当前位置:网站首页>Ms-tct: INRIA & SBU proposed a multi-scale time transformer for motion detection. The effect is SOTA! Open source! (CVPR2022)...
Ms-tct: INRIA & SBU proposed a multi-scale time transformer for motion detection. The effect is SOTA! Open source! (CVPR2022)...
2022-07-06 18:11:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
Share this article CVPR 2022 The paper 『MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection』,Inria&SBU Propose multi-scale time for motion detection Transformer,《MS-TCT》, Detection effect SOTA! The code is open source !
The details are as follows :

Thesis link :https://arxiv.org/abs/2112.03902
Project links :https://github.com/dairui01/MS-TCT
01
Abstract
Motion detection is an important and challenging task , Especially in non clip video datasets with dense tags . These data consist of complex temporal relationships , Including compound or joint actions . To detect actions in these complex environments , It is important to effectively capture short-term and long-term time information . So , The author proposes a new method for motion detection “ConvTransformer” The Internet :MS-TCT.
The network consists of three main components :
Time encoder module , It explores global and local temporal relationships with multiple temporal resolutions ;
Timescale mixer module , It effectively fuses multi-scale features , Create a unified feature representation ;
Classification module , It learns the relative position of the center of each action instance in time , And predict the frame level classification score .
The authors are working on several challenging data sets ( Such as Charades、TSU and MultiTHUMOS) The experimental results on show the effectiveness of the proposed method , This method is superior to the most advanced method on all three data sets .
02
Motivation

