当前位置:网站首页>Transform XL translation
Transform XL translation
2022-07-07 23:04:00 【Anny Linlin】
1. Introduce
Language modeling is one of the important problems that need to model long-term dependencies , It has successful applications , Such as unsupervised training (Peters et al., 2018; Devlin et al.,2018). However , How to make neural networks have the ability to model long-term dependencies in sequence data , It has always been a challenge . Recursive neural network (RNNs), In especial LSTM(Hochreiter & Schmidhuber, 1997), It has become a standard solution for language modeling , And achieved good results on multiple benchmarks . Although widely used ,RNNs It is difficult to optimize due to gradient disappearance and gradient explosion (Hochreiter et al., 2001), stay LSTMs The introduction of control doors and supervisor cutting technology (Graves,
2013; Pascanu et al., 2012) Maybe it can't effectively solve this problem . Based on previous work experience ,LSTM Language models are used on average 200 Contextual vocabulary (Khandelwal et al.,2018), This shows that there is room for further improvement .
On the other hand , The direct connection between long-distance word pairs in the attention mechanism can simplify optimization , And make it possible to learn long-term dependence (Bahdanau et al.,2014; Vaswani et al., 2017).. lately ,Al-Rfou et al. (2018) Designed a set of auxiliary losses for training deep transformer networks For character level language modeling , Its performance far exceeds LSTM. Although in Al-Rfou et al. (2018) Successful training , But it is executed on a fixed length segment separated by hundreds of characters , stay segments There is no flow of information between . Due to the fixed context length , The model cannot capture any long-term dependencies over ????. Besides , Fixed length segments It is created by selecting some continuous characters in the case of related sentences or other semantic boundaries . therefore , The model predicts that the first few characters lack the necessary context information , It leads to inefficient model optimization and poor execution effect . We call this context problem context fragment .
In order to solve the limitations of the above fixed length context , We propose a new architecture ,Transformer-XL (meaning extra long). We are introducing this concept into the deep self attention network . especially , We will no longer calculate the hidden state of each new segment from zero , Instead, reuse the hidden state obtained in the previous segment . The reused hidden state is used as the memory of the current segment , Establish a circular connection between these segments . therefore , Longer term dependency modeling is possible , Because information can be transmitted through circular connections . meanwhile , Passing information from the previous paragraph can also solve the problem of context segmentation . what's more , We showed the necessity of using relative position coding instead of absolute coding , To enable state reuse without causing time chaos . therefore , As an additional technical contribution , We introduce a simple but more effective relative position coding formula , It can be summarized as a longer attention length than that observed in training .
2. Related work
3. Model
Give a prediction base x = (x1; : : : ; xT ), This language model Is to estimate the joint probability P(x), It is usually automatically decomposed into ![]()
Through this decomposition formula , We can see that this problem comes down to the solution of each conditional probability . In this paper , We insist on using standard neurons to model and calculate conditional probability . To be specific , A trainable neural network will context x<t Encoded as a fixed size hidden state , It is related to words Embedding Multiply to get labels , Then enter this tag into softmax function , Find the probability of the next word category .
3.1 VANILLA TRANSFORMER LANGUAGE MODELS
In order to transform or self-attention Applied to language modeling , The core problem is how to train a Transformer, It can effectively encode any long context into a fixed size representation . Given unlimited memory and computing conditions , A simple solution is to use an unconditional Transformer decorder To handle the whole context sequence , Similar to feedforward neural network . However , With limited actual resources , This is usually not feasible .

A feasible but rough approximation is to divide the whole corpus into short manageable fragments , And only train the model in each segment , All contextual information from the first few fragments is ignored . The idea was Al-Rfou et al. (2018). use . We can call it Vanilla Model and in the picture 1(a) Visualize it . In this training mode , Whether forward or backward , Information will not flow across segments . Using a fixed length context has two key limitations : First , The maximum possible length of long-term dependence is segment The length is the upper limit , Build hundreds of models at the character level . therefore , although self-attention Mechanism and Rnns comparison , It is less affected by the vanishing gradient problem , however Vanilla model Not making full use of this advantage . secondly , Although it can be used to fill sentences or other semantic boundaries , In practice , Because of the improvement of efficiency , Simply converting long text blocks into fixed length sequences has become a standard practice (Peterset al., 2018; Devlin et al., 2018; Al-Rfou et al., 2018).. however , If you simply block the sequence into a fixed length sequence , This will lead to the problem of context fragmentation discussed in the section .
