当前位置:网站首页>Mysql索引优化实战一
Mysql索引优化实战一
2022-07-07 21:51:00 【打分几楼MOTO】
目录
in和or在表数据量比较大的情况下会走索引,在表记录不多的情况下会选择全表扫描
综合案例
联合索引第一个字段用范围不会走索引
联合索引第一个字段就用范围查找不会走索引,mysql内部可能觉得第一个字段就用范围,结果集应该很大,回表效率不高,还不如就全表扫描(由图上可以分析,可能使用改联合索引但是最终没用,内部做了优化,这种情况下不建议强制使用索引)
对于下面这种情况,可以走覆盖索引或者强制使用索引

<!--使用三个联合索引中的第一个索引或者直接全表扫描-->
EXPLAIN SELECT * FROM employees WHERE NAME > 'xxx' AND age = 22 AND POSITION = 'xxx';
<!--使用三个联合索引中的前两个索引-->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age > 22 AND POSITION = 'xxx';
<!--使用三个联合索引中的三个索引-->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age = 22 AND POSITION = 'xxx';
<!--使用三个联合索引中的三个索引-->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age = 22 AND POSITION = 'xxx';
强制走索引

- 虽然使用了强制走索引让联合索引第一个字段范围查找也走索引,扫描的行rows看上去也少了点,但是最终查找效率不一定比全表扫描高,因为回表效率不高
覆盖索引优化

in和or在表数据量比较大的情况下会走索引,在表记录不多的情况下会选择全表扫描
- 数据量大

- 数据量小

like kk%不管表数据量大小都会走索引
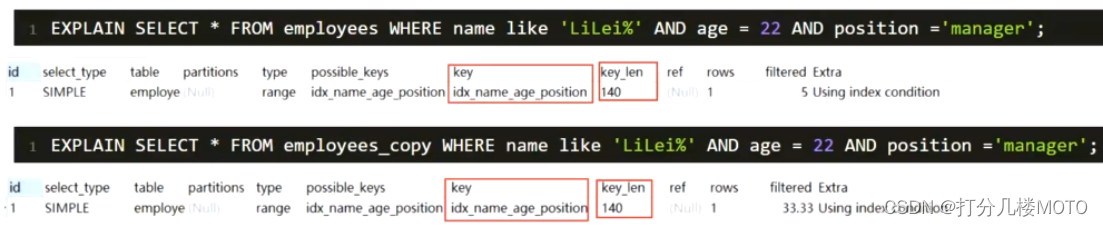
索引下推
- like kk%就是用到了索引下推优化
- 对于辅助的联合索引(name,age,position),正常情况按照最左前缀原则 SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager' 这种情况只会走name字段索引,因为根据name字段过滤完, 得到的索引行里的age和position是无序的,无法很好的利用索引。
- 在MySQL5.6之前的版本,这个查询只能在联合索引里匹配到名字是'LiLei'开头的索引,然后拿这些索引对应的主键逐个回表,到主键索引上找出相应的记录,再比对age和position这两个字段的值是否符合。
- MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数。使用了索引下推优化后,上面那个查询在联合索引里匹配到名字是 'LiLei'开头的索引之后,同时还会在索引里过滤age和position这两个字段,拿着过滤完剩下的索引对应的主键id再回表查整行数据。
- 索引下推会减少回表次数,对于innodb引擎的表索引下推只能用于二级索引,innodb的主键索引(聚簇索引)树叶子节点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
为什么范围查找Mysql没有用索引下推优化
- 应该是Mysql认为范围查找过滤的结果集过大,like kk%在绝大多数情况来看,过滤后的结果集比较小,所以Mysql选择给like kk%用索引下推
Mysql如何选择合适的索引