Motion detection is a well-known problem in computer vision , Its purpose is to find the precise time boundary between actions in the unedited video . It fits well with the settings of the real world , Because every minute of the video may be full of multiple actions to be detected and marked . Some public datasets provide dense annotations to solve this problem , Its movement distribution is similar to the real world . However , Such data can be challenging , Multiple actions occur simultaneously in different time spans , And the background information is limited . therefore , Understanding the short-term and long-term time dependence between actions is critical to making good predictions .
for example ,“ Eat something ”( See above ) The action of can be from “ Open the refrigerator ” and “ Make sandwiches ” Get context information , Corresponding to short-term and long-term action dependence respectively . Besides ,“ Put things on the table ” and “ Make sandwiches ” The appearance of provides context information to detect compound actions “ cooking ”. This example shows that an effective time modeling technique is needed to detect actions in tag dense video .
In order to model the time relationship in the uncut video , Many methods have been used in the past 1D Time convolution . However , Limited by the size of its nucleus , Convolution based methods can only directly access local information , Unable to learn the direct relationship between time distant clips in the video ( here , Treat a group of consecutive frames as a segment ). therefore , Such methods cannot model the remote interaction between fragments that may be important for action detection .
With Transformers Success in natural language processing , And recent success in the field of computer vision , The most recent method uses multi head self attention (MHSA) Modeling long-term relationships in video for motion detection . This attention mechanism can be used in every time segment of the video ( Time token) Establish a direct one-to-one overall relationship between , To detect highly correlated and compound actions . However , Existing methods rely on modeling this long-term relationship on the input frame itself .
ad locum , Time token Cover only part of the frame , Relative to an action , The number of these frames is too small . Besides , In this setting ,Transformer It is necessary to clearly learn the adjacency caused by time consistency token Strong relationship between , And time convolution ( That is, local inductive bias ) Naturally, this relationship will occur . therefore , pure transformer Architecture may not be enough to model complex time dependencies for action detection .
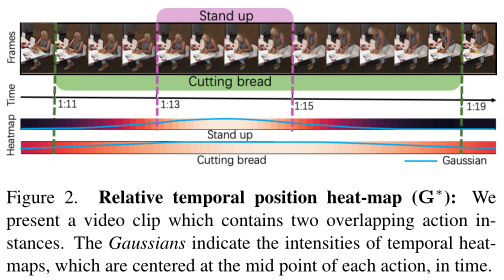
So , The author proposed multi-scale time ConvTransformer(MS-TCT), This is a model that includes both the advantages of convolution and self attention . The author is based on token Convolution is used to enhance token Multiple time scales , And easily mix adjacent token, So as to achieve time consistency .
in fact ,MS-TCT Build in use 3D Convolution trunk coding time period . Each time period is considered MS-TCT Single input token, It is processed in multiple stages with different time scales . These scales are determined by the size of the time period , The time period is treated as a single... In the input of each stage token. Having different scales makes MS-TCT Be able to understand atomic action at an early stage ( Such as “ Open the refrigerator ”) The fine-grained relationship between , And understand the compound action in the later stage ( Such as “ cooking ”) The rough relationship between .
More specifically , Each stage includes one for merging token Time convolution , Then there is a group of multi head self attention layer and time convolution layer , Model the global time relationship respectively , And in token Inject local information between . Because convolution introduces inductive bias ,MS-TCT Using the time convolution layer, we can inject and token Relevant location information . Then the time relationship under different scales is modeled , Use the hybrid module to fuse the features of each stage , Get a unified feature representation .
Last , In order to predict the behavior of dense distribution , The author in MS-TCT In addition to the usual multi label classification branches , We introduced one heat-map Branch . The heat-map The network is encouraged to predict the relative time position of each action class instance . The above figure shows the relative time position calculated based on the Gaussian filter parameterized by the center of the example and its duration . It represents the relative time position relative to the center of the action instance at any given time . Through this new branch ,MS-TCT Can be in token Embedded in the representation class-wise Relative time position of , Encourage differentiation in complex videos token classification .
in summary , Of this work Main contributions yes :
