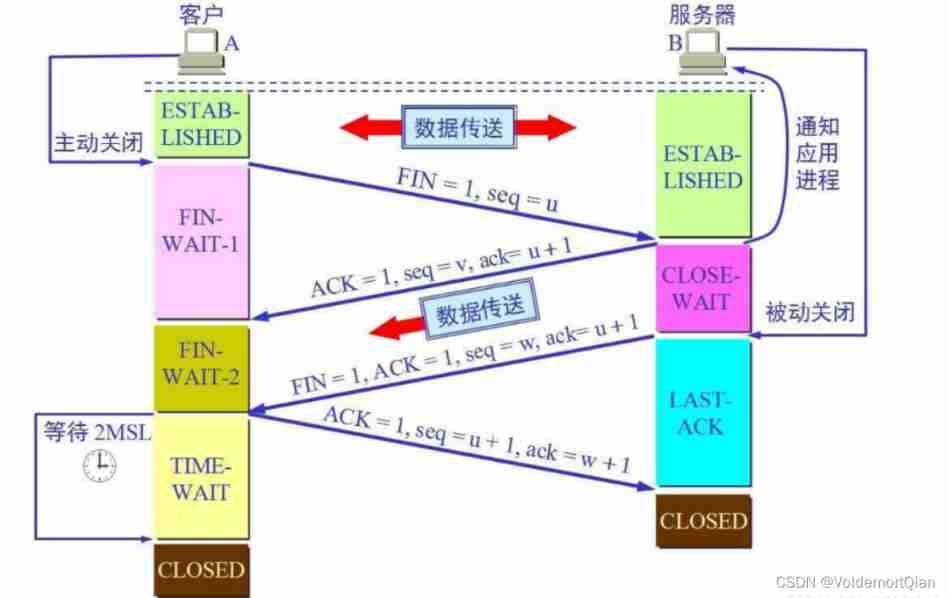
一、PolarDB-X 简介
PolarDB-X 是一款面向超高并发、海量存储、复杂查询场景设计的云原生分布式数据库系统。其采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,具备企业级、云原生、高可用、高度兼容 MySQL 系统及生态等特点。
PolarDB-X 最初为解决阿里巴巴天猫“双十一”核心交易系统数据库扩展性瓶颈而生,之后伴随阿里云一路成长,是一款经过多种核心业务场景验证的、成熟稳定的数据库系统。
二、PolarDB-X的核心特性
- 水平扩展
PolarDB-X 采用 Shared-nothing 架构进行设计,支持多种 Hash 和 Range 数据拆分算法,通过隐式主键拆分和数据分片动态调度,实现系统的透明水平扩展。
- 分布式事务
PolarDB-X 采用 MVCC + TSO 方案及 2PC 协议实现分布式事务。事务满足 ACID 特性,支持 RC/RR 隔离级别,并通过一阶段提交、只读事务、异步提交等优化实现事务的高性能。
- 混合负载
PolarDB-X 通过原生 MPP 能力实现对分析型查询的支持,通过 CPU quota 约束、内存池化、存储资源分离等实现了 OLTP 与 OLAP 流量的强隔离。
- 企业级
PolarDB-X 为企业场景设计了诸多内核能力,例如 SQL 限流、SQL Advisor、TDE、三权分立、Flashback Query 等。
- 云原生
PolarDB-X 在阿里云上有多年的云原生实践,支持通过 K8S Operator 管理集群资源,支持公有云、混合云、专有云等多种形态进行部署,并支持国产化操作系统和芯片。
- 高可用
通过多数派 Paxos 协议实现数据强一致,支持两地三中心、三地五副本等多种容灾方式,同时通过 Table Group、Geo-locality 等提高系统可用性。
- 兼容 MySQL 系统及生态
PolarDB-X 的目标是完全兼容 MySQL ,目前兼容的内容包括 MySQL 协议、MySQL 大部分语法、Collation、事务隔离级别、Binlog 等。
三、如何搭建的高可用系统
1. 创建实验资源及安装环境
开始实验之前,需要先创建ECS实例资源,并安装Docker、kubectl、minikube和Helm3,最后安装MySQL。
2. 使用PolarDB-X Operator安装PolarDB-X
- 使用minikube创建Kubernetes集群。
minikube是由社区维护的用于快速创建Kubernetes测试集群的工具,适合测试和学习Kubernetes。使用minikube创建的Kubernetes集群可以运行在容器或是虚拟机中,该实验场景以CentOS 8.5上创建Kubernetes为例。
a.新建账号galaxykube,并将galaxykube加入docker组中。【minikube要求使用非root账号进行部署】,切换到账号galaxykube,进入到home/galaxykube目录。执行如下命令,启动一个minikube。
minikube start --cpus 4 --memory 12288 --image-mirror-country cn --registry-mirror=https://docker.mirrors.sjtug.sjtu.edu.cn --kubernetes-version 1.23.3
b.执行如下命令,使用kubectl查看集群信息。
kubectl cluster-info
- 部署 PolarDB-X Operator。
a.执行如下命令,创建一个名为polardbx-operator-system的命名空间。
kubectl create namespace polardbx-operator-system
b.执行如下命令,安装PolarDB-X Operator。
helm repo add polardbx https://polardbx-charts.oss-cn-beijing.aliyuncs.com
