当前位置:网站首页>根据PPG估算血压利用频谱谱-时间深度神经网络【翻】
根据PPG估算血压利用频谱谱-时间深度神经网络【翻】
2022-07-06 10:43:00 【巴川笑笑生】
根据PPG估算血压利用频谱谱-时间深度神经网络
Blood Pressure Estimation from Photoplethysmogram Using a Spectro-Temporal Deep Neural Network
摘要
血压(BP)是高血压的直接指标,高血压是一种危险的、潜在的致命疾病。因此,定期监测血压是很重要的,但许多人不喜欢袖带式设备,它们的局限性在于只能在休息时使用。在我们的研究中,仅使用光体积图(PPG)来估计BP是一个潜在的解决方案。我们分析了MIMIC III数据库中高质量的PPG和动脉BP波形,得到了预处理后超过700小时的信号,属于510名受试者。然后,我们将PPG及其一阶和二阶导数作为输入,输入到具有剩余连接的新型光谱-时间深度神经网络。我们在一个留一个受试者的实验中表明,该网络能够对PPG和BP之间的依赖性进行建模,得出收缩压和舒张压的平均绝对误差分别为9.43和6.88。此外,我们已经表明,模型的个性化是重要的,并从根本上改善了结果,而导出一个良好的通用预测模型是困难的。我们已经公开了研究的关键部分,特别是使用的受试者列表和我们的神经网络代码,以提供一个可靠的基线,并简化未来研究在显式MIMIC III子集上的潜在比较。
简介
血压(BP)测量是最重要的,最常用的医学办公室测试。血压是高血压的直接指标,是多种心血管疾病的重要危险因素(CVDs)是2015年最常见的死亡原因,根据世界卫生组织(世卫组织)[2]的数据,在全世界造成近1500万人死亡。因此,定期监测血压对普通人群很重要,但对已经患有高血压或相关疾病的人尤其重要,因为这些人特别容易受到血压[3]升高的影响。
尽管它很重要,但人们对常规的BP监测明显感到反感。这在很大程度上可以归因于测量设备的性质。基于袖带的设备仍然是黄金标准,通常被医生推荐。这些设备提供了最高的测量精度,然而,它们也有一些缺点。使用袖带式设备的人必须遵循相对严格的测量协议,以确保测量值是正确的[4]。测量过程可能是乏味的,需要专门的时间和精力。体力活动(如运动)通常不允许同时使用袖带测量血压。此外,测量事件本身会引起被测者的压力或焦虑,这反过来又会影响测量的BP值。这通常被称为白大褂综合征[5]。
由于上述因素,该领域的工作重点在于开发鲁棒的不引人注目的BP估计系统,它可以向用户提供接近实时的周期性BP更新。这种系统发展的催化剂是越来越多的可穿戴设备的出现,比如手环,它可以以一种相当不显眼的方式收集无数的生理信号。其中一种反映心血管系统状态的信号是光体积图(PPG),我们将在下一节详细描述。
PPG背景
光体积描画术是一种相当简单和廉价的技术,在医学上广泛用于测量心率和血氧饱和度。它是基于皮肤的照明和测量其光吸收的变化。它通常由一个发光二极管(LED)来照亮皮肤和一个光电探测器(光电二极管)来测量通过或从皮肤[8]反射的光的数量。
组织颜色的变化以及对光线的吸收是由体内血液循环控制的,血液循环是由跳动的心脏的收缩和舒张驱动的。心脏收缩时,心脏肌肉收缩,血液流向身体周围,因此血压会升高。这种血液脉冲波的传播导致血压升高。同样,当心脏舒张期血液充盈时,血压也会下降。这就产生了一个周期信号,它具有清晰而明确的收缩期峰值(血液在收缩期被推出心脏时的第一次穿过)和微妙的舒张期峰值(血液在舒张期从外周返回心脏)。每个周期性重复的周期包含一个收缩期峰值和一个舒张期峰值。前者通常很容易检测到,可以用来确定心率(HR),而后者有时很明显,但更多时候很难正确检测到。理想波形和常见异常的示例如图1所示。
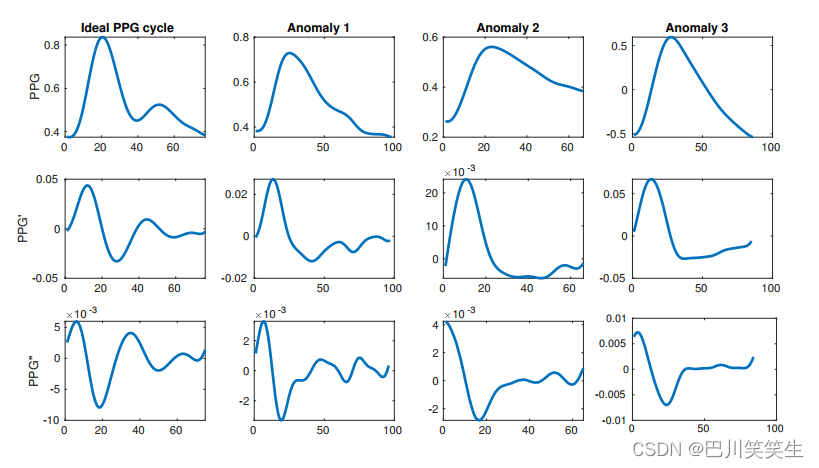
图1所示。理想光体积图(PPG)周期波形及其畸变波形旁的一阶和二阶导数。理想的例子有一个较大的收缩期峰值和一个较低的舒张期峰值,而异常有太多或太少的峰值。所有数据都来自于mimiciii数据库[11]。
如果用PPG来测量血流速度,即通常所说的脉搏波速度(PWV)[9],那么PPG和BP之间的关系就得到了很好的证实。当血管变硬或收缩得更厉害时,血液流动得更快,压力也更大。同样,当血管更放松或更有弹性时,血液流动更慢,施加的压力也更小。从心脏发出的脉搏到达身体外周点所需的时间称为脉搏传递时间(PTT)[10]。当PTT较短时,表示血压较高,而PTT较长则表示血压较低。然而,为了使用这种方法,需要两个传感器,通常是在心脏上的心电图(ECG)和在身体外周点的PPG
