当前位置:网站首页>Deep circulation network long-term blood pressure prediction [translation]
Deep circulation network long-term blood pressure prediction [translation]
2022-07-06 18:43:00 【Bachuan Xiaoxiaosheng】
Deep circulation network long-term blood pressure prediction
Abstract
Existing arterial blood pressure (BP) The estimation method directly maps the input physiological signal to the output BP value , Without explicit modeling BP Potential time dependence in dynamics . therefore , The accuracy of these models decreases with time , Therefore, it needs to be calibrated frequently . In this work , By formulating BP Estimation as a sequence prediction problem , The input and target are time series to solve this problem . We propose a new deep recurrent neural network (RNN), By multi-layer long-term and short-term memory (LSTM) Network composition , The network combines (1) Two way structure , To get larger scale input sequence context information ,(2) Remaining connections , Make depth RNN The gradient in spreads more effectively . In static BP The proposed depth on the dataset RNN The model was tested , Its effect on systole BP (SBP) And diastole BP (DBP) Root mean square error of prediction (RMSE) Respectively 3.90 and 2.66 mmHg, Beyond tradition BP Accuracy of prediction model . In many days BP On dataset , depth RNN In the 1 God SBP After the prediction 1 God 、 The first 2 God 、 The first 4 Day and day 6 Months RMSE Respectively 3.84、5.25、5.80 and 5.81 mmHg, Corresponding DBP forecast RMSE Respectively 1.80、4.78、5.0 and 5.21 mmHg, Better than all previous models , And significantly improved . Experimental results show that , Yes BP Dynamic time-dependent modeling can significantly improve BP Long term prediction accuracy .
brief introduction
High blood pressure (pressure pressure, BP) As a cardiovascular disease (CVD)[1] The primary risk factor , It has been widely used for diagnosis and prevention CVD Key criteria for . therefore , Be accurate in daily life 、 Continuous blood pressure monitoring is very important for the early detection and intervention of cardiovascular disease . Conventional BP Measuring equipment , Such as Omron products , It's based on cuffs , So heavy , Uncomfortable to use , It can only be used for snapshot measurement . These shortcomings limit the use of cuff devices for long-term continuous blood pressure measurement , The cuff type equipment is different for night monitoring and accurate diagnosis CVD Symptoms are critical
A key feature of the cardiovascular system is its complex dynamic self-regulation , Multiple feedback control loops are involved to respond BP The change of [2]. This mechanism makes BP Dynamics is time-dependent . therefore , This dependency is important for continuous BP forecast , Especially long-term BP Prediction is crucial .
Existing sleeveless continuous BP Estimation methods can be divided into two categories , Physiological model , Namely pulse transmission time model [3][4], The regression model , Such as the decision tree 、 Support vector regression, etc [5][6]. The accuracy of these models will decline over time , Especially for continuous BP forecast . This limitation has become a bottleneck that hinders the use of these models in practical applications . It is worth noting that , The above model directly maps the current input to the target , While ignoring the BP Important time dependency in dynamics . This may be the root cause of long-term inaccuracy .
And static BP Compared with the prediction , Many days BP Forecasting is usually more challenging . Due to the complex regulation mechanism of human body , Many days BP Dynamics has a more complex time dependence and a larger range of changes . In this paper , We will BP Prediction is defined as a sequential learning problem , And put forward a new depth RNN Model , The model is proved to be correct BP Modeling dynamic medium - and long-term dependencies is very effective , For many consecutive days BP The prediction has reached the most advanced accuracy
Model
The goal of arterial blood pressure prediction is to use a variety of time physiological signals to predict blood pressure sequence . set up X T = [ x 1 , x 2 … , x T ] X_{T} = [x_{1}, x_{2}…, x_{T}] XT=[x1,x2…,xT] For ECG and PPG Input characteristics of signal extraction , Y T = [ y 1 , y 2 … , y T ] Y_{T} = [y_{1}, y_{2}…, y_{T}] YT=[y1,y2…,yT] It means a goal BP Sequence . Conditional probability p ( Y T ∣ X T ) p(Y_{T} | X_{T}) p(YT∣XT) Factorization into
p ( Y T ∣ X T ) = ∏ t = 1 T p ( y t ∣ h t ) ( 1 ) p(Y_{T}|X_{T})=\prod_{t=1}^{T}p(y_{t}|h_{t})\quad (1) p(YT∣XT)=t=1∏Tp(yt∣ht)(1)
among h t h_{t} ht It can be understood as BP Hidden state of dynamic system , From the previous hidden state h t − 1 h_{t−1} ht−1 And current input x t x_{t} xt produce :
h t = f ( h t − 1 , x t ) ( 2 ) h_{t}=f(h_{t-1},x_{t})\quad (2) ht=f(ht−1,xt)(2)
chart 1 It explains the depth we proposed RNN An overview of the model . depth RNN From the bottom two-way LSTM And multilayer with residual connections LSTM (Long ShortTerm Memory) form . Network wide transit time [7] Back propagation training , To shrink BP Prediction and ground truth Differences between .
