当前位置:网站首页>Numerical analysis: least squares and ridge regression (pytoch Implementation)
Numerical analysis: least squares and ridge regression (pytoch Implementation)
2022-07-06 18:18:00 【u012804784】
Python Wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python Actual quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
Chapter 4
1. Least squares and normal equations
1.1 Two perspectives of least squares
From the perspective of numerical calculation, the least square method
When we study numerical linear algebra , Learned that when the solution of the equation exists , How to find Ax=b\textbf{A}\bm{x}=\bm{b} Solution . But what should we do when the solution does not exist ? When the equation is inconsistent ( unsolvable ) when , It is possible that the number of equations exceeds the number of unknown variables , We need to find the second possible solution , The least square approximation . This is the numerical calculation perspective of the least square method .
From a statistical perspective, the least square method
We learned how to find polynomial fitting data points accurately in numerical calculation ( That is interpolation ), But if there are a large number of data points , Or the collected data points have certain errors , In this case, we generally do not use high-order polynomials for fitting , Instead, a simple model is used to approximate the data . This is the statistical perspective of least squares .
1.2 The normal equation is derived from the perspective of numerical calculation
For a system of linear equations Ax=b\textbf{A}\bm{x}=\bm{b},A\textbf{A} by n×mn\times m Matrix , We will A\textbf{A} regard as Fm→Fn\textbf{F}^m \rightarrow \textbf{F}^n The linear mapping of . For mapping A\textbf{A}, The case where the system of equations has no solution corresponds to b∉range(A)\bm{b}∉\text{range}(\textbf{A}), namely b\bm{b} Not mapped A\textbf{A} Within the range of , namely b∉{Ax|x∈Rm}b∉ {\textbf{A}\bm{x} | \bm{x}∈\textbf{R}^{m}}.( And this is equivalent to b\bm{b} Not in the matrix A\textbf{A} The column vector In the open space ). We have to
(111−111)(x1x2)=(213)\left (
\begin{matrix}
1 & 1 \
1 & -1 \
1 & 1
\end{matrix}
\right)
\left(
\begin{matrix}
x_1 \
x_2
\end{matrix}
\right)=
\left(
\begin{matrix}
2 \
1 \
3
\end{matrix}
\right)
take (111)\left( \begin{matrix} 1\ 1\ 1 \end{matrix}\right) Treat as column vector a1\bm{a}_1,(1−11)\left(\begin{matrix}1\-1\1\end{matrix}\right) Treat as column vector a2\bm{a}_2,(213)\left(\begin{matrix}2\1\3\end{matrix}\right) Treat as column vector b\bm{b}, Then the linear system is shown in the figure below :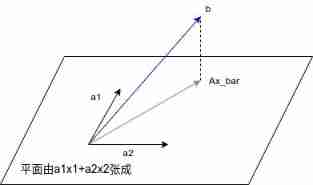
Although solution x\bm{x} non-existent , But we still want to find the plane composed of all candidate points Ax\textbf{A}\bm{x} And b\bm{b} The closest point ¯x\overline{\bm{x}}( pronounce as x\bm{x}_bar).
