当前位置:网站首页>Distiller les connaissances du modèle interactif! L'Université de technologie de Chine & meituan propose Virt, qui a à la fois l'efficacité du modèle à deux tours et la performance du modèle interacti
Distiller les connaissances du modèle interactif! L'Université de technologie de Chine & meituan propose Virt, qui a à la fois l'efficacité du modèle à deux tours et la performance du modèle interacti
2022-07-06 18:09:00 【J'aime la vision par ordinateur】
Attention au numéro public,DécouverteCVLa beauté de la technologie
Cet article est partagé『VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction』,Distillation des connaissances à partir de modèles interactifs!University of Central Science and Technology&Meituan a proposéVIRT,Efficacité du modèle à deux tours et performance du modèle interactif,Équilibrer la performance et l'efficacité dans l'appariement des textes!
Les détails sont les suivants::

Liens vers les articles:https://arxiv.org/abs/2112.04195
01
Résumé
Avec la pré - formationTransformerL'essor de,Basé sur le jumelageTransformerLe modèle de représentation de l'encodeur est devenu la principale technologie d'appariement de texte efficace.Et pourtant,Comparé au modèle interactif,En raison du manque d'interaction entre les paires de textes,Les performances de ces modèles ont fortement diminué.L'état de la technique tente de résoudre ce problème par une interaction supplémentaire avec les représentations codées jumelles,Et l'interaction dans le processus de codage est toujours ignorée.
Pour résoudre ce problème,L'auteur propose un Interaction virtuelle (VIRT), Transfert des connaissances interactives d'un modèle basé sur l'interaction à un encodeur jumeau par extraction de cartes d'attention .VIRT En tant que composant utilisé uniquement pour l'exécution de l'entraînement , Peut maintenir complètement l'efficacité de la structure jumelle , Et il n'y a pas de coûts de calcul supplémentaires dans le processus de raisonnement . Pour tirer le meilleur parti des connaissances interactives apprises , L'auteur a ensuite conçu une adaptation VIRT Stratégie d'interaction pour .
Les résultats expérimentaux sur plusieurs ensembles de données de correspondance de texte montrent que , La méthode présentée dans cet article est supérieure au modèle actuel fondé sur la représentation. .En outre,VIRT Peut être facilement intégré dans une approche fondée sur la représentation existante , Pour réaliser d'autres améliorations .
02
Motivation
L'appariement de texte est conçu pour modéliser l'Association sémantique entre deux textes , Il s'agit d'un problème fondamental dans la compréhension et l'application de diverses langues naturelles. .Par exemple, Questions et réponses dans la communauté (CQA)Dans le système, Un élément clé consiste à trouver des problèmes similaires liés aux problèmes des utilisateurs dans la base de données grâce à l'appariement des problèmes .De même,, L'agent de dialogue doit faire une inférence logique en prédisant la relation implicite entre les déclarations de l'utilisateur et certaines hypothèses prédéfinies .
