐
Sharp tool SPL for post SQL calculation
TiDB数据迁移场景综述
Let your HMI have more advantages. Fet-g2ld-c core board is a good choice
6.12 企业内部upp平台(Unified Process Platform)的关键一刻
11_Redis_Hyperloglog_命令
How does the computer set up speakers to play microphone sound
Party History Documentary theme public welfare digital cultural and creative products officially launched
02_线性表_顺序表
Build your own semantic segmentation platform deeplabv3+
XML配置文件
學習使用php實現公曆農曆轉換的方法代碼
Map introduction
原则、语言、编译、解释
Solve the problem of frequent interruption of mobaxterm remote connection
16_ Redis_ Redis persistence
哈夫曼树:(1)输入各字符及其权值(2)构造哈夫曼树(3)进行哈夫曼编码(4)查找HC[i],得到各字符的哈夫曼编码
Tidb data migration scenario overview
15_ Redis_ Redis. Conf detailed explanation
Recommended configuration of tidb software and hardware environment
Yolo format data set processing (XML to txt)