Observation map 1, We find special vectors A\textbf{A} It has the following characteristics : Remainder b−A¯x\bm{b}-\textbf{A}\overline{\bm{x}} Peace surface {Ax|x∈Rn}{\textbf{A}\bm{x} | \bm{x} \in \textbf{R}^n } vertical . That is for Rn\textbf{R}^n All the x\bm{x}, All have vectors Ax\textbf{A}\bm{x} Sum vector b−A¯x\bm{b}-\textbf{A}\overline{\bm{x}} orthogonal , namely *Ax,b−A¯x*⩾0\langle \textbf{A}\bm{x},\bm{b}-\textbf{A}\overline{\bm{x}}\rangle \geqslant0, Written in the form of matrix multiplication , We have :
(Ax)T(b−A¯x)=0(\textbf{A}\bm{x})^T(\bm{b}-\textbf{A}\overline{\bm{x}})=0
Based on the properties of matrix transpose , We have :
xTAT(b−A¯x)=0\bm{x}T\textbf{A}T(\bm{b}-\textbf{A}\overline{\bm{x}})=0
Because of x\bm{x} Taking any value, the formula satisfies , Then we must have :
AT(b−A¯x)=0\textbf{A}^T(\bm{b}-\textbf{A}\overline{\bm{x}})=0
Then we get the normal equation ( Because we use normal here to deduce , It can also be called normal equation ):
ATA¯x=ATb\textbf{A}T\textbf{A}\overline{\bm{x}}=\textbf{A}T\bm{b}
The solution of the equation ¯x\overline{\bm{x}} It's a system of equations Ax=b\textbf{A}\bm{x} = \bm{b} The least square solution of . If we adopt the form of numerical optimization instead of analytical , This least square solution can also be seen as an optimization formula argminx12||Ax−b||2\underset{x}{\text{argmin}} \frac{1}{2} ||\textbf{A}\bm{x} − \bm{b}||^2 Solution .
1.3 Derive the normal equation from the perspective of Statistics
There is a commonly used model in statistics called linear regression , Put the data matrix X∈Rm×n\textbf{X}∈\textbf{R}^{m\times n}(mm Samples , nn Characteristic dimensions ) As input , Predicted vector y∈Rm\bm{y}∈\textbf{R}^m(m\bm{m} Samples , One label per sample ) As output . The output of linear regression is the linear function of input , Make ˆy\hat{\bm{y}} Indicates that the model predicts y\bm{y} The value that should be taken . We define
ˆy=Xw \hat{\bm{y}}=\textbf{X}\bm{w}
among w∈Rn\bm{w}∈\textbf{R}^n Is the parameter (parameter) vector .
Next, we adopt the perspective of machine learning .《 machine learning : An artificial intelligence method 》 in Tom.Mitchell The definition of machine learning is :“ Hypothetical use PP To evaluate a computer program in a certain task class TT Performance on , If a program uses experience EE On mission TT Performance improvement on , Then we say about TT and PP, This task is right EE Learned .” We divide the samples into training data {x(i)train,y(i)train}{\bm{x}_{train}^{(i)}, y_{train}{(i)}} And test data {x(i)test,y(i)test}{\bm{x}_{test}{(i)}, y_{test}{(i)}} Use training data {x(i)train,y(i)train}{\bm{x}_{train}{(i)}, y_{train}^{(i)}} As experience , Train the model according to certain strategies , obtain ww Vector value , then Use the same strategy on the test set to evaluate the performance of the model .
The evaluation strategy adopted by our model is to evaluate the mean square error on the test set (MSE,mean squared error):MSEtest=1m∑i(ˆy(i)test−y(i)test)2\text{MSE}_{test} = \frac{1}{m}\sum_{i}(\hat{y}_{test}^{(i)} − y_{test}{(i)})2. We observe the training set {x(i)train,y(i)train}{\bm{x}_{train}^{(i)}, y_{train}^{(i)}} Gain experience , Reduce the mean square error on the training set MSEtest=1m∑i(ˆy(i)test−y(i)test)2\text{MSE}_{test} = \frac{1}{m}\sum_{i}(\hat{y}_{test}^{(i)} − y_{test}{(i)})2 To improve the weight bmwbm{w}( Be careful , Machine learning is different from traditional optimization , Optimization simply optimizes an objective function , and Machine learning is to reduce