当前位置:网站首页>pytorch常见损失函数
pytorch常见损失函数
2022-07-06 11:03:00 【m0_61899108】
转载于:
PyTorch 中的损失函数总结 | 梦家博客 (dreamhomes.top)
1、L1 loss


def mean_absolute_error(y_true, y_pred):
return K.mean(K.abs(y_pred - y_true), axis=-1)
# 实例代码
import torch
from torch import nn
input_data = torch.FloatTensor([[3], [4], [5]]) # batch_size, output
target_data = torch.FloatTensor([[2], [5], [8]]) # batch_size, output
loss_func = nn.L1Loss()
loss = loss_func(input_data, target_data)
print(loss) # 1.6667
# 验证代码
print((abs(3-2) + abs(4-5) + abs(5-8)) / 3) # 1.6666
2、L2 loss
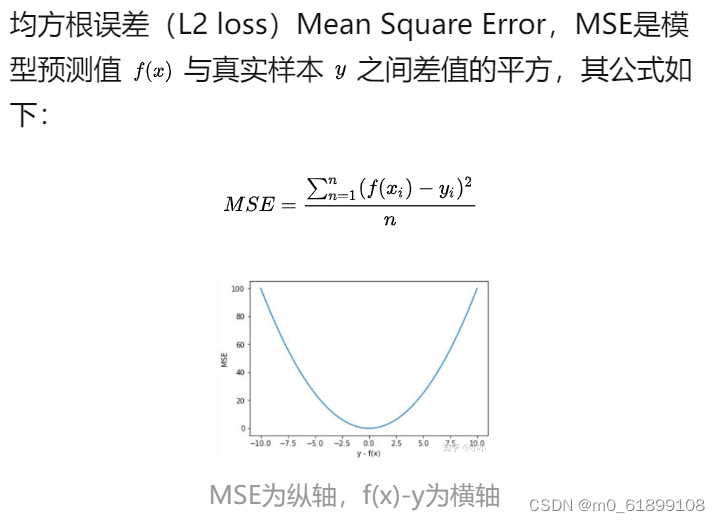

def mean_squared_error(y_true, y_pred):
return K.mean(K.square(y_pred - y_true), axis=-1)
# 实例代码
import torch
from torch import nn
input_data = torch.FloatTensor([[3], [4], [5]]) # batch_size, output
target_data = torch.FloatTensor([[2], [5], [8]]) # batch_size, output
loss_func = nn.MSELoss()
loss = loss_func(input_data, target_data)
print(loss) # 3.6667
# 验证
print(((3-2)**2 + (4-5)**2 + (5-8)**2)/3) # 3.6666666666666665
3、smooth L1 loss