An effective method is proposed ConvTransformer, Used to model complex temporal relationships in unedited video ;
A new branch is introduced to learn the position relative to the center of the instance , This is helpful for motion detection in dense annotation videos ;
It achieves SOTA Performance of !
03
Method
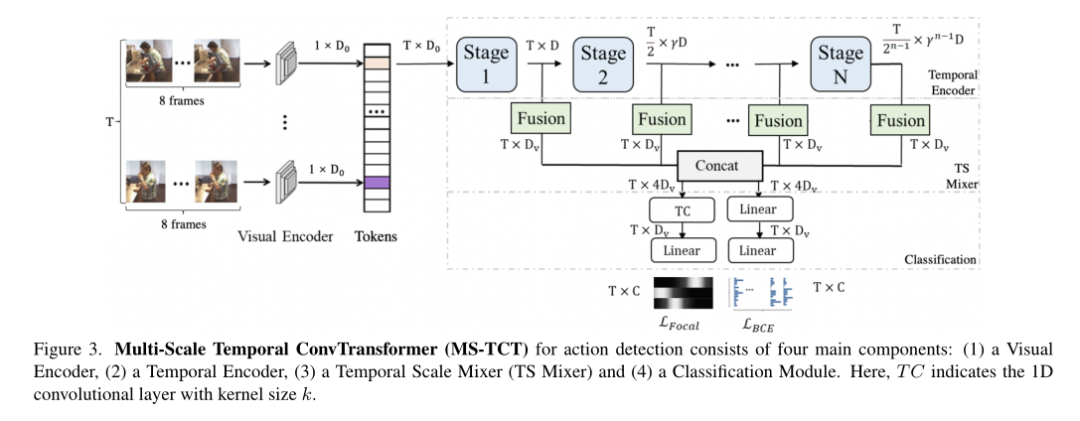
For length is T Video sequence of , Every time step t All contain a ground-truth Action tag , Which means action class . For each time step , Motion detection models need to predict class probabilities .
The motion detection model proposed in this paper MS-TCT As shown in the figure below , It contains 4 Parts of :
Encoding the preliminary video representation Visual encoder ,
At different time scales ( That's resolution ) On the structural modeling of time relationship Time encoder ,
Time expressed in combination with multi-scale time scale Mixer (TS Mixer),
Prediction of class probability Classification module .
3.1. Visual Encoder
Motion detection network MS-TCT The input of is an unedited video , It may last for a long time ( for example , A few minutes ). However , Processing long videos in spatial and temporal dimensions can be challenging , Mainly due to the computational burden . As a compromise , Similar to the previous motion detection model , The author will 3D CNN The features of the extracted video clips are used as MS-TCT The input of ,MS-TCT Potentially embed spatial information as channels .
To be specific , Author use I3D Trunk to encode video . Each video is divided into T Non overlapping fragments ( During training ), Each segment is composed of 8 The frame of . In this way RGB Frames are fed as input segments I3D The Internet . Each segment level feature (I3D Output ) Can be regarded as a time step Transformer token( Time token). Authors stack along the timeline token, Form a video token Express , And input it to the time encoder .
3.2. Temporal Encoder
Effective time modeling is crucial for understanding the long-term temporal relationship in video , Especially for complex motion synthesis . Given a set of videos token, There are two main ways to model time information : Use (1)1D Time convolution , This layer focuses on adjacent token, But ignore the direct long-term time dependence in video , or (2) The main methods of modeling time information : Use (1)1D Time convolution [31], This layer focuses on adjacent tokens , But ignore the direct long-term time dependence in video , or (2) Converter layer [45], This layer globally encodes the one-to-one interaction of all tokens , Ignore local semantics at the same time , This has proved useful in modeling highly correlated visual signals , This layer globally encodes all token One to one interaction , Ignore local semantics at the same time , This has proved useful in modeling highly correlated visual signals . The temporal encoder in this paper alternately explores local and global context information .
As shown in the figure above , The time encoder follows with N A hierarchy of stages : Early learning has more time token The fine-grained action representation of , And the later stage of learning has less token Rough representation of . Each stage corresponds to a semantic level ( Time resolution ), Merge blocks and by one time B A big picture - Local relation blocks consist of , As shown in the figure below .
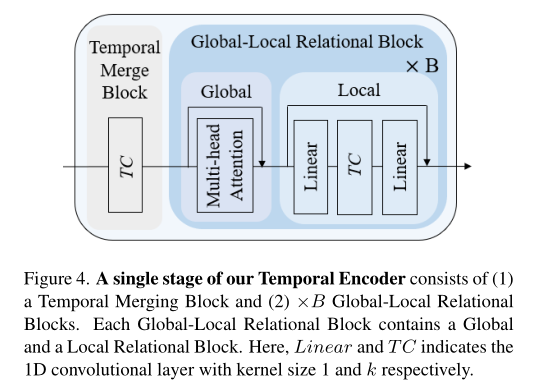
Temporal Merging Block
The time merge block is a key component to introduce the network hierarchy , It increases the feature dimension while reducing token The number of ( Time resolution ). This step can be regarded as adjacent token Weighted pooling operation between . actually , The author uses a single time convolution ( The nuclear size is k, The steps are usually 2) take token Halve the quantity , And expand the channel size ×γ. In the first phase , The author keeps the step size 1, To keep in touch with I3D Output the same number of token, And the feature size is projected from .
Global-Local Relational Block
overall situation - Local relation blocks are further decomposed into global relation blocks and local relation blocks ( See above ). In the global relationship block , The author uses the standard multi head self attention layer to model long-term action dependence , That is, the global context . In a local relation block , The author uses time convolution ( The nuclear size is k) By injecting adjacent token The context of ( That is, local inductive bias ) To enhance token Express . This enhances each token Time consistency , At the same time, the short-term time information corresponding to the action instance is modeled .
For block , The author will enter token Expressed as . First ,token Through multiple layers of attention in the global relationship block , The global relationship block consists of H It consists of two attention heads . For each head , Input projection to , among
402 Payment Required