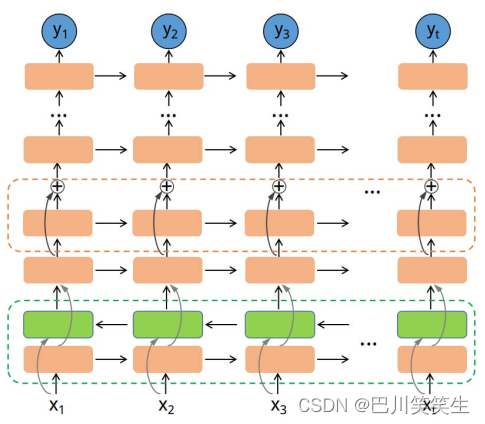
chart 1:DeepRNN framework . Each rectangle is a LSTM unit . The green dotted box at the bottom is a two-way LSTM layer , From positive ( Orange ) And reverse ( green )LSTM form . The orange dashed box indicates LSTM layer .
two-way LSTM structure
First , We introduced depth RNN The basic module of the model , That is, single-layer bidirectional long-term and short-term memory (LSTM).LSTM[8] Pass in standard RNN The state of memory cells is introduced in the process of implicit transformation ct And multi gating mechanism to solve the traditional RNN Vanishing gradient problem of .LSTM Hidden state in h t h_{t} ht from
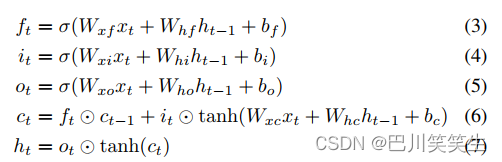
among f、I、o Forget the door 、 Input gate 、 Output gate , Control how much information will be forgotten 、 Accumulate or output .W Xiang He b The term represents the weight matrix and the offset vector respectively .σ and tanh respectively logistic s The application of shape function and hyperbolic tangent function , ⊙ \odot ⊙ Denotes unary multiplication
Conventional lstm Use ht Get information from past history x 1 , … x t − 1 x_{1},…x_{t-1} x1,…xt−1, Now input x t x_{t} xt. In order to obtain the time context of a larger input sequence , You can also add nearby future information x t + 1 , … , x T x_{t+1},…, x_{T} xt+1,…,xT Inform downstream modeling process . two-way RNN (BRNN)[9] Data is processed forward and backward through two separate hidden layers , Then merge into the same output layer to realize this function . Pictured 1 Shown at the bottom ,BRNN Calculate the forward hidden state by the following equation h t f h_{t}^{f} htf、 Backward hidden state h t b h_{t}^{b} htb And the final output h t h_{t} ht
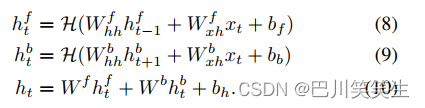
In style H \mathcal{H} H By the type 3-7 Realization .
Multi tier architecture with residual connections
[10][11] Various experimental results show that , Having a deep structure rnn It can be significantly better than the shallow structure rnn. Just put the RNN Stack multiple layers , You can easily acquire the ability to express . However , A complete deep network may become difficult to train as it deepens , It may be due to the gradient problem of explosion and disappearance [12].