- 如果用name索引需要遍历name字段联合索引树,然后还需要根据遍历出来的主键值去主键索引树里再去查出最终数据,成本比全表扫描还高,可以用覆盖索引优化,这样只需要遍历name字段的联合索引书就能拿到所有结果
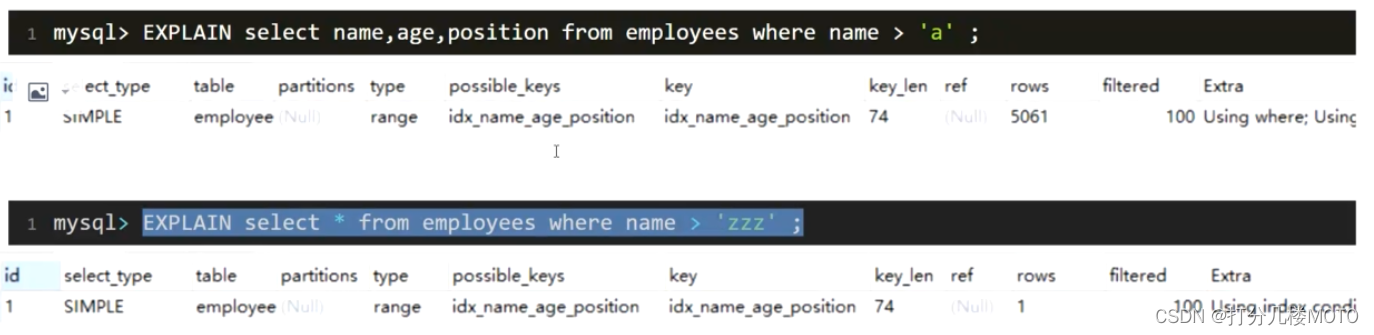
- 对于上面两种name>'a'和name>'zzz'的执行结果,mysql最终是否选择走索引或者一张表设计多个索引,mysql最终如何选择索引,我们可以用trace工具分析
打开trace
SET SESSION optimizer_trace="enabled=on",end_markers_in_json=ON;
SELECT * FROM employees WHERE NAME > 'a' ORDER BY POSITION;
SELECT * FROM information_schema.optimizer_trace关闭trace
SET SESSION optimizer_trace="enabled=off"
- 结果
{
"steps": [
{
"join_preparation": { 第一阶段:sql准备阶段,格式化sql
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'a') order by `employees`.`position` limit 0,1000"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { 第二阶段:sql优化阶段
"select#": 1,
"steps": [
{
"condition_processing": { 条件处理
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'a')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'a')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ 表依赖详情
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ 预估表的访问成本
{
"table": "`employees`",
"range_analysis": {
"table_scan": { 全表扫描情况
"rows": 1, 扫描行数
"cost": 2.45 查询成本
} /* table_scan */,
"potential_range_indexes": [ 查询可能使用的索引
{
"index": "PRIMARY", 主键索引
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_ name_ age_ position", 辅助索引
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "idx_ name_ age_ position",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": { 分析各个索引使用成本
"range_scan_alternatives": [
{
"index": "idx_ name_ age_ position",
"ranges": [
"a < name" 索引使用范围
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, 使用该索引获取的记录是否按照主键排序
"using_mrr": false,
"index_only": false, 是否使用覆盖索引
"rows": 1, 索引扫描行数
"cost": 0.61, 索引使用成本
"chosen": true 是否选择该索引
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_ name_ age_ position",
"rows": 1,
"ranges": [
"a < name"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { 左右访问路径
"considered_access_paths" : [ 最终选择的访问路径
{
"rows_to_scan": 1,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "range", 范文类型为range
"range_details": {
"used_index": "idx_ name_ age_ position"
} /* range_details */,
"resulting_rows": 1,
"cost": 0.71,
"chosen": true, 确定选择
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 0.71,
"sort_cost": 1,
"new_cost_for_plan": 1.71,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'a')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'a')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"optimizing_distinct_group_by_order_by": {
"simplifying_order_by": {
"original_clause": "`employees`.`position`",
"items": [
{
"item": "`employees`.`position`"
}
] /* items */,
"resulting_clause_is_simple": true,
"resulting_clause": "`employees`.`position`"
} /* simplifying_order_by */
} /* optimizing_distinct_group_by_order_by */
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"steps": [
] /* steps */,
"index_order_summary": {
"table": "`employees`",
"index_provides_order": false,
"order_direction": "undefined",
"index": "idx_ name_ age_ position",
"plan_changed": false
} /* index_order_summary */
} /* reconsidering_access_paths_for_index_ordering */
},
{
"finalizing_table_conditions": [
{
"table": "`employees`",
"original_table_condition": "(`employees`.`name` > 'a')",
"final_table_condition ": "(`employees`.`name` > 'a')"
}
] /* finalizing_table_conditions */
},
{
"refine_plan": [
{
"table": "`employees`",
"pushed_index_condition": "(`employees`.`name` > 'a')",
"table_condition_attached": null
}
] /* refine_plan */
},
{
"considering_tmp_tables": [
{
"adding_sort_to_table": "employees"
} /* filesort */
] /* considering_tmp_tables */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": { 第三阶段:SQL执行阶段
"select#": 1,
"steps": [
{
"sorting_table": "employees",
"filesort_information": [
{
"direction": "asc",
"expression": "`employees`.`position`"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"limit": 1000,
"chosen": false,
"cause": "sort_is_cheaper"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"memory_available": 262144,
"key_size": 40,
"row_size": 190,
"max_rows_per_buffer": 15,
"num_rows_estimate": 15,
"num_rows_found": 0,
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 0,
"sort_algorithm": "none",
"sort_mode": "<fixed_sort_key, packed_additional_fields>"
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
] /* steps */
}
常见sql深入优化
Order by
case1
- 利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len=74也能看出,age索引列用在排序过程中,因为Extra字段里没有using filesort

