当前位置:网站首页>Interview assault 63: how to remove duplication in MySQL?
Interview assault 63: how to remove duplication in MySQL?
2022-07-06 19:28:00 【Wang Lei】
stay MySQL in , There are two most common methods of weight removal : Use distinct Or use group by, What's the difference between them ? Let's take a look at .
1. Create test data
-- Create test table
drop table if exists pageview;
create table pageview(
id bigint primary key auto_increment comment ' Since the primary key ',
aid bigint not null comment ' article ID',
uid bigint not null comment '( visit ) user ID',
createtime datetime default now() comment ' Creation time '
) default charset='utf8mb4';
-- Add test data
insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(2,1);
insert into pageview(aid,uid) values(2,2);
The final display effect is as follows : 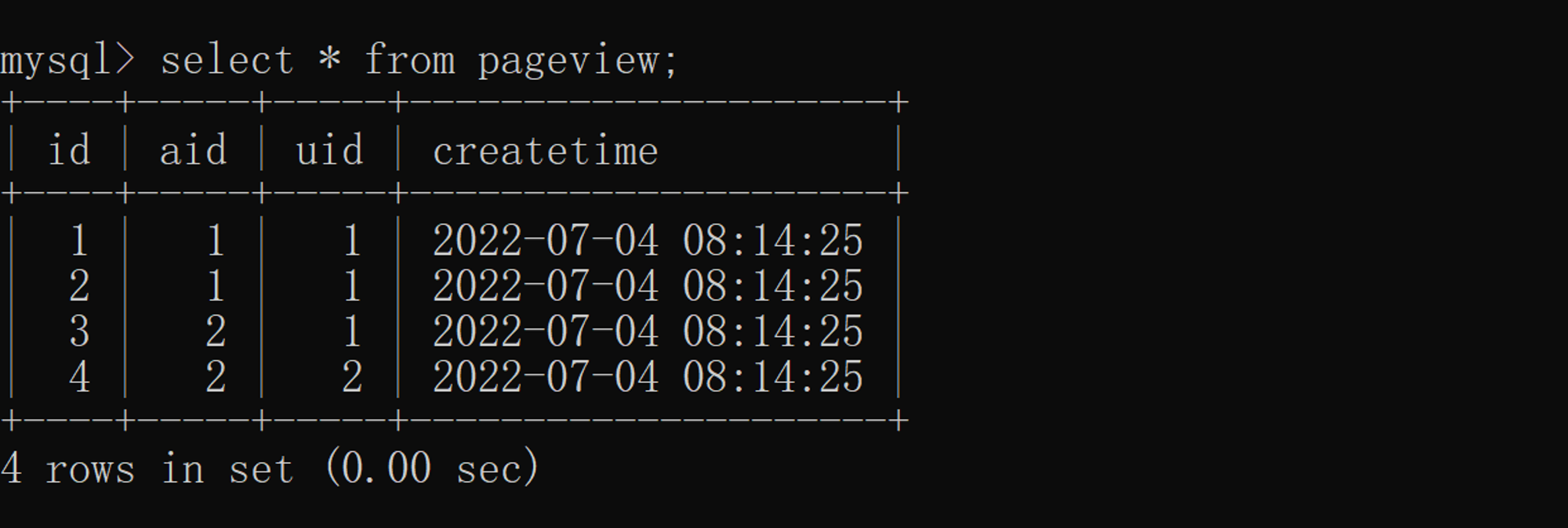
2.distinct Use
distinct The basic grammar is as follows :
SELECT DISTINCT column_name,column_name FROM table_name;
2.1 Separate the heavy ones
We use first distinct Realize single column weight removal , according to aid( article ID) duplicate removal , The specific implementation is as follows : 
2.2 More than one, more than one
In addition to single train weight removal ,distinct It also supports multiple columns ( Two or more trains ) duplicate removal , We according to the aid( article ID) and uid( user ID) Combined weightlessness , The specific implementation is as follows : 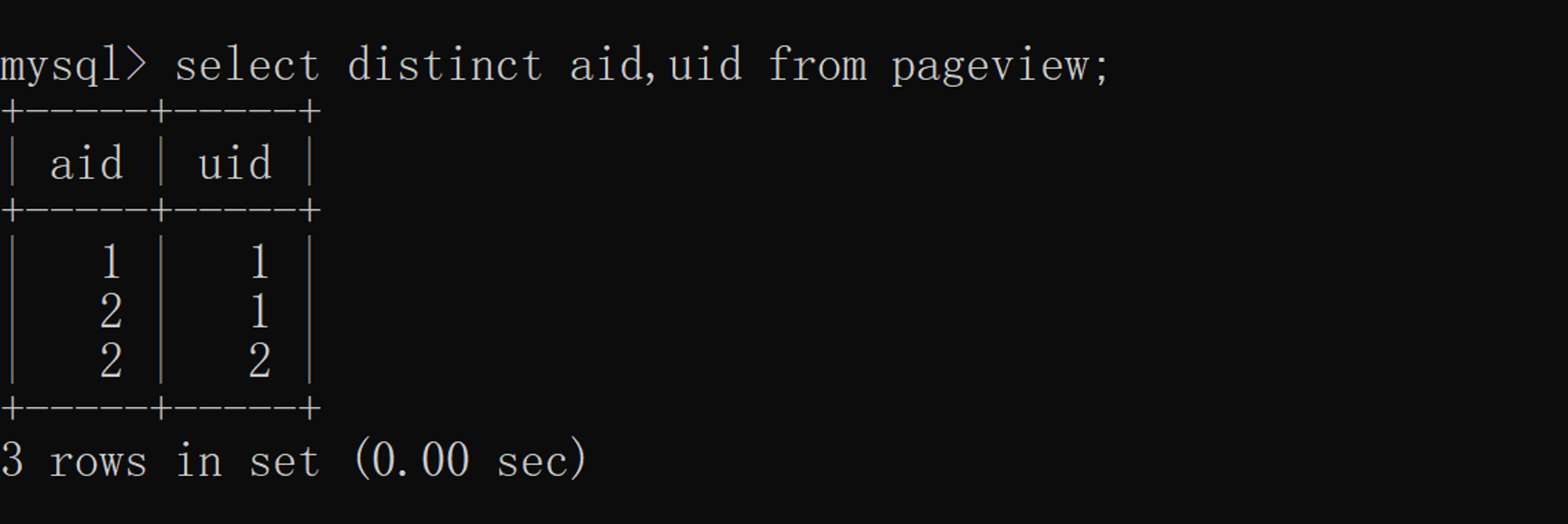
