当前位置:网站首页>系统与应用监控的思路和方法
系统与应用监控的思路和方法
2022-07-06 12:03:00 【Impl_Sunny】
0、前言
在实际的性能分析中,一个很常见的现象是,明明发生了性能瓶颈,但当你登录到服务器中想要排查的时候,却发现瓶颈已经消失了。或者说,性能问题总是时不时地发生,但却很难找出发生规律,也很难重现。
而要解决这个问题,就要搭建监控系统,把系统和应用程序的运行状况监控起来,并定义一系列的策略,在发生问题时第一时间告警通知。一个好的监控系统,不仅可以实时暴露系统的各种问题,更可以根据这些监控到的状态,自动分析和定位大致的瓶颈来源,从而更精确地把问题汇报给相关团队处理。要做好监控,最核心的就是全面的、可量化的指标,这包括系统和应用两个方面。
从系统来说,监控系统要涵盖系统的整体资源使用情况,比如 CPU、内存、磁盘和文件系统、网络等各种系统资源。
而从应用程序来说,监控系统要涵盖应用程序内部的运行状态,这既包括进程的 CPU、磁盘 I/O 等整体运行状况,更需要包括诸如接口调用耗时、执行过程中的错误、内部对象的内存使用等应用程序内部的运行状况。
一、系统监控
1.1 USE法
在开始监控系统之前,你肯定最想知道,怎么才能用简洁的方法,来描述系统资源的使用情况。你当然可以使用专栏中学到的各种性能工具,来分别收集各种资源的使用情况。不过不要忘记,每种资源的性能指标可都有很多,使用过多指标本身耗时耗力不说,也不容易为你建立起系统整体的运行状况。
在这里,我为你介绍一种专门用于性能监控的 USE(Utilization Saturation and Errors)法。
USE 法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数:
- 使用率:表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。
- 饱和度:表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。
- 错误数:表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
这三个类别的指标,涵盖了系统资源的常见性能瓶颈,所以常被用来快速定位系统资源的性能瓶颈。这样,无论是对 CPU、内存、磁盘和文件系统、网络等硬件资源,还是对文件描述符数、连接数、连接跟踪数等软件资源,USE 方法都可以帮你快速定位出,是哪一种系统资源出现了性能瓶颈。
1.2 性能指标
以下是常见的性能指标:
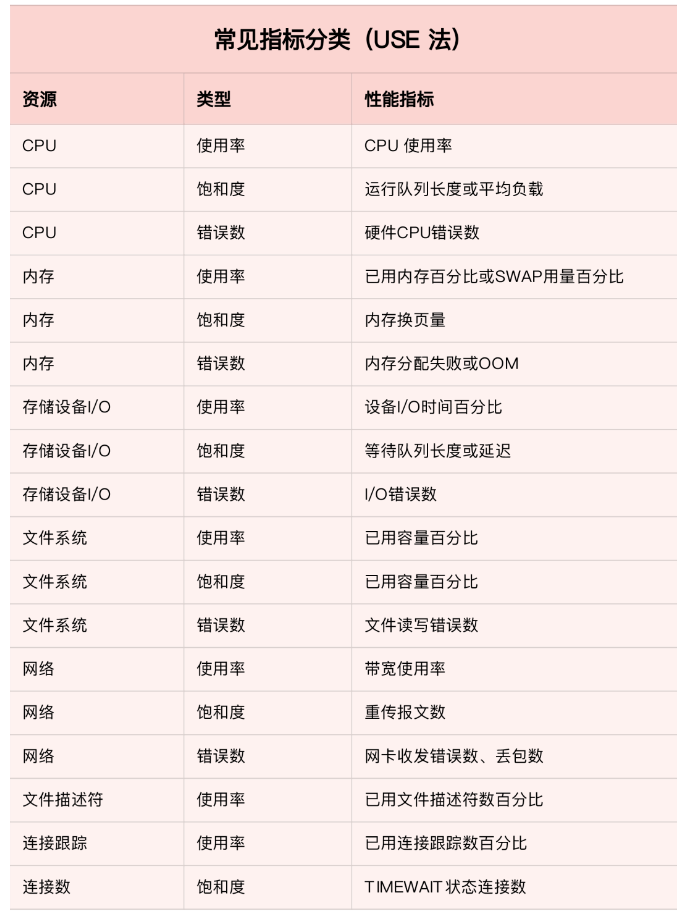
注意:USE 方法只关注能体现系统资源性能瓶颈的核心指标,但这并不是说其他指标不重要。诸如系统日志、进程资源使用量、缓存使用量等其他各类指标,也都需要我们监控起来。只不过,它们通常用作辅助性能分析,而 USE 方法的指标,则直接表明了系统的资源瓶颈。
1.3 监控系统
掌握 USE 方法以及需要监控的性能指标后,接下来要做的,就是建立监控系统,把这些指标保存下来;然后,根据这些监控到的状态,自动分析和定位大致的瓶颈来源;最后,再通过告警系统,把问题及时汇报给相关团队处理。一个完整的监控系统通常由数据采集、数据存储、数据查询和处理、告警以及可视化展示等多个模块组成。所以,要从头搭建一个监控系统,其实也是一个很大的系统工程。
搭建监控系统可参考方案:
1.4 小结
系统监控的核心是资源的使用情况,这既包括 CPU、内存、磁盘、文件系统、网络等硬件资源,也包括文件描述符数、连接数、连接跟踪数等软件资源。而要描述这些资源瓶颈,最简单有效的方法就是 USE 法。
USE 法把系统资源的性能指标,简化为了三个类别:使用率、饱和度以及错误数。当这三者之中任一类别的指标过高时,都代表相对应的系统资源可能存在性能瓶颈。
基于 USE 法建立性能指标后,我们还需要通过一套完整的监控系统,把这些指标从采集、存储、查询、处理,再到告警和可视化展示等贯穿起来。这样,不仅可以将系统资源的瓶颈快速暴露出来,还可以借助监控的历史数据,来追踪定位性能问题的根源。
二、应用监控
2.1 应用监控指标
跟系统监控一样,在构建应用程序的监控系统之前,首先也需要确定,到底需要监控哪些指标。特别是要清楚,有哪些指标可以用来快速确认应用程序的性能问题。
2.1.1 核心指标