helm install --namespace polardbx-operator-system polardbx-operator polardbx/polardbx-operator
c.执行如下命令,查看PolarDB-X Operator组件的运行情况。等待所有组件都进入Running状态,表示PolarDB-X Operator已经安装完成。
kubectl get pods --namespace polardbx-operator-system
- 部署 PolarDB-X 集群。
a.创建polardb-x.yaml,按i键进入编辑模式,将如下代码复制到文件中,然后按ECS退出编辑模式,输入:wq后按下Enter键保存并退出。
apiVersion: polardbx.aliyun.com/v1
kind: PolarDBXCluster
metadata:
name: polardb-x
spec:
config:
dn:
mycnfOverwrite: |-
print_gtid_info_during_recovery=1
gtid_mode = ON
enforce-gtid-consistency = 1
recovery_apply_binlog=on
slave_exec_mode=SMART
topology:
nodes:
cdc:
replicas: 1
template:
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: 100m
memory: 500Mi
cn:
replicas: 2
template:
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: 100m
memory: 1Gi
dn:
replicas: 1
template:
engine: galaxy
hostNetwork: true
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: 100m
memory: 500Mi
gms:
template:
engine: galaxy
hostNetwork: true
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: 100m
memory: 500Mi
serviceType: ClusterIP
upgradeStrategy: RollingUpgrade
b.创建PolarDB-X集群,查看PolarDB-X集群创建状态。
3. 连接PolarDB-X集群
1.执行如下命令,查看PolarDB-X集群登录密码。
kubectl get secret polardb-x -o jsonpath="{.data['polardbx_root']}" | base64 -d - | xargs echo "Password: "
2.执行如下命令,将PolarDB-X集群端口转发到3306端口。
kubectl port-forward svc/polardb-x 3306
3.执行如下命令,连接PolarDB-X集群。
mysql -h127.0.0.1 -P3306 -upolardbx_root -p<PolarDB-X集群登录密码>
4. 启动业务
·准备压测数据
- 创建压测数据库sysbench_test,输入exit退出数据库,切换到账号galaxykube。
- 进入到/home/galaxykube目录,创建准备压测数据的sysbench-prepare.yaml文件。
- 按i键进入编辑模式,将如下代码复制到文件中,然后按ECS退出编辑模式,输入:wq后按下Enter键保存并退出。
apiVersion: batch/v1
kind: Job
metadata:
name: sysbench-prepare-data-test
namespace: default
spec:
backoffLimit: 0
template:
spec:
restartPolicy: Never
containers:
- name: sysbench-prepare
