当前位置:网站首页>Analysis of frequent chain breaks in applications using Druid connection pools
Analysis of frequent chain breaks in applications using Druid connection pools
2022-07-06 18:58:00 【solihawk】
Some time ago, there was an application Druid The connection pool often prompts an error when the link is broken , The whole troubleshooting and analysis process is very interesting . There will be Druid Connection pool 、 Configuration analysis of database layer and load balancing layer , Record the analysis process of the whole problem , At the same time, comb Druid Configuration of connection pool and connection keeping and recycling mechanism .
1、 The problem background
Applications apply for connections through the database connection pool , Then connect to the database agent through load balancing, and then access the database , This is a typical architecture , As shown in the figure below :
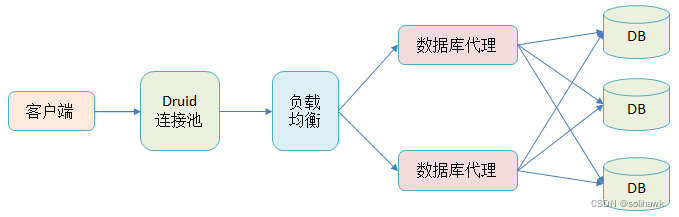
However, after the system goes online, the application always occasionally breaks the chain and reports errors , The following error messages appear frequently :
discard connection
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet successfully received from the server was 72,557 milliseconds ago. The last packet sent successfully to the server was 0 milliseconds ago.
According to the error log The preliminary judgment must be with DB The link between the two has been broken , An attempt to use a broken link will cause this error to occur , But according to Druid Connection check function of , There should be no such problem . Next, learn about Druid The basic configuration of the connection pool and the connection liveness and recycling mechanism .
2、Druid Connection pool
2.1 Druid Connection overview
Druid It is an open source database connection pool , It is a combination of C3P0、DBCP、Proxool etc. DB The advantages of the pool , At the same time, log monitoring is added , It's a good monitor DB Pool connection and SQL Implementation of .
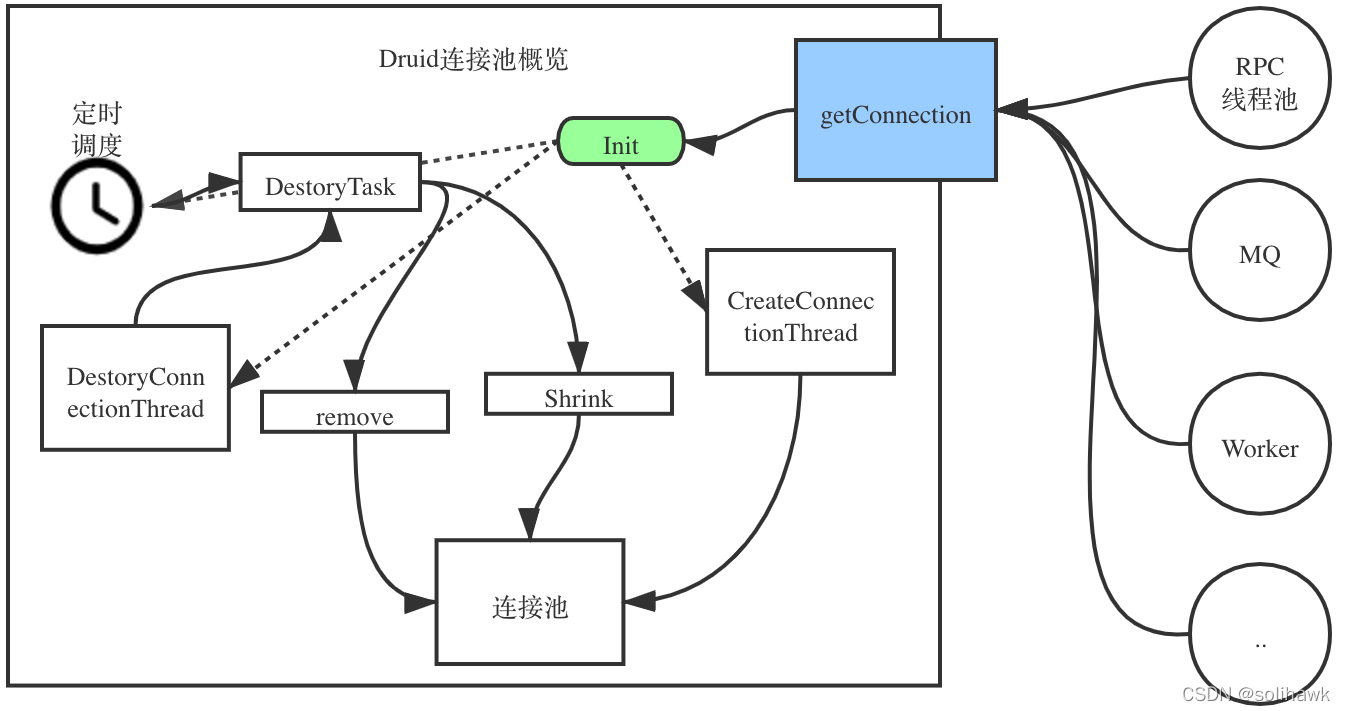
- stay druidDataSource There is a reentrant lock and two derived condition: Whether a monitoring connection pool is empty , A monitoring connection pool is not empty .
- stay druidDataSource There are two threads in the , One Make connections CreateConnectionThread, A recycling connection DestoryConnectionThread. Creating 、 obtain 、 These locks and... Will be used when recycling condition.
- Every time to get Connection Will be called init, For internal use inited identification DataSource Is it initialized OK.
- Every time to get Connection Will need to lock to ensure thread safety , All operations are performed after locking .
- If there is no connection in the pool , Call empty.signal(), notice CreateThread Create connection , And wait for the specified time , Wake up and check if there is a connection available .
2.2 Druid Parameter configuration description
1) Basic attributes
- name: The point of configuring this property is , If there are multiple data sources , Monitoring can be distinguished by name . If not configured , Will generate a name , The format is :“DataSource-” + System.identityHashCode(this).
- url: Connected to the database url, Different databases are different . for example :mysql : jdbc:mysql://10.20.153.104:3306/druid2、oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto
- username: User name to connect to the database
- password: Password to connect to the database
- driverClassName: This item can be matched or not , If you don't configure druid Will be based on url Automatic identification dbType, Then choose the appropriate driverClassName
2) Connection pool size
- initialSize: Number of physical connections established during initialization . Initialization occurs in the display call init Method , Or for the first time getConnection when . The default value is 0
- maxActive: Maximum number of connection pools . The default value is 8
- minIdle: Minimum number of connection pools . The default value is 0
- maxWait: Maximum wait time when getting a connection , Unit millisecond . Configured with maxWait after , Fair lock is enabled by default , Concurrency efficiency will decrease , If necessary, it can be configured through useUnfairLock The attribute is true Use unfair locks . The default value is -1
3) Connection detection
- testOnBorrow: Execute on connection request validationQuery Check whether the connection is valid , This configuration will degrade performance . The default value is true
- testOnReturn: Execute... When returning the connection validationQuery Check whether the connection is valid , This configuration will degrade performance . The default value is false
- testWhileIdle: Recommended configuration is true, No performance impact , And ensure safety . Check when applying for connection , If the free time is greater than timeBetweenEvictionRunsMillis, perform validationQuery Check whether the connection is valid . The default value is false
- timeBetweenEvictionRunsMillis: There are two meanings :1) Destroy The thread will detect the connection interval , If the connection idle time is greater than or equal to minEvictableIdleTimeMillis Then close the physical connection .2) testWhileIdle On the basis of . The default value is 60s
- maxEvictableIdleTimeMillis: Connection idle time is greater than this value , No matter minidle Close this connection at any rate . The default value is 7 Hours
- minEvictableIdleTimeMillis: The connection idle time is greater than this value and the number of idle connections in the pool is greater than minidle Then close the connection . The default value is 30 minute
- maxPoolPreparedStatementPerConnectionSize: To enable the PSCache, Must be configured greater than 0, When more than 0 when ,poolPreparedStatements Auto trigger changed to true. stay Druid in , No existence Oracle Next PSCache The problem of using too much memory , You can configure this value to be larger , for instance 100. The default value is -1
- PhyTimeoutMillis: The physical connection has been opened for more than this timeout , And the physical connection will be closed when it is no longer used , It is generally not recommended to open
- validationQuery: Used to check whether the connection is valid sql, The requirement is a query statement , Commonly used select ‘x’. If validationQuery by null,testOnBorrow、testOnReturn、testWhileIdle It doesn't work . The default value is null
