当前位置:网站首页>Pyg tutorial (8): calculate a more efficient sparse matrix form
Pyg tutorial (8): calculate a more efficient sparse matrix form
2022-07-25 21:35:00 【Si Xi is towering】
One . Preface
stay Pytorch Geometric We often use the messaging paradigm to customize GNN Model , But this method has some defects : In the process of neighborhood aggregation , Physicochemical x_i and x_j It may take up a lot of memory ( Especially on the big picture ). However , Not all GNN All need to be expressed in this normal form of message transmission , some GNN It can be directly expressed in the form of sparse matrix multiplication . stay 1.6.0 After the version ,PyG The official introduction of sparse matrix multiplication GNN Stronger support (torch-sparse Medium SparseTensor), Sparse matrix multiplication can make memory more efficient , At the same time, it also accelerates the execution time .
Two .SparseTensor Detailed explanation
2.1 The way of construction
PyG adopt SparseTensor Class to support sparse matrices , This class is located in torch_sparse Module , You can import :
from torch_sparse import SparseTensor
The constructor of this class is as follows :
def __init__(
self,
row: Optional[torch.Tensor] = None,
rowptr: Optional[torch.Tensor] = None,
col: Optional[torch.Tensor] = None,
value: Optional[torch.Tensor] = None,
sparse_sizes: Optional[Tuple[Optional[int], Optional[int]]] = None,
is_sorted: bool = False,
trust_data: bool = False,
)
Common parameters are described as follows :
| Parameters | explain |
|---|---|
row | Non zero row subscript , namely edge_index[0] |
col | Column subscripts with non-zero values , namely edge_index[1] |
value | Non zero value corresponding to index , Optional |
sparse_sizes | The size of the sparse matrix |
Given graph :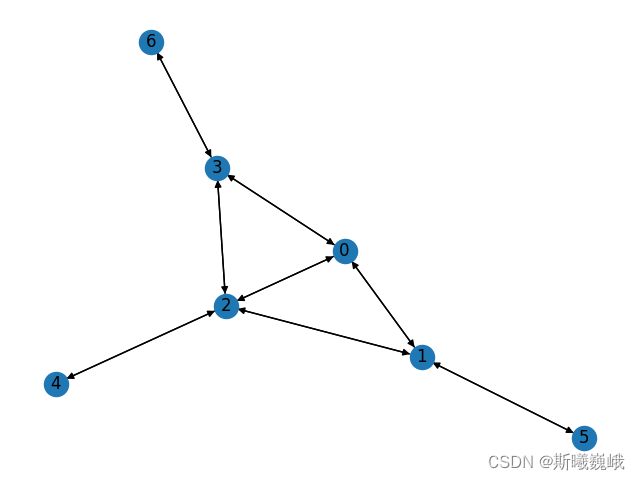
The corresponding sparse adjacency matrix construction code is as follows :
import torch
from torch_sparse import SparseTensor
from torch_geometric.utils import to_undirected
edge_index = torch.LongTensor(
[[0, 0, 0, 1, 2, 1, 2, 3], [1, 2, 3, 2, 3, 5, 4, 6]])
edge_index = to_undirected(edge_index)
adj = SparseTensor(row=edge_index[0], col=edge_index[1], sparse_sizes=(7, 7))
print(adj)
""" SparseTensor(row=tensor([0, 0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 5, 6]), col=tensor([1, 2, 3, 0, 2, 5, 0, 1, 3, 4, 0, 2, 6, 2, 1, 3]), size=(7, 7), nnz=16, density=32.65%) """
In addition to the above methods ,SparseTensor It can also be created in other forms :
# From dense matrix ( Common common matrix ) Create
adj = SparseTensor.from_dense(mat)
# Create a unit array of specified size
adj = SparseTensor.eye(100, 100)
# from scipy Create matrix
adj = SparseTensor.from_scipy(mat)
2.2 Common use
And scipy similar ,SparseTensor Also support COO、CSR and CSC And other storage formats :
row, col, value = adj.coo()
rowptr, col, value = adj.csr()
colptr, row, value = adj.csc()
For several different formats of sparse matrix ,Sparse Summary of main storage formats of sparse matrix The article has a more detailed introduction , It's not going to unfold here .
SparseTensor The common operations supported are as follows :
# section
adj = adj[:100, :100]
# Add diagonal item , A + I, I Is the unit matrix
adj = adj.set_diag()
# Transposition
adj_t = adj.t()
SparseTensor That is to say, they can communicate with each other Concentrated (dense) matrix Do multiplication , with sparse matrix Do multiplication , namely :
# Sparse-Dense Matrix Multiplication
x = torch.rand(7, 4)
out = adj.matmul(x)
print(out.shape)
# torch.Size([7, 4])
# Sparse-Sparse Matrix Multiplication
adj = adj.matmul(adj)
stay GNN in , We often need to evaluate adjacency matrix Regularization (Normalization), The following is the regularization source code of sparse matrix :
def norm_adj(adj_t, add_self_loops=True):
""" normalization adj """
if not adj_t.has_value():
adj_t = adj_t.fill_value(1.)
if add_self_loops:
adj_t = fill_diag(adj_t, 1.)
deg = sparsesum(adj_t, dim=1)
deg_inv_sqrt = deg.pow_(-0.5)
deg_inv_sqrt.masked_fill_(deg_inv_sqrt == float('inf'), 0.)
adj_t = mul(adj_t, deg_inv_sqrt.view(-1, 1))
adj_t = mul(adj_t, deg_inv_sqrt.view(1, -1))
return adj_t
adj = norm_adj(adj)
print(adj.to_dense())