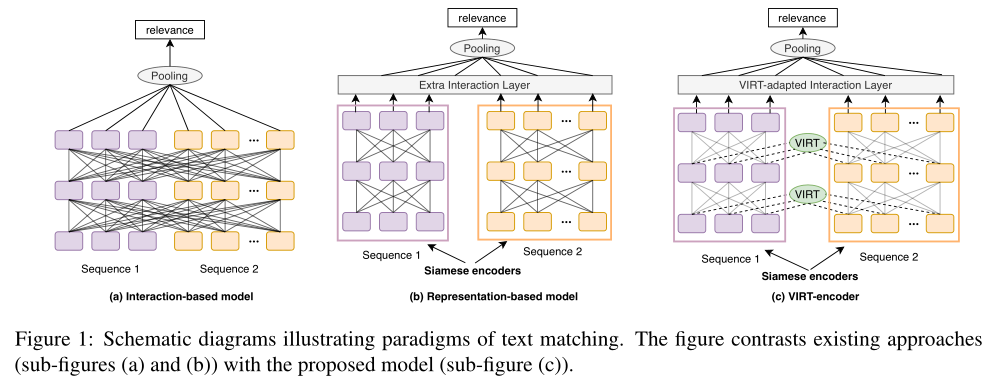
Récemment,Pré - formation approfondieTransformer Des progrès remarquables ont été accomplis dans l'utilisation généralisée de l'appariement des textes . Il y a généralement deux types basés sur le réglage fin Transformer Exemple d'encodeur : Modèle interactif ( C'est - à - dire l'encodeur croisé ) Et des modèles basés sur la représentation ( C'est - à - dire un double encodeur ),Comme indiqué ci - dessus(a)Et(b)Comme indiqué. Modèle interactif (Par exemple,BERT) Apparier le texte concat Pour une seule séquence , Et une interaction complète entre les paires de texte . Bien que l'interaction complète fournisse un signal de correspondance riche du Bas au haut du modèle , Mais il entraîne également des coûts de calcul plus élevés et des retards de raisonnement , Il est donc difficile de le déployer dans un scénario réel .
Par exemple, Dans un système de recherche de commerce électronique , Parce qu'il y a des millions de bonnes requêtes , Il faut des dizaines de jours pour évaluer ces paires à l'aide d'un modèle interactif .Au contraire., Le modèle basé sur la représentation est codé indépendamment par deux encodeurs jumeaux , Sans aucune interaction .Donc,, Il prend en charge les calculs hors ligne intégrés , Cela réduit considérablement les retards en ligne , Ce qui rend ces modèles très utiles dans la pratique .Malheureusement,, Un codage indépendant sans aucune interaction peut perdre le signal correspondant ,Ce qui entraîne une grave dégradation des performances.
Pour équilibrer efficacité et efficience , Certains travaux ont tenté d'équiper les structures jumelles de modules interactifs . Diverses stratégies d'interaction ont été proposées. , Comme le niveau d'attention et TransformerCouche.Et pourtant,Pour des raisons d'efficacité, Ces modules d'interaction sont ajoutés après l'encodeur jumeau , Pour préserver les caractéristiques jumelles , L'interaction dans le processus d'encodage des encodeurs jumeaux est toujours ignorée .Donc,, Perte de signaux interactifs riches , Les modèles actuels basés sur la représentation sont encore loin derrière les modèles basés sur l'interaction en ce qui concerne .
Dans ce travail, L'auteur tente de briser le dilemme entre les modèles basés sur l'interaction et les modèles basés sur la représentation . L'idée clé est que dans un modèle basé sur la représentation , Sans détruire la structure jumelle , Intégration des interactions dans le processus de codage jumelé .À cette fin,, L'auteur propose une interaction virtuelle (VIRT), Il s'agit d'un nouveau mécanisme de transmission des connaissances dans l'interaction texte - paire à un encodeur jumeau basé sur un modèle de représentation .
Plus précisément,, L'encodeur jumeau apprend l'interaction entre ces deux textes en imitant l'interaction complète , Et guidé par les connaissances transmises par le modèle interactif . Réaliser le transfert des connaissances en tant que tâche d'extraction de cartes d'attention dans le processus de formation , Cette tâche peut être supprimée pendant le raisonnement pour maintenir les caractéristiques jumelles .Donc ça s'appelle“Interaction virtuelle”.En outre, Afin d'utiliser davantage les connaissances interactives acquises après le codage jumelé , L'auteur a conçu une stratégie interactive d'adaptation virtuelle .Dans un endroit appeléVIRT Le modèle basé sur la représentation de l'encodeur est mis en oeuvre conjointement VIRTEtVIRT Stratégies d'interaction adaptées ,Comme indiqué ci - dessus(c)Comme indiqué.