- validationQueryTimeout: Company : second , Timeout to check if the connection is valid . Bottom call jdbc Statement Object's void setQueryTimeout(int seconds) Method . The default value is -1
- keepAlive: Connect... In the pool minIdle No more connections , And the idle time of the connection is greater than keepAliveBetweenTimeMillis But less than minEvictableIdleTimeMillis, Will perform validationQuery To maintain the effectiveness of the connection . The default value is false
- keepAliveBetweenTimeMillis: open KeepAlive when , When the idle time of the connection exceeds this value , Will use validationQuery Perform a query , Check if the connection is available . The default value is 120s
4) Cache statement
- poolPreparedStatements: Whether the cache preparedStatement, That is to say PSCache.PSCache Great improvement in database performance supporting cursors , for instance oracle. stay mysql The next suggestion is to close . The default value is false
- sharePrepareStatements
- maxPoolPreparedStatementPerConnectionSize: To enable the PSCache, Must be configured greater than 0, When more than 0 when ,poolPreparedStatements Auto trigger changed to true. stay Druid in , No existence Oracle Next PSCache The problem of using too much memory , You can configure this value to be larger , for instance 100. The default value is -1
2.3 Druid Connection pool use
Use druid Connection pool , Mainly Use DruidDataSourceFactory Create DataSource Data source object , Then call it. getConnection Method to get the database connection object , After getting the connection object , Unlike other database connections, when the connection is called close When the method is used , The bottom layer is no longer closing and destroying connection objects , Instead, put the connection object into the connection pool , So that when the subsequent new request comes , Use it directly .
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
public class druidtest {
public static void main(String[] args) throws Exception {
// Load profile
InputStream is = druidtest.class.getClassLoader().getResourceAsStream("druid.properties");
Properties prop = new Properties();
prop.load(is);
// According to the content of the configuration file , Create a data source object
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
// Get the database connection through the data source object
// If the connections in the connection pool have been used up , Will wait for a certain time ( Configured time )
// If the wait times out , Will throw an exception
Connection con = dataSource.getConnection();
// perform sql sentence , Get and print the result set
String sql = "select e_id,e_name,e_age from employee";
PreparedStatement pst = con.prepareStatement(sql);
ResultSet rs = pst.executeQuery();
while(rs.next()) {
System.out.println(
rs.getInt("e_id") + "\t" +
rs.getString("e_name") + "\t" +
rs.getInt("e_age"));
}
// Release resources
rs.close();
pst.close();
// Close the connection here , Instead of closing and destroying the connection, the connection object , Put it into the connection pool , For direct use during subsequent visits
con.close();
}
}
Pay attention to the con.close(), Close the connection here , Instead of closing and destroying the connection, the connection object , Put it into the connection pool , For direct use during subsequent visits .