the error on the training set in order to reduce the error on the test set , That is, the pursuit of generalization . and This often faces the problems of under fitting and over fitting , The regularization technique mentioned later is needed to solve ), Minimizing this mean square error formula is actually the same as the most Maximize the expectation of log likelihood Ex∼ˆpdatalogpmodel(ytrain|xtrain,θ)\mathbb{E}_{\bm{x}\sim \hat{p}_{data}}\text{log}_{p_{model}}(y_{train}|\bm{x}_{train}, \bm{θ}) The obtained parameters are the same . here ˆpdata\hat{p}_{data} Is the empirical distribution of the sample . However . The mean square error we want to minimize ( Or loss function ) It's a convex function , In other words, we can use the numerical optimization algorithm we learned earlier ( Such as Newton method , Gradient descent method , See 《 First and second order optimization algorithms 》) The only optimal solution can be found . However , The beauty of the least squares problem is that it can find an analytical solution without numerical iteration . The steps of calculating the analytical solution are as follows :
Here we simply use the first derivative condition discrimination method , But even ∇wMSEtrain∇_\bm{w}\text{MSE}_{train}, namely :
∇w1m||ˆytrain−ytrain||22=01m∇w||Xtrainw−ytrain||22=0∇w(Xtrainw−ytrain)T(Xtrainw−ytrain)=0∇w(wTXTtrainXtrainw−2wTXTtrainytrain+yTtrainytrain)=02XTtrainXtrainw−2XTtrainytrain=0XTtrainXtrainw=XTtrainytrain\nabla_{\bm{w}}\frac{1}{m}||\hat{\bm{y}}_{train}-\bm{y}_{train}||_2^2 = 0\
\frac{1}{m}\nabla_{\bm{w}}||\textbf{X}_{train}\bm{w}-\bm{y}_{train}||_2^2=0 \
\nabla_{\bm{w}}(\textbf{X}_{train}\bm{w}-\bm{y}_{train})^T(\textbf{X}_{train}\bm{w}-\bm{y}_{train})= 0 \
\nabla_{\bm{w}}(\bm{w}T\textbf{X}_{train}T\textbf{X}_{train}\bm{w}-2\bm{w}T\textbf{X}_{train}T\bm{y}_{train}+\bm{y}_{train}^T\bm{y}_{train})=0\
2\textbf{X}_{train}^T\textbf{X}_{train}\bm{w} - 2\textbf{X}_{train}^T\bm{y}_{train} = 0\
\textbf{X}_{train}^T\textbf{X}_{train}\bm{w} = \textbf{X}_{train}^T\bm{y}_{train}
In this way, we get the normal equation of statistical perspective , It is equivalent to the normal equation we derived from the point of view of numerical calculation .
It is worth noting that , In addition to our weight W\textbf{W} outside , Often add an offset bb, such y=Xw+b\bm{y} = \textbf{X}\bm{w} + b.
We want to continue to solve the normal equation derived above , You need to put this bb Incorporate the weight vector w\bm{w} in ( It's the following w1w_1). about X∈Rm×n\textbf{X}\in \mathbb{R}^{m\times n}, We give X\textbf{X} Expand a column , Yes :
(1X1,1…X1,n1⋮⋱⋮1Xm,1…Xm,n)(w1⋮wn+1)=(y1⋮ym)\left(
\begin{matrix}
1 &X_{1,1}&\dots & X_{1,n} \
1 &\vdots & \ddots & \vdots \
1 &X_{m,1} &\dots & X_{m,n}
\end{matrix}
\right)
\left(
\begin{matrix}
w_1\
\vdots\
w_{n+1}
\end{matrix}
\right)
= \left(
\begin{matrix}
y_1\
\vdots\
y_m
\end{matrix}
\right)
Then we can continue to solve it according to the normal equation in front of us .
We also have polynomial fitting form of least squares , Allow us to fit the data with polynomial curves spot .( About given directional quantity w\bm{w} The function of is nonlinear , But what about w\bm{w} The function of is linear , Our normal equation solution is still valid ) However, this requires us to preprocess the data matrix first , obtain :
(1X1,1…Xn1,n1⋮⋱⋮1Xm,1…Xnm,n)\left(
\begin{matrix}
1 &X_{1,1}&\dots & X_{1,n}^n \
1 &\vdots & \ddots & \vdots \
1 &X_{m,1} &\dots & X_{m,n}^n
\end{matrix}
\right)
Then the solution method is the same as that we mentioned before .