In the evaluation , At every step ,vanilla model Also use one with the same training length segment, Only one prediction was made at the last position . then , In the next step ,segment Only move one position to the right , And new segment It must be handled from the beginning . Pictured 1b Exhibition , This process ensures that during training , Each prediction uses the longest exposed context , And alleviate the problem of context fragmentation encountered in the training process . However, this evaluation process is costly . We will show that our proposed architecture can greatly improve the speed of evaluation .
3.2 SEGMENT-LEVEL RECURRENCE WITH STATE REUSE
In order to solve the limitation of using fixed length context , We suggest introducing in transformer A looping mechanism is introduced into the architecture . During training , For the front segment The computed hidden state sequence is fixed and cached , In order to deal with the next new segment Reuse as extension context , Pictured 2a Shown . Although the gradient remains at segment Inside , But this extra input allows the network to take advantage of historical information , Thus, we can model longer-term dependencies and avoid context fragmentation . In form , These two are continuous segment The length of L yes ![]() , use
, use ![]() Indicates the fourth segment The second n Layer hidden state sequence , among d Is the hidden layer dimension .
Indicates the fourth segment The second n Layer hidden state sequence , among d Is the hidden layer dimension .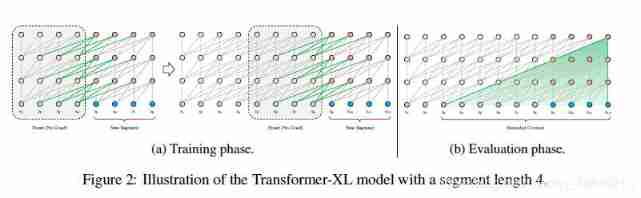
then ,segment Of ![]() The first n The generation process of layer hidden state is as follows :
The first n The generation process of layer hidden state is as follows :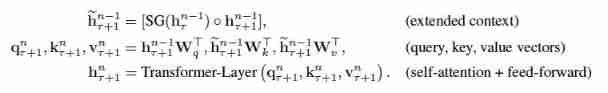
there SG(·) The function represents stop-gradient,![]() Indicates that two hidden layer sequences are connected along the length dimension ,W For the parameters of the model . And standard Transformer comparison , The key difference is this Key
Indicates that two hidden layer sequences are connected along the length dimension ,W For the parameters of the model . And standard Transformer comparison , The key difference is this Key ![]() and value
and value ![]() Is to extend the context
Is to extend the context ![]() and
and ![]() Cache front segment Information . Let's go through the picture 2a Green path to emphasize this special design . This recursive mechanism is applied to every two consecutive segment, Essentially, it creates segmented recursion in a hidden state . therefore , The effective context used can be far more than two parts . however , Note that this loop depends on
Cache front segment Information . Let's go through the picture 2a Green path to emphasize this special design . This recursive mechanism is applied to every two consecutive segment, Essentially, it creates segmented recursion in a hidden state . therefore , The effective context used can be far more than two parts . however , Note that this loop depends on ![]() and
and ![]() Between , Each segment moves down one layer , It's with the traditional RNN-LMs Loop different from the same layer . Therefore, the maximum possible dependence length is between the number of layers and segment Linear growth in length w.r.t,
Between , Each segment moves down one layer , It's with the traditional RNN-LMs Loop different from the same layer . Therefore, the maximum possible dependence length is between the number of layers and segment Linear growth in length w.r.t,![]() , In the figure 2b Show in . This is similar to truncated BPTT(Mikolov et al., 2010), A kind of training RNN-LMs The technique of . However , Our method is different from RNN-LMs, It is a sequence of cached hidden states instead RNN-LMs Only the last hidden state is reserved in , It is applied together to the relevant location coding technology through 3.3 Part to elaborate .
, In the figure 2b Show in . This is similar to truncated BPTT(Mikolov et al., 2010), A kind of training RNN-LMs The technique of . However , Our method is different from RNN-LMs, It is a sequence of cached hidden states instead RNN-LMs Only the last hidden state is reserved in , It is applied together to the relevant location coding technology through 3.3 Part to elaborate .