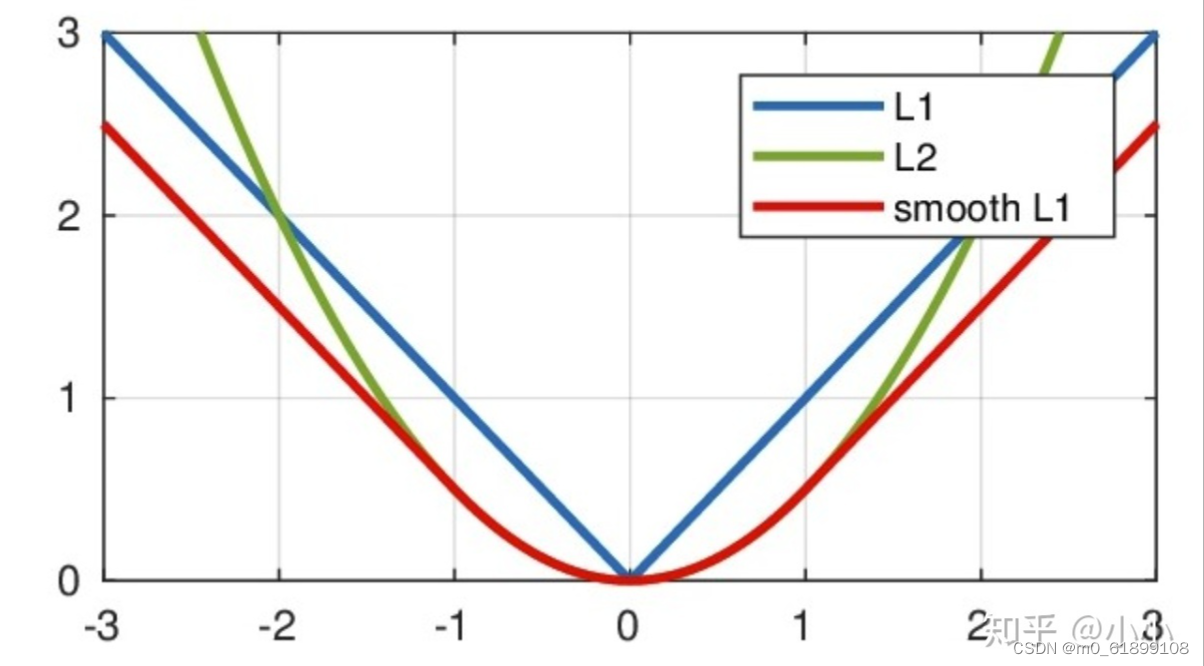
在Faster RCNN和SSD中使用了smooth L1 损失函数。

# 实例代码
import torch
from torch import nn
input_data = torch.FloatTensor([[3], [4], [5]]) # batch_size, output
target_data = torch.FloatTensor([[2], [4.1], [8]]) # batch_size, output
loss_func = nn.SmoothL1Loss()
loss = loss_func(input_data, target_data)
print(loss) # 输出:1.00174、NLLLoss

# 示例代码
# 三个样本 进行三分类 使用NLLLoss
import torch
from torch import nn
input = torch.randn(3, 3)
print(input)
# tensor([[ 0.0550, -0.5005, -0.4188],
# [ 0.7060, 1.1139, -0.0016],
# [ 0.3008, -0.9968, 0.5147]])
label = torch.LongTensor([0, 2, 1]) # 真实label
loss_func = nn.NLLLoss()
loss = loss_func(temp, label)
print(loss) # 损失1.6035
# 验证代码
output = torch.FloatTensor([
[ 0.0550, -0.5005, -0.4188],
[ 0.7060, 1.1139, -0.0016],
[ 0.3008, -0.9968, 0.5147]]
)
# 1. softmax + log = torch.log_softmax()
sm = nn.Softmax(dim=1)
temp = torch.log(sm(input))
print(temp)
# tensor([[-0.7868, -1.3423, -1.2607],
# [-1.0974, -0.6896, -1.8051],
# [-0.9210, -2.2185, -0.7070]])
# 2. 因为label为[0, 2, 1]
# 因此第一行取第一个值-0.7868。第二行取第三个值-1.8051,第三行取第二个值-2.2185。然后把负号直接扔掉。 说白的 就是去对数的负值成对应的label 也就是交叉熵。
print((0.7868 + 1.8051 + 2.2185) / 3) # 输出1.6034666666666666
5、CrossEntropyLoss

# 实例代码
# 三个样本进行三分类 和上面的数据一样
import torch
from torch import nn
loss_func1 = nn.CrossEntropyLoss()
output = torch.FloatTensor([
[ 0.0550, -0.5005, -0.4188],
[ 0.7060, 1.1139, -0.0016],
[ 0.3008, -0.9968, 0.5147]]
)
true_label = torch.LongTensor([0, 2, 1]) # 注意这里的label id必须从0开始 不能说label id是1,2,3 必须是0,1,2
loss = loss_func1(output, true_label)
print(loss) # 输出: 1.6035
6、BCELoss