image: severalnines/sysbench
env:
- name: POLARDB_X_USER
value: polardbx_root
- name: POLARDB_X_PASSWD
valueFrom:
secretKeyRef:
name: polardb-x
key: polardbx_root
command: [ 'sysbench' ]
args:
- --db-driver=mysql
- --mysql-host=$(POLARDB_X_SERVICE_HOST)
- --mysql-port=$(POLARDB_X_SERVICE_PORT)
- --mysql-user=$(POLARDB_X_USER)
- --mysql_password=$(POLARDB_X_PASSWD)
- --mysql-db=sysbench_test
- --mysql-table-engine=innodb
- --rand-init=on
- --max-requests=1
- --oltp-tables-count=1
- --report-interval=5
- --oltp-table-size=160000
- --oltp_skip_trx=on
- --oltp_auto_inc=off
- --oltp_secondary
- --oltp_range_size=5
- --mysql_table_options=dbpartition by hash(`id`)
- --num-threads=1
- --time=3600
- /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua
- run
4.执行如下命令,运行准备压测数据的sysbench-prepare.yaml文件,初始化测试数据。
kubectl apply -f sysbench-prepare.yaml
5.执行如下命令,获取任务进行状态。
kubectl get jobs
·启动压测流量。
创建启动压测的sysbench-oltp.yaml文件。
按i键进入编辑模式,将如下代码复制到文件中,然后按ECS退出编辑模式,输入:wq后按下Enter键保存并退出。
apiVersion: batch/v1
kind: Job
metadata:
name: sysbench-oltp-test
namespace: default
spec:
backoffLimit: 0
template:
spec:
restartPolicy: Never
containers:
- name: sysbench-oltp
image: severalnines/sysbench
env:
- name: POLARDB_X_USER
value: polardbx_root
- name: POLARDB_X_PASSWD
valueFrom:
secretKeyRef:
name: polardb-x
key: polardbx_root
command: [ 'sysbench' ]
args:
- --db-driver=mysql
- --mysql-host=$(POLARDB_X_SERVICE_HOST)
- --mysql-port=$(POLARDB_X_SERVICE_PORT)
- --mysql-user=$(POLARDB_X_USER)
- --mysql_password=$(POLARDB_X_PASSWD)
- --mysql-db=sysbench_test
- --mysql-table-engine=innodb
- --rand-init=on
- --max-requests=0
- --oltp-tables-count=1
- --report-interval=5
- --oltp-table-size=160000
- --oltp_skip_trx=on
- --oltp_auto_inc=off
- --oltp_secondary
- --oltp_range_size=5
- --mysql-ignore-errors=all
