当前位置:网站首页>Speech recognition (ASR) paper selection: talcs: an open source Mandarin English code switching corps and a speech
Speech recognition (ASR) paper selection: talcs: an open source Mandarin English code switching corps and a speech
2022-07-06 19:49:00 【My name is Yongqiang】
Statement : Usually read some articles, take some notes and share them , There are inevitably mistakes in the article , I hope you will have a better understanding of Haihan . Collect some information , It's easy to check and learn :http://yqli.tech/page/speech.html. For a list of papers in the field of speech synthesis, please visit http://yqli.tech/page/tts_paper.html, For the statistics of papers in the field of speech recognition, please visit http://yqli.tech/page/asr_paper.html. How to find voice information, please refer to the article https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg). If reproduced , Please indicate the source . Welcome to WeChat official account. : Keep a low profile .
TALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
This article is tal in 2022.06.27 Updated articles , Mainly open source the largest Chinese English mixed training corpus , For speech recognition Code-switching Contribute to research .
( Open source data statistics can be found in http://yqli.tech/page/data.html)
Because the main work of this paper is to open source the world's largest Chinese English mixed data , We will not introduce the background , View the data set directly . This data set is the audio of Tal English class , Including mixed Chinese and English speech , There is only one speaker per audio , The dataset has 100 More speakers .( file 63.36G) The data includes the following figure 1 Examples of intrasentence and inter sentence mixing shown . The ratio between Chinese characters and English words in this data is 13:1, among top 20 Pictured 2 Shown .table 1 It shows the division of the training set and test set of the corpus ,table 2 Show how to use this data set in espnet and wenet The results of the experiment on .
| Data scale | 587 Hour audio |
| Sampling rate | 16KHz |
| Sampling bit sound | 16bit |
| Recording devices | Ordinary microphone |
| The speaker | 200+ |
| Recording time | 2019 year |
| data format | Audio :.wav; Mark the results :.txt |
| Audio length | 1~60s |
| data type | English teacher's audio |



边栏推荐
猜你喜欢

Standardized QCI characteristics
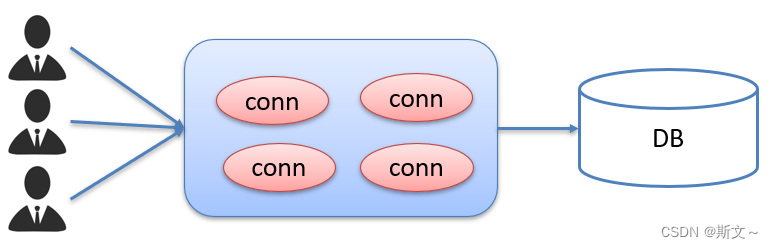
Druid database connection pool details
腾讯T2大牛亲自讲解,跳槽薪资翻倍

Live broadcast today | the 2022 Hongji ecological partnership conference of "Renji collaboration has come" is ready to go
算法面试经典100题,Android程序员最新职业规划

Tencent Android interview must ask, 10 years of Android development experience

Social recruitment interview experience, 2022 latest Android high-frequency selected interview questions sharing
It's enough to read this article to analyze the principle in depth
学习打卡web
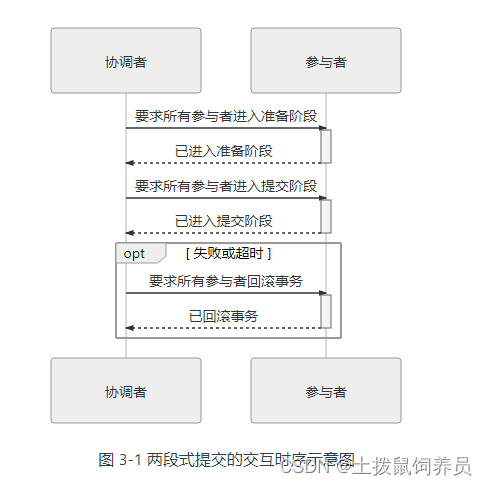
凤凰架构3——事务处理
随机推荐
【翻译】Linkerd在欧洲和北美的采用率超过了Istio,2021年增长118%。
Social recruitment interview experience, 2022 latest Android high-frequency selected interview questions sharing
leetcode先刷_Maximum Subarray
腾讯Android面试必问,10年Android开发经验
精彩编码 【进制转换】
Pay attention to the partners on the recruitment website of fishing! The monitoring system may have set you as "high risk of leaving"
PowerPivot——DAX(初识)
腾讯T3大牛手把手教你,大厂内部资料
技术分享 | 抓包分析 TCP 协议
Swiftui game source code Encyclopedia of Snake game based on geometryreader and preference
MySql必知必会学习
Spark foundation -scala
Druid database connection pool details
学习探索-无缝轮播图
Web开发小妙招:巧用ThreadLocal规避层层传值
Unbalance balance (dynamic programming, DP)
Tensorflow2.0 自定义训练的方式求解函数系数
Leetcode brush first_ Maximum Subarray
Carte de réflexion + code source + notes + projet, saut d'octets + jd + 360 + tri des questions d'entrevue Netease
10 schemes to ensure interface data security