一个样本多标签分类
# 示例代码 一个样本多标签分类
import torch
from torch import nn
bce = nn.BCELoss()
output = torch.FloatTensor(
[
[ 0.0550, -0.5005, -0.4188],
[ 0.7060, 1.1139, -0.0016],
[ 0.3008, -0.9968, 0.5147]
]
)
# 注意 输出要经过sigmoid
s = nn.Sigmoid()
output = s(output)
# 假设是一条数据多个标签的分类
label = torch.FloatTensor(
[
[1, 0, 1],
[0, 0, 1],
[1, 1, 0]
]
)
loss = bce(output, label)
print(loss) # 输出: 0.9013
# 验证代码
# 1. 模型输出
output = torch.FloatTensor(
[
[ 0.0550, -0.5005, -0.4188],
[ 0.7060, 1.1139, -0.0016],
[ 0.3008, -0.9968, 0.5147]
]
)
# 2. 经过sigmoid
s = nn.Sigmoid()
output = s(output)
# print(output)
# tensor([[0.5137, 0.3774, 0.3968],
# [0.6695, 0.7529, 0.4996],
# [0.5746, 0.2696, 0.6259]])
label = torch.FloatTensor(
[
[1, 0, 1],
[0, 0, 1],
[1, 1, 0]
]
)
# 我们根据标签和sigmoid计算出计算
# 第一行
sum_1 = 0
sum_1 += 1 * torch.log(torch.tensor(0.5137)) + (1 - 1) * torch.log(torch.tensor(1 - 0.5137)) # 第一列
sum_1 += 0 * torch.log(torch.tensor(0.3774)) + (1 - 0) * torch.log(torch.tensor(1 - 0.3774)) # 第二列
sum_1 += 1 * torch.log(torch.tensor(0.3968)) + (1 - 1) * torch.log(torch.tensor(1 - 0.3968)) # 第三列
avg_1 = sum_1 / 3
# 第二行
sum_2 = 0
sum_2 += 0 * torch.log(torch.tensor(0.6695)) + (1 - 0) * torch.log(torch.tensor(1 - 0.6695)) # 第一列
sum_2 += 0 * torch.log(torch.tensor(0.7529)) + (1 - 0) * torch.log(torch.tensor(1 - 0.7529)) # 第二列
sum_2 += 1 * torch.log(torch.tensor(0.4996)) + (1 - 1) * torch.log(torch.tensor(1 - 0.4996)) # 第三列
avg_2 = sum_2 / 3
# 第三行
sum_3 = 0
sum_3 += 1 * torch.log(torch.tensor(0.5746)) + (1 - 1) * torch.log(torch.tensor(1 - 0.5746)) # 第一列
sum_3 += 1 * torch.log(torch.tensor(0.2696)) + (1 - 1) * torch.log(torch.tensor(1 - 0.2696)) # 第二列
sum_3 += 0 * torch.log(torch.tensor(0.6259)) + (1 - 0) * torch.log(torch.tensor(1 - 0.6259)) # 第三列
avg_3 = sum_3 / 3
result = -(avg_1 + avg_2 + avg_3) / 3
print(result) # 输出0.9013
二分类问题
# 示例代码
# 两个样本,二分类
import torch
from torch import nn
bce = nn.BCELoss()
output = torch.FloatTensor(
[
[ 0.0550, -0.5005],
[ 0.7060, 1.1139]
]
)
# 注意 输出要经过sigmoid
s = nn.Sigmoid()
output = s(output)
# 假设是一条数据多个标签的分类
label = torch.FloatTensor(
[
[1, 0],
[0, 1]
]
)
loss = bce(output, label)
print(loss) # 输出0.6327
# 验证代码
output = torch.FloatTensor(
[
[ 0.0550, -0.5005],
[ 0.7060, 1.1139]
]
)
# 注意 输出要经过sigmoid
s = nn.Sigmoid()
output = s(output)
# print(output)
# tensor([[0.5137, 0.3774],
# [0.6695, 0.7529]])
# true_label = [[1, 0], [0, 1]]
sum_1 = 0
sum_1 += 1 * torch.log(torch.tensor(0.5137)) + (1 - 1) * torch.log(torch.tensor(1 - 0.5137))
sum_1 += 0 * torch.log(torch.tensor(0.3774)) + (1 - 0) * torch.log(torch.tensor(1 - 0.3774))
avg_1 = sum_1 / 2
sum_2 = 0
sum_2 += 0 * torch.log(torch.tensor(0.6695)) + (1 - 0) * torch.log(torch.tensor(1 - 0.6695))
sum_2 += 1 * torch.log(torch.tensor(0.7529)) + (1 - 1) * torch.log(torch.tensor(1 - 0.7529))
avg_2 = sum_2 / 2
print(-(avg_1 + avg_2) / 2) # 输出0.63277、BCEWithLogitsLoss

# 实例代码
# 用上面那个两个样本进行二分类的数据
import torch
from torch import nn
bce_logit = nn.BCEWithLogitsLoss()
output = torch.FloatTensor(
[
[ 0.0550, -0.5005],
[ 0.7060, 1.1139]
]
) # 未经Sigmoid
label = torch.FloatTensor(
[
[1, 0],
[0, 1]
]
)
loss = bce_logit(output, label)
print(loss) # tensor(0.6327)8、Focal Loss