2.4 Connect the preservation and recycling mechanism
2.4.1 Connect to keep alive
In order to prevent a database connection from being used for too long , And was shut down by other lower level services ,druid in Defined KeepAlive Options , The mechanism is similar to TCP Similar to . The keep alive mechanism can ensure that the connections in the connection pool are true and effective , If the connection is unavailable due to special circumstances ,keepAlive The mechanism expels invalid connections . The keep alive mechanism is made up of daemon threads DestroyConnectionThread Sponsored , After startup, the daemon thread will enter the wireless loop , According to the heartbeat interval timeBetweenEvictionRunsMillis Cycle call DestoryTask Threads , The default time is 60s.
1) Turn on KeepAlive
// The minimum lifetime of a connection in the connection pool
dataSurce.setMinEvictableIdleTimeMillis(60 * 1000); Unit millisecond
// Turn on keepAlive
dataSource.setKeepAlive(true);
2)DruidDataSource Two member variables in
// Store connections that need to be discarded for inspection
private DruidConnectionHolder[] evictConnections;
// Used to store live connections that need connection checking
private DruidConnectionHolder[] keepAliveConnections;
If KeepAlive open , When a connection is idle for more than keepAliveBetweenTimeMillis when , Will put this connection into this connection keepAliveConnections Array , And then use validationQuery Perform a query .
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
}
…
if (keepAliveCount > 0) {
// keep order
for (int i = keepAliveCount - 1; i >= 0; --i) {
DruidConnectionHolder holer = keepAliveConnections[i];
Connection connection = holer.getConnection();
holer.incrementKeepAliveCheckCount();
boolean validate = false;
try {
this.validateConnection(connection);
validate = true;
} catch (Throwable error) {
if (LOG.isDebugEnabled()) {
LOG.debug("keepAliveErr", error);
}
// skip
}
If this time validationQuery Execution failure , Then close the link , And discard .
2.4.2 Data source shrink
stay Druid When initializing the data source , Will create a timed DestroyTask, The main purpose of this task is Close the connection whose idle time meets the closing conditions .
1) Current connection lifetime > Configured physical connection time , Put in evictConnections
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
continue;
}
2) free time > Minimum expulsion time
if (idleMillis >= minEvictableIdleTimeMillis) {
if (checkTime && i < checkCount) {
evictConnections[evictCount++] = connection;
continue;
} else if (idleMillis > maxEvictableIdleTimeMillis) {
evictConnections[evictCount++] = connection;
continue;
}
}
…
if (evictCount > 0) {
for (int i = 0; i < evictCount; ++i) {
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCountUpdater.incrementAndGet(this);
}
Arrays.fill(evictConnections, null);
}
You can see from the code logic , The logic for selecting idle connections to close is as follows :
- For free time > minEvictableIdleTimeMillis The connection of , Only close poolingCount-minIdle individual , The following connections are not affected ;
- be in > maxEvictableIdleTimeMillis The idle connection of will be closed directly ;
- timeBetweenEvictionRunsMillis This is the interval between the scheduled tasks ;