1.4 Approximate solutions of matrix equations and matrix Moore-Penrose Pseudo pseudo ( Generalized inverse )
The normal equation we obtained earlier based on the perspective of numerical calculation is :ATAˆx=ATb\textbf{A}T\textbf{A}\hat{\bm{x}}=\textbf{A}T\bm{b}
Normal equation based on the perspective of probability and statistics :XTXw=XTy\textbf{X}T\textbf{X}\bm{w}=\textbf{X}T\bm{y}
Obviously , These two formulas are equivalent , It's just that the names of letters are different . generally speaking , We will adopt the letter naming style according to the context . If the context is numerical calculation , Then we will adopt The first way to write it , If the context is probabilistic , We will adopt the second way .
Now let's continue the symbolic naming style of numerical calculation , But the idea of statistics and machine learning Our understanding is also very helpful . about ATAx=ATb\textbf{A}T\textbf{A}\bm{x}=\textbf{A}T\bm{b}, We will ATA\textbf{A}^T\textbf{A} transposition , obtain :
¯x=(ATA)−1ATb\overline{\bm{x}} = (\textbf{A}T\textbf{A}){-1}\textbf{A}^T\bm{b}
When a linear system Ax=b\textbf{A}\bm{x}=\bm{b} When there is no solution , Immediate cause A\textbf{A} Irreversible, resulting in failure to follow x=A−1b\bm{x}=\textbf{A}{-1}\bm{b} When solving the problem , We can put the right side of the equation (ATA)−1AT(\textbf{A}T\textbf{A}){-1}\textbf{A}T As a linear system Ax=b\textbf{A}\bm{x}=\bm{b} in A\textbf{A} The pseudo inverse of .
From the previous derivation, we know that this pseudo inverse is obtained from the normal equation of the least squares problem . The least square can also be described as an optimization problem for numerical iteration , The optimal solution solved x\bm{x} by
argminx12||Ax−b||22\underset{\bm{x}}{\text{argmin}}\frac{1}{2} ||\textbf{A}\bm{x} - \bm{b} ||_2^2
there 12\frac{1}{2} It is manually derived and matched for the sake of square . And in machine learning , In order to avoid models Over fitting , We'll do... On the objective function Regularization (regularization). From the perspective of optimization , That's Tim Add penalty items to avoid excessive weight . We will write the regularized optimization formula :
argminx12||Ax−b||22+c||x||22\underset{\bm{x}}{\text{argmin} }\frac{1}{2}||\textbf{A}\bm{x} − \bm{b}||_22+c||\bm{x}||_22
It is known by manual derivation , The normal equation corresponding to this least squares problem is :
(ATA+cI)¯x=ATb(\textbf{A}^T\textbf{A}+c\textbf{I})\overline{\bm{x}} = \textbf{A}^T\bm{b}
The new pseudo inverse form of matrix is obtained as :
(ATA+cI)−1AT(\textbf{A}T\textbf{A}+c\textbf{I}){-1}\textbf{A}^T
We will make this more “ comprehensive ” The pseudo inverse form of is called Moore-Penrose Pseudo inverse (Moore-Penrose pseudoinverse), Always remember to do A+\textbf{A}^+. Note that it is opposite to the other one in the quasi Newton method Hessian Matrix approximation Shaann Pseudo inverse makes a difference .
The function of pseudo inverse is often used when A\textbf{A} Irreversible ( strange ) For matrix equations Ax=b\textbf{A}\bm{x}=\bm{b} The approximate solution of , It has important applications in the field of numerical calculation .