De cet articleContributionIl peut être résumé comme suit::
L'auteur propose un nouveau mécanisme d'interaction virtuelle VIRT, En extrayant des cartes d'attention d'un modèle interactif , Intégration dans un encodeur jumeau basé sur un modèle de représentation , Sans frais supplémentaires de raisonnement .
Beaucoup d'expériences ont montré,Ce qui est proposé iciVIRT Les encodeurs sont meilleurs que ceux basés sur SOTA Modèle représenté , Tout en maintenant l'efficacité du raisonnement .
VIRT Peut être facilement intégré dans d'autres modèles de correspondance de texte basés sur la représentation ,Pour améliorer encore ses performances.
03
Méthodes
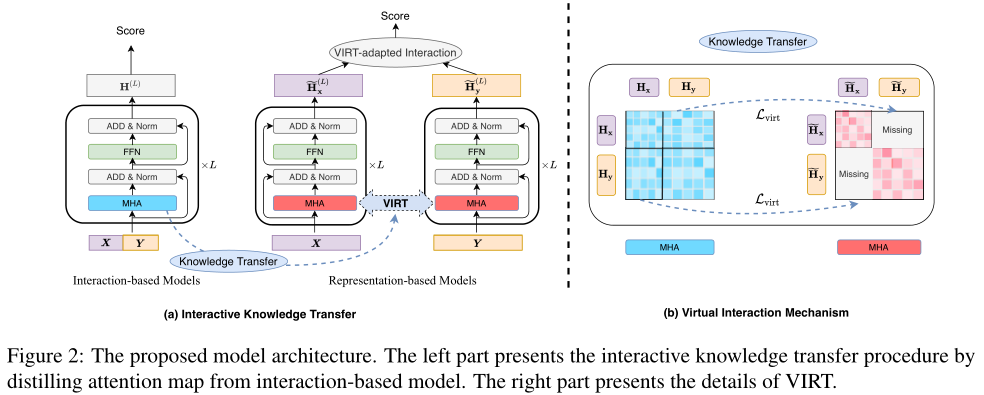
Dans cette section, Les auteurs décriront d'abord le modèle interactif et le modèle fondé sur la représentation. .Et puis, Introduction aux interactions virtuelles (VIRT), Il extrait les connaissances interactives du modèle interactif à l'encodeur jumeau .En outre,AdoptionVIRT Stratégies d'interaction adaptées , Peut tirer pleinement parti des connaissances interactives apprises .VIRT L'architecture est illustrée ci - dessus .
3.1 Interaction-based Models
Compte tenu de deux séquences de texte et comme entrée , Le modèle interactif XEtY concatPour,Et utiliserLCoucheTransformer Codage des paires :.Transformer Chaque couche se compose de deux sous - couches résiduelles : Une opération Multi - attention (MHA) Et un réseau d'alimentation (FFN):
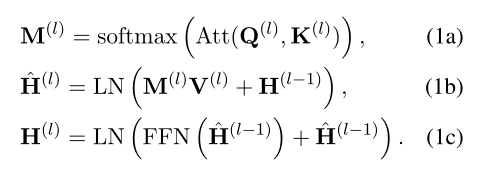
,Parmi euxd Est la dimension de l'état caché .Ici.,Pour faciliter la description,Omisbatch Dimensions de la taille et de la tête d'attention .
402 Payment Required
Oui.(l-1) Représentation du milieu de la couche ,C'est vrai.XEtY L'information interactive entre eux est codée . Et Oui.l Paramètres d'attention de la couche ,Par Cartographié. ReprésentationLayerNormFonctionnement.Je vois., Le modèle interactif permet de coder l'information interactive par un mécanisme d'attention totale à XEtYDans la représentation de.Plus précisément, Combiner les représentations pour générer des cartes d'attention M, Qui représente le poids des différents signaux interactifs . Ces représentations sont basées sur M Pour la sélection et la fusion .