2.3 Aggregate functions + duplicate removal
Use distinct + Aggregate function de duplication , Calculation aid Total number of strips after weight removal , The specific implementation is as follows : 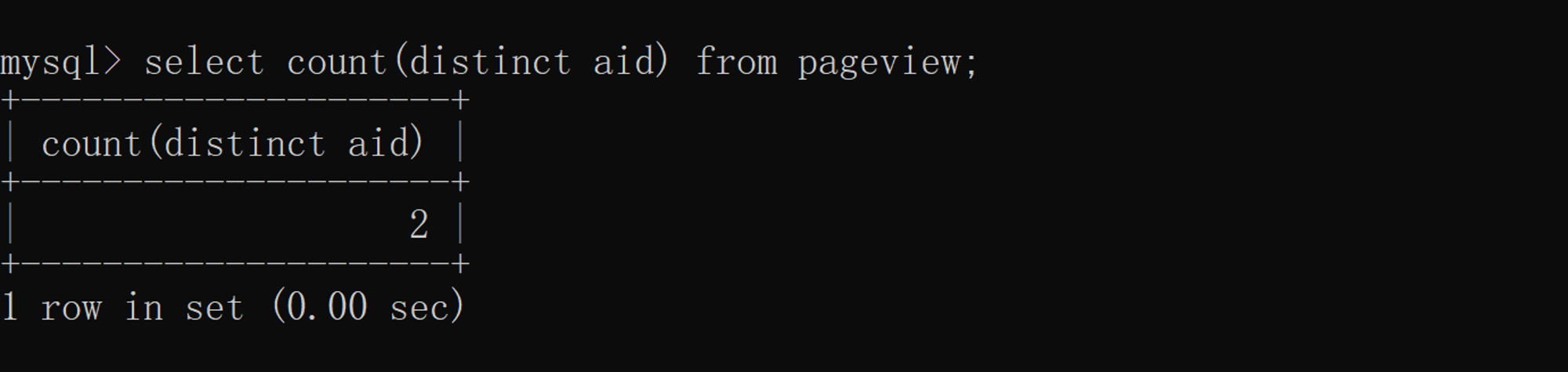
3.group by Use
group by The basic grammar is as follows :
SELECT column_name,column_name FROM table_name
WHERE column_name operator value
GROUP BY column_name
3.1 Separate the heavy ones
according to aid( article ID) duplicate removal , The specific implementation is as follows : 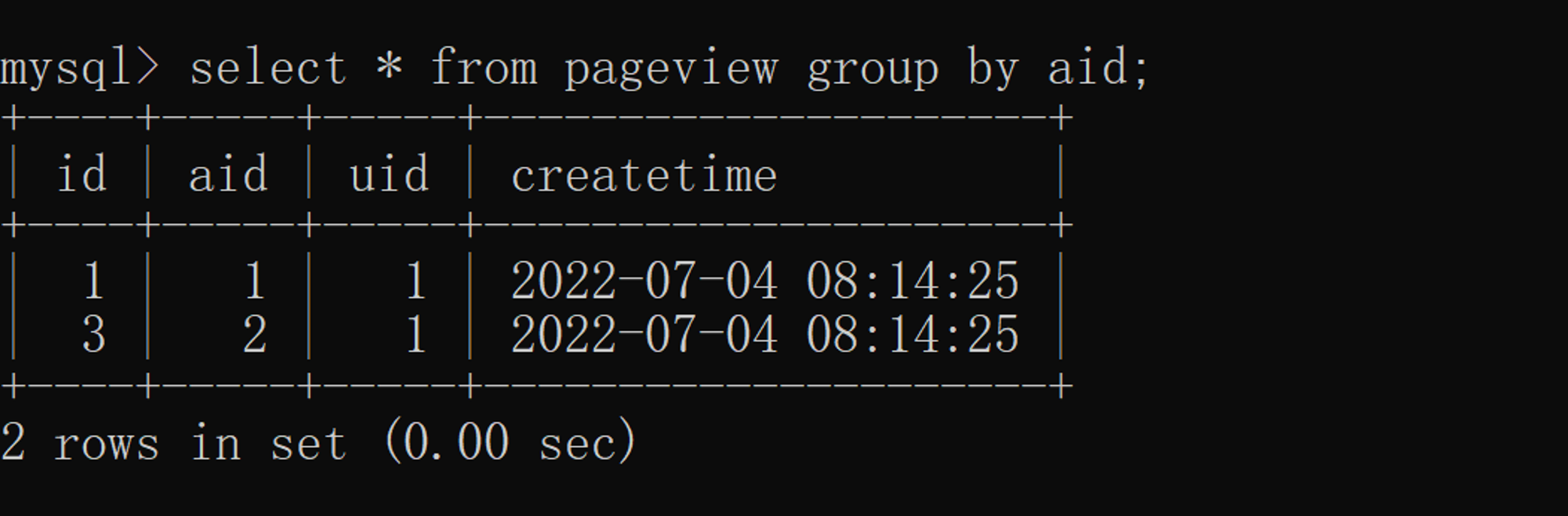 And distinct comparison group by More columns can be displayed , and distinct Only the de duplicated columns can be displayed .