心脏活动时血容量的细微变化,反映在PPG信号的形态上,似乎也与BP有关。然而,这种关系目前仅用机器学习建模。推导这样一个模型是最近1.3节讨论的密集研究的主题,也是我们的工作
BP估计的PTT方法
1922年,Bramwell等人首次研究了PWV与血管刚度之间的数学基础和相关性,并将其形式化。两根铜管连接到动脉上,水银以波的形式通过该装置。选择水银而不是实际血液是因为动脉段非常短,随后用于测量PWV的时间间隔也非常短。
Geddes等人于1981年[10]初步分析了动脉血压(ABP)与PTT之间的特异性联系。他们评估了10只麻醉犬的脉搏到达时间与舒张压(DBP)的关系。用化学方法控制血压,测量心电图信号R峰值在颈动脉和股动脉中对应收缩期的时间。PTT和DBP的变化呈良好的近线性相关
Chan等人在2001年创建了一个用于远程医疗的无袖BP估计系统的简单系统[12]。一组未确定人数的受试者参加了实验室实验,他们的心电图和PPG以1500 Hz的采样率测量,他们的地面真实值BP用带手铐的装置计算。测量PTT,每个受试者20个疗程用于校准。在此校准后,PTT和BP之间显示出线性关系。他们使用实际血压和预测血压之间的平均误差(以毫米汞柱(mmHg)为度量标准,得出收缩压(SBP)的ME为7.5,舒张压(DBP)的ME为4.1。使用ME进行评估可能会产生问题,因为在总体平均值中,同样巨大的正差异和负差异会相互抵消,显示出较低的总体ME,即使单个ME很大。
PTT方法最近的一个例子是Kachuee等人在2017年[13]发表的,该方法的范围与我们自己的工作类似。BP是通过mimicii数据库中大约1000名受试者估算出来的。采用预处理后的PPG和ECG来获得ptt相关特征,并以ABP作为基础真实值。采用10倍交叉验证(CV)实验评估几种回归模型。使用Adaptive Boosting (AdaBoost)取得了最好的结果,特别是SBP和DBP的平均绝对误差(MAE)为11.17和5.35。他们还在工作中使用了针对个人的校准,这改善了结果。与前面提到的工作相比,报告的评估指标更合适,并能更好地洞察结果
最近兴起的深度学习,被证明在许多领域都非常有效,也反映在这个研究领域。Su等人在2018年[14]发表了一篇论文,其中强调了现有PPG BP估计模型在长时间内精度下降的问题。这个问题意味着需要经常校准。采用一种具有长短时记忆(LSTM)的深度循环神经网络(RNN)对BP进行时间依赖性建模。以PPG和ECG作为输入,PTT和其他一些特征用于预测血压。与现有方法相比,他们的BP预测精度得到了长期的提高,同时保持了与相关工作相当的实时预测精度。
在过去的10年里,PTT方法经过了彻底的测试[15,16],并提出了一些轻微的变化,然而,基本原则没有改变。这种方法的缺点是需要两个传感器来测量PTT,这使得它比单设备方法更不方便。这也意味着必须对两个信号进行监控、预处理和分析。最后,由于必须跟踪相同的脉冲波,两个(通常是无线的)传感器之间的精确同步和峰值检测是至关重要的,在处理开始之前需要大量的努力。
单ppg BP估计方法
上一节提到的缺点,以及越来越多的可穿戴设备的出现,催生了使用单一PPG信号的新研究。本研究的重点是PPG形态的分析,借助通常描述每个周期PPG波形形状的特征。
Teng等人在2003年[17]进行了仅使用PPG信号进行BP估计的最早尝试之一。他们分析了ABP和PPG波形中某些特征之间的关系。数据收集自15名年轻健康受试者,使用专业设备,在高度控制的环境中,确保恒温、无运动和安静。通过相关性分析进行特征选择,并采用线性回归算法对关系进行建模。收缩压和舒张压的ME值分别为0.21 7.32 mmHg和0.02 4.39 mmHg。由于前面所述的原因,使用ME而不是MAE再次成为一个潜在的问题。此外,样本量很小,条件受到高度控制,所以这些结果如何转化为更实际的环境是值得怀疑的
Kurylyak等人在2013年[18]发表了一篇关于使用神经网络从PPG中进行BP估计的被引用率最高的论文。他们使用了MIMIC II数据库中的一小部分数据,首先计算出了21个特征,这些特征详细描述了单个PPG周期的形状。研究这些特征与BP之间的相关性,然后将这些特征输入人工神经网络(ANN)训练预测模型。他们报告收缩压MAE为3.80 3.46,舒张压MAE为2.21 2.09。结果很好,但是只使用了MIMIC数据库的一个小的未公开子集
