当前位置:网站首页>Princeton University, Peking University & UIUC | offline reinforcement learning with realizability and single strategy concentration
Princeton University, Peking University & UIUC | offline reinforcement learning with realizability and single strategy concentration
2022-07-06 03:12:00 【Zhiyuan community】

边栏推荐
- [ruoyi] set theme style
- Pat 1046 shortest distance (20 points) simulation
- Fault analysis | analysis of an example of MySQL running out of host memory
- How to choose PLC and MCU?
- SD卡报错“error -110 whilst initialising SD card
- Deep parsing pointer and array written test questions
- Game theory matlab
- Rust language -- iterators and closures
- Classic interview question [gem pirate]
- Precautions for single chip microcomputer anti reverse connection circuit
猜你喜欢
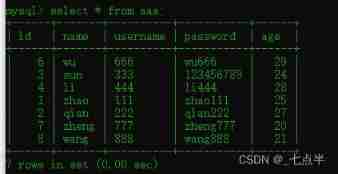
Mysql database operation
如何做好功能测试

Codeforces 5 questions par jour (1700 chacune) - jour 6
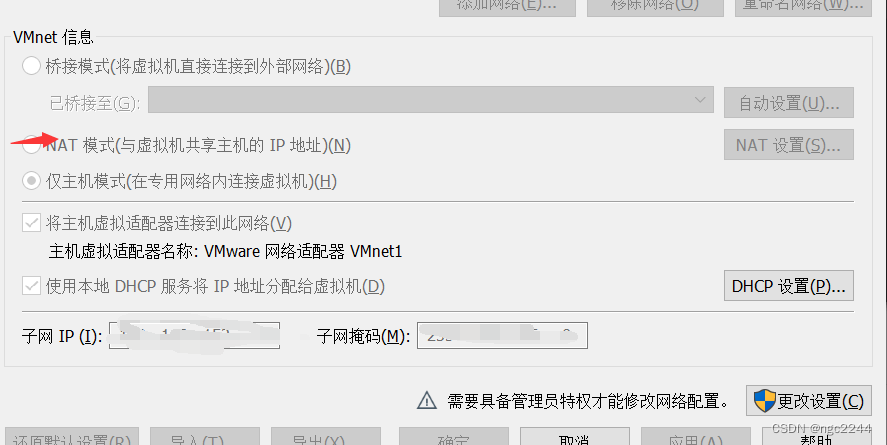
真机无法访问虚拟机的靶场,真机无法ping通虚拟机
![[Chongqing Guangdong education] higher mathematics I reference materials of Southwest Petroleum University](/img/0f/520242492524522c887b6576463566.jpg)
[Chongqing Guangdong education] higher mathematics I reference materials of Southwest Petroleum University
![[Yu Yue education] basic reference materials of digital electronic technology of Xi'an University of Technology](/img/47/e895a75eb3af2aaeafc6ae76caafe4.jpg)
[Yu Yue education] basic reference materials of digital electronic technology of Xi'an University of Technology
![[pointer training - eight questions]](/img/fd/1aa3937548a04078c4d7e08198c3a8.png)
[pointer training - eight questions]
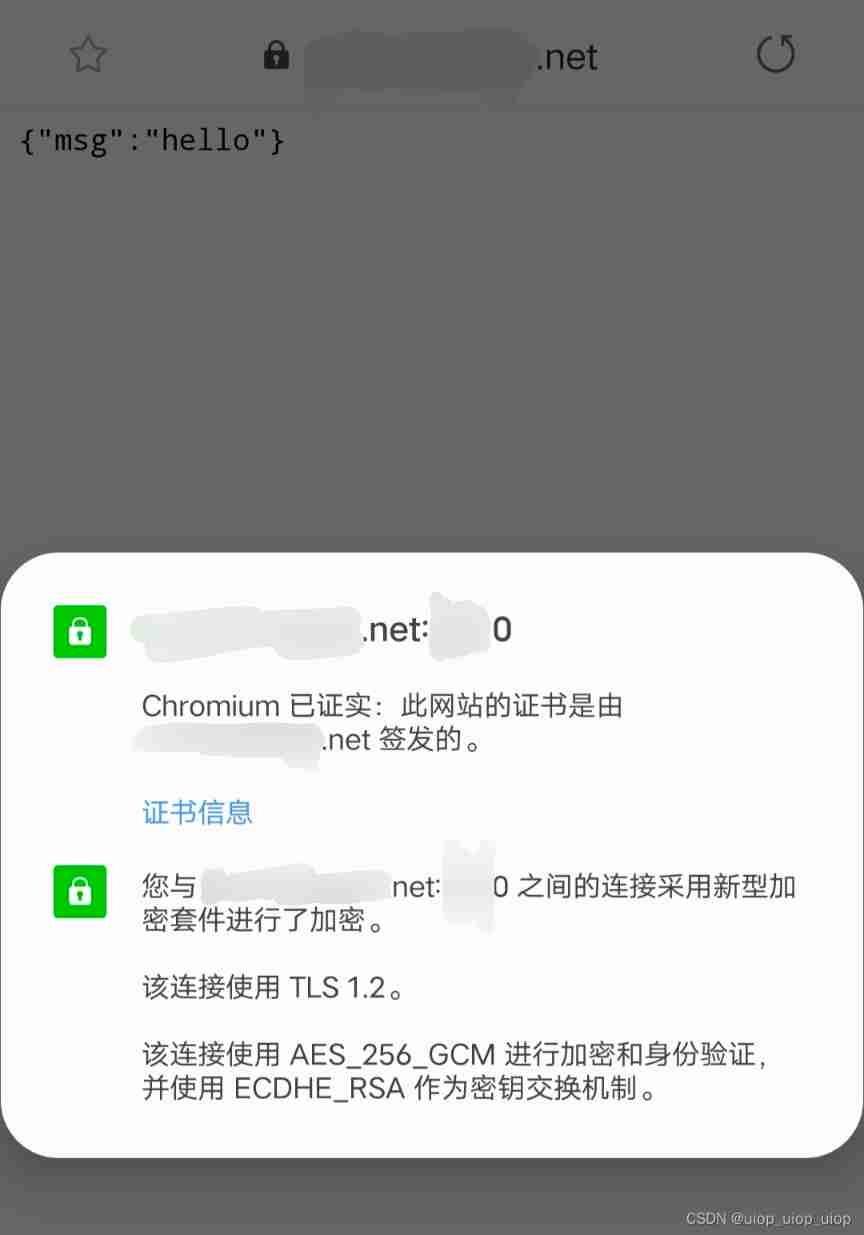
Sign SSL certificate as Ca
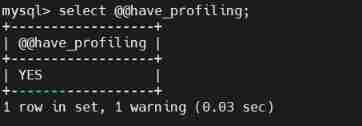
MySQL advanced notes
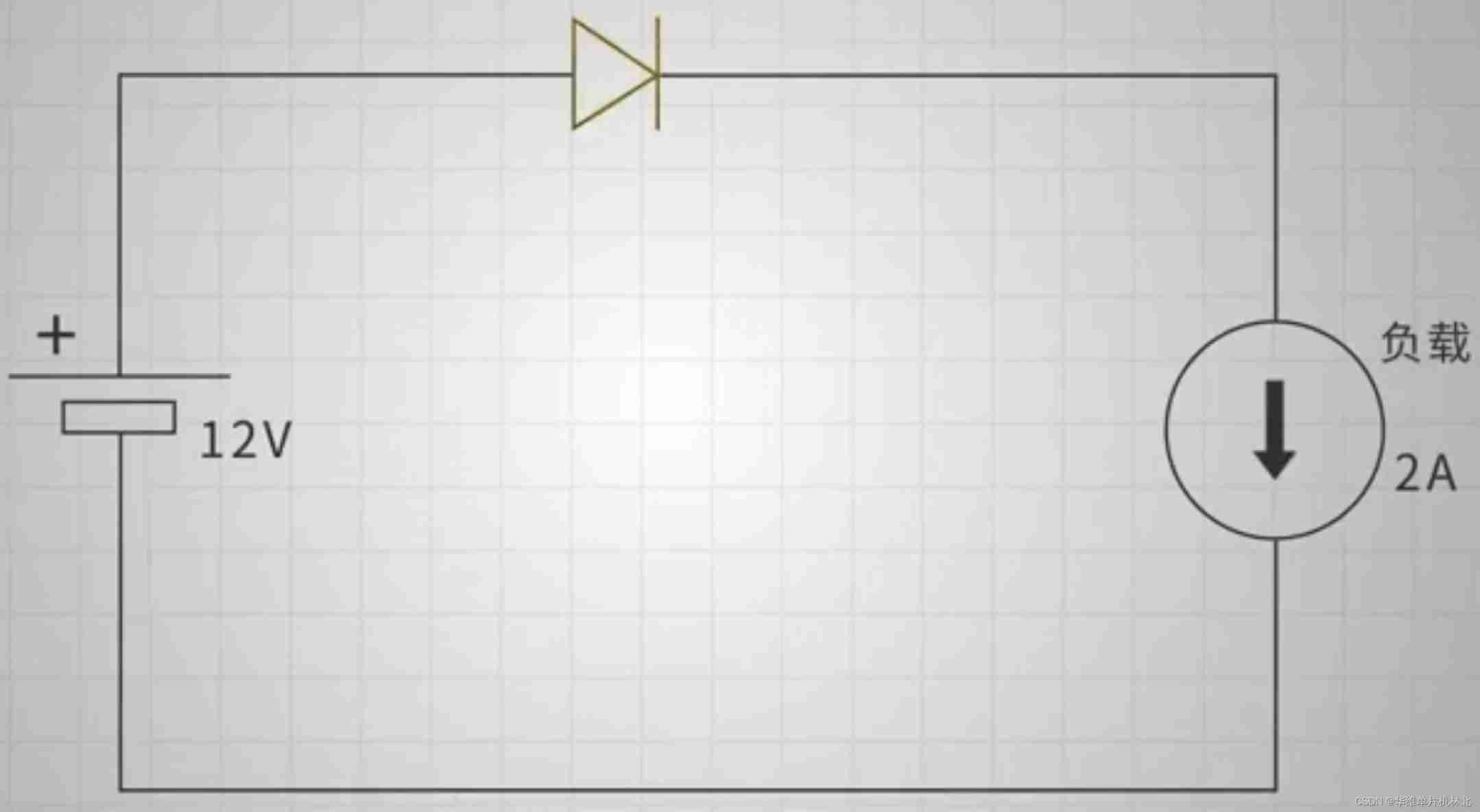
Precautions for single chip microcomputer anti reverse connection circuit

随机推荐
Leetcode problem solving -- 173 Binary search tree iterator
故障分析 | MySQL 耗尽主机内存一例分析
Apt installation ZABBIX
Some problem records of AGP gradle
Installation and use tutorial of cobaltstrike-4.4-k8 modified version
SD card reports an error "error -110 whilst initializing SD card
适合程序员学习的国外网站推荐
BUUCTF刷题笔记——[极客大挑战 2019]EasySQL 1
3857 Mercator coordinate system converted to 4326 (WGS84) longitude and latitude coordinates
Overview of OCR character recognition methods
银行核心业务系统性能测试方法
1003 emergency (25 points), "DIJ deformation"
Inherit day01
Custom attribute access__ getattribute__/ Settings__ setattr__/ Delete__ delattr__ method
Software design principles
What are the principles of software design (OCP)
Prototype design
Crazy, thousands of netizens are exploding the company's salary
[Li Kou] the second set of the 280 Li Kou weekly match
Data and Introspection__ dict__ Attributes and__ slots__ attribute