- --num-threads=8
- --time=3600
- /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua
- run
- 执行如下命令,运行启动压测的sysbench-oltp.yaml文件,开始压测。
kubectl apply -f sysbench-oltp.yaml
- 执行如下命令,查找压测脚本运行的POD。
kubectl get pods
- 执行如下命令,查看QPS等流量数据。
kubectl logs -f 目标POD
5. 体验PolarDB-X高可用能力
经过前面的准备工作,我们已经用PolarDB-X+Sysbench OLTP搭建了一个正在运行的业务系统。本步骤将通过使用kill POD的方式,模拟物理机宕机、断网等导致的节点不可用场景,并观察业务QPS的变化情况。
- 切换到账号galaxykube,获取CN POD的名字。返回结果如下,以‘polardb-x-xxxx-cn-default’开头的是CN POD的名字。
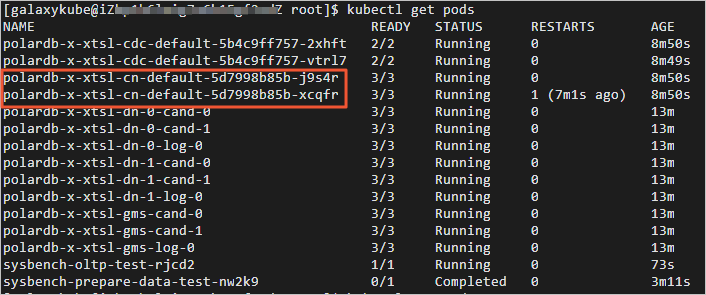
2.删除任意一个CN POD,查看CN POD自动创建情况。返回结果如下,可查看到CN POD已经处于自动创建中。经过几十秒后,被kill的CN POD自动恢复正常。切换至终端二,可查看kill CN之后业务QPS的情况。
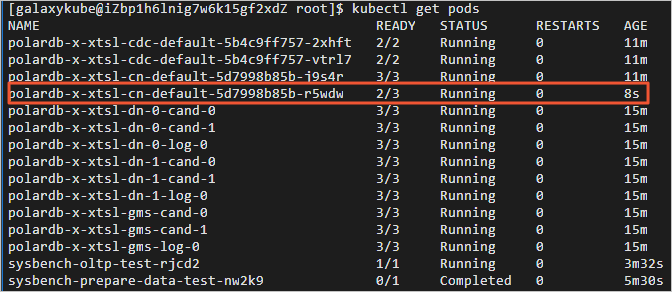
3.切换至终端三,获取DN POD的名字。返回结果如下,以‘polardb-x-xxxx-dn’开头的是DN POD的名字。
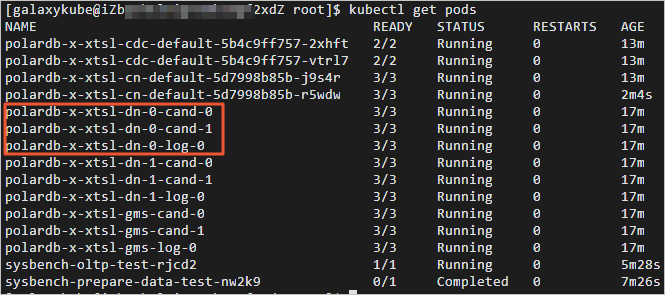
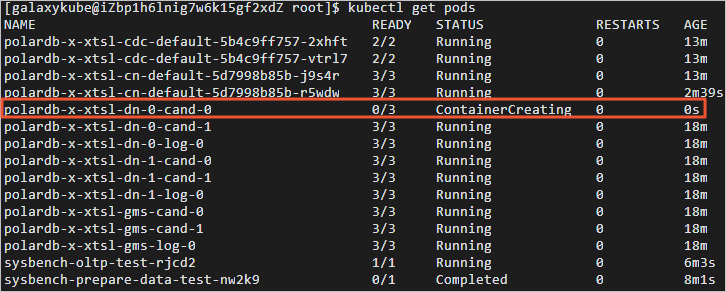
4.执行如下命令,删除任意一个DN POD,查看DN POD自动创建情况。返回结果如下,您可查看到DN POD已经处于自动创建中。经过几十秒后,被kill的DN POD自动恢复正常。切换至终端二,可查看kill DN之后业务QPS的情况。
5.切换至终端三,获取CDC POD的名字。返回结果如下,以‘polardb-x-xxxx-cdc-defaul’开头的是CDC POD的名字。
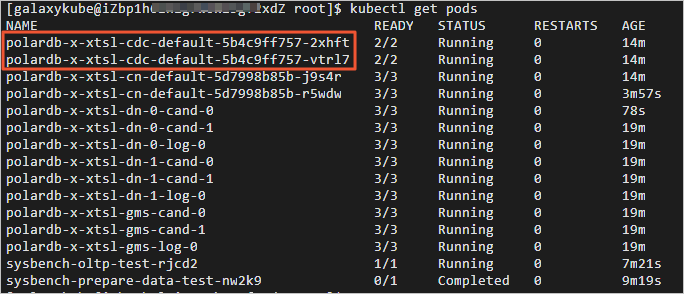
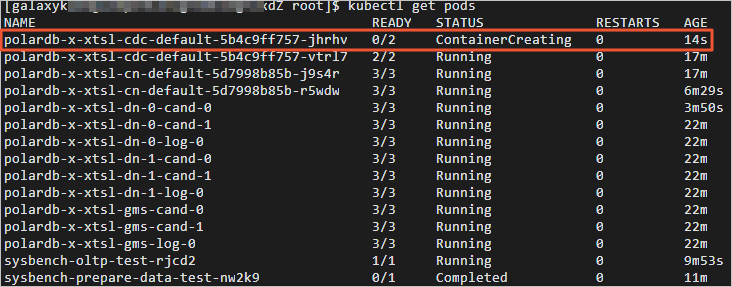
6.删除任意一个CDC POD,查看CDC POD自动创建情况。返回结果如下,您可查看到CDC POD已经处于自动创建中。经过几十秒后,被kill的CDC POD自动恢复正常。切换至终端二,您可查看kill CDC之后业务QPS的情况。
四、如何联动的数据大屏
1. 创建实验资源/安装PolarDB-X
开始实验之前,需要先创建ECS实例资源,之后安装并启动Docker,最后安装PolarDB-X
2. 在PolarDB-X中准备订单表
PolarDB-X支持通过MySQL Client命令行、第三方客户端以及符合MySQL交互协议的第三方程序代码进行连接。本实验使用MySQL Client命令行连接到PolarDB-X数据库。
- 安装MySQL,查看MySQL版本号。执行如下命令,登录PolarDB-X数据库。
mysql -h127.0.0.1 -P8527 -upolardbx_root -p123456
2.执行SQL语句,创建并使用测试库mydb。
3.执行如下SQL语句,创建订单表orders。
CREATE TABLE `orders` (
`order_id` int(11) NOT NULL AUTO_INCREMENT,
`order_date` datetime NOT NULL,
`customer_name` varchar(255) NOT NULL,
`price` decimal(10, 5) NOT NULL,
`product_id` int(11) NOT NULL,
`order_status` tinyint(1) NOT NULL,
PRIMARY KEY (`order_id`)