The idea of attaching a fully replicated hop connection between adjacent layers is inspired , It is training deep Neural Networks [13][14][15] It shows good performance , We added from a LSTM Layer to next LSTM The remaining connections of the layer , Pictured 2 Shown . set up x t i x^{i}_{t} xti , h t i h^{i}_{t} hti, H i \mathcal{H}_{i} Hi Namely LSTM The first i i i Layer of the input , Hidden state and LSTM function ( i = 1 , 2 , … , L ) (i = 1,2,…, L) (i=1,2,…,L), W i W^{i} Wi by H i \mathcal{H}_{i} Hi The corresponding weight .LSTM The first i i i Layer of the input x t i x_{t}^{i} xti The hidden state added to the layer by element h t i h^{i}_{t} hti in . Then this and x t i + 1 x_{t}^{i+1} xti+1 Sent to the next floor LSTM. With remaining connections LSTM Blocks can be used
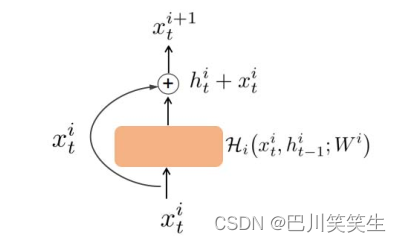
chart 2: With remaining connections LSTM
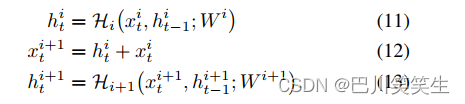
Multiple such LSTM Blocks are superimposed on each other , The output of the previous block constitutes the input of the next block , You can establish the depth RNN Model . Once the hidden state of the top layer is calculated , It can be output through the following formula z t z_{t} zt:
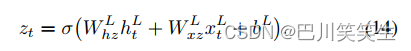
Multitasking training
Considering that we have multiple monitoring signals , Such as systolic blood pressure (SBP)、 diastolic pressure (DBP) And the average BP (MBP), They are closely related , We use multi task training strategy , Train a model , Parallel prediction SBP,DBP and MBP. therefore , The training goal is to make the total N Mean square error of training samples (MSE) Minimum , As shown below
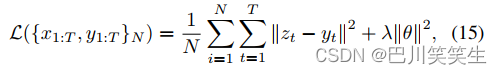
In style , y t = [ S B P , D B P , M B P ] y_{t} = [SBP, DBP, MBP] yt=[SBP,DBP,MBP] For the truth , z t z_{t} zt For the corresponding forecast . ∣ ∣ θ ∣ ∣ 2 ||\theta||^{2} ∣∣θ∣∣2 Representing model parameters L 2 L_{2} L2 Regular , λ \lambda λ Is the corresponding penalty coefficient . One advantage of multitasking training is , Learn to predict differences at the same time BP Values can be implicitly encoded SBP、DBP and MBP Quantitative constraints between .
depth RNN structural analysis
Because of their hidden state transitions ,rnn With internal depth time . Despite the depth proposed RNN The model has a certain depth in time , But it also has a certain depth along the layer structure . To simplify the analysis , Here we mainly focus on the gradient flow along the layer depth . Update the equation recursively (12), We will have
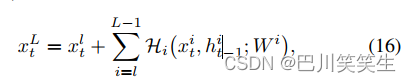
For any deeper layer L L L And shallower layers l l l. equation (16) Good back propagation characteristics can be obtained . Record the loss function as L \mathcal{L} L, According to the chain rule of back propagation
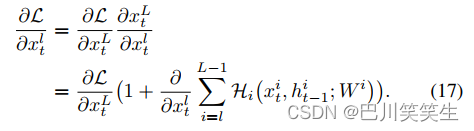
equation (17) It's a gradient ∂ L ∂ x t l \frac{\partial \mathcal{L}}{\partial x_{t}^{l}} ∂xtl∂L It can be decomposed into two additive terms : a ∂ L ∂ x t L \frac{\partial \mathcal{L}}{\partial x_{t}^{L}} ∂xtL∂L Direct dissemination of information , Not through any weight layer , The other one ∂ L ∂ x t l ( ∂ ∂ x ∑ i = l L − 1 H i ) \frac{\partial \mathcal{L}}{\partial x_{t}^{l}}(\frac{\partial }{\partial x}\sum_{i=l}^{L-1}\mathcal{H}_{i}) ∂xtl∂L(∂x∂∑i=lL−1Hi). First of all ∂ L ∂ x t L \frac{\partial \mathcal{L}}{\partial x_{t}^{L}} ∂xtL∂L Ensure that the supervision information can be directly back propagated to any shallow layer x t l x_{t}^{l} xtl. In general ∂ ∂ x ∑ i = l L − 1 H i \frac{\partial }{\partial x}\sum_{i=l}^{L-1}\mathcal{H}_{i} ∂x∂∑i=lL−1Hi For all samples in small batches , Can't always −1, So the gradient ∂ L ∂ x t l \frac{\partial \mathcal{L}}{\partial x_{t}^{l}} ∂xtl∂L Unlikely to be offset . This means that even if the intermediate weight is arbitrarily small , A layer of gradient will not disappear . This good back-propagation characteristic enables us to train the depth with stronger expression ability RNN Model , There is no need to worry about the disappearance of the gradient .
experiment
We are static and multi day continuous BP The proposed model is evaluated on the dataset . Root mean square error (RMSE) As an evaluation indicator , The definition for
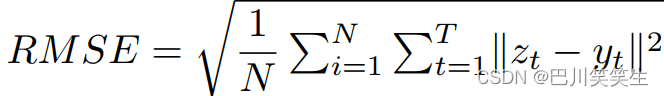
On these two datasets , We compare our model with the following reference model
- Pulse transmission time (PTT) Model : We selected the two most cited models based on pt Model of ——Chen Methods [3]1 and Poon Methods [4].