Xing等人在2016年[19]发表了一项重要的近期研究。他们使用了来自MIMIC II数据库的69名患者和另外23名志愿者。首先对所有信号进行严格的预处理,以获得高质量的波形。与之前使用时间特征的工作不同,他们使用快速傅里叶变换(FFT)从频域的波形中提取振幅和相位特征。将这些特征再次输入人工神经网络,得到了良好的结果,符合BP估计装置的主要标准。一个特殊的贡献是在患者中标准化PPG波形的提议,据说消除了校准的需要。
我们知道,没有直接使用原始PPG信号作为深度学习BP估计的输入,然而,Gotlibovych等人在2018年[20]研究了使用原始PPG数据进行房颤检测,并取得了合理的成功,这暗示了原始信号输入的潜力
除了综述的相关工作,还有大量其他高质量的论文在该领域发表,但他们遵循的是使用PPG信号来计算基于周期的特征的既定方法,然后用这些特征来训练回归ML模型,所以他们没有单独讨论。
我们在研究的背景下进行相关的工作
建立良好的PTT方法在该领域占据主导地位,这是意料之中的,因为描述PTT和BP相关性的潜在机制已经形式化并得到了良好的测试。在可穿戴设备、移动健康和远程医疗的时代,纯PPG方法确实有很多优势,也很有意义,但人们对PPG信号的理解和研究较少,这促使我们只关注PPG信号。
相关工作中常见的情况是使用不可用的私有收集的数据集或未指定的MIMIC数据库子集。一方面,对于私人收集的数据,这是可以理解的,因为医疗数据是敏感的,收集这些数据的研究人员可能无法获得共享的许可。另一方面,当使用公开可用的数据集(如MIMIC)时,应该指定获取它的选定子集或过程。鉴于科学中普遍存在的可重复性危机[21],使用未公开或公开不可用的数据可能是有问题的。这个问题被本文的作者也遇到了几次,因为使用的具体数据和实验的代码几乎从来没有从作者那里获得
在相关工作中,不与总是预测训练数据均值的回归因子进行比较也是常见的。这是很重要的,因为可能会出现一个选定的数据子集的基本真实BP值范围很小(例如,BP值相对恒定的受试者),在这种情况下,误差会很低,但这并不一定意味着模型已经学习了比预测平均值多得多的东西。
这促使我们的研究从完整的公开可用的MIMIC数据库(版本III)开始,将其缩小到具有明确描述滤波的高质量波形子集,这使我们得到用于训练和评估的最终子集。由于数据库非常庞大(数万个主题,每个主题可能有几个记录会话),它也非常适合与深度学习一起使用,后者可以使用原始信号作为输入,推导出自己的特征。这是有价值的,因为相关工作依赖于一组相当标准的特征,这些特征需要完美的波形,严重依赖于单个明确的舒张峰值,而这通常很难检测,甚至缺失。此外,[22]的一些相关工作也表明,来自PPG波形的一阶(PPG)和二阶(PPG)的额外特征更难一致地检测,如图1所示。
我们通过以下方式处理所讨论的问题:
使用精确指定的大型MIMIC III数据库子集,其中包含可用的id和用于获取它的相应代码,以及
将PPG及其衍生物的波形直接输入到一种新型的频谱-时间残差神经网络中,成功地模拟了PPG与BP之间的关系。据我们所知,我们提出的神经网络架构是该领域迄今为止最复杂的,因为它考虑了PPG波形及其导数中包含的时间和频率信息。体系结构的细节将在后面的部分中描述,模型的代码是可用的。
材料与方法
如前所述,我们的工作基于MIMIC III数据库[11,23],可在https://physionet.org/physiobank/database/mimic3wdb/上获得。该数据库包含3万多名16岁或以上患者住院期间记录的各种不同类型的数据。成年患者中位年龄为65.8岁,男性占55.9%,女性占44.1%。每个病人都可能有多个记录,从几秒(通常是异常情况)到几小时不等。我们对记录床旁波形的患者很感兴趣,特别是那些同时有PPG和ABP信号的患者。一旦对数据进行清理和预处理,首先计算特征,然后训练一个经典的ML模型(随机森林)。最后,将原始数据作为输入输入深度神经网络(DNN),以预测SBP和DBP。
获取和清理原始数据
由于完整的数据库非常大,在最初获取数据和随后选择适合机器学习的高质量波形的患者方面存在一些挑战。如此大量的数据的好处是,我们可以在清洗过程中非常严格,因为在每个清洗步骤之后都会留下大量的数据。