3.2 Representation-based Models
Comparé au modèle interactif, Le modèle basé sur la représentation commence par deux jumeaux indépendants Transformer Encodeurs paires séparées XEtYCodage( Supposons que chaque encodeur ait L- Oui.TransformerCouche):,.Et puis, Ils interagissent davantage avec les sommes codées jumelles .transformer La même structure que le modèle interactif , Je fais juste attention à la photo (Ou)Avec seulementX(OuY)Calcul séparé:
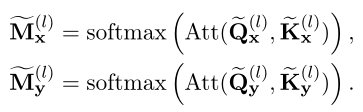
Comparé au modèle interactif,Pendant le codageXEtY Il n'y a pas d'interaction entre . Dans un modèle basé sur la représentation ,XEtY L'information sur les interactions à grain fin entre les ,Cela peut entraîner une dégradation des performances.
3.3 Virtual Interaction
Comme indiqué précédemment, Le principal inconvénient du modèle basé sur la représentation est l'absence d'interaction lors de l'encodage séparé de deux séquences d'entrée .Intuitivement, Le modèle interactif passe par MHA Le mécanisme effectue l'interaction . Par correspondance avec XEtY Pour calculer .Comparé au modèle interactif, Le modèle basé sur la représentation passe seulement par X(OuY)Calcul séparé(Ou).Dans la section suivante, Les deux modèles seront d'abord détaillés dans MHA Différences opérationnelles .Et puis...,IntroductionVIRTMécanismes, Il peut améliorer le modèle basé sur la représentation sans coûts supplémentaires de raisonnement .
Tout d'abord, décomposez MHAFonctionnement,Comme indiqué ci - dessus(b) L'attention bleue dans le graphique montre .En particulier:, Dans le modèle interactif l L'entrée de la couche représente ,C'est - à - dire:,Peut être décomposé enXPartie etYSection.Donc,,,Parmi eux,
402 Payment Required
.Sur cette base, Les paramètres d'attention peuvent également être réécrits comme suit: XSection(Exprimé en Et )EtYSection(Exprimé en Et )Combinaison de.Softmax(·) Score d'attention final avant l'opération (Exprimé en ) Peut être décomposé en la matrice de partition suivante :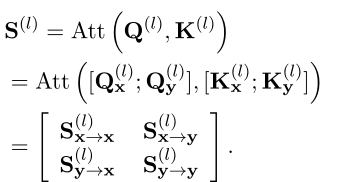
Il peut donc être divisé en quatre parties :
402 Payment Required
,C'est - à - dire::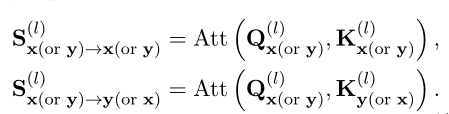
Oui seulementXOuYExécuté dansMHAFonctionnement, Il correspond à MHAFonctionnement. Et se réfère au modèle basé sur l'interaction xEtYInteraction entre, Ces modèles sont chargés d'enrichir la représentation avec des informations interactives .Et pourtant, Ils manquent dans le modèle basé sur la représentation , Il en résulte un écart de performance entre les deux modèles .
Par l'analyse ci - dessus, Les interactions manquantes d'un modèle basé sur la représentation peuvent être extraites comme suit: XEtYEntreMHAFonctionnement. Pour restaurer cette interaction manquante , Faire en sorte que la simulation de modèle basée sur la représentation soit basée sur l'interaction dans le modèle interactif ,Comme suit:
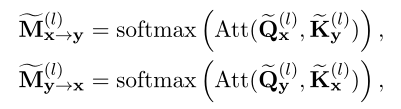
Où est indiqué par attend Au graphique d'attention généré ,Indique parattend Au graphique d'attention généré . .Ces deux graphiques d'attention supplémentaires représentent les signaux interactifs manquants dans le modèle basé sur la représentation .
