当前位置:网站首页>Coco2017 dataset usage (brief introduction)
Coco2017 dataset usage (brief introduction)
2022-07-06 18:14:00 【Mufeng 8023】
I use training pictures for target tracking as data set expansion , So I only checked train Of json file .
Catalog
The introduction
COCO The full name is Common Objects in Context, It's a data set provided by Microsoft team that can be used for image recognition .MS COCO The images in the dataset are divided into training 、 Verification and test sets . The paper 、 Official website of dataset
CoCo2017 The dataset includes train(118287 Zhang )、val(5000 Zhang )、test(40670 Zhang )
CoCo There are also official API, I extract the category pictures I want according to my own ideas to train .
Folder and name of data set 
Dataset annotation json File directory 
object detection / Instance segmentation data annotation file parsing
train Annotation file of pictures
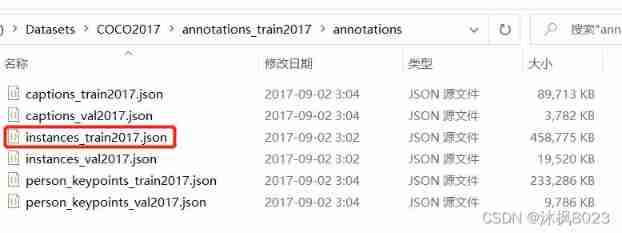
Mark the file :instances_train2017.json
This article takes COCO2017\annotations_train2017\annotations\instances_train2017.json
As an example .
This json The information in the document is as follows 5 Key values refer to .
The basic structure is as follows :
{
“info”: {…},
“licenses”: […],
“images”: […],
“categories”: […],
“annotations”: […]
}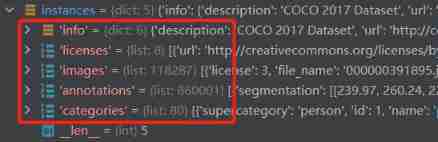
among info、images、licenses Three key It is shared by different types of annotation files , final annotations and categories It varies according to different tasks .
info:
The dictionary contains metadata about the dataset , For the official COCO Data sets , as follows :
{
“description”: “COCO 2017 Dataset”,
“url”: “http://cocodataset.org”,
“version”: “1.0”,
“year”: 2017,
“contributor”: “COCO Consortium”,
“date_created”: “2017/09/01”
}
As we can see , It contains only basic information ,"url" The value points to the official website of the dataset ( for example UCI Repository pages or in separate domains ), This is a common thing in machine learning data sets , Point to their website for more information , For example, how and when to obtain data .
licenses:
The following is a link to image licensing in the dataset , For example, knowledge sharing License , It has the following structure :
[
{
“url”: “http://creativecommons.org/licenses/by-nc-sa/2.0/”,
“id”: 1,
“name”: “Attribution-NonCommercial-ShareAlike License”
},
{
“url”: “http://creativecommons.org/licenses/by-nc/2.0/”,
“id”: 2,
“name”: “Attribution-NonCommercial License”
},
…
]
The important thing to note here is "id" Field ——"images" Each image in the dictionary should be assigned its license “id”.
When using images , Please make sure not to violate its permission —— Can be in URL Find the full text under .
If we decide to create our own dataset , Please assign the appropriate license to each image —— If we're not sure , It is best not to use this image .
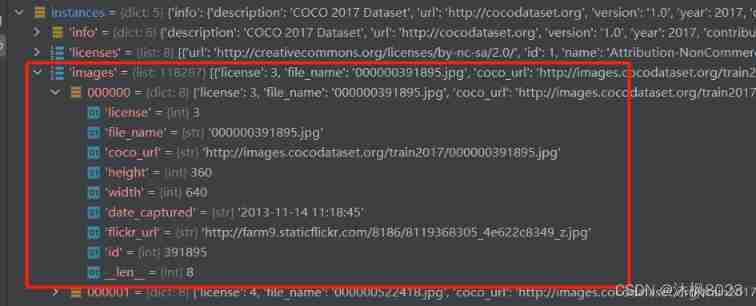
image:
This dictionary also contains the names of all pictures But there is no information about the target in the picture
Contains metadata about images :
{
“license”: 3,
“file_name”: “000000391895.jpg”,
“coco_url”: “http://images.cocodataset.org/train2017/000000391895.jpg”,
“height”: 360,
“width”: 640,
“date_captured”: “2013–11–14 11:18:45”,
“flickr_url”: “http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg”,
“id”: 391895
}
Let's take a closer look at :
“license”: From this "licenses" Part of the image license ID
“file_name”: File name in image directory
“coco_url”, “flickr_url”: Hosting image copies online URL
“height”, “width”: The size of the image , In image C It is very convenient in such a low-level language , It is very difficult to obtain the size of matrix in this language
“date_captured”: Time to take pictures
"id" Domain is the most important domain , This is for "annotations" Identify the number of the image , So if we want to recognize the comments of a given image file , Must be in " Images " Check the corresponding image document “id”, And then in “ notes ” Cross reference it .