2. Ridge Regression and Lasso
Previously, we gave the optimal solution when the objective function is not regularized x\bm{x} by
argminx12||Ax−b||22 \underset{\bm{x}}{\text{argmin}} \frac{1}{2} ||\textbf{A}\bm{x} − \bm{b}||_2^2
Because we are going to discuss the regularization of machine learning , So we adopt the machine learning perspective , take A\textbf{A} As a data matrix X\textbf{X},x\bm{x} As an optimization vector w\bm{w}, It is omitted for the convenience of manual derivation and matching 12\frac{1}{2}, And make one 1m\frac{1}{m},mm Is the number of samples . Then we get the mean square error (MSE, mean squared error)
MSE=1m||Xw−y||22\text{MSE} = \frac{1}{m}||\textbf{X}\bm{w} − \bm{y}||_2^2, In the field of machine learning, it is generally called the mean square error loss function (MSE Loss), Such optimal solution writing :
argminw1m||Xw−y||22\underset{w}{\text{argmin}} \frac{1}{m}||\textbf{X}\bm{w} − \bm{y}||_2^2
Add regular items , writing :
argminw1m||Xw−y||22+λ||w||22\underset{\bm{w}}{\text{argmin}}\frac{1}{m}||\textbf{X}\bm{w} − \bm{y}||_22+λ||\bm{w}||_22
\tag{1}
Where the regularization parameter λ>0λ>0.
here , Because the regular term is introduced ||w||22||\bm{w}||_2^2, We call it using L2L_2 Regularization . The corresponding regression problem is called ridge regression( Ridge return / Pole regression )
We define pp norm , The regular term is ||w||pp||\bm{w}||_p^p The regularization of is LpL_p Regularization .
There is a special kind of regularization , It's called Lasso( pronounce as “ inhaul cable ”), It corresponds to L1L_1 Regularization :
argminx1m||Xw−y||22+λ||w||11\underset{\bm{x}}{\text{argmin}} \frac{1}{m}||\textbf{X}\bm{w} − \bm{y}||_22+λ||\bm{w}||_11
\tag{2}
Where the regularization parameter λ>0λ>0.
L1L_1 Norm sum L2L_2 Norm regularization can help reduce the risk of over fitting , But the former also brings an additional benefit : It is easier to obtain than the latter ” sparse “(sparse) Explain , That is, it obtains ww There will be fewer non-zero components .( in fact , Yes ww exert “ Sparse constraint ”( Hope ww As few non-zero components as possible ) The most natural thing is to use L0L_0 norm (L0L_0 Norm can be understood as the absolute value of all dimensions of a vector , Then take the largest dimension ). but L0L_0 Norm discontinuity , It's not convex , Its optimization is NP-hard Of , Therefore, it is often used L1L_1 Norm to approximate .L1L_1 Norm optimization is a convex optimization problem , There is a numerical optimal solution in polynomial time )
To understand this , Let's look at an intuitive example : Suppose any sample x\bm{x} There are only two properties , So whether it is L1L_1 Regularization is still L2L_2 Regularized solution w\bm{w} There are only two components , namely w1w_1 and w2w_2. We take it as two coordinate axes , Then draw the formula in the figure (1)(1) Sum formula (2)(2) The first item is ” contour “, That is to say (w1,w2)(w_1,w_2) The connecting line of points with the same value of square error term in space , Draw L1L_1 Norm sum L2L_2 Isoline of norm , That is to say (w1,w2)(w_1,w_2) In the space L1L_1 The connecting line of points with the same norm , as well as L2L_2 The connecting line of points with the same norm , As shown in the figure below .( The picture is from 《 Watermelon book 》253 page )
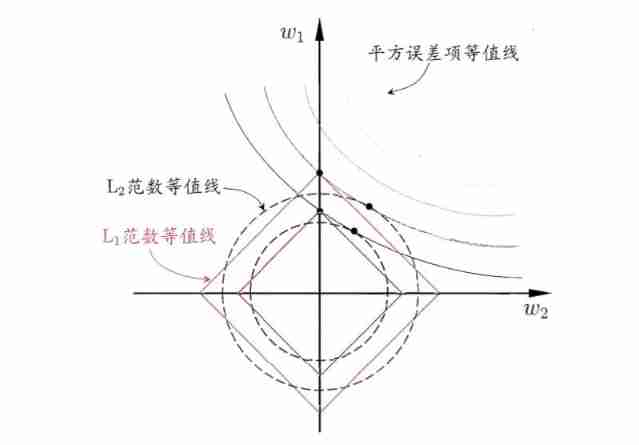
type (1)(1) Sum formula (2)(2) The solution of is to make a compromise between the square error term and the regularization term , That is, it appears at the intersection of the isoline of the square error term and the isoline of the regularization term . As can be seen from the picture , use L1L_1 The intersection point of the square error isoline and regularization isoline often appears on the coordinate axis , namely w1w_1 and w2w_2 by 0, And in the use of L2L_2 When the norm is , The intersection of the two appears in a quadrant of China , namely w1w_1 and w2w_2 None 0; In other words , use L1L_1 Norm ratio L2L_2 Norm is easier to get sparse solution .