我们最初使用自定义DataMiner.sh bash脚本下载数据。为了下载所需的MATLAB格式的数据,使用了WFDB软件包[23],具体来说就是wfdb2mat函数。一台专用服务器负责下载数据并将其保存到本地存储。我们最初注意到一些下载的文件是空的,或者包含极少量的示例。为了节省空间,经验确定的大小阈值为17千字节的文件被Cleaner.sh bash脚本删除,甚至不考虑进行进一步的清理步骤。该脚本还删除了不包含PPG和ABP波形的文件(在文件中指定为PLETH和ABP)。这一步骤使我们减少到大约1万名患者。
之后,我们进行了更详细的清洗程序,处理波形质量。首先,将PPG和ABP所需的最小长度设置为10分钟。删除所有长度较短的录音,因为我们想要足够长的波形,至少包含一些SBP和DBP的变化。然后将PPG信号归一化到零平均单位方差,用4阶巴特沃斯带通滤波器滤波,截止频率分别为0.5 Hz和8 Hz。低于0.5赫兹的都可以被认为是基线徘徊,而高于8赫兹的都是高频噪声。然后,利用Hampel滤波器再次对信号进行滤波,以去除异常值。这需要一个包含7个后续PPG样本的滑动窗口,并计算该窗口的中值。然后它估计每个样本关于窗口中位数的标准差。如果样本与窗口中位数相差超过三个标准差,则用中位数[24]替换。选择Hampel滤波器而不是中位数,因为它被证明是略优于信号处理[25]的一些相关工作,也因为它的效果已经证明是令人满意的视觉检查。需要注意的是,尽管有时可以在ABP波形中观察到一些高频噪声,但这些噪声没有以任何方式进行滤波或预处理,因为它可能会略微影响信号值,而信号值是SBP和DBP的ground truth。SBP是心脏收缩期出现的一个ABP周期(或段)的峰值(或检测峰值的平均值),而DBP是在舒张期出现的ABP周期之间的谷。
然后这些信号被分割成周期,每个周期对应一次心跳。利用Elgendi等人[26]提出的峰谷检测器进行分割。作者证明了该算法比传统的用于PPG信号的峰值检测器更快、更有效,最重要的是,更精确。在最初的经验检验中,它在我们的数据集上工作得很好,但由于ground truth峰值不知道,很难做一个精确的评估。这可以由专家通过目测来手工分割PPG周期,但是这样的工作要求很高
分割成周期,然后对波形进行实证评估。我们绘制了大量随机记录的PPG和ABP的短随机片段,这使我们能够识别波形形态中常见的滤波后问题。这些主要可以分为两大类
平线:在PPG和ABP正常周期之间的较长时间内,有时会出现平线,如图2所示。当三个或多个连续的信号样本没有改变它们的值时,检测到一条平坦的线。这种平线可以在信号的几个单独的片段中观察到,我们假设它们是由周期性传感器异常或传感器分离引起的。这些区域是无用的,因此被从波形中切除
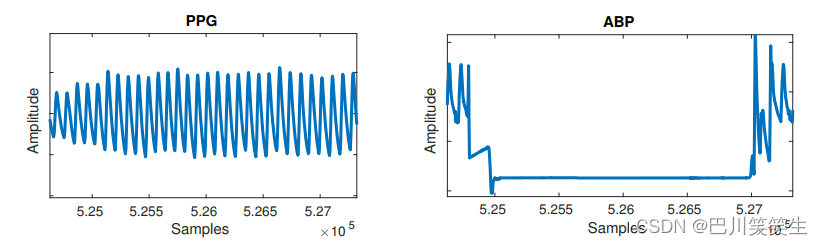
图2。动脉血压(ABP)信号可见平线异常。
平峰:类似地,ABP波形通常有平峰,顶部部分缺失,如图3所示。将PPG分割成多个周期后,通过检查在给定周期内是否有三个或多个连续样本具有相同的值来类似地检测峰值。原因仍然未知,但很可能是传感器的问题。ABP的峰值是至关重要的,因为它的值就是SBP,这是机器学习所需的ground truth。
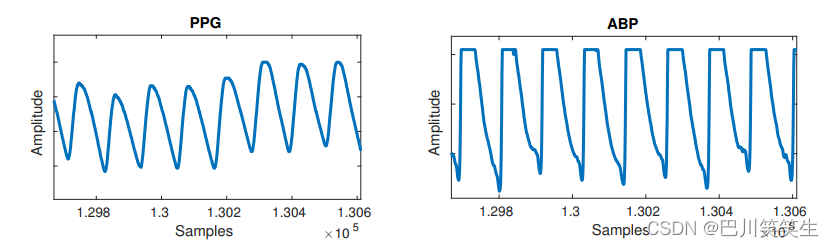
图3。在ABP信号中可以观察到平峰异常。
与以前一样,由于数据量的原因,我们应用了一个相当严格的标准,如果超过5%的周期有平坦的峰值,或者超过10%的记录持续时间由平坦的线组成,我们就从数据集中删除这个记录。
最后,将剩余的平线或平峰周期从波形中切除,只需去掉剩余平线起始点和结束点之间的PPG和ABP部分,或者,如果是周期,则将整个周期切除。图4总结了整个流程。
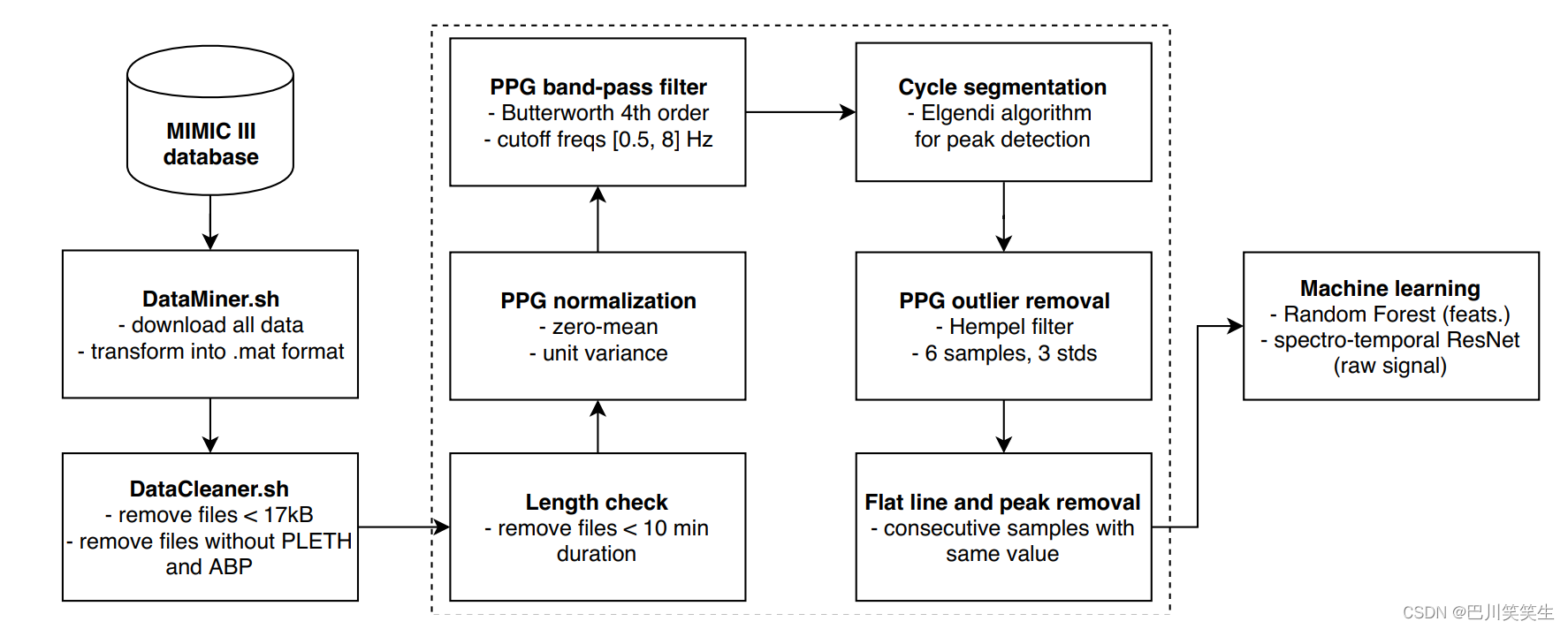
图4。本系统的管道示意图
一旦清洗完成,510名患者保留了下来,每个患者至少有一个高质量的波形记录,持续至少10分钟。我们的目标是创建一个包含自然发生的PPG波形的完整变化的数据集(如图1所示的波形),同时避免极有可能归咎于传感器问题的异常(这在我们的数据集中非常普遍)。平均而言,清理后受试者有5次1.3小时的记录,总共将近700小时的训练数据。我们最终数据的SBP和DBP分布如图5所示。
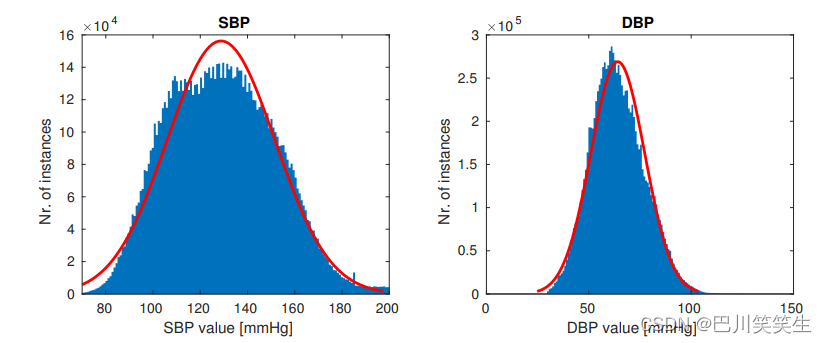
图5。收缩压(SBP)和舒张压(DBP)在我们最终数据中的分布。
