当前位置:网站首页>Thesis reading_ Tsinghua Ernie
Thesis reading_ Tsinghua Ernie
2022-07-03 04:43:00 【xieyan0811】
English title :ERNIE: Enhanced Language Representation with Informative Entities
Chinese title :ERNIE: Use information entities to enhance language representation
Address of thesis :https://arxiv.org/pdf/1905.07129v3/n
field : natural language processing
Time of publication :2019
author :Zhengyan Zhang, Tsinghua University
Source :ACL
Quantity cited :37
Code and data :https://github.com/thunlp/ERNIE
Reading time :2002.06.25
Journal entry
2019 Around the year, Tsinghua and Baidu both proposed the name ERNIE Model of , The same name , The method is different . Tsinghua's ERNIE hold Knowledge map is integrated into the vector of text Express , Also called KEPLM, The idea is more interesting , Model improvement effect : When using a small amount of data to train the model ,ERNIE Better than other models . From a technical point of view , It demonstrates Methods of integrating heterogeneous data .
Introduce
In this paper, ERNIE, It is a pre training language model combining knowledge map and large-scale data . The introduction of knowledge maps faces two important challenges :
- How to extract and represent the structure in knowledge graph in text representation
- Integrate heterogeneous data : Map the pre training model representation and knowledge graph representation to the same vector space
ERNIE The solution is as follows :
- Identify named entities mentioned in the text , And then The entity is aligned with the corresponding entity in the knowledge graph , Using text semantics as the entity embedding of knowledge graph , Reuse TransE Methods learn the structure of the graph .
- In terms of pre training language model , Also use similar BERT Of MLM Method , At the same time, use the alignment method , look for Mask the entities in the knowledge map ; Aggregate context and knowledge graph to jointly predict token And entities .
Method
Defining symbols
token( The smallest unit of operation : Usually words or words ) Use {w1,…,wn} Express , Aligned Entity use {e1,…, em} Express . We need to pay attention to m And n Generally, the number is different , An entity may contain more than one word . Definition V To include all token The vocabulary of , All entities in the knowledge graph use E Express . Use functions f(w)=e Indicates the alignment function , The first of entities is used in this paper token alignment .
Model structure
The structure of the model is shown in the figure -2 Shown :
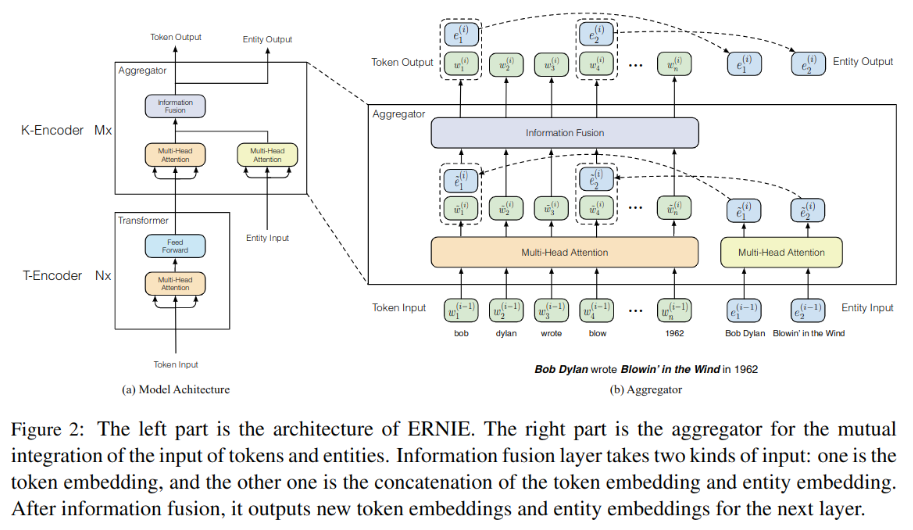
The model structure consists of two ,T-Encoder For extraction token Relevant text information ;K-Encoder Integrated extended graph information , Transform heterogeneous data into a unified space .
First , Will make use of token {w1,…, wn} Words embedded in 、 Segment embedding 、 Position insertion , Plug in T-Encoder layer , Calculate its semantic features :

T-Encoder Similar to ordinary BERT, It consists of N individual Transformer layers , In bold {e1,…, em} Said by TransE Pre trained graph embedding , Bold w and e Plug in K-Encoder, Integrate heterogeneous data , Generate output wo and eo:
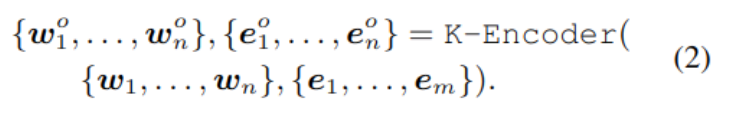
wo and eo Will be used for downstream tasks .
Knowledge coding
From the picture -2 You can see the right half of ,K-Encoder Generally including M layer , By the end of i Layer as an example , The input is number i-1 Layer of w and e, Use two multi headed self-attention.