- minEvictableIdleTimeMillis Is the minimum idle time that can close the connection
2.5 Druid Connection life cycle
Druid The life cycle of connection is viewed from two dimensions : One is the application user , Including connection application 、 Use and close ; One is Druid Self managed connection pool , Including connection creation and recycling 、 Survival mechanism, etc . The details are as follows :
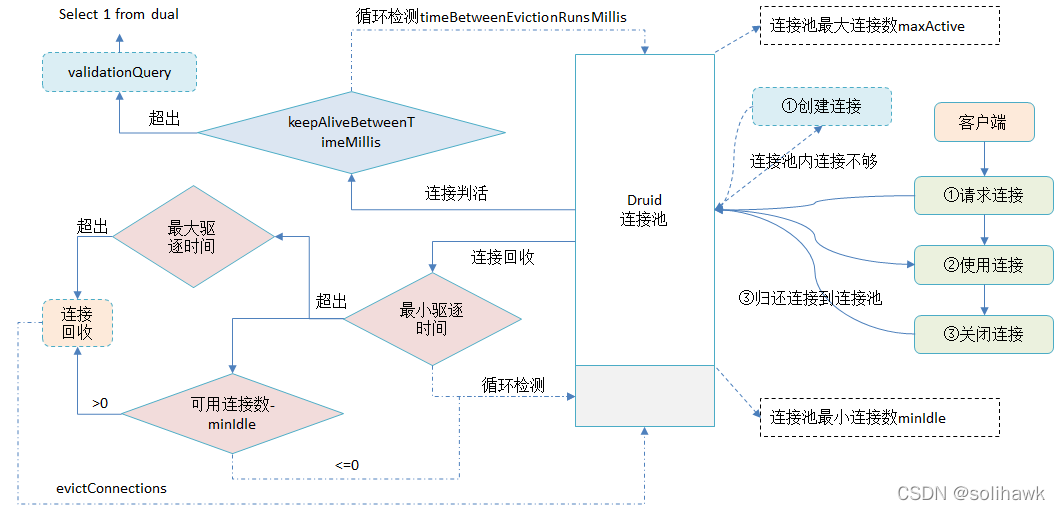
1) Client connection management
- The client initiates a connection request from Druid Connection pool request connection , If there are not enough connections in the connection pool, it will call CreateThread Create connection ;
- After the client gets the connection , Access the database for operation ;
- After the connection operation , Release database resources and close Connect , This step is usually done by the application itself , After the connection is closed, it will be recycled , Give back to Druid Connection pool .
2)Druid Connection pool management
- Druid Connection pool Settings Minimum connections minIdle And maximum connections maxActive, The minimum number of connections supports the preheating function , Applications do not need to be reinitialized every time they apply for a connection , High parallel delivery can improve performance ;
- The connection pool will keep the connection alive regularly ,KeepAlive The period of is determined by timeBetweenEvictionRunsMillis control ( The default value is 60s), When it is found that the idle time of the connection exceeds keepAliveBetweenTimeMillis( The default value is 120s) when , It will actively initiate link maintenance , Generally, it is initiated to the database SQL Inquire about , This SQL Statement can be customized , Usually it is “select 1 from dual”
- To prevent connection leakage , Idle connections will be recycled regularly , Idle time for connection is greater than minEvictableIdleTimeMillis( The default is 30 minute ) And the number of free connections in the connection pool is greater than minIdle Then close the connection ; If the connection idle time is greater than maxEvictableIdleTimeMillis( The default value is 7 Hours ) Then close the connection directly
- And you can see that , Keep alive if there is no connection , When setting minIdle After that, some connections within the minimum connection will be closed due to idle connection timeout ; Of course, if it's set KeepAlive And when the detection frequency of keeping alive and keepAliveBetweenTimeMillis Less than minEvictableIdleTimeMillis when , The idle connection will not be closed .
3、 Problem analysis
Back to the problem of application chain breaking , be based on Druid The setting of connection pool and the timeout setting of the entire link of the application accessing the database , With MySQL Database, for example , You can get the following configuration :
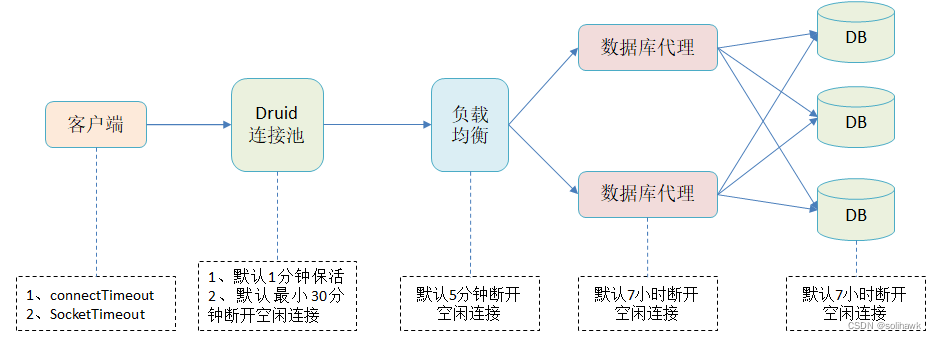
3.1 application JDBC Of url Connection configuration
JDBC Of url Connection configuration connectTimeout and socketTimeout All belong to TCP Timeout of level
- connectTimeout: It refers to the establishment of database driver and database server TCP Connection timeout . The following exception message may appear after timeout
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
...
