当前位置:网站首页>Self supervised heterogeneous graph neural network with CO comparative learning
Self supervised heterogeneous graph neural network with CO comparative learning
2022-07-06 18:30:00 【kc7w91】
Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning Paper reading
One 、 Key points
Heterograph : The basic idea of heterograph is quick pass
Dual Perspective : network schema view & meta-path structure view, Finally, the node representation obtained from the two perspectives is studied through comparison (contrastive learning) To merge
Self supervision : No label information is required , Directly use the data itself as supervision information , It can be divided into comparative learning and generative learning . This article is comparative learning , The core idea is to compare positive samples and negative samples in feature space , Feature representation of learning samples
Two 、 Two perspectives
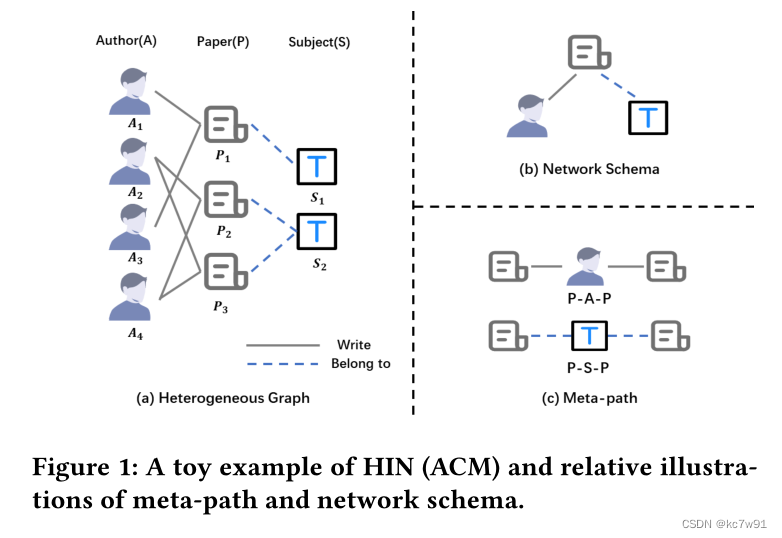
network schema Pictured 1(b), Represents the relationship between nodes of different categories
meta-path Pictured 1(c), Multiple meta paths can be defined by - article - author / article - The theme - article /…
3、 ... and 、 Model definition
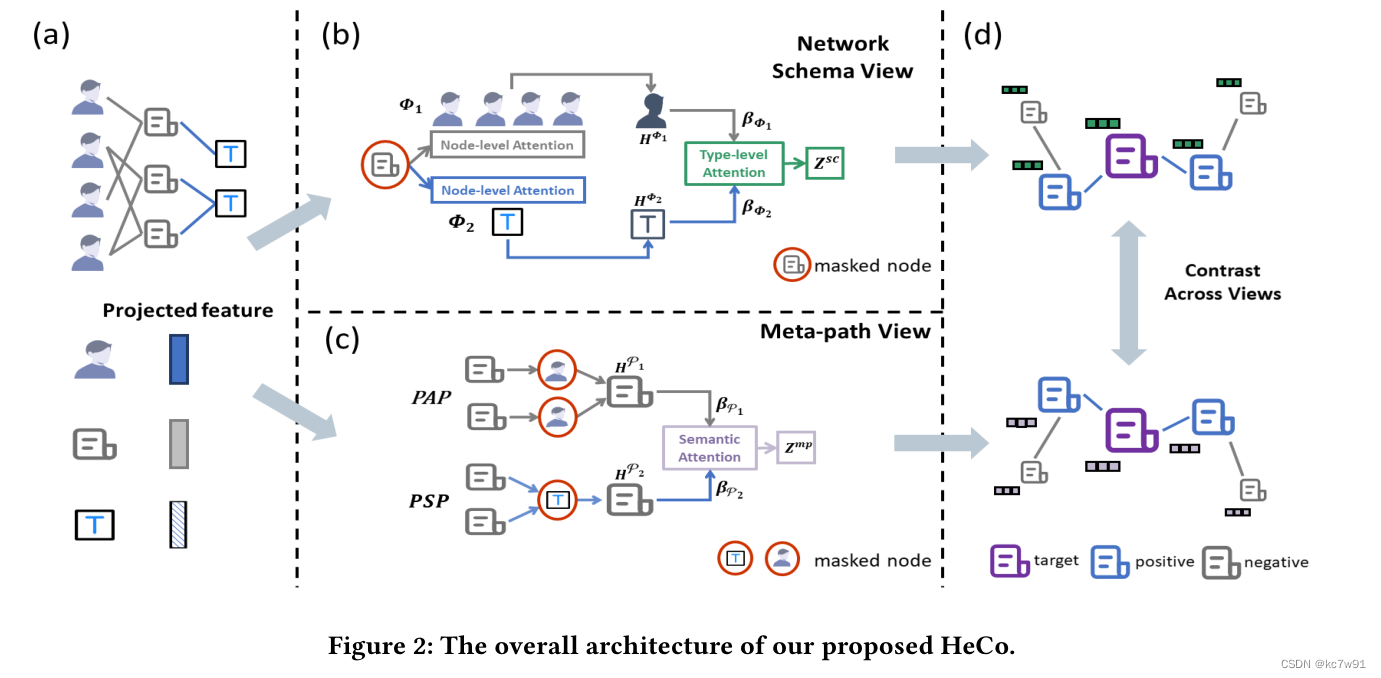
1. Preprocessing
The node characteristics of different categories x Project into the same space , The feature length alignment is recorded as h
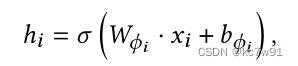
2.network schema
For an article node , stay network schema From the perspective of the author 、 Topics learn from nodes in two categories embedding, Different categories have different effects on the current node , This degree value is similar to GAT The way ( Introduce attention mechanism ) Obtained by autonomous learning of the model . Each category contains multiple nodes , The importance of different nodes varies , The importance of each point in the class is also similar GAT The way to learn .