In the official COCO Data set "id" And "file_name" identical . It should be noted that , Customize COCO This may not be the case with datasets ! This is not a mandatory rule , For example, a dataset made of private photos may have the name of the original photo that has nothing in common with "id".
categories:
Category information 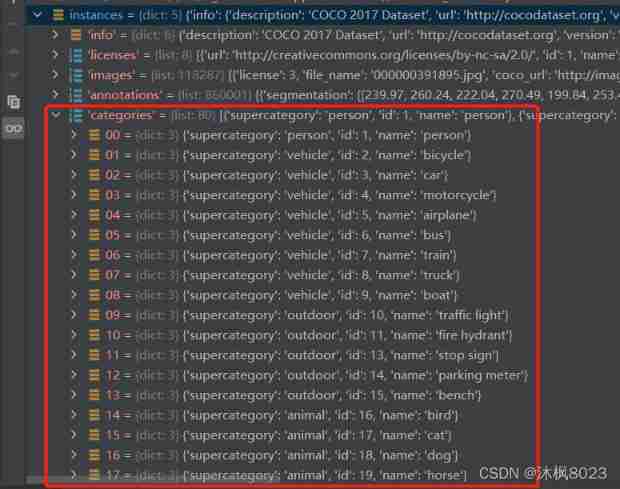
Object detection / Object segmentation :
[
{“supercategory”: “person”, “id”: 1, “name”: “person”},
{“supercategory”: “vehicle”, “id”: 2, “name”: “bicycle”},
{“supercategory”: “vehicle”, “id”: 3, “name”: “car”},
…
{“supercategory”: “indoor”, “id”: 90, “name”: “toothbrush”}
]
These are the object categories that can be detected on the image ("categories" stay COCO Is another name of the category , We can learn from supervised machine learning ).
Each category has a unique "id", They should be [1,number of categories] Within the scope of . Categories are also divided into “ Supercategory ”, We can use them in programs , for example , When we don't care about bicycles 、 When the car is still a truck , Generally detect vehicles .
annotations:
This is the most important part of the data set , It is an introduction to all target information in the data set .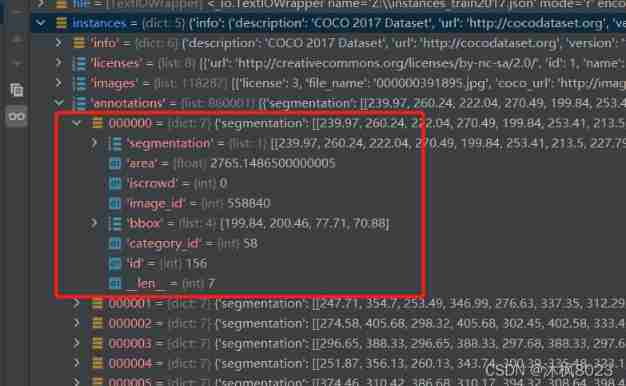
“segmentation”: Split mask pixel list ; This is a flat list of pairs , So we should use the first and second values ( In the picture x and y), Then there are the third and fourth values , To get the coordinates ; It should be noted that , These are not image indexes , Because they are floating point numbers —— They are made up of COCO-annotator And other tools to create and compress from the original pixel coordinates
“area”: Number of pixels in the segmentation mask
“iscrowd”: Annotations are for individual objects ( The value is 0), Or for multiple objects close to each other ( The value is 1); For instance segmentation , This field is always 0 And be ignored
“image_id”: ‘images’ In the dictionary ‘id’ Field ; It is the name of the picture without the suffix
“bbox”: Bounding box , That is, the coordinates of the rectangle around the object ( Top left x, Top left y, wide , high );
“category_id”: The class of the object , Corresponding " Category " Medium "id" Field
“id”: Unique identifier of the comment ; Warning : This is just a comment ID, This does not point to specific images in other dictionaries !