L2 Regularization can also be understood from the perspective of quadratic programming , See 《 Statistical learning 3: Linear support vector machines (Pytorch Realization )》
The following is the algorithm description of the least squares analytic solution :
example 1 The analytical solution of the least squares ( Variables to be optimized c=(w,b)\bm{c}=(w,b),xx Is the abscissa of the data point , However, you need to preprocess the expansion constant first ,yy Is the ordinate of the data point )
import numpy as np
if __name__ == '\_\_main\_\_':
x = np.array(
[
[-1],
[0],
[1],
[2]
]
)
y = [1, 0, 0, -2]
# For data matrix x Preprocessing , That is, the expansion constant 1 The column of
# here A A total of two columns , The highest number is only 1 Time
A = np.concatenate([np.ones([x.shape[0], 1]), x], axis=1)
AT_A = A.T.dot(A)
AT_y = A.T.dot(y)
c_bar = np.linalg.solve(AT_A, AT_y)
print(" Parameters obtained by least square estimation :", c_bar)
# Condition number
print(" Condition number :", np.linalg.cond(AT_A))
Here, because the splicing operation is involved , So the vector x\bm{x} Write matrix ( Column vector ) form .
The analytical solution and condition number are respectively :
Parameters obtained by least square estimation : [ 0.2 -0.9]
Condition number : 2.6180339887498953
example 2 Polynomial fitting of least squares ( Variables to be optimized c=(w1,w2,b)\bm{c}=(w_{1},w_{2},b), The data points are still points on the two-dimensional plane ,xx It is still the abscissa of the data point , In addition to expansion, it also needs to preprocess the calculation of the power term .yy It is still the ordinate of the data point )
import numpy as np
if __name__ == '\_\_main\_\_':
x = np.array(
[
[-1],
[0],
[1],
[2]
]
)
y = [1, 0, 0, -2]
# For data matrix x Preprocessing , Calculate the power value of the second column from the third column ( Or fitting points on the plane , But it expands )
# here A There are three columns , The highest number is 2 Time , It's a parabola
A = np.concatenate([np.ones([x.shape[0], 1]), x, x**2], axis=1)
AT_A = A.T.dot(A)
AT_y = A.T.dot(y)
c_bar = np.linalg.solve(AT_A, AT_y) # The API AT\_y It's one dimension / Two dimensional is ok
print(" Parameters obtained by least square estimation :", c_bar)
# Condition number
print(" Condition number :", np.linalg.cond(AT_A))
Analytic solution and A The conditions of are :
Parameters obtained by least square estimation : [ 0.45 -0.65 -0.25]
Condition number : 20.608278259652856
The least squares can also be written in the form of iterative solutions , The following is the solution of the least squares with the gradient descent method .