- A typical regression model : Support vector regression (SVR)、 Decision tree (DT) And Bayesian linear regression (BLR).
- Kalman filter
Data sets
Static continuous BP Data sets . The data set includes ECG 、PPG and BP, come from 84 Healthy people , Among them, men 51 example , women 33 example . Every experiment adopts Biopac The system collects ECG and PPG The signal ,Finapres The system simultaneously measures continuous benchmarks BP value . At rest , With 1000 Hz The sampling frequency was recorded for each subject BP、ECG and PPG data , continued 10 minute .
Continuous for many days BP Data sets . Similar data sets are taken from 12 Healthy subjects , Include 11 Men and 1 Famous woman . Record the resting state of each subject BP、ECG and PPG data , Multiple dates , That is to say 1 God 、 The first 2 God 、 The first 4 Day and day 1 Days later 6 Months , common 8 minute .
The data shows
Because the main goal of this paper is to prove BP Modeling time correlation in dynamics is accurate BP The importance of prediction , We simply chose ECG and PPG The signal 7 A representative manual feature ( Pictured 3 Shown ) as follows :
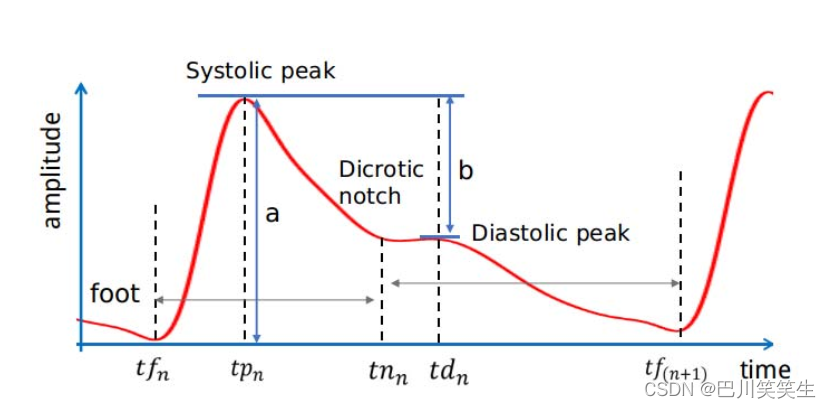
chart 3:PPG Feature diagram
- P T T S PTT_{S} PTTS: From electrocardiogram R Peak to the same heart cycle PPG Time interval of maximum slope .
- heart rate HR
- Reflectivity R I = b / a RI=b/a RI=b/a
- Contraction interval S T = t n n − t f n ST=tn_{n}-tf_{n} ST=tnn−tfn
- Rise time $upTime = tp_{n} - tf_{n} $
- Systolic volume S V = ∫ t n n t f n P P G ( t ) d t SV=\int_{tn_{n}}^{tf_{n}}PPG(t)dt SV=∫tnntfnPPG(t)dt
- Heart relaxing volume D V = ∫ t n n t f n + 1 P P G ( t ) d t DV=\int_{tn_{n}}^{tf_{n}+1}PPG(t)dt DV=∫tnntfn+1PPG(t)dt
Now the input X T X_{T} XT Become a 7 × T 7\times T 7×T Matrix , X T X_{T} XT Each row of is normalized to zero mean and unit variance . By adding more information properties as model input , It can be expected to further improve the performance of the model .
result
Static continuous BP Validation of data sets . As shown in the table 1 Shown ,PTT The result of the model is slightly better than BLR and SVR Model , But the performance is DT、 Kalman filtering 、 two-way LSTM And depth RNN (DeepRNN) The model is poor .4 Layer depth RNN (DeepRNN-4L) Model for SBP and DBP The prediction accuracy is the highest ,RMSE Respectively 3.73 and 2.43.Bland-Altman chart ( chart 4) indicate ,DeepRNN- 4L The prediction is in good agreement with the real value ,95% The difference lies in the same area . chart 6 Qualitatively demonstrates static continuity BP Data set for a representative subject DeepRNN-4L Predicted results .
