当前位置:网站首页>Pytorch builds the simplest version of neural network
Pytorch builds the simplest version of neural network
2022-07-03 05:49:00 【code bean】
The data set is , Indicators of patients with diabetes and whether to change diabetes .

diabetes.csv Training set
diabetes_test.csv Test set
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
# Note that this must be written as a two-dimensional matrix
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
self.activate = torch.nn.ReLU()
# __call__() This function will be called in !
def forward(self, x):
# x = self.activate(self.linear1(x))
# x = self.activate(self.linear2(x))
# x = self.activate(self.linear3(x))
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
# model Is callable ! Realized __call__()
model = Model()
# Specify the loss function
# criterion = torch.nn.MSELoss(size_average=Flase) # True
# criterion = torch.nn.MSELoss(reduction='sum') # sum: Sum up mean: Averaging
criterion = torch.nn.BCELoss(size_average=True) # Two class cross entropy loss function
# -- Specify optimizer ( In fact, it is the algorithm of gradient descent , be responsible for ), The optimizer and model Associated
# optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # This one is very accurate , Other things are not good at all
# optimizer = torch.optim.Rprop(model.parameters(), lr=0.01)
for epoch in range(5000):
y_pred = model(x_data) # Directly put the whole test data into
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # It will automatically find all the w and b Clear ! The role of the optimizer ( Why is this put in loss.backward() You can't clear it later ?)
loss.backward()
optimizer.step() # It will automatically find all the w and b updated , The role of the optimizer !
# test
xy = np.loadtxt('diabetes_test.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, -1])
x_test = torch.Tensor(x_data)
y_test = model(x_test) # forecast
print('y_pred = ', y_test.data)
# Compare the predicted results with the real results
for index, i in enumerate(y_test.data.numpy()):
if i[0] > 0.5:
print(1, int(y_data[index].item()))
else:
print(0, int(y_data[index].item()))
From the code , From the beginning, the data feature dimension is 8 dimension , Through the dimensionality reduction layer by layer, the final output of one-dimensional data ( Although the input is multidimensional , But the output is a one-dimensional probability value , It is still a binary problem )
Such as : Linear(8, 6) Indicates that the input characteristic is 8 dimension , Output characteristics 6 dimension . The dimension considered at this time is column ( The number of unknowns ). Regardless of the dimension of the row , Because the dimension of a row represents the number of samples , And for pythroch Function of , The number of samples doesn't matter , One will do , A pile of it , It only cares about the dimension of the column .
The model built by the final code is as follows :( I built an extra layer in my code , You can also try more )