Caused by: java.net.SocketTimeoutException: connect timed out
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
...
- socketTimeout: adopt TCP After connecting and sending data , Timeout waiting for response . Usually in sql The execution time of is longer than socket timeout In the case of setting . Similar error messages will appear after timeout :
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet successfully received from the server was 3,080 milliseconds ago. The last packet sent successfully to the server was 3,005 milliseconds ago.
...
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
3.2 Database layer timeout settings
With MySQL For example , Set the idle connection in the database layer Timeout parameters wait_timeout, The default is 7 Hours , The idle connection will be automatically disconnected after exceeding . In the actual process , Application through load balancing or Druid Connect to database , If load balancing is not enabled, session persistence or Druid There is no connection survival mechanism , The connection idle time of the client exceeds 7 Hours later, , Will actively kill in the database layer . But now that it has been used Druid Connection pool , Then the database connection on the application side can be made by Druid Good management .
3.3 Druid Connection configuration
From the application chain breaking error information , Not more than 7 Hours off , It is 300s about , Therefore, the problem of active chain breaking at the database layer is eliminated . Let's analyze Druid End configuration , The parameters related to the connection are as follows :
datasource.druid.validationQuery=SELECT 1 from dual
datasource.druid.validationQueryTimeout=2000
datasource.druid.testWhileIdle=true
datasource.druid.minIdle=50
datasource.druid.maxActive=100
datasource.druid.minEvictableIdleTimeMillis=300000
datasource.druid.timeBetweenEvictionRunsMillis=600000
datasource.druid.keepAlive=true
datasource.druid.keepAliveBetweenTimeMillis=300s
- Druid Of KeepAlive The switch is on , The mechanism of connecting and keeping alive is effective . By default druid It's using mysql.ping Check the agreement , Use check statements “SELECT 1 from dual” Same update session Of idle time , There is no problem here
- Druid The link keep alive detection cycle of is timeBetweenEvictionRunsMillis by 600s, The default value is 60s, The application adjusts the detection cycle considering the performance . If the idle connection exceeds 600s, If the detection cycle is met, it can be kept alive again , But if the idle time of the connection is less than 600s And be close fall , That is not Druid It's caused here , That is, in this problem 300s The left and right links are disconnected .
3.4 Load balanced session persistence configuration
One thing that is easy to ignore is Load balanced session keeping , Session hold means that there is a mechanism on the load balancer , While balancing the load , It also guarantees that access requests associated with the same user will be assigned to the same server . Session persistence is time limited , With F5 For example, I think 5 minute , That is, it is detected that the connection is idle for more than 5 minute , Will take the initiative to disconnect it . There seems to be a problem here ,Druid The survival of the connection pool is 10 Minutes, and the idle connection detection on the load balancing side is 5 minute , When the idle time of a connection exceeds 5 Minutes but less than 10 Minutes later , Will be killed by the load balancing side , Of course, when using this connection, the application will report an error of chain disconnection . Finally, it adjusts the detection time of load balanced session retention , To avoid similar problems .
4、 summary
Application in use Druid When the connection pool accesses the database , According to the business TPS And concurrent adjustment of the appropriate configuration , To take advantage of Druid The implementation of connection pool is to create connections 、 Keep alive and release management . When encountering problems like chain breaking , Check and analyze every point from end to end , To locate the ultimate cause , For example, the configuration of load balancing this time is hard to think of . Application from Druid After applying for connection , This connection has exceeded Druid Management scope of , It needs to be handled by the application itself , timely close Return to the connection pool , Otherwise, there will be more and more connections on the database side , Moreover, the idle connection will be broken by the database layer or load balancing layer after a certain period of time, resulting in the error of disconnection , This requires additional processing by the application .