)AUTO_INCREMENT = 10001;
4.执行如下SQL语句,给订单表orders中插入数据。
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
3. 运行Flink
- 安装JDK。
使用yum安装JDK 1.8,查看是否安装成功。返回结果如下,表示您已成功安装JDK 1.8。

- 下载Flink和Flink CDC MySQL Connector。
下载并解压Flink,进入lib目录。执行如下命令,下载flink-sql-connector-mysql-cdc。
wget https://labfileapp.oss-cn-hangzhou.aliyuncs.com/PolarDB-X/flink-sql-connector-mysql-cdc-2.2.1.jar
- 启动Flink。
a.执行如下命令,启动Flink。
./bin/start-cluster.sh
b.执行如下命令,连接Flink。
./bin/sql-client.sh
- 在Flink中创建与PolarDB-X关联的订单表orders。
a.执行如下SQL语句,创建订单表orders。
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '8527',
'username' = 'polardbx_root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
b.执行如下SQL语句,查看订单表orders。可以查看到PolarDB-X的订单表orders的数据已经同步到Flink的订单表orders中。
select * from orders;
4. 启动压测脚本并实时获取GMV
经过前面几步操作后,我们在PolarDB-X中准备好了原始订单表,在Flink中准备好了对应的订单表,并通过 PolarDB-X Global Binlog与Flink CDC MySQL Connector打通了两者之间的实时同步链路。 本步骤将指导您如何创建压测脚本,模拟双十一零点大量订单涌入的场景。
- 准备压测脚本。
a.创建新的终端二,配置文件mysql-config.cnf。将如下代码添加到配置文件mysql-config.cnf中。
[client]
user = "polardbx_root"
password = "123456"
host = 127.0.0.1
port = 8527
b.添加完成后,按下Esc键后,输入:wq后按下Enter键保存并退出。创建脚本buy.sh,将如下代码添加到脚本buy.sh中。添加完成后,按下Esc键后,输入:wq后按下Enter键保存并退出。
#!/bin/bash
echo "start buying..."
count=0
while :
do
mysql --defaults-extra-file=./mysql-config.cnf -Dmydb -e "insert into orders values(default, now(), 'free6om', 1024, 102, 0)"
let count++
if ! (( count % 10 )); then
let "batch = count/10"
echo $batch": got 10 products, gave 1024¥"
fi
sleep 0.05
done
c.执行如下命令,为脚本buy.sh增加执行权限。
chmod +x buy.sh
- 启动Flink实时计算。
切换至终端一,在Flink中执行如下SQL语句,查询GMV(gmv列)和订单数(orders列)。
select 1, sum(price) as gmv, count(order_id) as orders from orders;
- 启动压测脚本。
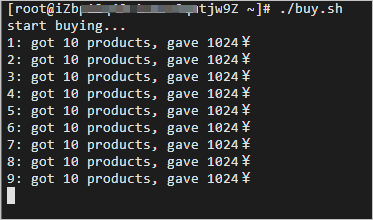
a.切换至终端二,执行如下命令,启动压测脚本,开始创建订单。
b.切换至终端一,在Flink的实时计算结果中,可查看到实时的GMV(gmv列)和订单数(orders列)。