应用程序的核心指标,不再是资源的使用情况,而是请求数、错误率和响应时间。
这些指标不仅直接关系到用户的使用体验,还反映应用整体的可用性和可靠性。有了请求数、错误率和响应时间这三个黄金指标之后,我们就可以快速知道,应用是否发生了性能问题。
请求书、响应时间的详情,可参考:【参数】一文搞清楚QPS、TPS、并发用户数、吞吐量
2.1.2 性能评估指标
虽然通过核心指标可以知道应用发生问题,但是,只有这些指标显然还是不够的,因为发生性能问题后,我们还希望能够快速定位“性能瓶颈区”。所以,在我看来,下面几种指标,也是监控应用程序时必不可少的:
应用进程的资源使用情况:
- 描述:比如进程占用的 CPU、内存、磁盘 I/O、网络等。使用过多的系统资源,导致应用程序响应缓慢或者错误数升高,是一个最常见的性能问题。
- 作用:可以把系统资源的瓶颈跟应用程序关联起来,从而迅速定位因系统资源不足而导致的性能问题
应用程序之间调用情况:
- 描述:比如调用频率、错误数、延时等。由于应用程序并不是孤立的,如果其依赖的其他应用出现了性能问题,应用自身性能也会受到影响。
- 作用:可以迅速分析出一个请求处理的调用链中,到底哪个组件才是导致性能问题的罪魁祸首
应用程序内部核心逻辑的运行情况:
- 描述:比如关键环节的耗时以及执行过程中的错误等。由于这是应用程序内部的状态,从外部通常无法直接获取到详细的性能数据。
- 作用:可以更进一步,直接进入应用程序的内部,定位到底是哪个处理环节的函数导致了性能问题。
基于这些思路,我相信你就可以构建出,描述应用程序运行状态的性能指标。再将这些指标纳入到监控系统(比如 Prometheus + Grafana)中,就可以跟系统监控一样,一方面通过告警系统,把问题及时汇报给相关团队处理;另一方面,通过直观的图形界面,动态展示应用程序的整体性能。
2.2 全链路监控
业务系统通常会涉及到一连串的多个服务,形成一个复杂的分布式调用链。为了迅速定位这类跨应用的性能瓶颈,你还可以使用 skywalking、Zipkin、Jaeger、Pinpoint 等各类开源工具,来构建全链路跟踪系统。
全链路跟踪可以帮你迅速定位出,在一个请求处理过程中,哪个环节才是问题根源。
全链路跟踪除了可以帮你快速定位跨应用的性能问题外,还可以帮你生成线上系统的调用拓扑图。这些直观的拓扑图,在分析复杂系统(比如微服务)时尤其有效。
2.3 日志监控
性能指标的监控,可以让你迅速定位发生瓶颈的位置,不过只有指标的话往往还不够。比如,同样的一个接口,当请求传入的参数不同时,就可能会导致完全不同的性能问题。所以,除了指标外,我们还需要对这些指标的上下文信息进行监控,而日志正是这些上下文的最佳来源。
对比来看,指标是特定时间段的数值型测量数据,通常以时间序列的方式处理,适合于实时监控。
而日志则完全不同,日志都是某个时间点的字符串消息,通常需要对搜索引擎进行索引后,才能进行查询和汇总分析。
对日志监控来说,最经典的方法,就是使用 ELK 技术栈,即使用 Elasticsearch、Logstash 和 Kibana 这三个组件的组合。如下图所示,经典的 ELK 架构图:

- Logstash :负责对从各个日志源采集日志,然后进行预处理,最后再把初步处理过的日志,发送给 Elasticsearch 进行索引。
- Elasticsearch :负责对日志进行索引,并提供了一个完整的全文搜索引擎,这样就可以方便你从日志中检索需要的数据。
- Kibana :负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示等。
下面这张图,就是一个 Kibana 仪表板的示例,它直观展示了 Apache 的访问概况。

注意:ELK 技术栈中的 Logstash 资源消耗比较大。所以,在资源紧张的环境中,我们往往使用资源消耗更低的 Fluentd,来替代 Logstash(也就是所谓的 EFK 技术栈)。
2.4 小结
应用程序的监控,可以分为指标监控和日志监控两大部分:
- 指标监控:主要是对一定时间段内性能指标进行测量,然后再通过时间序列的方式,进行处理、存储和告警。
- 日志监控:可以提供更详细的上下文信息,通常通过 ELK 技术栈来进行收集、索引和图形化展示。
在跨多个不同应用的复杂业务场景中,你还可以构建全链路跟踪系统。这样可以动态跟踪调用链中各个组件的性能,生成整个流程的调用拓扑图,从而加快定位复杂应用的性能问题。