MIMIC数据库的作者报告了PPG和ABP之间可能存在的轻微延迟。考虑到这一点,由于BP在常见情况下(不包括动脉出血、强效药物等)不会发生实质性变化,我们通过取传统ML在特定PPG周期附近ABP 2短段内检测到的峰值和谷值的平均值,从而获得基本真实的SBP和DBP。对于深度学习中使用的PPG片段,由于PPG和ABP具有非常相似的波形,所以使用相同的峰值检测算法进行检测,耗时5 s。由于神经网络中的谱图层对信号有足够的周期性,为了提取频率内容的有意义的信息,我们选择更长的一段进行深度学习。传统的机器学习以周期为基础,因此取的片段更短(理想情况下,只取一个PPG周期对应的量,但在某些边缘情况下,可能会发生ABP的收缩期峰值没有捕获,因此选择了更长的长度)。
经典的机器学习
由于相关工作已经表明,传统的回归模型可以很好地处理一组广泛使用的特征,我们进行了这样一个实验,以便与深度学习进行比较。我们计算了一组在之前讨论的相关工作中常用的特征。Yousef等人也暗示了PPG和PPG[22]的潜在有用性,因此我们也试图从中提取特征。所有的共同特征都描述了每个周期PPG波形的形态。因此,数据最初被分割为多个周期,特征计算所需的点(例如,收缩峰)是在原始PPG周期及其一阶导数上确定的。尽管二阶导数也被提出,但它的波形并没有表现出预期的峰数,因此不可能使用这些特征。表1给出了所有使用的特性。与我们之前的工作[27]相比,我们通过添加频域的特征在语义上扩展了我们的特征集。大部分频域特征由Welch ’ s方法[28]得到的PSD计算得到。与此同时,我们删除了一些在过去被证明没有价值的功能。
| 域 | 特征 |
|---|---|
| 时域 | T c T_{c} Tc周期持续时间 |
| T s T_{s} Ts从周期开始到收缩期高峰的时间 | |
| T d T_{d} Td从收缩期高峰到周期结束的时间 | |
| T s t e e p e s t T_{steepest} Tsteepest。PPG '(最陡点)从周期开始到第一个峰值的时间 | |
| T d i a n o r t c h T_{dianortch} Tdianortch。从周期开始到第二个峰PPG’的时间 | |
| T S y s T o D i a N o t c h T_{SysToDiaNotch} TSysToDiaNotch。从收缩期高峰到小凹期的时间 | |
| T d i a T o E n d T_{diaToEnd } TdiaToEnd。从重脉到循环结束的时间 | |
| 比率。收缩期和舒张期振幅之比 |
表1。根据每个周期的PPG计算的特征。
| 域 | 特征 |
|---|---|
| 频域 | 三个最大的幅度。从PSD中考虑了三个最大量级的峰。这些告诉我们周期中的主要频率。以幅值和频率(Hz)为特征。 |
| 能量。计算为快速傅里叶变换(FFT)分量大小的平方和。然后通过除以周期长度将能量归一化。$能量=\frac{1}{N}\sum_{n=0}^{N-1} | |
| 熵。计算为归一化的FFT分量大小的信息熵。 熵 = − s u m n = 0 N − 1 x ( n ) l o g ( x ( n ) ) 熵=-sum_{n=0}^{N-1}x(n)log(x(n)) 熵=−sumn=0N−1x(n)log(x(n)) | |
| 统计分布。一个归一化的直方图,本质上是FFT的大小分布到10个大小相等的容器中,范围从0 Hz到62.5 Hz。 | |
| 偏态和峰态。这些描述了周期的形状。更准确地说,偏度告诉我们对称性,而峰度告诉我们平坦度。 |
在理想情况下,预计PPG周期有两个峰值(收缩期和舒张期),PPG也有两个峰值。然而,我们的数据是关于PPG舒张切迹的特征,PPG的两个峰很难计算,因为舒张切迹非常细微,甚至没有,如图1所示。在这些情况下,在收缩期峰值和周期结束之间PPG最接近零的点(PPG信号最平缓的点)被用来计算处理舒张notch的特征。
这些特征最终被输入到使用100棵树的scikit-learn的默认随机森林(RF)实现中,并运行了一个留一个被试者(LOSO)实验,我们将在后续章节中详细描述这个实验。
深度学习
为了向神经网络提供输入数据的完整表示,我们使用了原始PPG、PPG和PPG的短片段作为深度学习的时域输入。此外,利用从时间输入段计算的频谱图来获取频域信息。为了明智地利用声谱图,需要至少包含一些周期行为的信号片段。因此,我们将信号分成5秒的片段,而不是以前使用的通常持续不到1秒的单个周期。训练网络输出数值的SBP和DBP,从而解决回归任务。
神经网络结构与超参数