Parce que nous voulons améliorer la performance du modèle basé sur la représentation en un modèle basé sur l'interaction , Par conséquent, l'auteur propose d'aligner les cartes d'attention manquantes sur leurs correspondances existantes dans le modèle interactif . Le diagramme d'attention dans le modèle interactif peut guider la représentation (Et) Vers l'enrichissement interactif , C'est comme s'ils interagissaient dans le processus de codage. .De cette façon, Extraction des connaissances au cours de l'interaction , Et le transférer dans un double encodeur , Sans frais généraux de calcul supplémentaires . C'est pourquoi ce mécanisme est appelé “Interaction virtuelle”.
Pour réaliserVIRT, L'auteur a utilisé la technologie de distillation des connaissances , L'un des modèles interactifs formés est considéré comme un enseignant. , Un modèle basé sur la représentation qui nécessite une formation est considéré comme un étudiant . Et le modèle interactif correspondant XEtYInteraction entre. Ils peuvent aller directement de softmax(·) Obtenu à partir des scores d'attention précédents : Oui, avant. mLigne et finn Section colonne , Correspond au dernier nLigne et avantmColonnes.Sauf quesoftmaxHors fonctionnement, L'auteur a également choisi les deux tranches directement , Pour former un diagramme d'attention guidé à partir d'un modèle interactif :
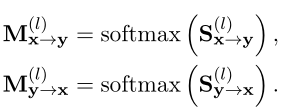
Transfert ultérieur des connaissances en tant qu'interaction supervisée ,Pour guiderVIRT.Plus précisément,, L'objectif est de minimiser et L2Distance:
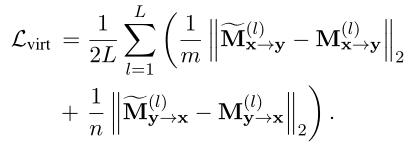
Utiliser la formule ci - dessus comme objectif d'optimisation seulement pendant la phase de formation , Et le supprimer pendant le raisonnement . Ceci préserve les attributs jumeaux du modèle basé sur la représentation , Sans frais supplémentaires de raisonnement .
3.4 VIRT-Adapted Interaction
AdoptionVIRT, Les connaissances interactives peuvent pénétrer dans chaque couche de codage d'un modèle basé sur la représentation .Et pourtant, Après le double codage , Représentation de la dernière couche ,Et, Toujours incapable de se voir , Il n'y a donc pas d'interaction Claire . Pour tirer le meilleur parti des connaissances interactives apprises , L'auteur a ensuite conçu une adaptation VIRT Stratégie d'interaction pour ,La stratégie est mise en œuvreVIRT La carte de l'attention de l'apprentissage est intégrée et .
En particulier:, L'auteur exécute et entre VIRT Adaptation aux interactions . La formule du diagramme d'attention qui en résulte est la suivante :
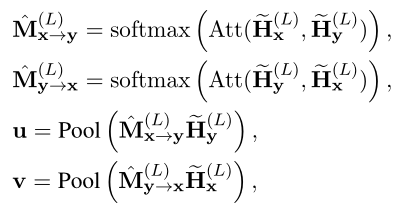
Parmi euxPool(·) Représente la moyenne des opérations de mise en commun .Enfin, Prédiction de l'appariement des étiquettes par fusion simple y:
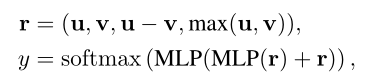
Il y aconcatFonctionnement,MLPReprésente un perceptron multicouche. L'objectif général de la formation est de réduire la perte de supervision d'une tâche particulière. (C'est - à - dire la perte d'entropie croisée) La combinaison de et est réduite au minimum :
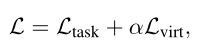
Parmi euxα Est un superparamètre pour mesurer l'impact d'une interaction virtuelle .
Ce qui est remarquable, c'est que,VIRT C'est une stratégie universelle , Peut être utilisé pour améliorer n'importe quel modèle de correspondance basé sur la représentation .