Intra class importance alpha(node-level attention):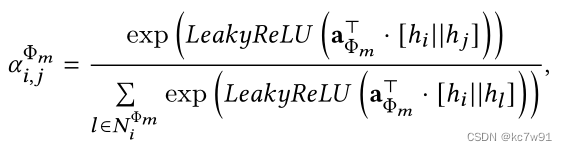
among fai_m Indicates the node category , common m Kind of ;a For the parameters to be learned
adopt node-level attention Aggregate neighbor information :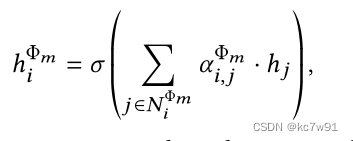
notes : Not all neighbors , There are sampling operations
Get different categories embedding To merge
Category importance beta(type-level attention):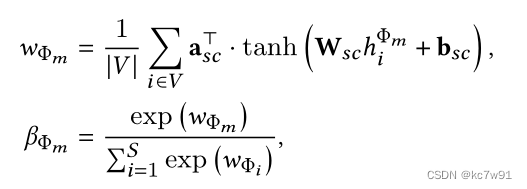
among W、b For the parameters to be learned
adopt type-level attention Aggregate different categories embedding: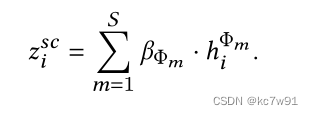
3. meta-path
Through the Metapath, we get isomorphic graph , For each isomorphic graph, use GCN Get the preliminary characterization of each node h: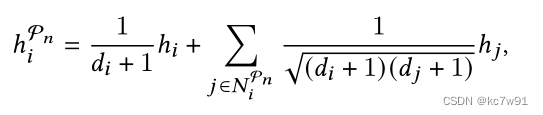
Fuse the node representations obtained under different meta paths ( It's similar GAT, semantic-level attention):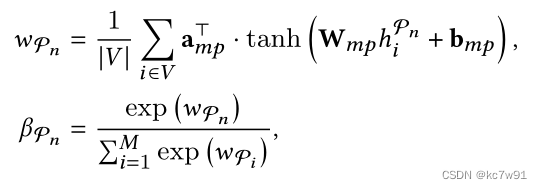
among W、b For the parameters to be learned ,beta_fai_n Is the importance of graphs obtained under different meta paths 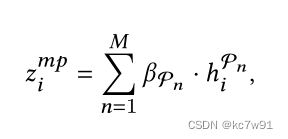
According to different degrees of importance , obtain meta-path Nodes from the perspective embedding
4. mask
network schema Nodes in do not aggregate their own information (masked),meta-path The information of the transit node is not aggregated in , This will distinguish the nodes connected with the current article by category , Don't double count .