我们提出的频谱时间ResNet示意图如图6所示。ResNet的想法最初是由He等人[29]提出的,用于训练带有消失梯度问题的非常深的网络,在这个问题中,向后的误差传播被削弱了,第一层没有充分更新它们的权值。因此,在较大的层块之间提出了快捷(剩余)连接。Su et al.[14]还表明,剩余连接在PTT的BP估计这一特定领域也有帮助。
对于三个输入(PPG, PPG和PPG)中的每一个,时间表示都由每个包含三层卷积(CNN)的残差块提取。每个CNN层后面都有一个批处理归一层,以减少内部协变量的偏移,以及一个ReLU激活层,相比其他激活,可以加快训练过程。每个剩余块最终都有一个平均池化层,用于降维。该网络还提取输入特定的光谱时间信息。光谱层提取光谱信息,对三个输入的每个5s输入段进行谱图计算。光谱层的输出被用于门控循环单位(GRU),以获得时间变化。
然后,每一堆5个剩余块的输出被连接并传递到另一个GRU层。同样,频谱-时间块的输出也被串联起来。两个数据流在最后时刻连接在一起,并在两个密集(完全连接)层中使用。网络的最终输出由ReLu层提供,它输出给定窗口的预计SBP和DBP值。在每一层谱图之后使用GRU单元,以便为随后的密集层提供谱图时间变化的额外信息。实验表明,这是被测试者中最好的网络结构。
训练模型的学习率为 1 0 − 4 10^{-4} 10−4,衰减率为 1 0 − 4 10^{-4} 10−4。批大小设置为256,最大训练epoch设置为20,当三个epoch没有看到改进时提前停止。网络参数包括残差块数、每个块的CNN层数、CNN滤波器的大小、学习率和批量大小都是通过实验确定的,可以进行额外的优化。
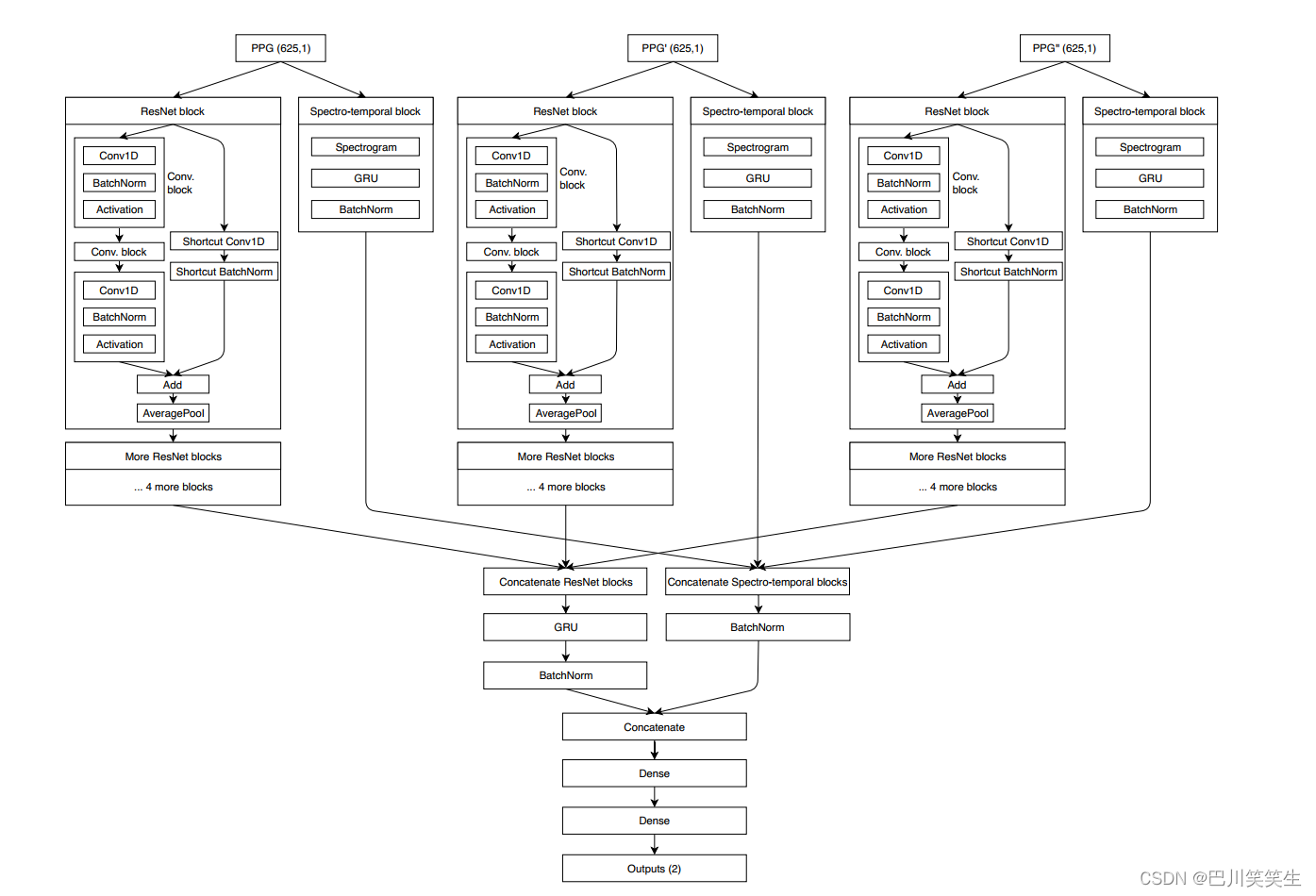
图6。我们的神经网络架构示意图。
通过将梯度反向传播到所有层,对网络的训练进行完全监督。通过使用RMSprop优化器最小化MAE损失函数来优化参数。在初始训练过程结束后,利用最佳epoch的权重作为个性化的起点。在个性化的过程中,我们选择20%的给定对象的数据来额外训练我们的网络。受试者的其他数据被用于最后的测试。20%的数据已经被证明足以显著改善结果,如表2所示。
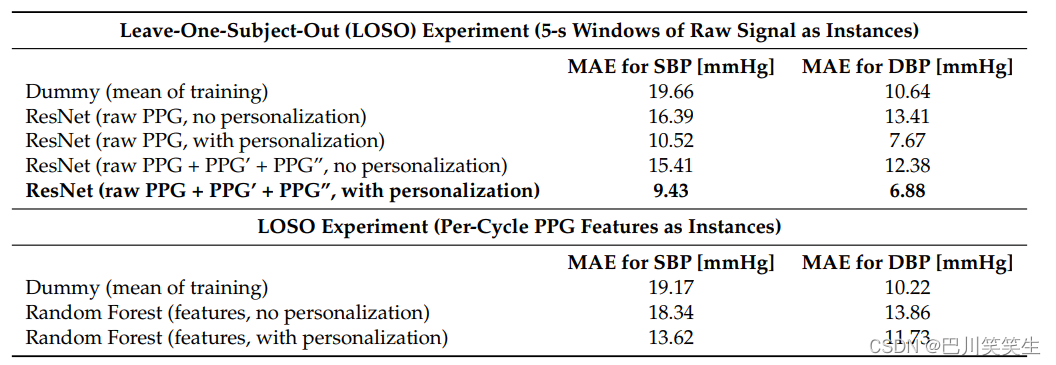
表2。通过经典ML和深度学习实现的平均绝对误差(MAEs)具有和不具有个性化。
实验装置
为了训练和评估一个良好的通用模型,我们进行了LOSO实验。这样的实验在泛化性能方面是最稳健的,因为它完全独立于人。在n次迭代中(n =被试人数),每一次迭代中,有n 1个被试的数据用于训练,而被遗漏的被试的数据用于测试。每次迭代计算MAE,并以平均值的形式给出最终MAE。
与典型的训练测试分离相比,这种实验设置的一个优势在于,后者可能会受到过度乐观或过度悲观的结果的困扰,这些结果可能通过非常具体的分离获得,而在LOSO设置中,结果不取决于分离的选择。
在传统方法中,我们分别建立SBP和DBP模型,而训练神经网络同时预测两者,有两个输出。
这个实验的缺点是计算非常复杂,尤其是在训练ResNet时,因为整个网络必须训练n次。考虑到实验的数据量和复杂性,GPU集群几乎是必须的。在我们的实验中,我们使用了包含4个nVidia 1080Ti 8GB单元的GPU服务器和使用nVidia Quadro P6000 24gb单元的工作站的组合。描述的整个数据集上的LOSO实验花费了一周的时间
结果
与相关工作相比,LOSO实验的初始独立于人的结果欠佳。因此,采用神经网络结构与超参数节末尾所述的个性化(校准)方法,对结果有了较大的改善,如表2所示。在每次LOSO迭代中,总误差以单个mae的平均值计算。将所有结果与一个虚拟回归因子进行比较,该回归因子始终输出列车集的SBP和DBP的均值作为预测。
与虚拟回归因子相比,所有模型都实现了更低的收缩压误差,证实了PPG信号及其衍生品中存在一些关于BP的信息,并且可以在一定程度上建模潜在的关系。然而,哑回归显示低DBP误差,因为DBP有更低的方差和一般更稳定。个性化显著改善了结果,表明BP和PPG之间的关系是主体依赖的。
通过对传统的基于手工特征的ML方法和基于原始信号作为输入的深度学习方法的比较,发现后者效果更好。可能的原因是,它有更强的学习能力,手工制作的特征不能从原始输入中获取像DNN那样多的信息,或者常用的特征不能成功地在具有不完美波形的变化很大的数据集上使用。
最后,我们比较了仅使用PPG作为我们的ResNet输入与使用PPG及其一阶和二阶导数。可以看出,求导使总MAE减少了大约1 mmHg,暗示导数波形中包含了额外的有用信息。
