当前位置:网站首页>Understanding disentangling in β- VAE paper reading notes
Understanding disentangling in β- VAE paper reading notes
2022-07-06 18:46:00 【zeronose】
List of articles
Preface
article :Understanding disentangling in β-VAE
Link to the original text : link
Understanding disentangling in β-VAE Is based on β-VAE An article from .
First ,β-VAE There are several problems in :
1.β-VAE Just by KL Item adds a super parameter β, It is found that the model has decoupling characteristics , But there is no good explanation for adding a super parameter β Will produce decoupling characteristics .
2.β-VAE Find out , When the decoupling effect is good, the reconstruction effect is not good , When the reconstruction effect is good, the decoupling effect is poor , So we need to balance decoupling and reconstruction .
Based on this ,Understanding disentangling in β-VAE adopt Information bottleneck theory given β-VAE Explanation of decoupling , And for β-VAE We need to balance decoupling and reconstruction , They put forward their own training methods ---- Gradually increase the amount of information of potential variables in the training process .
The original text also introduces VAE And β-VAE, It's just more here , Interested can see my previous article
VAE
β-VAE
One 、 What is the information bottleneck ?

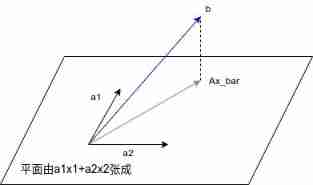
The figure below is the explanation of the information bottleneck in the original text , In fact, information bottleneck describes a constrained optimization goal , The goal is to maximize potential bottlenecks Z And tasks Y Mutual information between , At the same time, discard the input X About Y All irrelevant information .
Drawing is troublesome , Let's make do with it , As shown in the figure below 
You can see β-VAE The loss function of is :
L(θ, ϕ, β; x, z) = Eqϕ(z|x)ln pθ(x|z)− βKL (qϕ(z|x) || p(z))
The first term on the right of the equation is the reconstruction term , The second term is the regular term . The second is the information bottleneck of the first , Increase the weight of the second term, that is β Value , Also is to let qϕ(z|x) Closer to the p(z), because p(z) It's the standard Zhengtai distribution , At this time, the implicit variables are limited z It contains x The amount of information , Therefore, the decoupling effect is good, but the reconstruction effect is poor , On the contrary, the decoupling effect is poor , The effect of refactoring is good .
Two 、 New training goals
1. Loss function
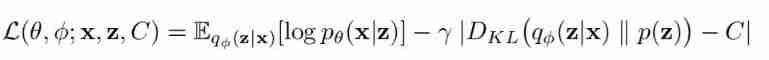
among ,γ Fixed to a larger number 1000,C Is a variable number . In the process of training ,C Gradually increase from zero to a value large enough to produce high-quality reconstruction .
The training process here is similar to β-VAE Different ,β-VAE During training , It needs to be fixed first β Value then train , change β You need to retrain after the value . there C Is a variable parameter , It also becomes the amount of information , He is in the process of training , from 0 Gradually increasing .
summary
By controlling the increase of potential posterior coding ability in the training process , Allow the previous average KL The difference increases gradually from zero , Not the original β-VAE Fixed in the target β weighting KL Increase of items . Compared with the result of the original formula , It promotes Robust learning of disentangled representation , Combined with better reconstruction fidelity .
边栏推荐
- Coco2017 dataset usage (brief introduction)
- Nuc11 cheetah Canyon setting U disk startup
- echart简单组件封装
- SQL injection Foundation
- How are you in the first half of the year occupied by the epidemic| Mid 2022 summary
- 裕太微冲刺科创板:拟募资13亿 华为与小米基金是股东
- Blue Bridge Cup real question: one question with clear code, master three codes
- 深度循环网络长期血压预测【翻译】
- Penetration test information collection - basic enterprise information
- 监控界的最强王者,没有之一!
猜你喜欢
CSRF漏洞分析
![[the 300th weekly match of leetcode]](/img/a7/16b491656863e2c423ff657ac6e9c5.png)
[the 300th weekly match of leetcode]
Nuc11 cheetah Canyon setting U disk startup
AvL树的实现

Excellent open source fonts for programmers

44 colleges and universities were selected! Publicity of distributed intelligent computing project list
Numerical analysis: least squares and ridge regression (pytoch Implementation)

C#/VB.NET 给PDF文档添加文本/图像水印
Method of accessing mobile phone storage location permission under non root condition
Docker installation redis
随机推荐
随着MapReduce job实现去加重,多种输出文件夹
Stm32+esp8266+mqtt protocol connects onenet IOT platform
Splay
Epoll () whether it involves wait queue analysis
美庐生物IPO被终止:年营收3.85亿 陈林为实控人
Crawling data encounters single point login problem
Oracle advanced (IV) table connection explanation
Noninvasive and cuff free blood pressure measurement for telemedicine [translation]
Splay
Celery best practices
2022-2024年CIFAR Azrieli全球学者名单公布,18位青年学者加入6个研究项目
[Matlab] Simulink 同一模块的输入输出的变量不能同名
Penetration test information collection - basic enterprise information
Numerical analysis: least squares and ridge regression (pytoch Implementation)
SQL injection - access injection, access offset injection
About NPM install error 1
C#/VB.NET 给PDF文档添加文本/图像水印
AcWing 3537.树查找 完全二叉树
First, look at K, an ugly number
[sword finger offer] 60 Points of N dice