Reference material :
- https://github.com/alibaba/druid/wiki/
- https://www.cnblogs.com/studyjobs/p/15888552.html
- https://www.jianshu.com/p/131998f9777d
- https://blog.csdn.net/qq_45533884/article/details/107392617
Reprint please indicate the original address :https://blog.csdn.net/solihawk/article/details/125612396
The article will be synchronized in the official account. “ Shepherd's direction ” to update , Interested can pay attention to the official account , thank you !

边栏推荐
- Atcoder a mountaineer
- Certains marchés de l'emploi de Shanghai refusent d'embaucher des personnes qui se rétablissent positives à Xinguan
- Estimate blood pressure according to PPG using spectral spectrum time depth neural network [turn]
- 基于蝴蝶种类识别
- 深度循环网络长期血压预测【翻译】
- Breadth first traversal of graph
- Mathematics in machine learning -- common probability distribution (XIII): Logistic Distribution
- Penetration test information collection - WAF identification
- Collection of penetration test information -- use with nmap and other tools
- RedisSystemException:WRONGTYPE Operation against a key holding the wrong kind of value
猜你喜欢
![[depth first search] Ji suanke: Square](/img/fc/e42ae0d036be258bed5623d55fc2db.jpg)
[depth first search] Ji suanke: Square

About static type, dynamic type, ID, instancetype
![[depth first search] Ji suanke: find numbers](/img/e4/708a1e8252bcd2d0d621c66bf6bfed.jpg)