And distinct comparison group by More columns can be displayed , and distinct Only the de duplicated columns can be displayed .
3.2 More than one, more than one
according to aid( article ID) and uid( user ID) Combined weightlessness , The specific implementation is as follows : 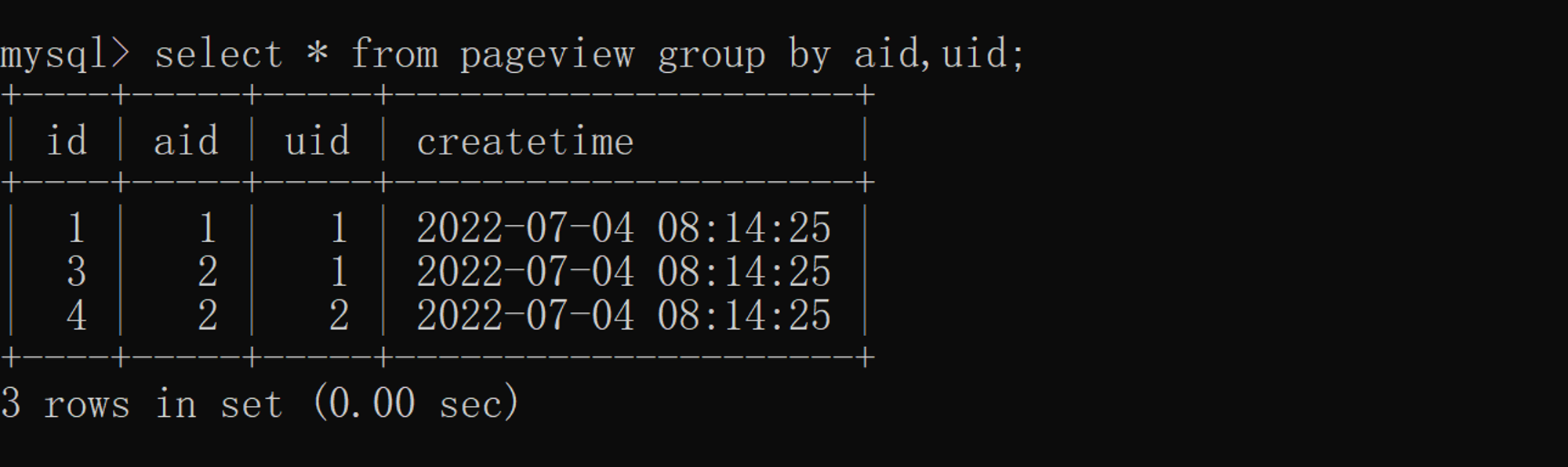
3.3 Aggregate functions + group by
Count each one aid Total quantity ,SQL The implementation is as follows : 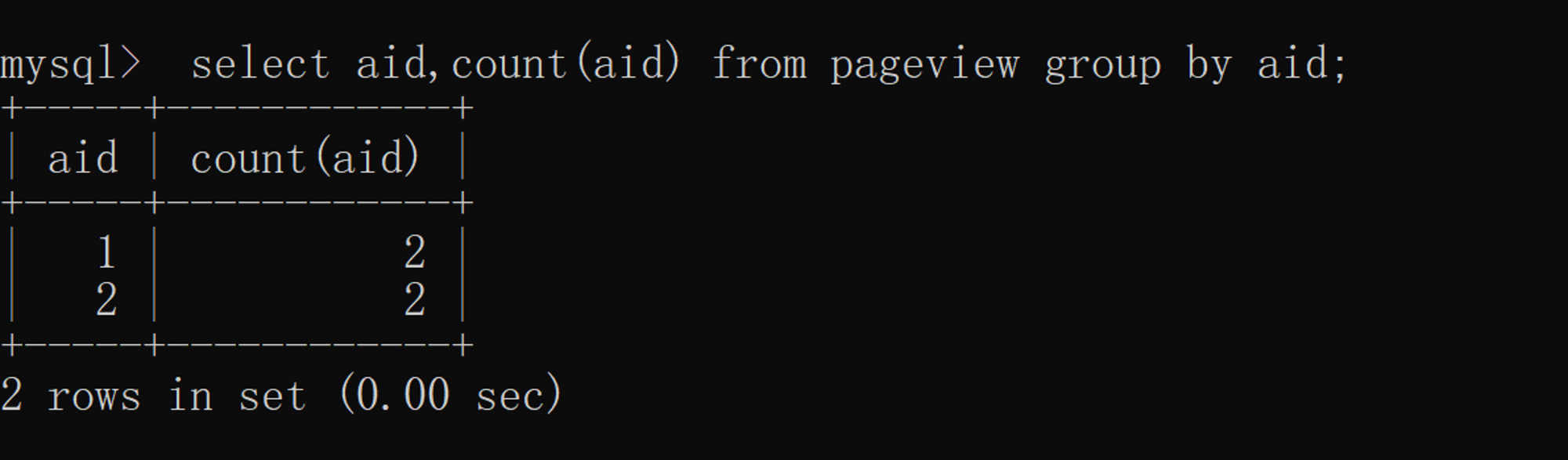 As can be seen from the above results , Use group by and distinct Add count The query semantics of is completely different ,distinct + count It counts the total quantity after weight removal , and group by + count Statistics are the total number of each group of data after grouping .
As can be seen from the above results , Use group by and distinct Add count The query semantics of is completely different ,distinct + count It counts the total quantity after weight removal , and group by + count Statistics are the total number of each group of data after grouping .
4.distinct and group by The difference between