case2

case3
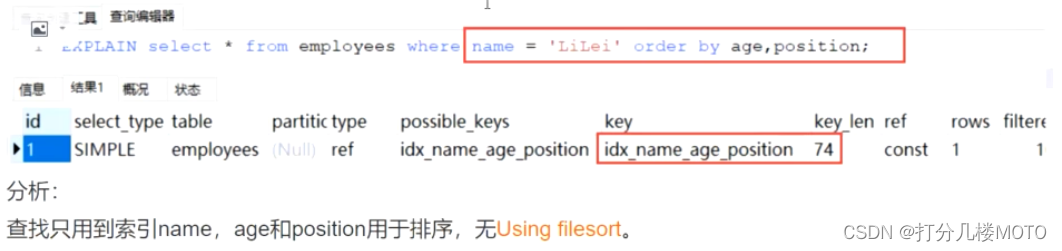
case4

case5

case6

case7
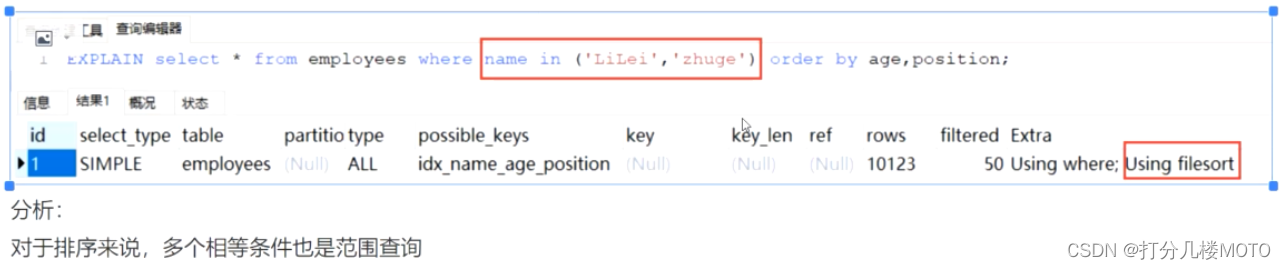
in如果不是在排序查询中有可能走索引,但是在排序查询中一定不会走索引(in会导致后面两个字段无序)
case8