Represents the weight of the linear layer , Represents the feature size of each head . therefore , The self attention of each head is calculated as :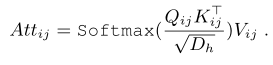
then , The output of different attention heads is mixed with additional linear layers , As shown below :
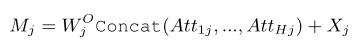
Where represents the weight of the linear layer . The output feature size of the multi head attention layer is the same as the input feature size .
Next , The output of long attention token Send to local relation block , The block is composed of two linear layers and a time convolution layer . As shown in the figure above ,token First, go through the linear layer to increase the feature dimension from , Then the core size is k Time convolution , Its mixture is adjacent token To time token Provide local location information . Last , Another linear layer projects the feature size back . The two linear layers in this block realize the conversion between the multi head attention layer and the time convolution layer .
From the last overall situation of each stage - Output of local relation block token It is combined and fed to the following time scale mixer .
3.3. Temporal Scale Mixer
In obtaining different time scales token after , The rest of the problem is , How to aggregate these multiscale token To get a unified video representation ? In order to predict the action probability , The classification module of this paper needs to predict the original length of time as the network input . therefore , Need to interpolate across time dimensions token, This is achieved by performing up sampling and linear projection steps .
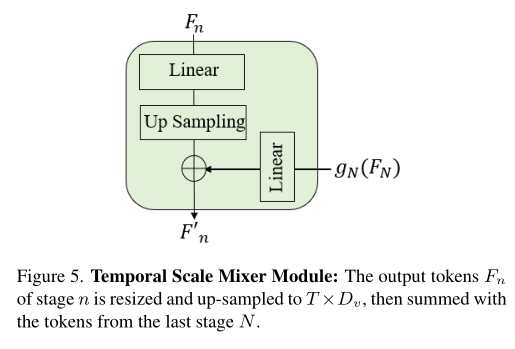
As shown in the figure above , For from stage Output , This operation can be expressed as :
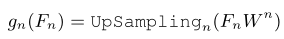
among , The upper sampling rate is n. In the hierarchy of this article , Early stage ( Low semantics ) It has high time resolution , And later stage ( Higher semantics ) With low time resolution . To balance resolution and semantics , The last stage N Up sampling of token Processing through linear layers , And with the upper sampling of each stage token Add up . This operation can be expressed as :
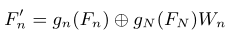
among , It's No n Stage refining token,⊕ Represents the addition and of elements . here , All refined token It means that they all have the same length of time . Last , Will they concat get up , Get the final multi-scale video representation :
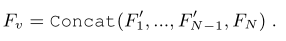
Then send the multi-scale video representation to the classification module for prediction .
3.4. Classification Module
MS-TCT Training is achieved through joint learning of two classification tasks . The author introduces a new classification branch to learn action examples heatmap. this heatmap differ ground truth label , Because it changes over time , Based on Action Center and duration . Use this heatmap The purpose of expression is to MS-TCT Learning from token Relative positioning of coding time in .
For training heatmap Branch , First, we need to build class based ground truth heatmap Respond to , among C Indicates the number of action classes . In this work , The author constructs By considering the maximum response of a set of one-dimensional Gaussian filters . Each Gaussian filter corresponds to an instance of an action class in the video , Focus on specific action instances in time .
More precisely , For each time location t,ground truth heatmap The response formula is as follows :
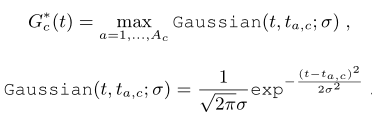
here ,σ Provide instance specific Gaussian activation based on center and instance duration . Besides ,σ Equal to the duration of each instance , Represents a class c And examples a Center of . It's in the video c Total number of instances of class .heatmap Is to use a core size of k Time convolution and nonlinear activation , Then there is sigmoid Activate another linear layer to calculate . Given ground truth And predicted heatmap, The author calculated action focal loss, The formula is as follows :
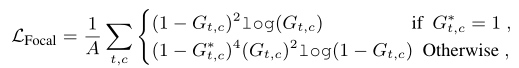
among A Is the total number of action instances in the video .
Similar to the previous work , The author uses another branch to perform common multi label classification . For video features , Use two with sigmoid The active linear layer calculates the prediction , And according to ground truth Tag calculation Binary Cross Entropy(BCE) Loss . Only the scores predicted by this branch are used in the evaluation . The input of both branches is the same output token.heatmap Branching encourages the model to embed the relative position of the instance center into the video token in . therefore , Classification branches can also benefit from these location information , To make better predictions .
The total loss is expressed as the weighted sum of the above two losses :
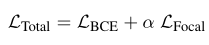
04
experiment