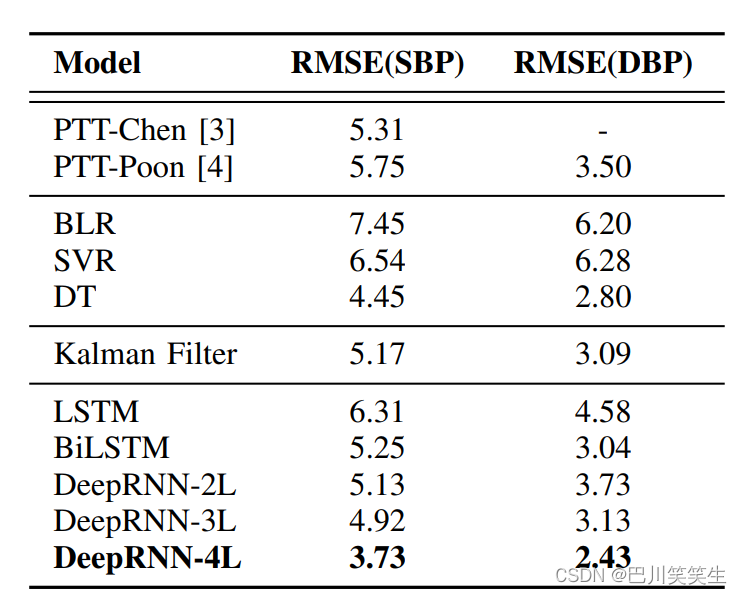
Table 1 : Detailed analysis of our Deep RNN Model , And compared with different reference models .DeepRNN-xL Express x layer RNN Model . In static continuous BP All models are verified on the data set .( Company : Mm Hg )
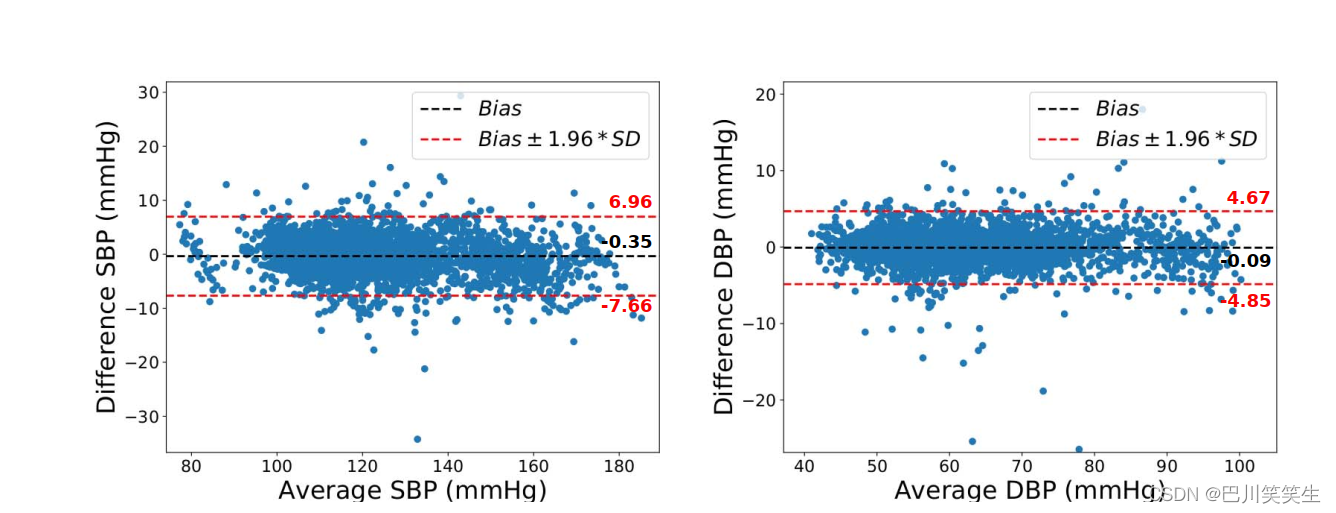
chart 4: In static continuous BP On dataset ,DeepRNN-4L Model vs. overall SBP and DBP Predicted Bland-Altman chart .