- name > 'a' order by name: 按照我们的理解应该走索引,有可能是mysql觉得数据量太大了,而且查询字段是全部字段还需要进行回表所以使用使用全表扫描和文件排序
优化总结
- Mysql支持两种方式的排序filesort和index,Using index是指Mysql扫描索引本身完成排序,index,效率高,filesort效率低
- order by满足两种情况会使用Using index
- order by 语句使用索引最左前列
- 使用where字句与order by字句条件满足索引最左前列
- 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序),时的最左前缀法则
- 如果order by的条件不在索引列上,就会产生Using filesort
- 能用覆盖索引尽量用覆盖索引
- group by与odert by很类型,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则.对于group by的优化如果不需要排序的可以加上order by null 禁止排序,注意 where高于having,能写在where中的限定条件就不要去having中限定
Using filesort文件排序原理详解
filesort文件排序方式
- 单路排序:一次性取出满足条件行的所有字段,然后在sort buffer中进行排序;用trace工具可以看到sort_mode信息里显示<sort_key,additional_fields>或者<sort_key,packed_additional_fields>
- 双路排序(回表排序模式):首先根据相应的条件取出相应的排序字段和可以直接定位数据行的ID(从单路排序的结果集中拿到这些字段),然后在sort buffer中进行排序,排序完后需要再次取回其他需要的字段;用trace工具可以看到sort_mode信息里显示<sort_key,rowid>
如何选择使用哪种方式
通过比较系统变量max_length_for_sort_data(默认为1024字节)的大小和需要查询的字段总大小来判断哪种排序模式
如果字段的总长度小于max_length_for_sort_data,使用单路排序模式
如果字段的总长度大于max_length_for_sort_data,使用双路排序模式
SET SESSION optimizer_trace="enabled=on",end_markers_in_json=ON;
SELECT * FROM employees WHERE NAME = 'xxx' ORDER BY POSITION;
SELECT * FROM information_schema.optimizer_trace{
"steps": [
{
"join_execution": { sql执行阶段
"select#": 1,
"steps": [
{
"sorting_table": "employees",
"filesort_information": [
{
"direction": "asc",
"expression": "`employees`.`position`"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"limit": 1000,
"chosen": true
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { 文件排序信息
"memory_available": 262144,
"key_size": 40,
"row_size": 186,
"max_rows_per_buffer": 1001,
"num_rows_estimate": 18446744073709551615,
"num_rows_found": 0,"num_of_tmp_files": 3, 使用临时文件的个数,这个值如果为0代表全部使用的是sort_buffer内存排序,否则使用磁盘文件排序
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 194194,
"sort_algorithm": "none",
"unpacked_addon_fields": "using_priority_queue",
"sort_mode": "<fixed_sort_key, additional_fields>" 排序方式,这里使用的是单路排序
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
] /* steps */
}
- 我们先看单路排序的详细过程:
- 从索引name找到第一个满足name = 'zhuge'条件的主键id
- 根据主键id取出整行,取出所有字段的值,存入sort_ buffer 中
- 从索引name找到下一一个满足name = 'zhuge'条件的主键id
- 重复步骤2、3直到不满足name = 'zhuge'
- 对sort_ _buffer 中的数据按照字段position 进行排序
- 返回结果给客户端
- 我们再看下双路排序的详细过程:
- 从索引name找到第一个满足name = 'zhuge'的主键id
- 根据主键id取出整行,把排序字段position和主键id这两个字段放到sort buffer中
- 从索引name取下一个满足name =‘'zhuge'记录的主键id
- 重复3、4直到不满足name = 'zhuge'
- 对sort_ buffer 中的字段position 和主键id按照字段position进行排序
- 遍历排序好的id和字段position,按照id的值回到原表中取出所有字段的值返回给客户端
- 其实对比两个排序模式,单路排序会把所有需要查询的字段都放到sort buffer中,而双路排序只会把主键和需要排序的字段放到sort buffer中进行排序,然后再通过主键回到原表查询需要的字段。如果MySQL排序内存sort_ buffer 配置的比较小并且没有条件继续增加了,可以适当把max_ _length_ for_ _sort_ _data 配置小点,让优化器选择使用双路排序算法,可以在sort_ buffer 中- -次排序更多的行,只是需要再根据主键回到原表取数据。如果MySQL排序内存有条件可以配置比较大,可以适当增大max_ length_ for_ sort. _data 的值,让优化器优先选择全字段排序(单路排序),把需要的字段放到sort _buffer 中,这样排序后就会直接从内存里返回查询结果了。所以,MySQL通过max_ _length_ _for_ sort_ data 这个参数来控制排序,在不同场景使用不同的排序模式,从而提升排序效率。
- 注意:如果全部使用sort_ _buffer内存排序一 般情况下效率会高于磁 盘文件排序,但不能因为这个就随便增大sort_ _buffer(默认 1M),mysq|很多参数设置都是做过优化的,不要轻易调整。
索引设计原则
代码先行,索引为上
- 一般应该等到主体业务功能开发完毕,把涉及到该表相关sq|都要拿出来分析之后再建立索引。