5.contrastive learning
Fuse nodes drawn from two perspectives embedding And then judge , The first use of MLP mapping :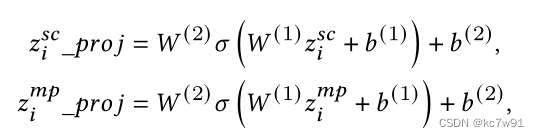
Next, introduce contrastive learning
Comparative learning : There should be a high degree of similarity between small variants of something (positive samples), The similarity between essentially different things is low (negative samples). The positive and negative samples in this paper are defined as follows :
positive: By multiple meta-path Connected node pairs ( Emphasize the importance of edges )
negative: others
With i Node network schema From the perspective of loss Function as an example , Align the nodes according to meta-path The number of connected pieces is arranged in descending order , Set the threshold to divide positive and negative samples . After the division, there are network schema view Under the contrastive loss(meta-path view Empathy ):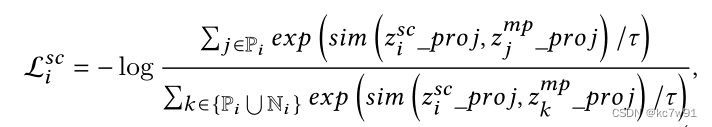
among sim by cos function , Indicates the similarity between two vectors . the reason being that network schema From the perspective of loss function , So target embedding(gt) yes network schema Medium embedding; Positive and negative samples embedding come from meta-path view. The corresponding value of positive samples should be as large as possible , The corresponding value of negative samples should be as small as possible ,loss To get smaller .
Two perspectives loss equilibrium :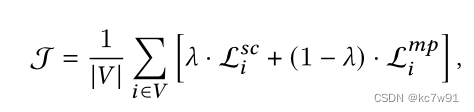
6. model extension
Hard to distinguish negative samples is very helpful to improve the performance of the comparative learning model , Therefore, a new negative sample generation strategy is introduced :GAN & Mixup
边栏推荐
猜你喜欢
![[Android] kotlin code writing standardization document](/img/d5/53d6a75e87af15799bf7e5d6eb92a5.png)
[Android] kotlin code writing standardization document
Numerical analysis: least squares and ridge regression (pytoch Implementation)

面向程序员的精品开源字体
虚拟机VirtualBox和Vagrant安装
【.NET CORE】 请求长度过长报错解决方案
Distill knowledge from the interaction model! China University of science and Technology & meituan proposed virt, which combines the efficiency of the two tower model and the performance of the intera

Blue Bridge Cup real question: one question with clear code, master three codes
Transport layer congestion control - slow start and congestion avoidance, fast retransmission, fast recovery

Declval of template in generic programming
模板于泛型编程之declval
随机推荐
node の SQLite
Interview shock 62: what are the precautions for group by?
当保存参数使用结构体时必备的开发技巧方式
2022/02/12
模板于泛型编程之declval
2022暑期项目实训(一)
Comparative examples of C language pointers *p++, * (p++), * ++p, * (++p), (*p) + +, +(*p)
Automatic reservation of air tickets in C language
The latest financial report release + tmall 618 double top, Nike energy leads the next 50 years
Coco2017 dataset usage (brief introduction)
[sword finger offer] 60 Points of N dice
Jerry is the custom background specified by the currently used dial enable [chapter]
celery最佳实践
简单易用的PDF转SVG程序
STM32 key state machine 2 - state simplification and long press function addition
Blue Bridge Cup real question: one question with clear code, master three codes
用友OA漏洞学习——NCFindWeb 目录遍历漏洞
2022 Summer Project Training (I)
Cobra 快速入门 - 专为命令行程序而生
declval(指导函数返回值范例)