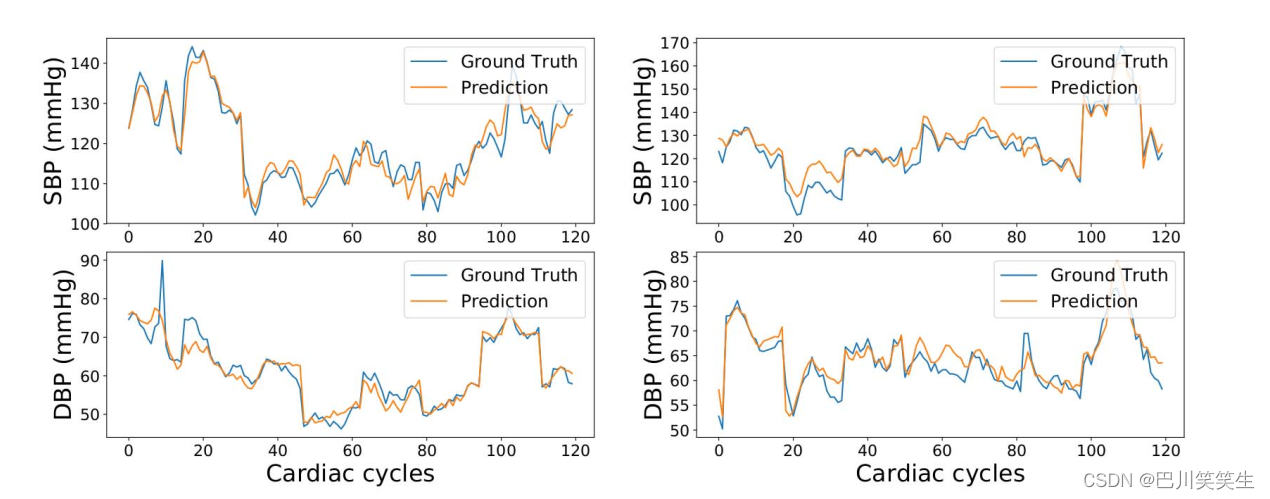
chart 6: Static continuous BP Of two representative objects in the dataset ground truth and DeepRNN Comparison of prediction results . Each column represents the prediction of systolic and diastolic blood pressure of a subject .
By adding a two-way structure to the model , That is, use two-way LSTM (BiLSTM), And ordinary LSTM comparison , The prediction accuracy is significantly improved ,SBP RMSE Reduce 17%,DBP RMSE Reduce 34%. Besides , It is also found that with the increase of depth , The prediction accuracy of deep neural network is also improving . for example , use DeepRNN-4L replace DeepRNN-2L, Yes SBP and DBP Their predictions have been improved 27% and 35%. When we superimpose on a 5 Layer of DeepRNN when , Models tend to over fit , The obvious depth advantage can no longer be observed
Continuous for many days BP Validation of data sets . chart 5 Compared the depth RNN And the prediction performance of the reference model . You can see it clearly , And PTT Compared with the regression model ,DeepRNN The model produces better performance , This may be due to DeepRNN Time dependent modeling in the model . Kalman filter can model the temporal dependence , But its performance is not as good as depth prnn Model . Because of the linear assumption of Kalman filter , It is likely that both the state transition and the measurement function are linear . This assumption may limit its effect on BP The ability to model complex time dependencies in dynamics . depth prnn - 4l The model is in 1 God SBP After the prediction 1 God 、 The first 2 God 、 The first 4 Day and day 6 The accuracy of months is the highest ,RMSE Respectively 3.84、5.25、5.80 and 5.81 mmHg, DBP Predicted RMSE Respectively 1.80、4.78、5.0 and 5.21 mmHg. Pictured 5 Shown , be-all PTT Model 、 Both regression model and Kalman filter showed significant accuracy degradation on the second day . Although after the first day ,DeepRNN The prediction accuracy of the model has also decreased , But it's RMSE The value is always the lowest of all models . chart 7 Qualitatively show DeepRNN track BP The ability to change over time .