Finally, when using data sets , To use image_id To get the picture of the target , Use bbox Get the bounding box of the target ,category_id To get the category of goals , These are the three main parameters
Code
import json
import os
# Progress bar ,[ Program links ](https://blog.csdn.net/weixin_50727642/article/details/119965701)
from Tools import progressDialog
""" instances = { 'info':a dict [ It saves some meta information of the data set , Not used in use , You can ignore ], 'licenses':a list [ Some shared knowledge , Some license links for images ], 'images':a list [ All the training is saved train Picture information , For example, the name of the picture , The source URL of the picture , The width and height of the image ], 'categories': a list [ All categories are saved ,, Each list holds a category information , There are superclasses , Category id, The name of the category , These three messages ], 'annotations': a list [ What is saved is the information of all targets , Each element in the list is a dictionary , There is information needed for segmentation in the dictionary , And the information needed for detection ,] } Let's focus on images、annotations The information in these two lists , It's all a list , The element of each list is a dictionary 'images' = [{'license' : 3(a int), 'file_name' : '000000391895.jpg'(a str), 'coco_url' : website (a str), 'height' : 360(a int), 'width' : 640(a int), 'date_captured" : Time (a str), 'flickr_url' : website (a str), 'id' : 8(a int)}, {}, ....] 'annotations' = [{'segmentation' : [[float, ....]](a list), 'area' : (a float), 'iscrowd' : 0(a int), 'image_id' : 558840(a int), 'bbox' : [float, float, float, float](a list), 'category_id' : 58(a int), 'id' : 156(a, int)}, {}, ....] """
class AnalysisCoCo:
""" Saved data format {'000000000025' : {'path' : r'Z:\\Datasets\\COCO2017\\train2017\\000000000025.jpg', 'objects':[{'bbox' : [float, float, float, float], 'category_id':str, 'category_name':str}, {}, ...]}, '000000000026' : {'path' : r'Z:\\Datasets\\COCO2017\\train2017\\000000000026.jpg', 'objects':[{'bbox' : [float, float, float, float], 'category_id':str, 'category_name':str}, {}, ...]}, .... } """
def __init__(self, root, save, name="CoCo", is_train=True, bbox_area_thresh=500., cls=()):
""" :param root: The root directory of the dataset :param save: The directory where the generated files are saved :param name: Dataset name :param is_train: Training data set or validation data set :param bbox_area_thresh: The area threshold of the selected bounding box :param cls: Retained categories """
self.name = name
self.bbox_area_thresh = float(bbox_area_thresh)
self.cls = cls
self.flag = False if len(cls) == 0 else True # When cls This condition is enabled only when tuples have elements ,
self.root = root # ...\Datasets\COCO2017
self.save = self._check_dir(os.path.join(save, name)) # .../datasets_txt/CoCo
if is_train:
self.instances_path = 'instances_train2017.json'
self.sub_dir = 'train2017'
else:
self.instances_path = 'instances_val2017.json'
self.sub_dir = 'val2017'
self.analysis_coco()
def analysis_coco(self):
instances = self._read_json(os.path.join(self.root, 'annotations_train2017',
'annotations', self.instances_path))
# First, get the category information , It's a list
categories = instances['categories']
# Save category information ,classes={int:str, ...}
classes = {
}
for step, category in enumerate(categories):
# category:{'supercategory':(str), 'name':(str), 'id':(int)}
progressDialog(len(categories), step, information=' Category information extraction ...')
name = category['name'] # str
# super_name = category['supercategory']
id_ = category['id'] # int
classes[str(id_)] = name # [ class , Superclass ]
annotations = instances['annotations']
information = {
} # Save the final information
image_name = [] # The name of the picture
for step, annotation in enumerate(annotations):
progressDialog(len(annotations), step, information=" Targeted information is being extracted ...")
image_id = annotation['image_id'] # Image name ,int
bbox = annotation['bbox'] # list
category_id = annotation['category_id'] # Category No int
iscrowd = annotation['iscrowd'] # int 0: Easy to detect ;1: It's not easy to detect
# print('bbox:%f*%f=%f ' % (bbox[2], bbox[3], bbox[2] * bbox[3]), 'area:', annotation['area'])
if self.flag and classes[str(category_id)] not in self.cls: # Choose a new target instead of the category you want to use
continue
# Only when the area of the target is greater than the threshold, the information of the target will be saved
if bbox[2] * bbox[3] >= self.bbox_area_thresh:
# The name of the picture is not in the message information Saved in the dictionary
if image_id not in image_name:
image_name.append(image_id)
# Create a new key value pair
information['%012d' % image_id] = {
'path': os.path.join(self.root,
self.sub_dir,
'%012d.jpg' % image_id),
'objects': [{
'bbox': bbox,
'category_id': str(category_id),
'category_name': classes[str(category_id)],
'iscrowd': iscrowd}]}
# The name of the picture is already in the message information Saved in the dictionary
else:
# Add a dictionary to the list to save the information of each target
information['%012d' % image_id]['objects'].append({
'bbox': bbox,
'category_id': str(category_id),
'category_name': classes[str(category_id)],
'iscrowd': iscrowd})
else: # The area of the target does not meet the conditions , Just skip this goal
continue
# Save information to json In file
self._save_json(os.path.join(self.save, 'classes.json'), classes)
self._save_json(os.path.join(self.save, 'CoCo.json'), self.sorted_dict(information))
print("Finish...")