04
L'expérience
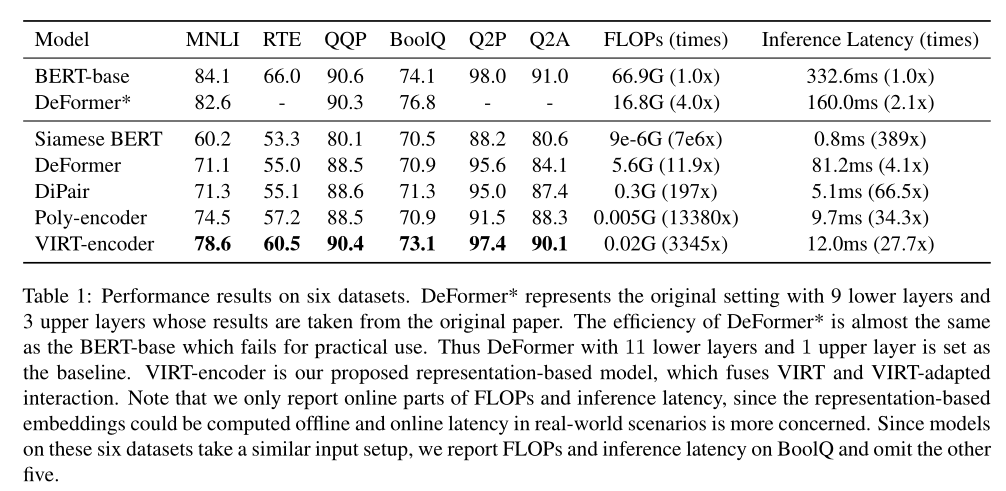
Les performances des différentes méthodes sont présentées dans le tableau ci - dessus. .BERT-base En tant que modèle interactif puissant ,Montre son efficacité.AvecBERTComparé à,Siamese BERTLes performances de.Ce qui est proposé iciVIRT Encodeur pour une meilleure performance , Meilleur que tous les baseline, Même avec des BERT Le modèle est compétitif par rapport à .Ça prouveVIRT Capacité d'approximation du modèle interactif pour la modélisation interactive en profondeur .
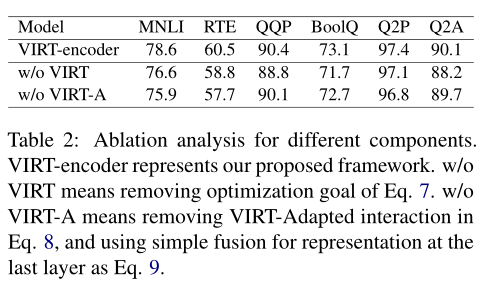
Le tableau ci - dessus montre les VIRTEtVIRT Contribution à l'adaptation aux interactions .Non utiliséVIRTOuVIRT La dégradation des performances pour s'adapter à l'interaction démontre l'efficacité des deux Architectures .PourMNLIEtRTE, En raison de l'enlèvement VIRT La dégradation des performances due aux interactions adaptatives est encore plus grave .
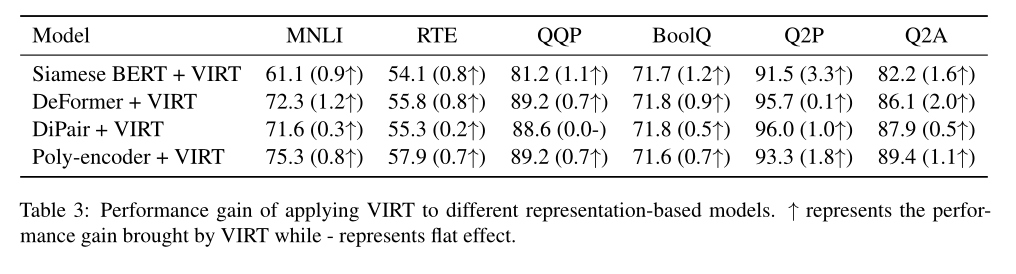
Pour vérifier ce qui est proposéVIRTLa polyvalence de, L'auteur l'a ensuite importé dans le modèle fondé sur la représentation décrit ci - dessus. .Les résultats sont présentés dans le tableau ci - dessus..Sur la base des résultats,Peut être observéVIRT Peut être facilement intégré dans d'autres modèles de correspondance de texte basés sur la représentation ,Pour améliorer encore les performances.