""" tensor([[0.2500, 0.2500, 0.2236, 0.2500, 0.0000, 0.0000, 0.0000], [0.2500, 0.2500, 0.2236, 0.0000, 0.0000, 0.3536, 0.0000], [0.2236, 0.2236, 0.2000, 0.2236, 0.3162, 0.0000, 0.0000], [0.2500, 0.0000, 0.2236, 0.2500, 0.0000, 0.0000, 0.3536], [0.0000, 0.0000, 0.3162, 0.0000, 0.5000, 0.0000, 0.0000], [0.0000, 0.3536, 0.0000, 0.0000, 0.0000, 0.5000, 0.0000], [0.0000, 0.0000, 0.0000, 0.3536, 0.0000, 0.0000, 0.5000]]) """
3、 ... and . Sparse matrix form GCN
GCN The propagation formula of is :
X ′ = D ^ − 1 / 2 A ^ D ^ − 1 / 2 X Θ \mathbf{X}^{\prime} = \mathbf{\hat{D}}^{-1/2} \mathbf{\hat{A}} \mathbf{\hat{D}}^{-1/2} \mathbf{X} \mathbf{\Theta} X′=D^−1/2A^D^−1/2XΘ
among A ^ = A + I \mathbf{\hat{A}} = \mathbf{A} + \mathbf{I} A^=A+I. According to the formula , Sparse matrix form GCN Realization 、 The training and evaluation are as follows :
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch_sparse import fill_diag, mul
from torch_sparse import sum as sparsesum
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
from copy import deepcopy
def norm_adj(adj_t, add_self_loops=True):
""" normalization adj """
if not adj_t.has_value():
adj_t = adj_t.fill_value(1.)
if add_self_loops:
adj_t = fill_diag(adj_t, 1.)
deg = sparsesum(adj_t, dim=1)
deg_inv_sqrt = deg.pow_(-0.5)
deg_inv_sqrt.masked_fill_(deg_inv_sqrt == float('inf'), 0.)
adj_t = mul(adj_t, deg_inv_sqrt.view(-1, 1))
adj_t = mul(adj_t, deg_inv_sqrt.view(1, -1))
return adj_t
class GCNConv(nn.Module):
def __init__(self, in_feats, out_feats, bias=False) -> None:
super().__init__()
self.lin = nn.Linear(in_feats, out_feats, bias)
def forward(self, x, adj):
x = self.lin(x)
return adj.matmul(x)
class GCN(nn.Module):
def __init__(self, in_feats, hidden_size, out_feats) -> None:
super().__init__()
self.gcn_conv1 = GCNConv(in_feats, hidden_size)
self.gcn_conv2 = GCNConv(hidden_size, out_feats)
def forward(self, x, adj):
x = self.gcn_conv1(x, adj)
x = F.relu(x)
x = self.gcn_conv2(x, adj)
return F.log_softmax(x, dim=1)
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = Planetoid("temp", name="Cora", transform=T.ToSparseTensor())
data = dataset[0].to(device)
model = GCN(in_feats=dataset.num_features,
hidden_size=16, out_feats=dataset.num_classes)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_acc, best_model = 0., None
model.train()
for epoch in range(600):
optimizer.zero_grad()
out = model(data.x, norm_adj(data.adj_t))
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
valid_acc = (out[data.val_mask].argmax(dim=1)
== data.y[data.val_mask]).sum()
if valid_acc > best_acc:
best_acc = valid_acc
best_model = deepcopy(model)
if (epoch + 1) % 50 == 0:
print(f"Epoch {
epoch + 1}: loss: {
loss.item()}")
loss.backward()
optimizer.step()
best_model.eval()
pred = best_model(data.x, norm_adj(data.adj_t)).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {
acc:.4f}')
""" Epoch 50: loss: 1.4066219329833984 Epoch 100: loss: 0.7072957754135132 Epoch 150: loss: 0.3014388084411621 Epoch 200: loss: 0.14514322578907013 Epoch 250: loss: 0.08141915500164032 Epoch 300: loss: 0.05128778889775276 Epoch 350: loss: 0.0351191945374012 Epoch 400: loss: 0.02553318254649639 Epoch 450: loss: 0.01940452679991722 Epoch 500: loss: 0.015253005549311638 Epoch 550: loss: 0.012309947051107883 Epoch 600: loss: 0.010146616026759148 Accuracy: 0.8090 """
Conclusion
Reference material :
The form of sparse matrix is very useful in large graphs , It can save more computing resources , At the same time, matrix multiplication is also more efficient . So if your GCN It can be expressed in the form of sparse matrix multiplication , It is a good idea to adopt this method .
The above is the whole content of this article , If you think it's good, just like it or pay attention to the blogger , Your support is the motivation for bloggers to continue their creation , Of course, if you have any questions, please criticize and correct !!!
边栏推荐
- yuv422转rgb(422sp转420p)
- PE格式: 分析IatHook并实现
- An interview question about interface and implementation in golang
- Six principles of C program design
- Qixin Jushi cloud spectrum new chapter | Haitai Fangyuan and Sichuan Unicom reach ecological strategic cooperation
- Autojs learning - file depth search
- Mysql8.0 MHA to achieve high availability "MHA"
- The onnx model is exported as a TRT model
- 性能调试 -- Chrome Performance
- Trusted and controllable way of Tencent cloud database
猜你喜欢