讨论和结论
我们的工作与第1.2节和第1.3节讨论的相关工作的比较见表3。总的来说,我们发现由于不同的评估指标和不同且不充分指定的数据集,很难比较这一领域的相关工作。此外,一些作者没有明确报告训练数据中是否包括任何测试对象的数据(我们在表中以未知的个性化表示这一点)。最小的错误是在公共或私人收集的带有未知个性化的小子集上实现的,而处理大规模数据的工作(Kachuee et al.[13]和我们的工作)有更大的错误,这暗示在大型数据集上创建一个健壮的通用模型的困难。造成这种情况的原因可能是大型MIMIC III数据集包含大量不同的受试者以及潜在不同的PPG和ABP测量设备
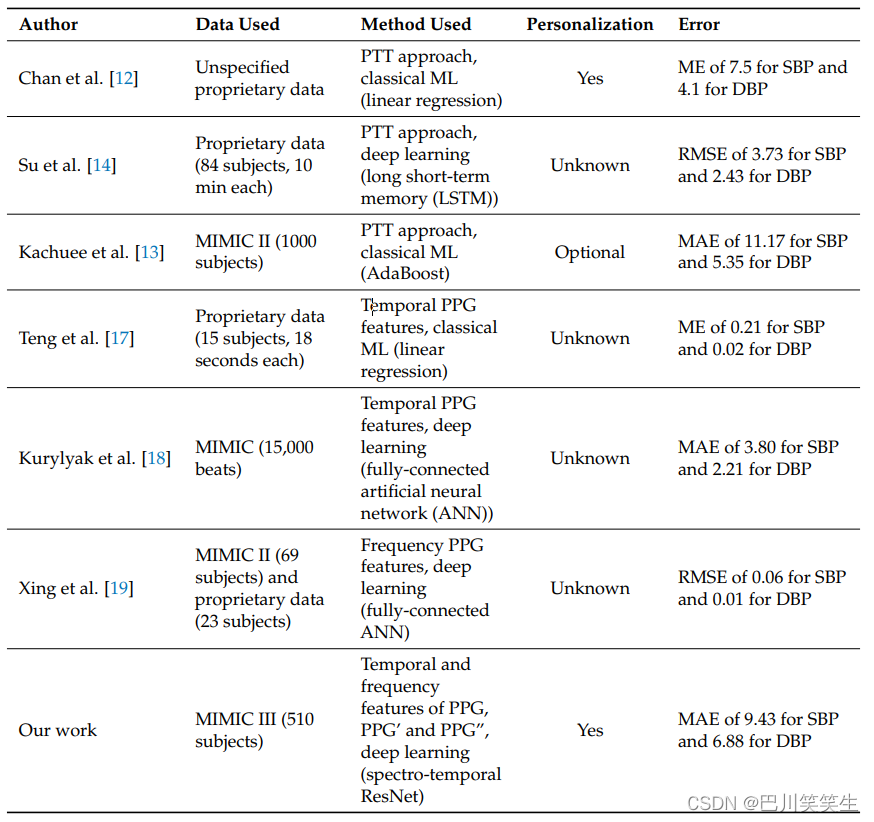
在数据使用、方法和误差方面与已有的相关工作进行比较。
从个别相关论文来看,与Chan等人[12]和Teng等人[17]进行比较是不可行的,因为他们使用ME作为衡量标准。Su等人[14]使用了一种现代LSTM深度学习架构,但与只使用PPG信号相比,使用了PTT方法。Kurylyak等人[18]实现了较低的误差,但使用了相当少量未指明的数据,即使用了15000拍,这相当于3小时多一点的信号(假设平均周期长度为0.8 s)。他们也没有明确说明该数据属于多少被试,只是拍的总数,这意味着该数据的变化和独立性是未知的。由于Xing等人[19]报告的极小误差,我们试图重现他们的工作。我们不能完全这样做,使用类似的网络架构和输入,我们的错误更大。尽管与使用PTT方法相比只需要一个PPG信号,但我们的DNN取得的结果与Kachuee等人[13]取得的结果相当,这表明我们的网络架构非常适合这个问题。据我们所知,到目前为止,还没有任何工作使用原始PPG及其两个导数作为输入到神经网络,以成功地估计BP。这一点很重要,因为它表明,在一个大数据集上,仅使用PPG信号进行BP评估是可行的。此外,提出的神经网络架构允许融合三个输入,以及每个输入的频率和时间信息。
除了新颖的DNN架构之外,另一个贡献是详细描述了过滤数据以获得我们的子集的过程,并提供了用于训练和评估的最终主题。作者也在https://github.com/gasper321/bp-estimation-mimic3上提供了DataMiner.sh、Cleaner.sh和MATLAB预处理代码,以及我们的神经网络模型定义的Python代码,这允许研究人员进一步构建我们的工作,并使他们能够彼此比较。注意,这段代码是实验性的,用于研究,不健壮,也不适合生产。
主要的限制在于个性化需求,这意味着模型需要一些真实的数据来适应每个用户。在实践中,这意味着用户必须使用高质量的袖口设备测量他们的PPG和SBP/DBP,然后将这些数据交给模型进行个性化设置。虽然这需要一些努力,但这似乎是一个合理的成本,可以监测BP,而无需用户事后采取任何行动。个性化的计算需求在GPU上是几分钟,这在服务器上不是问题,但目前在监控设备本身上可能是不可行的。作为一个额外的限制,噪声很大的数据可能是有问题的,特别是对于导数波形,因为它们的形状变得非常畸形
由医疗器械促进协会、欧洲高血压学会和国际标准化组织提出的血压测量装置验证标准[参考文献]要求估计可容忍误差(10 mmHg)的概率至少为85%。没有个性化设置的结果肯定不能满足这一要求,但有了个性化设置的结果就接近了(平均误差是可以容忍的,尽管这对于小于85%的个别错误是正确的)。通过一些适度的改进,使用单个PPG传感器进行个性化BP估计,因此可以足够准确地用于提供信息的家庭使用
基于ppg的BP估计提供了更大的舒适度,并在家庭环境中潜在地提高了用户对这一重要测量的依从性。虽然MIMIC III数据库没有提供关于获得PPG信号的设备的信息,但它们可能是指尖血氧饱和度监测仪。它们当然适合一次测量,有时用这种设备对患者进行连续监测,因此可以同时监测血压。指尖设备一般不适合在门诊使用,因此必须使用不同的设备进行不引人注目的连续血压监测。手环是配备PPG传感器的最普遍的设备,目前提供的PPG信号较差,尽管其他传感器如摄像头[30]也在为此目的进行探索。总之,我们认为本文的结果表明,使用单个PPG传感器进行BP估计可能适用于一次BP测量,而它们对连续BP监测的适用性有限。