联合索引尽量覆盖条件
- 比如可以设计一个或者两三个联合索引(尽量少建单值索引),让每一个联合索引都尽量去包含sq|语句里的where、order by. group by的字段,还要确保这些联合索引的字段顺序尽量满足sq|查询的最左前缀原则。
不要在小基数字段上建立索引
- 索引基数是指这个字段在表里总共有多少个不同的值,比如一张表总共100万行记录,其中有个性别字段,其值不是男就是女,那么该字段的基数就是2。
- 如果对这种小基数字段建立索弓|的话,还不如全表扫描了,因为你的索引树里就包含男和女两种值,根本没法进行快速的二分查找,那用索引就没有太大的意义了。
- 一般建立索引,尽量使用那些基数比较大的字段,就是值比较多的字段,那么才能发挥出B+树快速二分查找的优势来。
长字符串我们可以采用前缀索引
- 尽量对字段类型较小的列设计索引,比如说什么tinyint之 类的,因为字段类型较小的话,占用磁盘空间也会比较小,此时你在搜索的时候性能也会比较好一-点。
- 当然,这个所谓的字段类型小-点的列,也不是绝对的,很多时候你就是要针对varchar(255)这种字段建立索引,哪怕多占用一些磁盘空间也是有必要的。对于这中varchar(255)的大字段可能会比较占用磁盘空间,可以稍微优化下,比如针对这个字段的前20个字符建立索引,就是说,对这个字段里的每个值的前20个字符放在索引树里,类似于KEY index(name(20),age,position)。此时你在where条件里搜索的时候,如果是根据name字段来搜索,那么此时就会先到索引|树里根据name字段的前20个字符去搜索,定位到
之后前20个字符的前缀匹配的部分数据之后,再回到聚簇索引提取出来完整的name字段值进行比对。 - 但是假如你要是order by name,那么此时你的name因为在索引树里仅仅包含了前20个字符,所以这个排序是没法用上索引的,group by也是同理。所以这里大家要对前缀索引有一个了解。
where与order by冲突时有限where
- 在where和order by出现索引设计冲突时,到底是针对where去设计索引,还是针对order by设计索引?到底是让where去用上索引,还是让order by用上索引?
- 一般这种时候往往都是让where条件 去使用索引来快速筛选出来一部分指定的数据, 接着再进行排序。因为大多数情况基于索引进行where筛选往往可以最快速度筛选出你要的少部分数据,然后做排序的成本可能会小很多。
基于慢查询做优化
索引设计实战
以社交场景APP来举例,我们一般会去搜索一些好友, 这里面就涉及到对用户信息的筛选,这里肯定就是对用户user表搜索了,这个表-般来说数据量会比较大,我们先不考虑分库分表的情况.比如,我们一般会筛选地区(省市),性别,年龄,身高,爱好之类的,有的APP可能用户还有评分,比如用户的受欢迎程度评分,我们可能还会根据评分来排序等等。对于后台程序来说除了过滤用户的各种条件,还需要分页之类的处理,可能会生成类似sql语句执行:select XX from user where xx=Xx and xx=xx order by XX limit xx,XX对于这种情况如何合理设计索引了,
- 用户可能经常会根据省市优先筛选同城的用户,还有根据性别去筛选,那我们是否应该设计一个联合索引(province,ity,sex)了?这些字段好像基数都不大,其实是应该的,因为这些字段查询太频繁了。
- 假设又有用户根据年龄范围去筛选了,比如where province=xx and city=xx and age>=xx and age<=xx,我们尝试着把age字段加入联合索引(province,city,sex,age),注意, -般这种范围查找的条件都要放在最后,之前讲过联合索引范围之后条件的是不能用索引的,但是对于当前这种情况依然用不到age这个索引字段,因为用户没有筛选sex字段,那怎么优化了?其实我们可以这么来优化下sq|l的写法: where province=xx and city=xx and sex in ('female' ,'male') and age>=Xx and age<=xx
- 对于爱好之类的字段也可以类似sex字段处理,所以可以把爱好字段也加入索引 (province ,city,sex,hobby,age)
- 假设可能还有一个筛选条件,比如要筛选最近一周登录过的用户,一 般大家肯定希望跟活跃用户交友了,这样能尽快收到反馈,对应后台sq|可能是这样:where province=xx and city=xx and sex in ('female','male') and age>=xx and age<=xx and latest_login_ time>= Xx那我们是否能把latest_login_ time 字段也加入索引了?比如(province,city,sex,hobby,age,latest login_ time) ,显然是不行的,那怎么来优化这种情况了?其实我们可以试着再设计- -个字段is_ _login_ in_ latest 7_ days,用户如果-周内有登录值就为1, 否则为0,那么我们就可以把索引设计成(province,ity,sex,hobby,is_ _login_ in_ latest_ 7_ days,age)来满足上面那种场景了!
- 一般来说, 通过这么一个多字段的索弓 |是能够过滤掉绝大部分数据的,就保留小部分数据下来基于磁盘文件进行order by语句的排序,最后基于limit进行分页,那么一般性能还是比较高的。不过有时可能用户会这么来查询,就查下受欢迎度较高的女性,比如sq|: where sex = 'female' order by score limit xx,xx,那么上面那个索引是很难用上的,不能把太多的字段以及太多的值都用in语句拼接到sq|里的,那怎么办了?其实我们可以再设计-一个辅助的联合索引,比如(sex,score),这样就能满足查询要求了。
- 以上就是给大家讲的一些索引设计的思路了,核心思想就是,尽量利用- -两个复杂的多字段联合索引,抗下你80%以上的查询,然后用一两个辅助索引尽量抗下剩余的- -些非典型查询,保证这种大数据量表的查询尽可能多的都能充分利用索引,这样就能保证你的查询速度和性能了!
边栏推荐
- Conversion between commonsmultipartfile and file
- Gee (IV): calculate the correlation between two variables (images) and draw a scatter diagram
- Grid
- Circumvention Technology: Registry
- 云原生数据仓库AnalyticDB MySQL版用户手册
- Dynamic agent explanation (July 16, 2020)
- Oracle-数据库的备份与恢复
- What are the similarities and differences between smart communities and smart cities
- 微信论坛交流小程序系统毕业设计毕设(2)小程序功能
- oc 可变參数传递
猜你喜欢