Huawei occupies half of the folding mobile phone market, proving its irreplaceable position in the high-end market

人脸与关键点检测:YOLO5Face实战

919. 完全二叉树插入器 : 简单 BFS 运用题

接口测试工具 restlet client

IJCAI2022开会了! 微软等《领域泛化Domain Generalization》教程

零基础学习CANoe Panel(17)—— Panel CAPL Function
Per capita Swiss number series, Swiss number 4 generation JS reverse analysis

Detailed explanation of JVM memory model and structure (five model diagrams)

MySQL master-slave configuration

Qixin Jushi cloud spectrum new chapter | Haitai Fangyuan and Sichuan Unicom reach ecological strategic cooperation
随机推荐
GDB locates the main address of the program after strip
An interview question about concurrent reading and writing of map in golang
作为测试,如何理解线程同步异步
Vivo official website app full model UI adaptation scheme
[database] conceptual design, logical design, relational database design theory
The inexplicability of Intel disassembly
I live far away. Is there a good way to open an account? Is it safe to open a stock account by mobile phone?
Record the transfer of domain names from Alibaba cloud service providers to Huawei cloud
Leetcode skimming -- guess the size of numbers II 375 medium
数据库sql语句练习题「建议收藏」
cuda_ error_ out_ of_ Memory (out of memory)
接口测试工具 restlet client
strcpy()
[ManageEngine] value brought by Siem to enterprises
5、 Pinda general permission system__ PD tools XXS (anti cross site script attack)
How to evaluate hardware resources (number of CPUs, memory size) when Oracle migrates from small computers to x86 architecture? Is there a measurement index or company?
Babbitt | metauniverse daily must read: the popularity of virtual people has decreased, and some "debut is the peak", and the onlookers have dispersed
Stm3 (cubeide) lighting experiment
租房二三事
ag 搜索工具参数详解