Official documents describe distinct When it comes to : in the majority of cases distinct It's special group by, As shown in the figure below :  Official document address :https://dev.mysql.com/doc/refman/8.0/en/distinct-optimization.html But there are still some subtle differences between the two , For example, the following .
Official document address :https://dev.mysql.com/doc/refman/8.0/en/distinct-optimization.html But there are still some subtle differences between the two , For example, the following .
difference 1: The query result set is different
When using distinct When you go to heavy duty , In the query result set, only the de duplication information , As shown in the figure below :  When you try to add a non de duplication field ( Inquire about ) when ,SQL An error will be reported, as shown in the figure below :
When you try to add a non de duplication field ( Inquire about ) when ,SQL An error will be reported, as shown in the figure below :  While using group by Sorting can query one or more fields , As shown in the figure below :
While using group by Sorting can query one or more fields , As shown in the figure below : 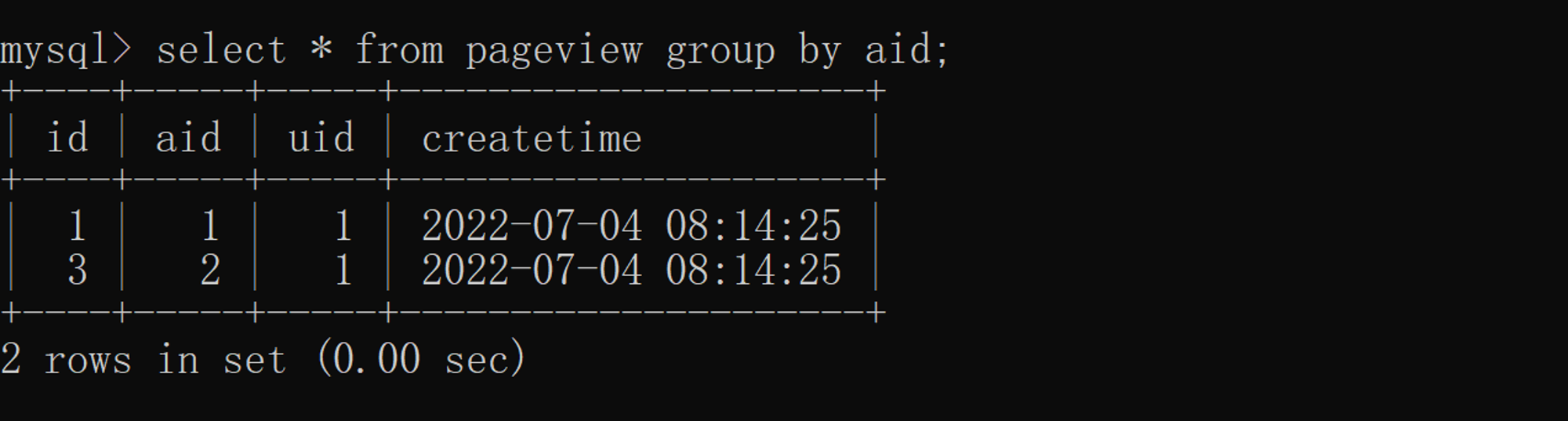
difference 2: Different business scenarios
To count the total quantity after weight removal, you need to use distinct, And statistical grouping details , Or when adding query criteria on the basis of grouping details , You have to use group by 了 . Use distinct Count the total quantity of a column after weight removal : 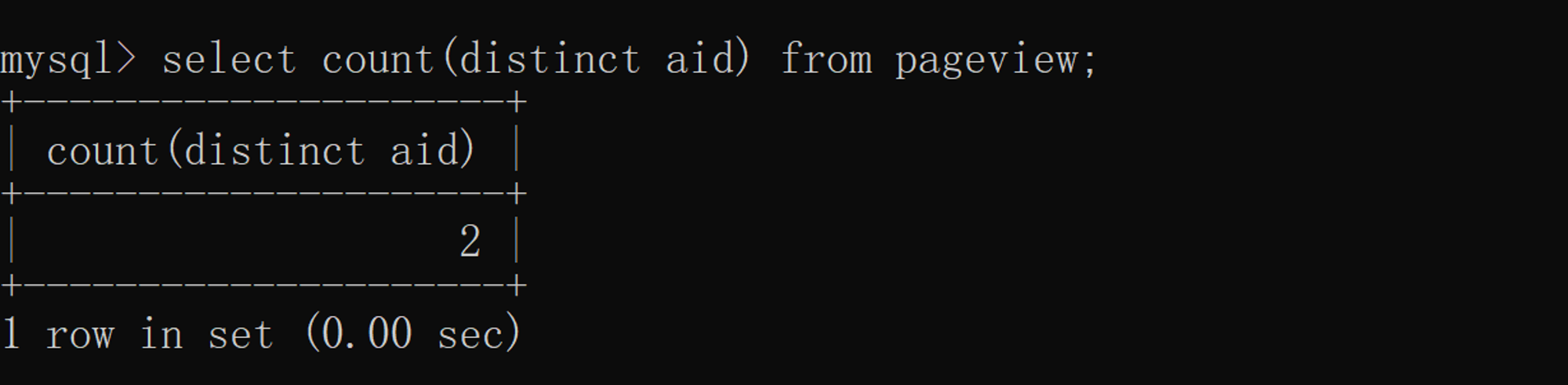 The number after statistical grouping is greater than 2 The article , Then use group by 了 , As shown in the figure below :
The number after statistical grouping is greater than 2 The article , Then use group by 了 , As shown in the figure below : 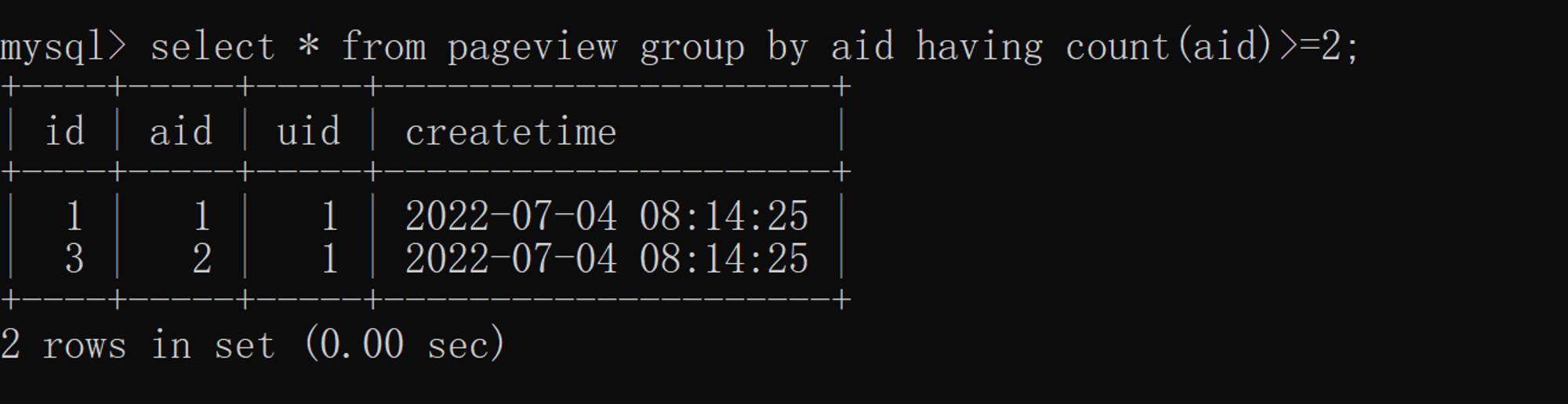
difference 3: Different performance
If the de duplicated field has an index , that group by and distinct You can use indexes , In this case, their performance is the same ; and When the de duplicated field has no index ,distinct Performance will be higher than group by, Because in MySQL 8.0 Before ,group by There is a hidden function that will sort by default , This will trigger filesort This leads to reduced query performance .