example 2 Iterative solution of least squares
import numpy as np
import torch
def mse\_loss(y\_pred, y, w, lam, reg):
m = y.shape[0]
return 1/m*torch.square(y-y_pred).sum()
def linear\_f(X, w):
return torch.matmul(X, w)
# Gradient descent method realized before , Made some minor changes
def gradient\_descent(X, w, y, n\_iter, eta, lam, reg, loss\_func, f):
# Initialize calculation chart parameters , Be careful : Here is to create a new object , Non parametric references
w = torch.tensor(w, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, w)
loss_v = loss_func(y_pred, y, w, lam, reg)
loss_v.backward()
with torch.no_grad():
w.sub_(eta*w.grad)
w.grad.zero_()
w_star = w.detach().numpy()
return w_star
# This model is designed according to the multi classification architecture
def linear\_model(
X, y, n\_iter=200, eta=0.001, loss\_func=mse\_loss, optimizer=gradient\_descent):
# Initialize model parameters
# We make w and b The fusion ,X Add one dimension later
X = np.concatenate([np.ones([X.shape[0], 1]), X], axis=1)
w = np.zeros((X.shape[1],), dtype=np.float64)
# Call the gradient descent method to optimize the function
# Here, a single iteration is used to estimate all samples , Later, we will introduce the small batch method to reduce the time complexity
w_star = optimizer(X, w, y, n_iter, eta, mse_loss, linear_f)
return w_star
if __name__ == '\_\_main\_\_':
X = np.array(
[
[-1],
[0],
[1],
[2]
], dtype=np.float32
)
y = np.array([1, 0, 0, -2], dtype=np.float32)
n_iter, eta = 200, 0.1, 0.1
w_star = linear_model(X, y, n_iter, eta, mse_loss, gradient_descent)
print(" Parameters obtained by least square estimation :", w_star)
It can be seen that after enough iterations (200) Time , Finally, it converges to the optimal solution ( Equal to the analytical solution we found before (0.2, -0.9)):
Parameters obtained by least square estimation : [ 0.2 -0.9]
Least squares can also use regularization terms to constrain weights , The following is the least square solution of the term to be regularized by the gradient descent method .
example 3 Iterative solution of least squares ( With regular term )
import numpy as np
import torch
def mse\_loss(y\_pred, y, w, lam, reg):
# here y Is to create a new object , There will be y Turn into (batch\_size. 1) form
m = y.shape[0]
if reg == 'L2':
reg_item = lam*torch.square(w).sum()
elif reg == 'L1':
reg_item = lam*torch.norm(w, p=1).sum()
else:
reg_item = 0
return 1/m*torch.square(y-y_pred).sum() + reg_item
def linear\_f(X, w):
return torch.matmul(X, w)
# Gradient descent method realized before , Made some minor changes
def gradient\_descent(X, w, y, n\_iter, eta, lam, reg, loss\_func, f):
# Initialize calculation chart parameters , Be careful : Here is to create a new object , Non parametric references
w = torch.tensor(w, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, w)
loss_v = loss_func(y_pred, y, w, lam, reg)
loss_v.backward()
with torch.no_grad():
w.sub_(eta*w.grad)
w.grad.zero_()
w_star = w.detach().numpy()
return w_star
# This model is designed according to the multi classification architecture
def linear\_model(
X, y, n\_iter=200, eta=0.001, lam=0.01, reg="L2", loss\_func=mse\_loss, optimizer=gradient\_descent):
# Initialize model parameters
# We make w and b The fusion ,X Add one dimension later
X = np.concatenate([np.ones([X.shape[0], 1]), X], axis=1)
w = np.zeros((X.shape[1],), dtype=np.float64)
# Call the gradient descent method to optimize the function
# Here, a single iteration is used to estimate all samples , Later, we will introduce the small batch method to reduce the time complexity
w_star = optimizer(X, w, y, n_iter, eta, lam, reg, mse_loss, linear_f)
return w_star
if __name__ == '\_\_main\_\_':
X = np.array(
[
[-1],
[0],
[1],
[2]
], dtype=np.float32
)
y = np.array([1, 0, 0, -2], dtype=np.float32)
n_iter, eta, lam = 200, 0.1, 0.1
reg = "L1"
w_star = linear_model(X, y, n_iter, eta, lam, reg, mse_loss, gradient_descent)
print(" Parameters obtained by least square estimation :", w_star)
No regularization , Let the regularization coefficient λ\lambda by 0, The number of iterations and learning rate remain unchanged , You can see that the final estimation result is the same as the previous example :
Parameters obtained by least square estimation : [ 0.2 -0.9]
use L2L_2 Norm regularization , The regularization coefficient is 0.1, The number of iterations and learning rate remain unchanged , You can see the norm of the whole parameter vector ( It can be understood as size ) It's getting smaller , It can be seen that regularization limits the norm of parameters :
Parameters obtained by least square estimation : [ 0.14900662 -0.82781457]
Note that the gradient descent method used here is not a random algorithm , Reproducible , The algorithm runs many times and the same result is obtained .