Note here , Although it's called Linear Layer, But in fact , It contains an activation function , So it's actually nonlinear , If it is linear, it is not called neural network
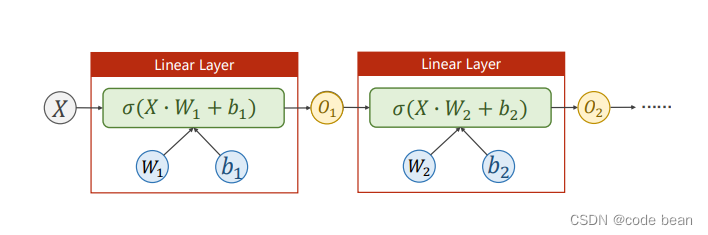
You can also try other activation functions :
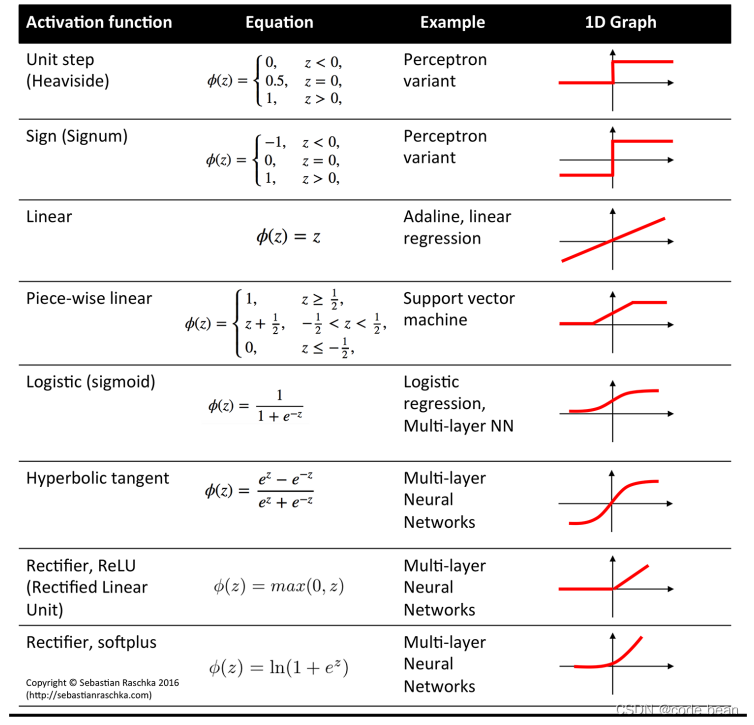
Welcome to send your settings to the comment area . Let's see the effect of your prediction .
At present, there is no small batch processing of data , Then add .
Reference material :
 https://www.bilibili.com/video/BV1Y7411d7Ys?p=8&vd_source=eb730c561c03cdaf7ce5f40354ca252c
https://www.bilibili.com/video/BV1Y7411d7Ys?p=8&vd_source=eb730c561c03cdaf7ce5f40354ca252cDataset resources :
边栏推荐
- How do I migrate my altaro VM backup configuration to another machine?
- 2022.7.2 模拟赛
- Altaro virtual machine replication failed: "unsupported file type vmgs"
- MySQL startup error: several solutions to the server quit without updating PID file
- Ensemble, série shuishu] jour 9
- Final review (Day5)
- Xaml gradient issue in uwp for some devices
- 1. 两数之和
- Sophomore dilemma (resumption)
- [teacher Zhao Yuqiang] MySQL flashback
猜你喜欢

中职网络子网划分例题解析

How to install and configure altaro VM backup for VMware vSphere

Capacity expansion mechanism of map

理解 期望(均值/估计值)和方差
![[escape character] [full of dry goods] super detailed explanation + code illustration!](/img/33/ec5a5e11bfd43f53f2767a9a0f0cc9.jpg)
[escape character] [full of dry goods] super detailed explanation + code illustration!
![[teacher Zhao Yuqiang] kubernetes' probe](/img/cc/5509b62756dddc6e5d4facbc6a7c5f.jpg)
[teacher Zhao Yuqiang] kubernetes' probe

Redhat7系统root用户密码破解

Shanghai daoning, together with American /n software, will provide you with more powerful Internet enterprise communication and security component services

Exception when introducing redistemplate: noclassdeffounderror: com/fasterxml/jackson/core/jsonprocessingexception
![[together Shangshui Shuo series] day 7 content +day8](/img/fc/74b12addde3a4d3480e98f8578a969.png)
[together Shangshui Shuo series] day 7 content +day8
随机推荐
There is no one of the necessary magic skills PXE for old drivers to install!!!
Understand one-way hash function
Today, many CTOs were killed because they didn't achieve business
CAD插件的安裝和自動加載dll、arx
Jetson AGX Orin 平台移植ar0233-gw5200-max9295相机驱动
Shanghai daoning, together with American /n software, will provide you with more powerful Internet enterprise communication and security component services
伯努利分布,二项分布和泊松分布以及最大似然之间的关系(未完成)
[video of Teacher Zhao Yuqiang's speech on wot] redis high performance cache and persistence
Qt读写Excel--QXlsx插入图表5
Analysis of the example of network subnet division in secondary vocational school
Redhat7 system root user password cracking
The programmer shell with a monthly salary of more than 10000 becomes a grammar skill for secondary school. Do you often use it!!!
How to create and configure ZABBIX
Yum is too slow to bear? That's because you didn't do it
The server data is all gone! Thinking caused by a RAID5 crash
AtCoder Beginner Contest 258(A-D)
Export the altaro event log to a text file
Altaro o365 total backup subscription plan
kubernetes资源对象介绍及常用命令(五)-(ConfigMap)
redis 遇到 NOAUTH Authentication required