PMP project management exam pass Formula-1
微信论坛交流小程序系统毕业设计毕设(3)后台功能

Lecture 30 linear algebra Lecture 5 eigenvalues and eigenvectors
七月第一周

微信论坛交流小程序系统毕业设计毕设(8)毕业设计论文模板
ArcGIS:矢量要素相同字段属性融合的两种方法
Solve the problem of duplicate request resource paths /o2o/shopadmin/o2o/shopadmin/getproductbyid

Unity3D学习笔记6——GPU实例化(1)

Inftnews | the wide application of NFT technology and its existing problems
USB(十五)2022-04-14
随机推荐
定位到最底部[通俗易懂]
海内外技术人们“看”音视频技术的未来
微信论坛交流小程序系统毕业设计毕设(8)毕业设计论文模板
网络安全-CSRF
Transform XL translation
Kubernetes' simplified data storage storageclass (creation, deletion and initial use)
Grid
FPGA基础篇目录
UE4_UE5全景相机
网络安全-burpsuit
【微服务|SCG】gateway整合sentinel
GEE(四):计算两个变量(影像)之间的相关性并绘制散点图
【编译原理】词法分析设计实现
Txt file virus
CAIP2021 初赛VP
Digital collections accelerated out of the circle, and marsnft helped diversify the culture and tourism economy!
Adrnoid Development Series (XXV): create various types of dialog boxes using alertdialog
微信论坛交流小程序系统毕业设计毕设(5)任务书
Two kinds of curves in embedded audio development
js 获取对象的key和value