As shown in the table above , With only classified branches I3D Features are considered representative baseline. The baseline Contains a classifier , The classifier uses I3D features , Without any further time modeling . Adding the time encoder in this article significantly improves the performance (+7.0%). This reflects the effectiveness of time encoder in modeling the time relationship in video .
Besides , If a time scale mixer is introduced to mix features from different time scales , It can be improved with the least amount of calculation +0.5%. Last , The author has studied heatmap The practicality of branches in the classification module . Pay attention to this discovery , When optimized with classification branches ,heatmap Branches are valid , But when optimizing without it , Unable to learn to distinguish between representations .
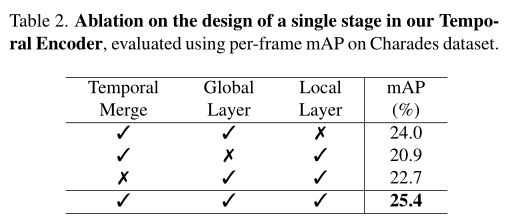
In the above table , The author gives the ablation related to the design selection of a stage in the time encoder . Each row in the above table represents the result of removing components at each stage . It can be found that removing any component will significantly reduce performance . This observation shows that , In the method of this paper , The importance of joint modeling of global and local relationships , And the effectiveness of multi-scale structure .
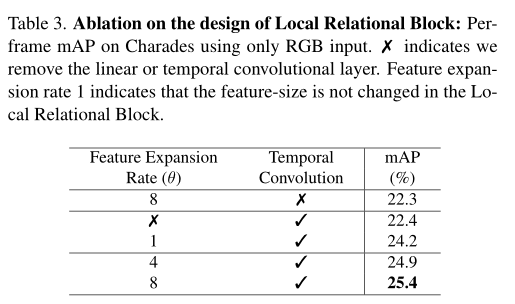
The author also delves into the local relationship blocks in each stage . There are two linear layers and a time convolution layer in the local relation block . In the above table , The authors further ablated these components . First , The author found , If there is no time to accumulate , Detection performance will degrade . This observation shows that Transformer Token The importance of mixing with time and location .
Besides , When the feature size remains unchanged , Using a transition layer can improve performance 1.8%, This shows the importance of the transition layer . Last , The author studies the influence of expansion rate on network performance . When setting different feature expansion rates , The author finds that when the input feature is located in a high-dimensional space , Time convolution can better model local time relations .
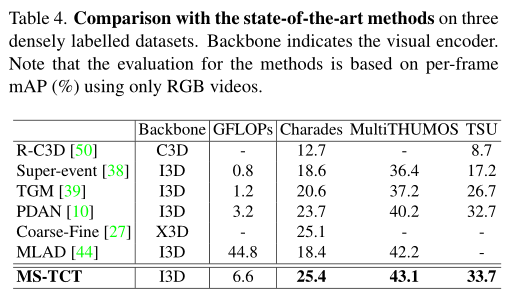
The above table shows the methods and SOTA The comparison results of the methods are , It can be seen that this method has obvious performance advantages .
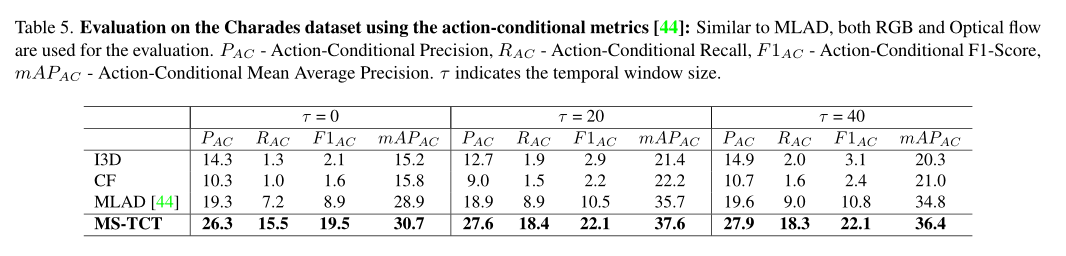
The table above shows Charades The action condition measurement of data set is used to evaluate the network in this paper .
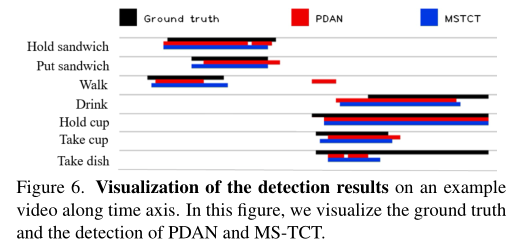
The picture above shows Charades The data set is right PDAN and MS-TCT A qualitative assessment was carried out . because Coarse-Fine Network The prediction of is similar to X3D The Internet , Limited to dozens of frames , Therefore, it is impossible to communicate with Coarse-Fine Network Compare . As you can see from the picture above MS-TCT Comparable PDAN Predict action instances more accurately . This comparison reflects transformer Effectiveness of structure and multi-scale time modeling .
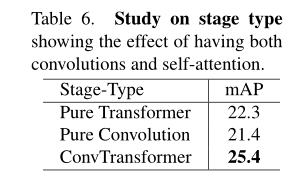
The table above shows the proposed ConvTransformer To a great extent, it is superior to pure transformer And pure convolution network ( Respectively 3.1% and 4.0%). This shows that ConvTransformer It can better model the time relationship of complex actions .