# 代码实现
import torch
import torch.nn.functional as F
def reduce_loss(loss, reduction):
reduction_enum = F._Reduction.get_enum(reduction)
# none: 0, elementwise_mean:1, sum: 2
if reduction_enum == 0:
return loss
elif reduction_enum == 1:
return loss.mean()
elif reduction_enum == 2:
return loss.sum()
def weight_reduce_loss(loss, weight=None, reduction='mean', avg_factor=None):
if weight is not None:
loss = loss * weight
if avg_factor is None:
loss = reduce_loss(loss, reduction)
else:
# if reduction is mean, then average the loss by avg_factor
if reduction == 'mean':
loss = loss.sum() / avg_factor
# if reduction is 'none', then do nothing, otherwise raise an error
elif reduction != 'none':
raise ValueError('avg_factor can not be used with reduction="sum"')
return loss
def py_sigmoid_focal_loss(pred, target, weight=None, gamma=2.0, alpha=0.25, reduction='mean', avg_factor=None):
# 注意 输入的pred不需要经过sigmoid
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
focal_weight = (alpha * target + (1 - alpha) *
(1 - target)) * pt.pow(gamma)
# 下面求交叉熵的这个函数 对pred进行了sigmoid
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
# print(loss)
'''输出
tensor([[0.0394, 0.0506],
[0.3722, 0.0043]])
'''
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss
if __name__ == '__main__':
output = torch.FloatTensor(
[
[0.0550, -0.5005],
[0.7060, 1.1139]
]
)
label = torch.FloatTensor(
[
[1, 0],
[0, 1]
]
)
loss = py_sigmoid_focal_loss(output, label)
print(loss)9、GHM Loss