[depth first search] Ji suanke: find numbers
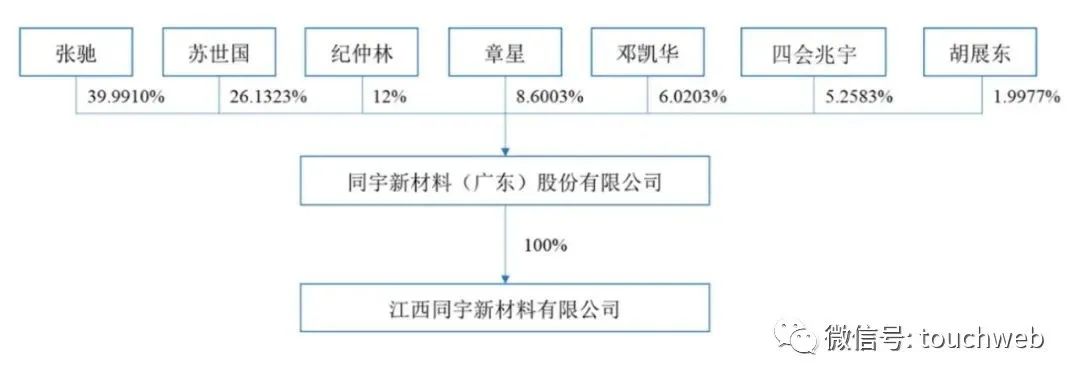
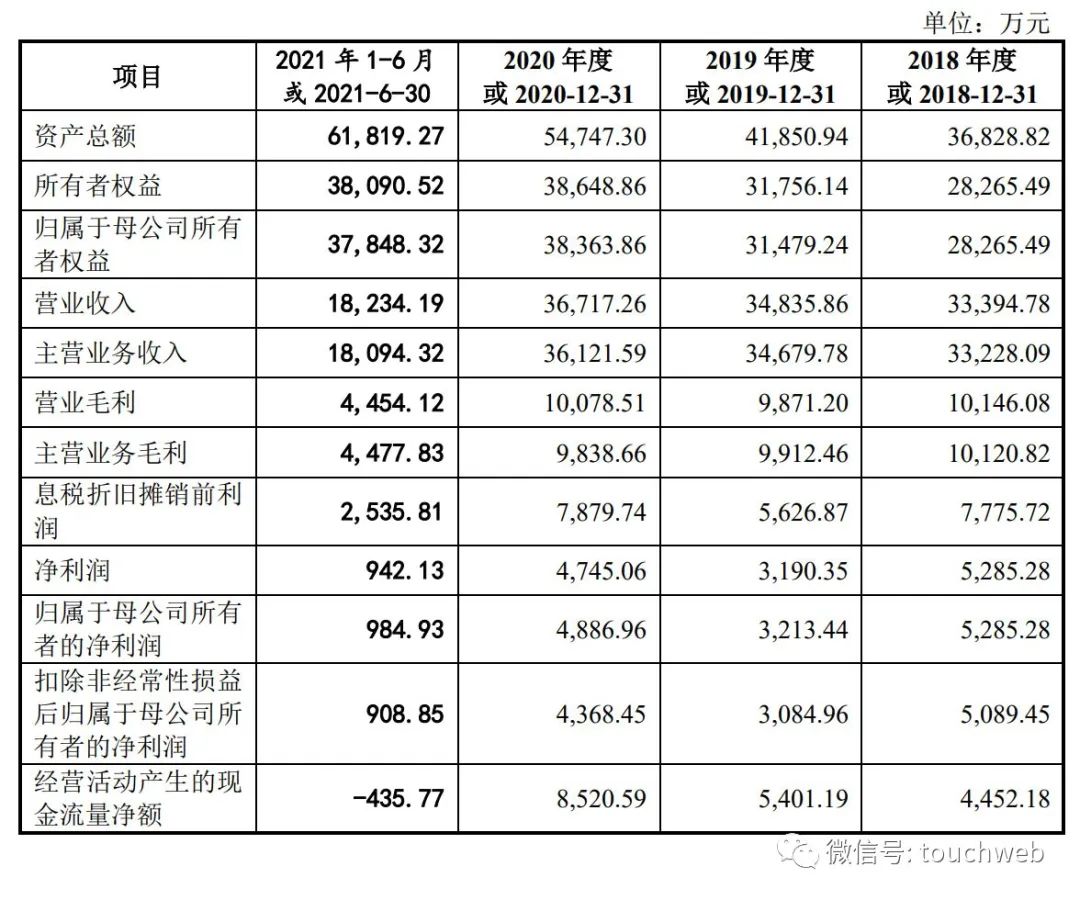
同宇新材冲刺深交所:年营收9.47亿 张驰与苏世国为实控人

美庐生物IPO被终止:年营收3.85亿 陈林为实控人

How are you in the first half of the year occupied by the epidemic| Mid 2022 summary

C#/VB.NET 给PDF文档添加文本/图像水印
星诺奇科技IPO被终止:曾拟募资3.5亿元 年营收3.67亿

Describe the process of key exchange

涂鸦智能在香港双重主板上市:市值112亿港元 年营收3亿美元
随机推荐
Penetration test information collection - basic enterprise information
AIRIOT物联网平台赋能集装箱行业构建【焊接工位信息监控系统】
Some understandings of tree LSTM and DGL code implementation
Wx applet learning notes day01
[depth first search] Ji suanke: a joke of replacement
How to improve website weight
抽象类与抽象方法
Execution process of MySQL query request - underlying principle
Interpreting cloud native technology
Introduction to the use of SAP Fiori application index tool and SAP Fiori tools
About static type, dynamic type, ID, instancetype
Abstract classes and abstract methods
CSRF vulnerability analysis
Yutai micro rushes to the scientific innovation board: Huawei and Xiaomi fund are shareholders to raise 1.3 billion
Implementation of AVL tree
美庐生物IPO被终止:年营收3.85亿 陈林为实控人
How are you in the first half of the year occupied by the epidemic| Mid 2022 summary
Test 123
使用map函数、split函数一行键入多个元素
pychrm社区版调用matplotlib.pyplot.imshow()函数图像不弹出的解决方法