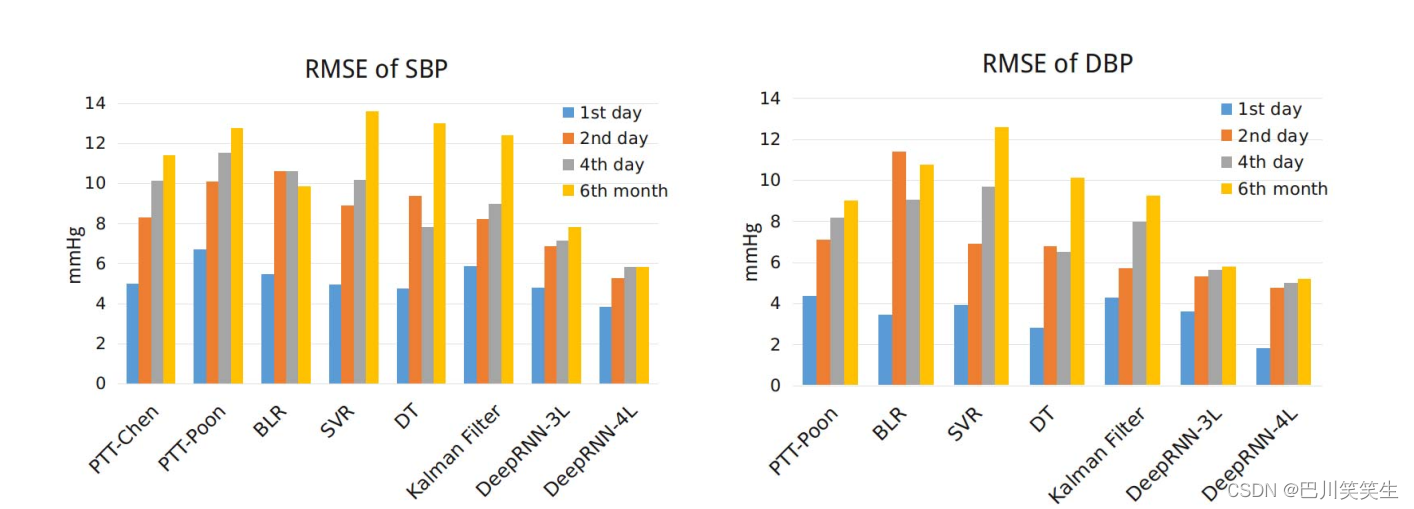
chart 5: Different models are continuous for many days BP Overall on the dataset RMSE Compare
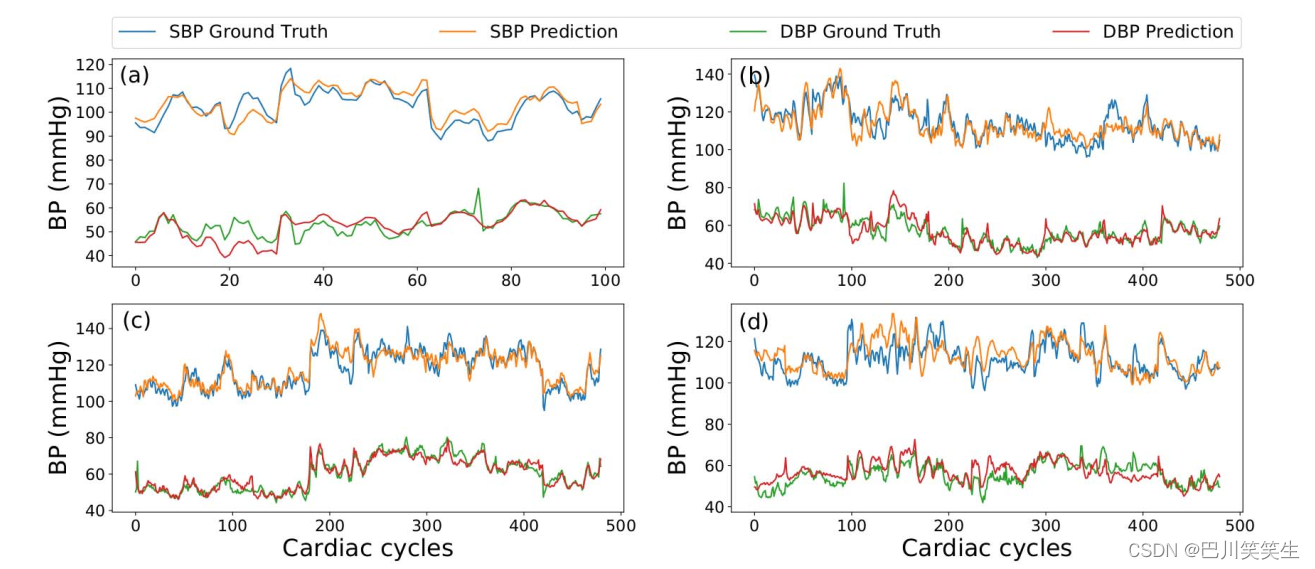
chart 7: For many days BP Of a representative object in the dataset ground truth and DeepRNN Comparison of prediction results . chart (a)、(b)、 and (d) They are No 1 God 、 The first 2 God 、 The first 4 Day and day 6 The results of the last two months .
The importance of residual connection . In order to study the importance of residual connections , We are interested in static continuity BP Data sets were used for ablation studies . As shown in the table 2 Shown , Add the remaining connections DeepRNN The working effect of the model is much better than that of the corresponding model . In the process of training , We find that the residual connection significantly improves the gradient flow in backward transfer , Make the deep neural network easier to optimize . therefore , More expressive deep structure can get better performance . The detailed reasons for this calculation of benefits are explained in Section III .