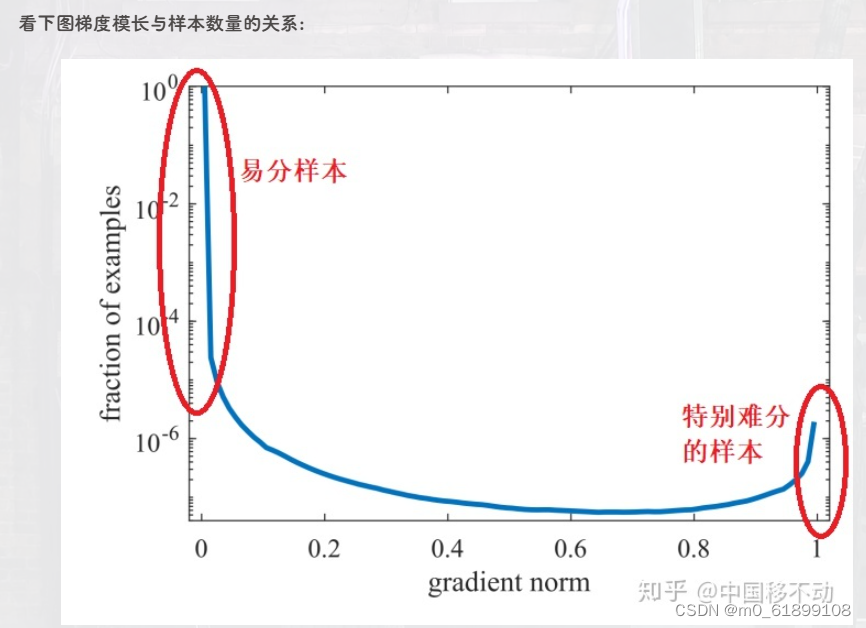



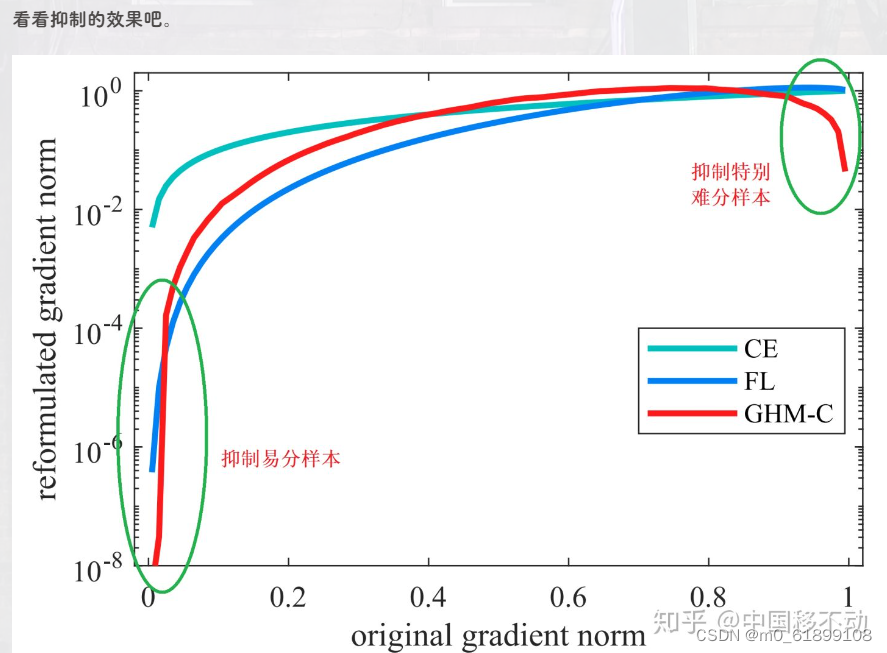
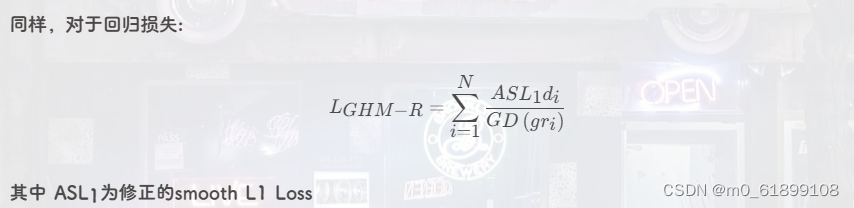
代码实现
# 代码实现
import torch
from torch import nn
import torch.nn.functional as F
class GHM_Loss(nn.Module):
def __init__(self, bins, alpha):
super(GHM_Loss, self).__init__()
self._bins = bins
self._alpha = alpha
self._last_bin_count = None
def _g2bin(self, g):
return torch.floor(g * (self._bins - 0.0001)).long()
def _custom_loss(self, x, target, weight):
raise NotImplementedError
def _custom_loss_grad(self, x, target):
raise NotImplementedError
def forward(self, x, target):
g = torch.abs(self._custom_loss_grad(x, target)).detach()
bin_idx = self._g2bin(g)
bin_count = torch.zeros((self._bins))
for i in range(self._bins):
bin_count[i] = (bin_idx == i).sum().item()
N = (x.size(0) * x.size(1))
if self._last_bin_count is None:
self._last_bin_count = bin_count
else:
bin_count = self._alpha * self._last_bin_count + (1 - self._alpha) * bin_count
self._last_bin_count = bin_count
nonempty_bins = (bin_count > 0).sum().item()
gd = bin_count * nonempty_bins
gd = torch.clamp(gd, min=0.0001)
beta = N / gd
return self._custom_loss(x, target, beta[bin_idx])
class GHMC_Loss(GHM_Loss):
# 分类损失
def __init__(self, bins, alpha):
super(GHMC_Loss, self).__init__(bins, alpha)
def _custom_loss(self, x, target, weight):
return F.binary_cross_entropy_with_logits(x, target, weight=weight)
def _custom_loss_grad(self, x, target):
return torch.sigmoid(x).detach() - target
class GHMR_Loss(GHM_Loss):
# 回归损失
def __init__(self, bins, alpha, mu):
super(GHMR_Loss, self).__init__(bins, alpha)
self._mu = mu
def _custom_loss(self, x, target, weight):
d = x - target
mu = self._mu
loss = torch.sqrt(d * d + mu * mu) - mu
N = x.size(0) * x.size(1)
return (loss * weight).sum() / N
def _custom_loss_grad(self, x, target):
d = x - target
mu = self._mu
return d / torch.sqrt(d * d + mu * mu)
if __name__ == '__main__':
# 这个损失函数不需要自己进行sigmoid
output = torch.FloatTensor(
[
[0.0550, -0.5005],
[0.7060, 1.1139]
]
)
label = torch.FloatTensor(
[
[1, 0],
[0, 1]
]
)
loss_func = GHMC_Loss(bins=10, alpha=0.75)
loss = loss_func(output, label)
print(loss)10、mean_absolute_percentage_error
mape:和mae的区别就是,累加预测值和实际值的差除以实际值,然后求均值。
def mean_absolute_percentage_error(y_true, y_pred):
diff = K.abs((y_true - y_pred) / K.clip(K.abs(y_true),
K.epsilon(),
None))
return 100. * K.mean(diff, axis=-1)11、mean_squared_logarithmic_error
msle:取对数,作差,平方,累加求平均值。
def mean_squared_logarithmic_error(y_true, y_pred):
first_log = K.log(K.clip(y_pred, K.epsilon(), None) + 1.)
second_log = K.log(K.clip(y_true, K.epsilon(), None) + 1.)
return K.mean(K.square(first_log - second_log), axis=-1)12、Huber Loss