参考资料:
边栏推荐
- Lick the dog until the last one has nothing (simple DP)
- Leetcode brush first_ Maximum Subarray
- Transformer model (pytorch code explanation)
- Learn to explore - use pseudo elements to clear the high collapse caused by floating elements
- 腾讯Android面试必问,10年Android开发经验
- Appx代码签名指南
- How to customize animation avatars? These six free online cartoon avatar generators are exciting at a glance!
- Mysql Information Schema 學習(一)--通用錶
- Wonderful coding [hexadecimal conversion]
- 颜色(color)转换为三刺激值(r/g/b)(干股)
猜你喜欢
LeetCode_双指针_中等_61. 旋转链表
深度剖析原理,看完这一篇就够了
Pay attention to the partners on the recruitment website of fishing! The monitoring system may have set you as "high risk of leaving"
In simple terms, interview surprise Edition

Tencent Android interview must ask, 10 years of Android development experience
Vscode debug run fluent message: there is no extension for debugging yaml. Should we find yaml extensions in the market?
手把手教你学会js的原型与原型链,猴子都能看懂的教程
腾讯T2大牛亲自讲解,跳槽薪资翻倍
After solving 2961 user feedback, I made such a change
面试突击63:MySQL 中如何去重?
随机推荐
js实现力扣71题简化路径
Learning and Exploration - Seamless rotation map
从sparse.csc.csr_matrix生成邻接矩阵
Carte de réflexion + code source + notes + projet, saut d'octets + jd + 360 + tri des questions d'entrevue Netease
Example of applying fonts to flutter
HDU 1026 Ignatius and the Princess I 迷宫范围内的搜索剪枝问题
Speech recognition (ASR) paper selection: talcs: an open source Mandarin English code switching corps and a speech
Recursive implementation of department tree
[translation] Digital insider. Selection process of kubecon + cloudnativecon in Europe in 2022
转让malloc()该功能后,发生了什么事内核?附malloc()和free()实现源
Dom 操作
PowerPivot——DAX(初识)
腾讯云数据库公有云市场稳居TOP 2!
Application of clock wheel in RPC
POJ1149 PIGS 【最大流量】
LeetCode_双指针_中等_61. 旋转链表
深入浅出,面试突击版
String长度限制?
[玩转Linux] [Docker] MySQL安装和配置
mod_wsgi + pymssql通路SQL Server座