@staticmethod
def sorted_dict(_dict: dict):
_tuple = sorted(_dict.items(), key=lambda item: item[0])
_dict = {
k: v for k, v in _tuple}
return _dict
@staticmethod
def _read_json(_path):
with open(_path, 'r', encoding='utf-8') as file:
information = json.load(file)
return information
@staticmethod
def _save_json(_path, lines: dict):
print("Saving file to %s" % _path)
with open(_path, 'w', encoding='utf-8') as file:
json.dump(lines, file, indent=4)
@staticmethod
def _check_dir(_path):
if not os.path.exists(_path):
os.makedirs(_path)
return _path
if __name__ == '__main__':
project_path = os.path.dirname(os.getcwd())
print("Analysis CoCo ...")
coco = AnalysisCoCo(root=os.path.join(r'Z:\Datasets', 'COCO2017'),
save=os.path.join(project_path, 'datasets_txt'),
bbox_area_thresh=1314.0,
cls=("person", "car", "airplane", "motorcycle",
"truck", "boat", "cat", "dog", "horse", "sheep",
"cow", "elephant", "bear", "zebra", "giraffe",))
边栏推荐
- MSF horizontal MSF port forwarding + routing table +socks5+proxychains
- 2022 Summer Project Training (I)
- This article discusses the memory layout of objects in the JVM, as well as the principle and application of memory alignment and compression pointer
- The integrated real-time HTAP database stonedb, how to replace MySQL and achieve nearly a hundredfold performance improvement
- C语言通过指针交换两个数
- What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
- Implementation of queue
- C language exchanges two numbers through pointers
- 2022暑期项目实训(二)
- Prophet模型的简介以及案例分析
猜你喜欢
C language exchanges two numbers through pointers
The third season of Baidu online AI competition is coming in midsummer, looking for you who love AI!
传输层 拥塞控制-慢开始和拥塞避免 快重传 快恢复

Declval (example of return value of guidance function)
Comparative examples of C language pointers *p++, * (p++), * ++p, * (++p), (*p) + +, +(*p)

Recursive way
從交互模型中蒸餾知識!中科大&美團提出VIRT,兼具雙塔模型的效率和交互模型的性能,在文本匹配上實現性能和效率的平衡!...
Kivy tutorial: support Chinese in Kivy to build cross platform applications (tutorial includes source code)
Distinguish between basic disk and dynamic disk RAID disk redundant array
Windows connects redis installed on Linux
随机推荐
Pytest learning ----- pytest confitest of interface automation test Py file details
Declval (example of return value of guidance function)
2022暑期项目实训(一)
SQL statement optimization, order by desc speed optimization
Distiller les connaissances du modèle interactif! L'Université de technologie de Chine & meituan propose Virt, qui a à la fois l'efficacité du modèle à deux tours et la performance du modèle interacti
面向程序员的精品开源字体
This article discusses the memory layout of objects in the JVM, as well as the principle and application of memory alignment and compression pointer
李書福為何要親自掛帥造手機?
容器里用systemctl运行服务报错:Failed to get D-Bus connection: Operation not permitted(解决方法)
C语言通过指针交换两个数
UDP protocol: simple because of good nature, it is inevitable to encounter "city can play"
Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices
UDP协议:因性善而简单,难免碰到“城会玩”
Selected technical experts from China Mobile, ant, SF, and Xingsheng will show you the guarantee of architecture stability
Jerry is the custom background specified by the currently used dial enable [chapter]
8位MCU跑RTOS有没有意义?
FMT open source self driving instrument | FMT middleware: a high real-time distributed log module Mlog
2019 Alibaba cluster dataset Usage Summary
Four processes of program operation
Interview shock 62: what are the precautions for group by?