13、Log-Cosh Loss

14、Quantile Loss分位数损失
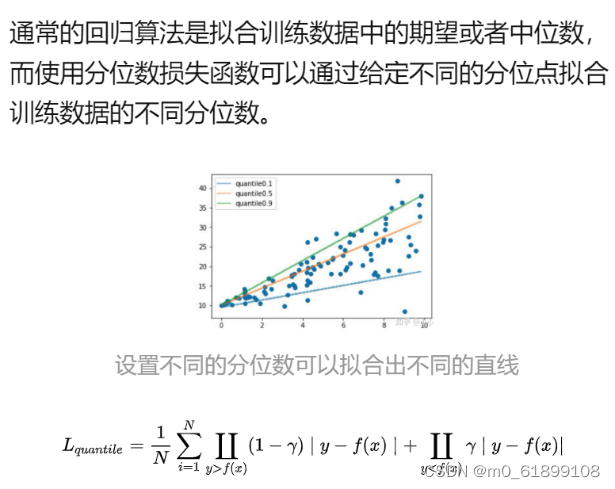
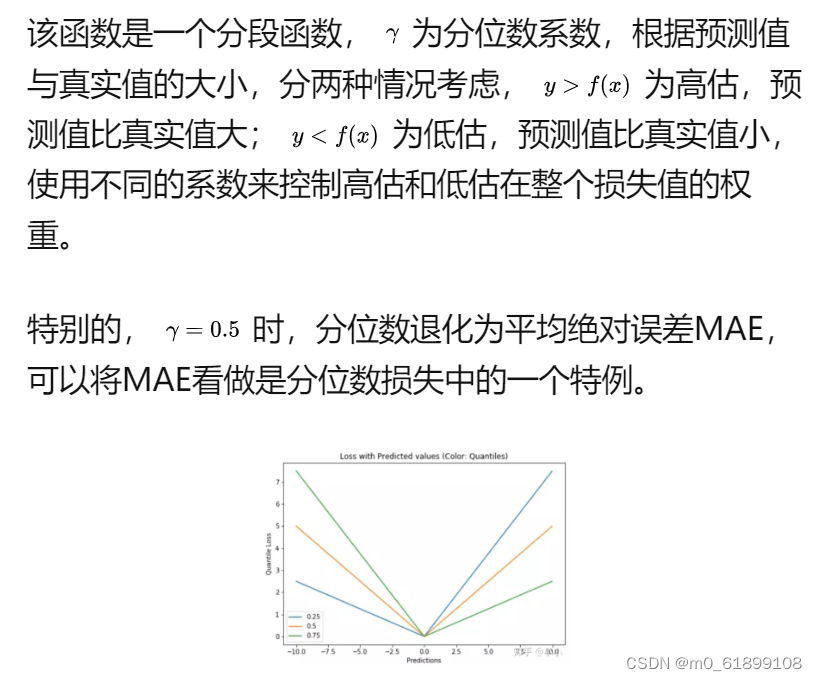
15、charbonnier