quote
- [1] Timothy sauer. numerical analysis ( The first 2 edition )[M]. Mechanical industry press , 2018.
- [2] Golub, Van Loan. Matrix computing [M]. People's post and Telecommunications Press , 2020.
- [3] zhou . machine learning [M]. tsinghua university press , 2016.
- [4] Ian Goodfellow,Yoshua Bengio etc. . Deep learning [M]. People's post and Telecommunications Press , 2017.
边栏推荐
- echart简单组件封装
- Transport layer congestion control - slow start and congestion avoidance, fast retransmission, fast recovery
- 【Android】Kotlin代码编写规范化文档
- 78 year old professor Huake has been chasing dreams for 40 years, and the domestic database reaches dreams to sprint for IPO
- Ms-tct: INRIA & SBU proposed a multi-scale time transformer for motion detection. The effect is SOTA! Open source! (CVPR2022)...
- Virtual machine VirtualBox and vagrant installation
- 华为0基金会——图片整理
- Splay
- bonecp使用数据源
- Jielizhi obtains the currently used dial information [chapter]
猜你喜欢

Interesting - questions about undefined
Kivy tutorial: support Chinese in Kivy to build cross platform applications (tutorial includes source code)

Declval (example of return value of guidance function)

Take you through ancient Rome, the meta universe bus is coming # Invisible Cities

287. 寻找重复数
Introduction to the usage of model view delegate principal-agent mechanism in QT

78 year old professor Huake has been chasing dreams for 40 years, and the domestic database reaches dreams to sprint for IPO

Excellent open source fonts for programmers

2019阿里集群数据集使用总结

Alibaba cloud international ECS cannot log in to the pagoda panel console
随机推荐
Transfer data to event object in wechat applet
UDP协议:因性善而简单,难免碰到“城会玩”
287. 寻找重复数
C语言自动预订飞机票问题
Alibaba cloud international ECS cannot log in to the pagoda panel console
转载:基于深度学习的工业品组件缺陷检测技术
用友OA漏洞学习——NCFindWeb 目录遍历漏洞
【.NET CORE】 请求长度过长报错解决方案
《ASP.NET Core 6框架揭秘》样章发布[200页/5章]
Introduction to the usage of model view delegate principal-agent mechanism in QT
Compilation principle - top-down analysis and recursive descent analysis construction (notes)
[.Net core] solution to error reporting due to too long request length
文档编辑之markdown语法(typora)
使用block实现两个页面之间的传统价值观
MSF横向之MSF端口转发+路由表+SOCKS5+proxychains
传输层 拥塞控制-慢开始和拥塞避免 快重传 快恢复
2022 Summer Project Training (II)
【LeetCode第 300 场周赛】
Distill knowledge from the interaction model! China University of science and Technology & meituan proposed virt, which combines the efficiency of the two tower model and the performance of the intera
SQL优化问题的简述