about token:wj And with it alignment Entity of :ek=f(wj), Use the following methods to fuse data :

there hj Is the inner hidden layer , It is a combination of token And entity representation ,σ It's a nonlinear activation function , Use here GELU. For those who cannot find the corresponding entity token, No need to merge :
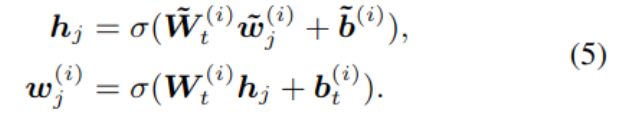
The first i The simplified representation of the layer is as follows :

Use the pre training model to inject knowledge
In pre training , Random Mask aligned token-entity, Let the model predict the corresponding multiple token. This process is similar to self encoder dEA. Knowledge map may contain many entities , do softmax The amount of calculation is very large , And we only focus on the entities needed by the system , To reduce the amount of calculation . In the given token Sequence and entity sequence , Define alignment distribution calculation :

It counts in w Under the condition of , Align entities to ej Probability , type (7) Used to calculate the cross entropy loss function .
stay 5% Under the circumstances , Replace the entity with another entity , Correct with training model token Alignment error with entity ; stay 15% Under the circumstances , shelter token Alignment with entities , Correct the alignment failure with the training model ; Keep alignment in other cases , Study token Relationship with entities .
The loss function of training synthesizes dEA( Self coding ),MLM( shelter ) and NSP( Sentence order ) The loss of .
Fine tune the model for specific tasks
Pictured -3 Shown :

For general tasks , Embed the encoded words into the downstream model . For knowledge driven tasks , For example, relationship classification , Or predict the entity type , Use the following methods to fine tune .
For the problem of relationship classification , The most direct method is to add a pool layer after the output entity vector , Concatenate entity pairs , Then send it to the classifier . The method proposed in this paper is shown in Figure -3 Shown , It labels the front and back of the head entity and the tail entity respectively , The effect of tags is similar to the position embedding in traditional relationship classification , Still use CLS To mark categories .
The prediction entity type is a simplified version of the relationship classification , Also used ENT Tags to guide the model to combine context information and entity information .
experiment
Tsinghua's ERNIE It is a model for English training , Experimental proof , Additional knowledge can help the model make full use of small training data , This is very useful for many tasks with limited data .
边栏推荐
- Summary of training competition (Lao Li's collection of questions)
- Symbol of array element product of leetcode simple problem
- Network security textual research recommendation
- How to choose cross-border e-commerce multi merchant system
- Use the benchmarksql tool to perform a data prompt on kingbases. The jdbc driver cannot be found
- General undergraduate college life pit avoidance Guide
- 2.14 summary
- String matching: find a substring in a string
- Leetcode simple question: check whether two string arrays are equal
- Shell script Basics - basic grammar knowledge
猜你喜欢

Golang -- realize file transfer
Know that Chuangyu cloud monitoring - scanv Max update: Ecology OA unauthorized server request forgery and other two vulnerabilities can be detected

Number of 1 in binary (simple difficulty)
Web - Information Collection

Preparation for school and professional cognition

Joint search set: the number of points in connected blocks (the number of points in a set)

Php+mysql registration landing page development complete code

论文阅读_中文NLP_ELECTRA
2022 new examination questions for the main principals of hazardous chemical business units and examination skills for the main principals of hazardous chemical business units

2022 Shandong Province safety officer C certificate examination content and Shandong Province safety officer C certificate examination questions and analysis
随机推荐
stm32逆向入门
[USACO 2009 Dec S]Music Notes
Truncated sentences of leetcode simple questions
The simple problem of leetcode: dismantling bombs
Market status and development prospects of the global IOT active infrared sensor industry in 2022
Dive Into Deep Learning——2.1数据操作&&练习
Games101 Lesson 9 shading 3 Notes
带有注意力RPN和多关系检测器的小样本目标检测网络(提供源码和数据及下载)...
[luatos sensor] 1 light sensing bh1750
RSRS index timing and large and small disc rotation
Market status and development prospect prediction of global neutral silicone sealant industry in 2022
Web security - CSRF (token)
Small sample target detection network with attention RPN and multi relationship detector (provide source code, data and download)
Crazy scientist
消息队列(MQ)介绍
雇佣收银员(差分约束)
Ffmpeg mix
2022 new examination questions for the main principals of hazardous chemical business units and examination skills for the main principals of hazardous chemical business units
[Thesis Writing] how to write the overall design of JSP tourism network
When using the benchmarksql tool to preheat data for kingbasees, execute: select sys_ Prewarm ('ndx_oorder_2 ') error