Table two : There are residual connections and no residual connections DeepRNN-4L Model performance comparison . The result is statically continuous BP From the dataset .( Company : Mm Hg )
The importance of multi task training . It can be seen from table 3 , The multi task training strategy can improve the prediction performance compared with the individual training of a single model . This can be interpreted as , The different training objectives involved in each task are strongly related , Therefore, many data representations that capture the underlying factors are shared , These data represent that you can learn through the same model structure . therefore , By learning to share , It can greatly improve the generalization ability of the model .
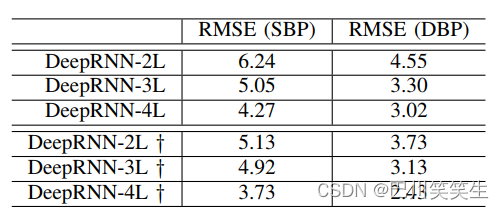
Table 3 : Under different settings DeepRNN survey . The model using multi task target training is marked as ’†'. The result is statically continuous BP From the dataset .( Company : Mm Hg )
Conclusion
Model structure learning . therefore , By learning to share , It can greatly improve the generalization ability of the model .
[ Outside the chain picture transfer in …(img-Lcy4Ylj5-1656835802157)]
Table 3 : Under different settings DeepRNN survey . The model using multi task target training is marked as ’†'. The result is statically continuous BP From the dataset .( Company : Mm Hg )
Conclusion
In this work , We proved that BP Dynamic time-dependent modeling can significantly improve BP Long term prediction accuracy , This is sleeveless BP One of the most challenging problems in estimation . To solve this problem , We propose a new depth RNN, It combines two-way LSTM And the remaining connections . Experimental results show that , depth RNN The model is static and continuous for many days BP The data set has reached the most advanced accuracy .
边栏推荐
猜你喜欢

Summary of performance knowledge points
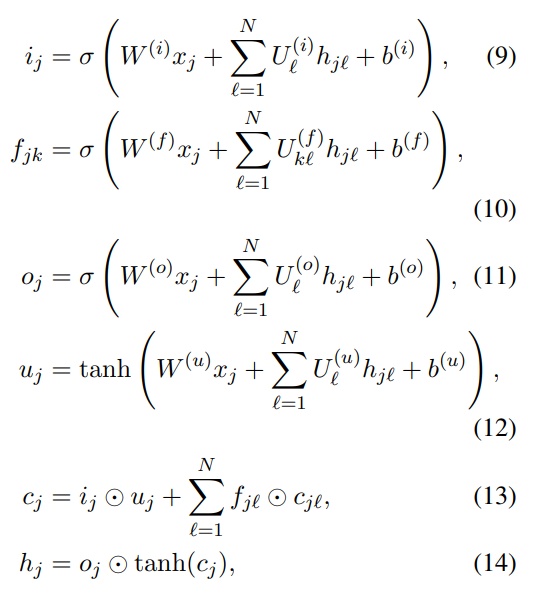
Tree-LSTM的一些理解以及DGL代码实现

287. Find duplicates

Solve DoS attack production cases
Splay

线代笔记....
用于远程医疗的无创、无袖带血压测量【翻译】
![[Sun Yat sen University] information sharing of postgraduate entrance examination and re examination](/img/a8/41e62a7a8d0a2e901e06c751c30291.jpg)
[Sun Yat sen University] information sharing of postgraduate entrance examination and re examination

44 colleges and universities were selected! Publicity of distributed intelligent computing project list

被疫情占据的上半年,你还好么?| 2022年中总结
随机推荐
Virtual machine VirtualBox and vagrant installation
Specify flume introduction, installation and configuration
Penetration test information collection - basic enterprise information
SQL injection Foundation
Alibaba cloud international ECS cannot log in to the pagoda panel console
Cobra 快速入门 - 专为命令行程序而生
[Matlab] Simulink 同一模块的输入输出的变量不能同名
TOP命令详解
上海部分招工市场对新冠阳性康复者拒绝招录
用友OA漏洞学习——NCFindWeb 目录遍历漏洞
C语言高校实验室预约登记系统
巨杉数据库首批入选金融信创解决方案!
CSRF漏洞分析
基于ppg和fft神经网络的光学血压估计【翻译】
深度循环网络长期血压预测【翻译】
First, look at K, an ugly number
Mathematics in machine learning -- common probability distribution (XIII): Logistic Distribution
[the 300th weekly match of leetcode]
使用block实现两个页面之间的传统价值观
复现Thinkphp 2.x 任意代码执行漏洞