05
Résumé
Les modèles basés sur la représentation sont largement utilisés dans les tâches de correspondance de texte en raison de leur grande efficacité , Et le modèle basé sur l'interaction n'est pas très performant en raison du manque d'interaction . Les travaux antérieurs ont souvent introduit des couches d'interaction supplémentaires , .Et l'interaction dans l'encodeur jumeau est toujours manquante .
Dans cet article, L'auteur propose une interaction virtuelle (VIRT)Mécanismes, Ce mécanisme permet d'approximation de la capacité de modélisation interactive en extrayant des diagrammes d'attention d'un modèle basé sur l'interaction à un encodeur jumeau basé sur un modèle de représentation , Sans frais supplémentaires de raisonnement .
PropositionVIRTEncodeur adoptéVIRTEtVIRT Adapter les stratégies d'interaction , Mise à jour des performances des modèles basés sur la représentation existants dans plusieurs tâches de correspondance de texte .En outre,VIRT D'autres améliorations ont été apportées au modèle actuel fondé sur la représentation. .
Références
[1]https://arxiv.org/abs/2112.04195

END
Adhésion「Vision par ordinateur」Remarques du Groupe AC:CV

边栏推荐
- Principle and usage of extern
- 2022暑期项目实训(三)
- What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
- kivy教程之在 Kivy 中支持中文以构建跨平台应用程序(教程含源码)
- C语言通过指针交换两个数
- RB157-ASEMI整流桥RB157
- Rb157-asemi rectifier bridge RB157
- VR panoramic wedding helps couples record romantic and beautiful scenes
- Unity particle special effects series - treasure chest of shining stars
- Fleet tutorial 13 basic introduction to listview's most commonly used scroll controls (tutorial includes source code)
猜你喜欢
虚拟机VirtualBox和Vagrant安装
Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices

递归的方式

偷窃他人漏洞报告变卖成副业,漏洞赏金平台出“内鬼”

2019 Alibaba cluster dataset Usage Summary
30 分钟看懂 PCA 主成分分析

1700C - Helping the Nature
SAP UI5 框架的 manifest.json

趣-关于undefined的问题
std::true_type和std::false_type
随机推荐
李书福为何要亲自挂帅造手机?
Interview shock 62: what are the precautions for group by?
STM32按键状态机2——状态简化与增加长按功能
VR panoramic wedding helps couples record romantic and beautiful scenes
declval(指导函数返回值范例)
Getting started with pytest ----- allow generate report
酷雷曼多种AI数字人形象,打造科技感VR虚拟展厅
The latest financial report release + tmall 618 double top, Nike energy leads the next 50 years
HMS Core 机器学习服务打造同传翻译新“声”态,AI让国际交流更顺畅
How to solve the error "press any to exit" when deploying multiple easycvr on one server?
kivy教程之在 Kivy 中支持中文以构建跨平台应用程序(教程含源码)
Heavy! Ant open source trusted privacy computing framework "argot", flexible assembly of mainstream technologies, developer friendly layered design
面试突击62:group by 有哪些注意事项?
In terms of byte measurement with an annual salary of 30W, automated testing can be learned in this way
Why should Li Shufu personally take charge of building mobile phones?
The difference between parallelism and concurrency
[introduction to MySQL] the first sentence · first time in the "database" Mainland
C语言通过指针交换两个数
Unity particle special effects series - treasure chest of shining stars
面试突击62:group by 有哪些注意事项?