In addition to solving the problem of ultra long context memory and context fragmentation , Another advantage of the proposed circulation scheme is that it greatly speeds up the evaluation . Especially during the evaluation , From the front segment The representation of can be reused , Not like it vanilla model Then calculate from scratch . stay enwiki8 In the experiments ,Transformer-XL yes Vanilla model Of 1800+ times .
Last , Please note that , The recursive scheme need not be limited to the previous paragraph . Theoretically , We can do it in GPU Cache as much memory as possible before segment, And dealing with the current segment Reuse them as additional context . therefore , Due to memory enhancement with Neural Networks (Graves et al.,2014;Weston et al., 2014) Clear connection , We can cache a predefined length -M The old hidden state of crosses ( Probably ) Multiple segment Of , And call them memory ![]() .
.
In our experiment , When we train , Set up M be equal to segment length , And it has been added many times in the evaluation process .
3.3 RELATIVE POSITIONAL ENCODINGS
Although we found the idea proposed in the previous section very attractive , But to reuse hidden states , We haven't solved a key technical challenge . in other words , When we reuse state , How to maintain the consistency of location information ? Think about it , In standard Transformer in , The information of sequence sequence is provided by a set of position codes . The symbol is ![]() , Here I i That's ok Ui It's corresponding to segment pass the civil examinations i The absolute position of ,Lmax Specify the maximum possible length to be modeled . then ,Transformer The real input of is to add by element word embedding and positional encodings. If we simply adapt this location coding to the recursive mechanism introduced above , The hidden state sequence will be calculated as shown in the figure below :
, Here I i That's ok Ui It's corresponding to segment pass the civil examinations i The absolute position of ,Lmax Specify the maximum possible length to be modeled . then ,Transformer The real input of is to add by element word embedding and positional encodings. If we simply adapt this location coding to the recursive mechanism introduced above , The hidden state sequence will be calculated as shown in the figure below :![]()