和度监测仪。它们当然适合一次测量,有时用这种设备对患者进行连续监测,因此可以同时监测血压。指尖设备一般不适合在门诊使用,因此必须使用不同的设备进行不引人注目的连续血压监测。手环是配备PPG传感器的最普遍的设备,目前提供的PPG信号较差,尽管其他传感器如摄像头[30]也在为此目的进行探索。总之,我们认为本文的结果表明,使用单个PPG传感器进行BP估计可能适用于一次BP测量,而它们对连续BP监测的适用性有限。
边栏推荐
- 44所高校入选!分布式智能计算项目名单公示
- 从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
- node の SQLite
- This article discusses the memory layout of objects in the JVM, as well as the principle and application of memory alignment and compression pointer
- Maixll dock camera usage
- C语言高校实验室预约登记系统
- Jerry is the custom background specified by the currently used dial enable [chapter]
- Picture zoom Center
- 巨杉数据库首批入选金融信创解决方案!
- node の SQLite
猜你喜欢

【LeetCode第 300 场周赛】
Windows connects redis installed on Linux
30 minutes to understand PCA principal component analysis
![[Sun Yat sen University] information sharing of postgraduate entrance examination and re examination](/img/a8/41e62a7a8d0a2e901e06c751c30291.jpg)
[Sun Yat sen University] information sharing of postgraduate entrance examination and re examination

Blue Bridge Cup real question: one question with clear code, master three codes

Alibaba cloud international ECS cannot log in to the pagoda panel console

爬虫玩得好,牢饭吃到饱?这3条底线千万不能碰!
监控界的最强王者,没有之一!
Maixll-Dock 摄像头使用
Top command details
随机推荐
Echart simple component packaging
DOM Brief
徐翔妻子应莹回应“股评”:自己写的!
MS-TCT:Inria&SBU提出用于动作检测的多尺度时间Transformer,效果SOTA!已开源!(CVPR2022)...
Stm32+esp8266+mqtt protocol connects onenet IOT platform
44所高校入选!分布式智能计算项目名单公示
With the implementation of MapReduce job de emphasis, a variety of output folders
二叉搜索树
2022-2024年CIFAR Azrieli全球学者名单公布,18位青年学者加入6个研究项目
Reprint: defect detection technology of industrial components based on deep learning
Recursive way
STM32+HC05串口蓝牙设计简易的蓝牙音箱
使用block实现两个页面之间的传统价值观
Easy to use PDF to SVG program
Stm32+hc05 serial port Bluetooth design simple Bluetooth speaker
一种用于夜间和无袖测量血压手臂可穿戴设备【翻译】
Rb157-asemi rectifier bridge RB157
epoll()无论涉及wait队列分析
echart简单组件封装
[.Net core] solution to error reporting due to too long request length