class L1_Charbonnier_loss(torch.nn.Module):
"""L1 Charbonnierloss."""
def __init__(self):
super(L1_Charbonnier_loss, self).__init__()
self.eps = 1e-6
def forward(self, X, Y):
diff = torch.add(X, -Y)
error = torch.sqrt(diff * diff + self.eps)
loss = torch.mean(error)
return loss16、wing loss
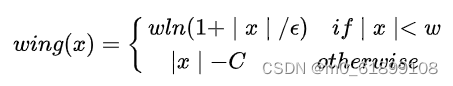
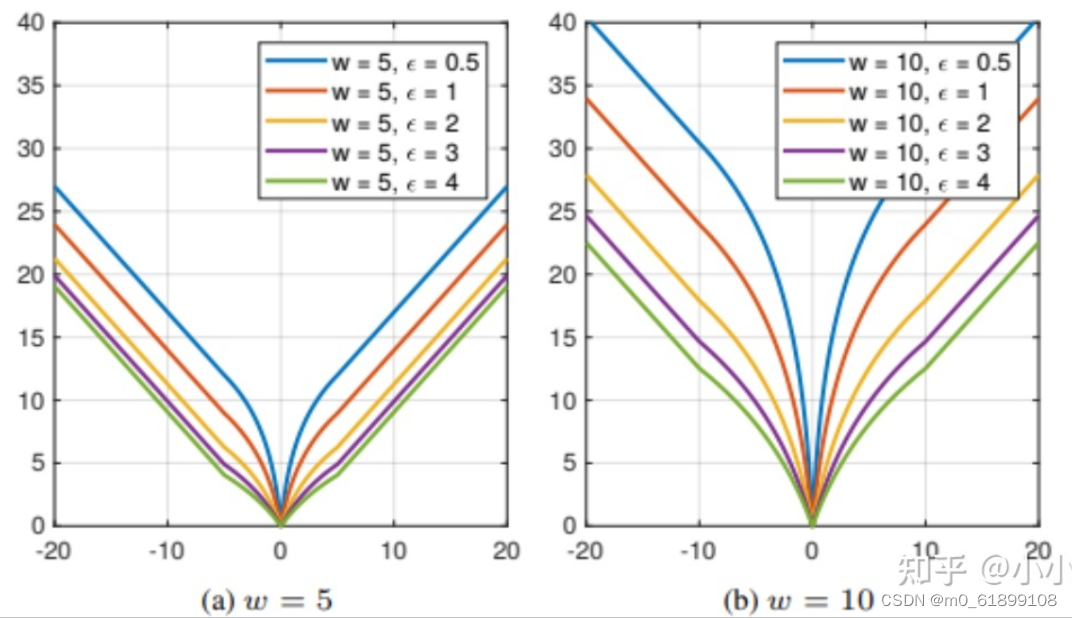
边栏推荐
- 徐翔妻子应莹回应“股评”:自己写的!
- C#/VB.NET 给PDF文档添加文本/图像水印
- [matlab] Simulink the input and output variables of the same module cannot have the same name
- Blue Bridge Cup real question: one question with clear code, master three codes
- 多线程基础:线程基本概念与线程的创建
- 巨杉数据库首批入选金融信创解决方案!
- Execution process of MySQL query request - underlying principle
- 青龙面板最近的库
- SQL injection Foundation
- Use cpolar to build a business website (1)
猜你喜欢

Xu Xiang's wife Ying Ying responded to the "stock review": she wrote it!
星诺奇科技IPO被终止:曾拟募资3.5亿元 年营收3.67亿
![[matlab] Simulink the input and output variables of the same module cannot have the same name](/img/99/adfe50075010916439cd053b8f04c7.png)
[matlab] Simulink the input and output variables of the same module cannot have the same name
![[the 300th weekly match of leetcode]](/img/a7/16b491656863e2c423ff657ac6e9c5.png)
[the 300th weekly match of leetcode]
![Deep circulation network long-term blood pressure prediction [translation]](/img/9c/c1ed28242a4536c1e8fde3414f82a8.png)
Deep circulation network long-term blood pressure prediction [translation]

How are you in the first half of the year occupied by the epidemic| Mid 2022 summary
Numerical analysis: least squares and ridge regression (pytoch Implementation)

如何提高网站权重

提前解锁 2 大直播主题!今天手把手教你如何完成软件包集成?|第 29-30 期
Mathematics in machine learning -- common probability distribution (XIII): Logistic Distribution
随机推荐
[Sun Yat sen University] information sharing of postgraduate entrance examination and re examination
Atcoder a mountaineer
Online notes
Collection of penetration test information -- use with nmap and other tools
二叉搜索树
Noninvasive and cuff free blood pressure measurement for telemedicine [translation]
十、进程管理
AIRIOT物联网平台赋能集装箱行业构建【焊接工位信息监控系统】
朗坤智慧冲刺科创板:年营收4亿 拟募资7亿
QPushButton绑定快捷键的注意事项
用友OA漏洞学习——NCFindWeb 目录遍历漏洞
Celery best practices
Some recruitment markets in Shanghai refuse to recruit patients with covid-19 positive
关于npm install 报错问题 error 1
图之广度优先遍历
Reptiles have a good time. Are you full? These three bottom lines must not be touched!
SQL injection Foundation
Handwritten online chat system (principle part 1)
三年Android开发,2022疫情期间八家大厂的Android面试经历和真题整理
Afnetworking framework_ Upload file or image server