summary
In most scenes distinct It's special group by, But there are subtle differences between the two , For example, they are on the query result set 、 Specific business scenarios used , And the performance is different .
Reference resources & Acknowledgement
zhuanlan.zhihu.com/p/384840662
It's up to you to judge right and wrong , Disdain is to listen to people , Gain or loss is more important than number .
official account :Java Analysis of the real interview questions
Interview collection :https://gitee.com/mydb/interview
边栏推荐
猜你喜欢
How to access localhost:8000 by mobile phone
Word如何显示修改痕迹
LeetCode-1279. 红绿灯路口

Dark horse -- redis
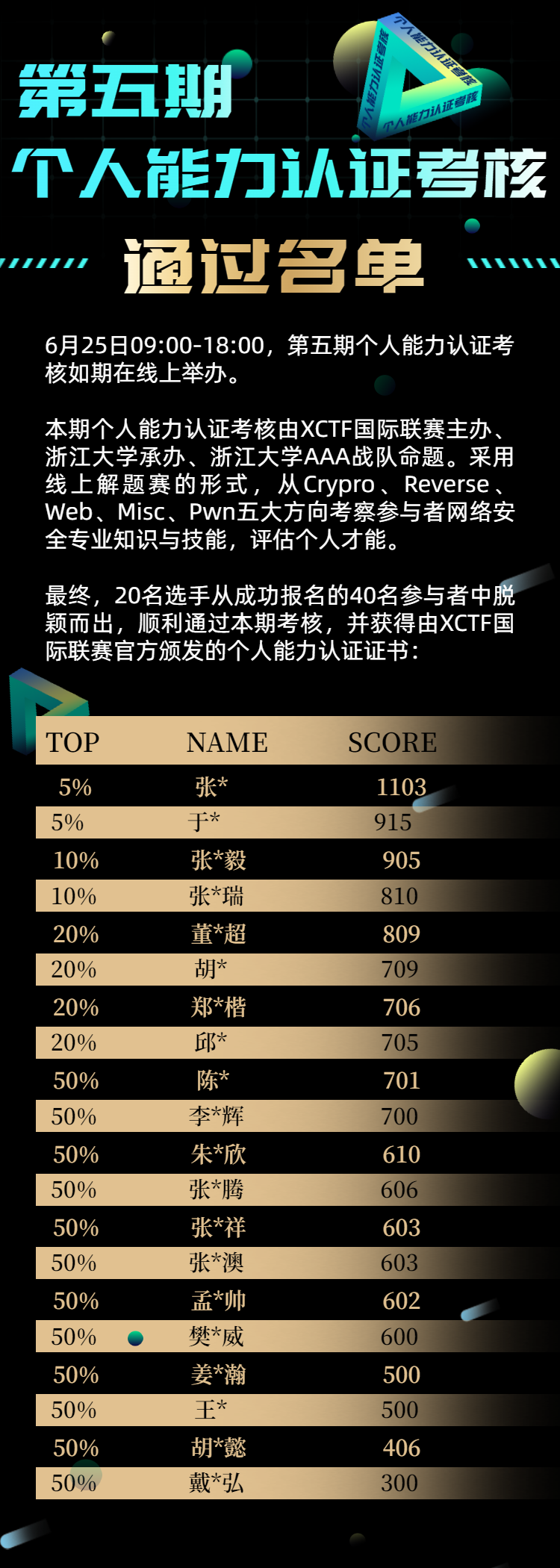
第五期个人能力认证考核通过名单公布
Zero foundation entry polardb-x: build a highly available system and link the big data screen
Interface test tool - postman
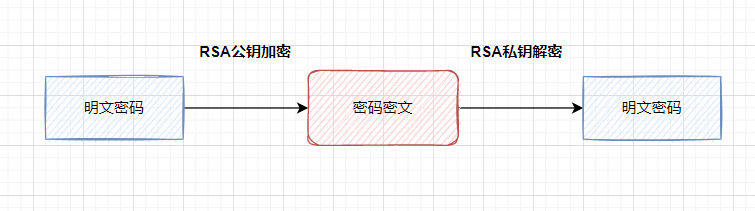
保证接口数据安全的10种方案