The figure above visualizes Ground Truth Heatmap() And the corresponding prediction Heatmap(). The author observed , adopt Heatmap Branch ,MS-TCT Predict the central position of the action instance , indicate MS-TCT Embed relevant information of the center into token in .
05
summary
In this work , The author puts forward a new kind of ConvTransformer The Internet :MS-TCT For motion detection . It benefits from convolution and self attention , Modeling local and global time relationships on multiple time scales . Besides , The author also introduces a new branch to learn the relative position of action instance center in class .MS-TCT Evaluate on three challenging benchmarks for dense marker motion detection , On this basis, the latest results have been obtained .
Reference material
[1]https://arxiv.org/abs/2112.03902
[2]https://github.com/dairui01/MS-TCT

END
Join in 「 Motion detection 」 Exchange group notes :ActD

边栏推荐
- 面向程序员的精品开源字体
- 《ASP.NET Core 6框架揭秘》样章发布[200页/5章]
- Easy introduction to SQL (1): addition, deletion, modification and simple query
- 2019阿里集群数据集使用总结
- Will openeuler last long
- Jielizhi obtains the customized background information corresponding to the specified dial [chapter]
- 递归的方式
- [introduction to MySQL] the first sentence · first time in the "database" Mainland
- Principle and usage of extern
- Open source and safe "song of ice and fire"
猜你喜欢

模板于泛型编程之declval

Declval (example of return value of guidance function)
Awk command exercise
【Swoole系列2.1】先把Swoole跑起来

Unity particle special effects series - treasure chest of shining stars

Heavy! Ant open source trusted privacy computing framework "argot", flexible assembly of mainstream technologies, developer friendly layered design

There is a gap in traditional home decoration. VR panoramic home decoration allows you to experience the completion effect of your new house
虚拟机VirtualBox和Vagrant安装

Stealing others' vulnerability reports and selling them into sidelines, and the vulnerability reward platform gives rise to "insiders"
UDP协议:因性善而简单,难免碰到“城会玩”
随机推荐
The integrated real-time HTAP database stonedb, how to replace MySQL and achieve nearly a hundredfold performance improvement
带你穿越古罗马,元宇宙巴士来啦 #Invisible Cities
微信小程序中给event对象传递数据
This article discusses the memory layout of objects in the JVM, as well as the principle and application of memory alignment and compression pointer
2019阿里集群数据集使用总结
DNS hijacking
Jerry's watch deletes the existing dial file [chapter]
Awk command exercise
Stealing others' vulnerability reports and selling them into sidelines, and the vulnerability reward platform gives rise to "insiders"
Distinguish between basic disk and dynamic disk RAID disk redundant array
Will openeuler last long
Appium automated test scroll and drag_ and_ Drop slides according to element position
JMeter interface test response data garbled
std::true_type和std::false_type
Heavy! Ant open source trusted privacy computing framework "argot", flexible assembly of mainstream technologies, developer friendly layered design
HMS core machine learning service creates a new "sound" state of simultaneous interpreting translation, and AI makes international exchanges smoother
趣-关于undefined的问题
Codeforces Round #803 (Div. 2)
VR全景婚礼,帮助新人记录浪漫且美好的场景
Declval of template in generic programming