边栏推荐
- 苹果在iOS 16中通过'虚拟卡'安全功能进一步进军金融领域
- 安踏DTC | 安踏转型,构建不只有FILA的增长飞轮
- ADC采样率(HZ)是什么怎么计算
- Comparison of various development methods of applets - cross end? Low code? Native? Or cloud development?
- PHP method of obtaining image information
- 0-5vac to 4-20mA AC current isolated transmitter / conversion module
- Ligne - raisonnement graphique - 4 - classe de lettres
- Microbial health network, how to restore microbial communities
- One question per day - pat grade B 1002 questions
- 微服务远程Debug,Nocalhost + Rainbond微服务开发第二弹
猜你喜欢
Line test - graphic reasoning - 4 - alphabetic class

【测试面试题】页面很卡的原因分析及解决方案
Leetcode94. Middle order traversal of binary trees
数字藏品加速出圈,MarsNFT助力多元化文旅经济!

0-5vac to 4-20mA AC current isolated transmitter / conversion module

Line test - graphic reasoning -5- one stroke class
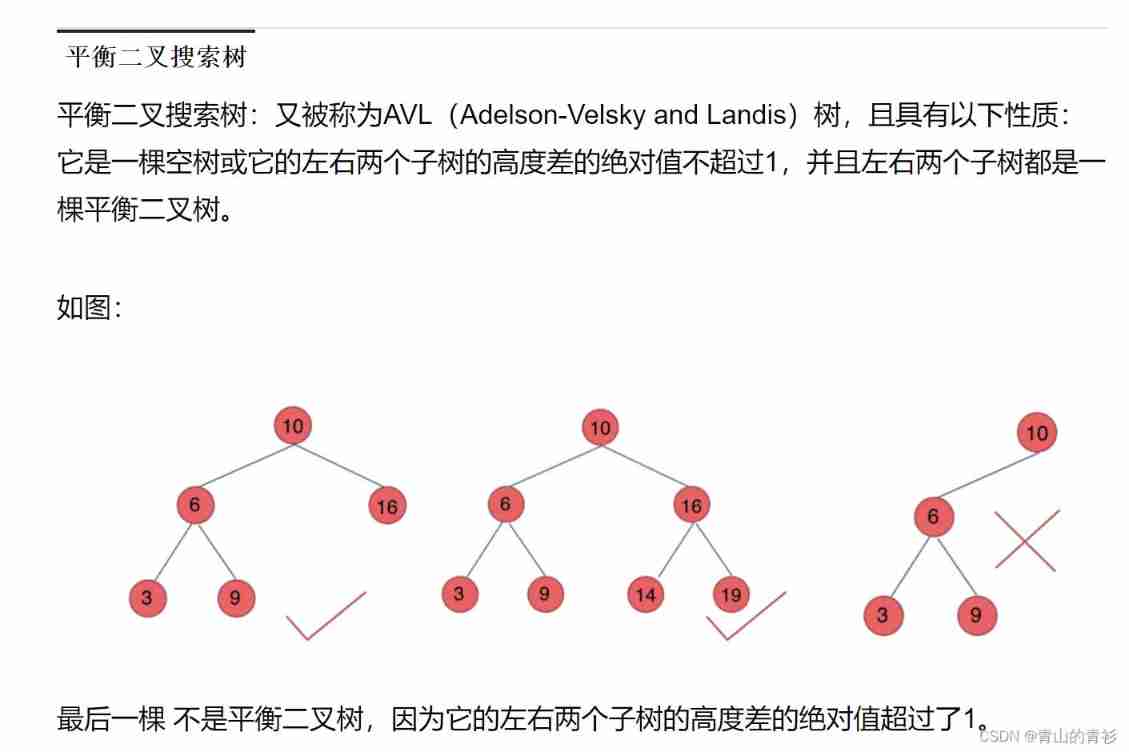
Basic knowledge of binary tree
面试百问:如何测试App性能?
The PHP source code of the new website + remove authorization / support burning goose instead of pumping
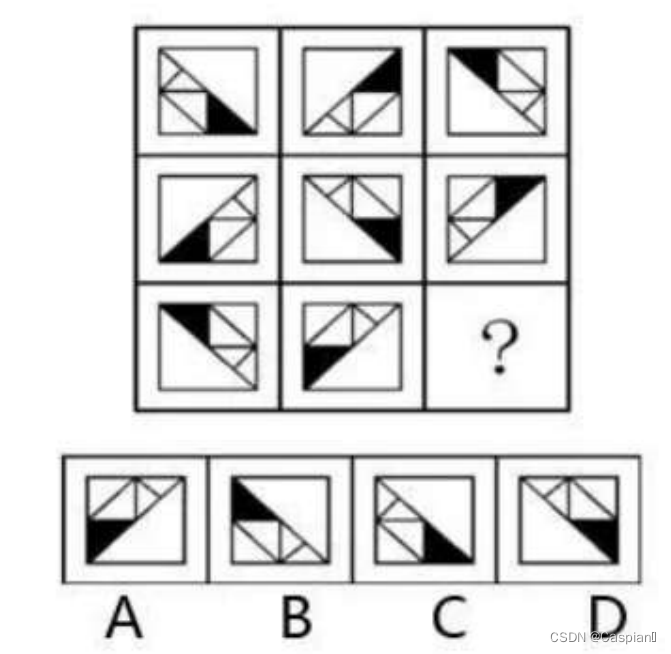
行测-图形推理-6-相似图形类
随机推荐
Apple further entered the financial sector through the 'virtual card' security function in IOS 16
Use JfreeChart to generate curves, histograms, pie charts, and distribution charts and display them to JSP-1
Amesim2016 and matlab2017b joint simulation environment construction
Early childhood education industry of "screwing bar": trillion market, difficult to be a giant
Online interview, how to better express yourself? In this way, the passing rate will be increased by 50%~
Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades-KDD2020
Use JfreeChart to generate curves, histograms, pie charts, and distribution charts and display them to jsp-2
苹果在iOS 16中通过'虚拟卡'安全功能进一步进军金融领域
Sword finger offer 27 Image of binary tree
LeetCode203. Remove linked list elements
Form组件常用校验规则-2(持续更新中~)
Debezium系列之:源码阅读之SnapshotReader
知识点滴 - PCB制造工艺流程
2022 words for yourself
PCL . VTK files and Mutual conversion of PCD
每日一题——PAT乙级1002题
Ni9185 and ni9234 hardware settings in Ni Max
What does the model number of asemi rectifier bridge kbpc1510 represent
Two minutes, talk about some wrong understandings of MySQL index
LeetCode142. Circular linked list II [two pointers, two methods for judging links in the linked list and finding ring points]