Help improve the professional quality of safety talents | the first stage of personal ability certification and assessment has been successfully completed!
如何自定义动漫头像?这6个免费精品在线卡通头像生成器,看一眼就怦然心动!
随机推荐
Modulenotfounderror: no module named 'PIL' solution
R语言ggplot2可视化:使用ggpubr包的ggdotplot函数可视化点阵图(dot plot)、设置palette参数设置不同水平点阵图数据点和箱图的颜色
An error occurs when installing MySQL: could not create or access the registry key needed for the
Use of deg2rad and rad2deg functions in MATLAB
主从搭建报错:The slave I/O thread stops because master and slave have equal MySQL serv
JDBC详解
swagger2报错Illegal DefaultValue null for parameter type integer
Interface test tool - postman
A method of removing text blur based on pixel repair
五金机电行业供应商智慧管理平台解决方案:优化供应链管理,带动企业业绩增长
LeetCode-1279. Traffic light intersection
关于图像的读取及处理等
学习探索-函数防抖
First day of rhcsa study
RT-Thread 组件 FinSH 使用时遇到的问题
快速幂模板求逆元,逆元的作用以及例题【第20届上海大学程序设计联赛夏季赛】排列计数
10 schemes to ensure interface data security
Translation D28 (with AC code POJ 26:the nearest number)
Test technology stack arrangement -- self cultivation of test development engineers
思維導圖+源代碼+筆記+項目,字節跳動+京東+360+網易面試題整理