当前位置:网站首页>Interpretation of Dagan paper
Interpretation of Dagan paper
2022-07-06 19:30:00 【‘Atlas’】
List of articles
The paper : 《Depth-Aware Generative Adversarial Network for Talking Head Video Generation》
github: https://github.com/harlanhong/CVPR2022-DaGAN
solve the problem
Existing problems :
Existing video generation schemes mainly use 2D characterization , Face 3D Information is actually critical to this task , Then note that it costs a lot ;
resolvent :
The author of this paper proposes a self-monitoring scheme , Automatically generate dense from face video 3D Geometric information , No need for any annotation data ; Based on this information , Further estimate the sparse face key points , Used to capture important movements of the head ; Depth information is also used for learning 3D Cross modal ( Appearance and depth )attention Mechanism , Guide the generation of a sports field used to distort the original image ;
What this article puts forward DaGAN It can generate highly realistic faces , And it has achieved good results on faces that have never been seen before ;
The contributions of this paper mainly include the following three points :
1、 Introduce self-monitoring method to fit depth map from video , And use it to improve the generation effect ;
2、 Propose novel and deep concerns GAN, Depth guided facial key point estimation and cross modal ( Depth and image )attention Mechanism , Introduce depth information into the generation network ;
3、 Full experiments show the accurate depth fitting of face images , At the same time, the production effect exceeds SOTA;
Algorithm
DaGAN The method is shown in the figure 2, It is composed of generator and discriminator ;
The generator consists of three parts :
1、 Self supervised deep information learning sub network F d F_d Fd, Self supervised learning depth estimation from two consecutive frames in video ; Then fix F d F_d Fd Conduct the whole network training ;
2、 Depth information guided sparse key detection sub network F k p F_{kp} Fkp;
3、 The feature distortion module uses key points to generate change regions , It has combined appearance information with motion information by distorting source image features , Get distorted features F w F_w Fw; To ensure that the model pays attention to details and facial microexpressions , Learn more about paying attention to in-depth information attention map, Its refinement F w F_w Fw obtain F g F_g Fg, Used to generate images I g I_g Ig;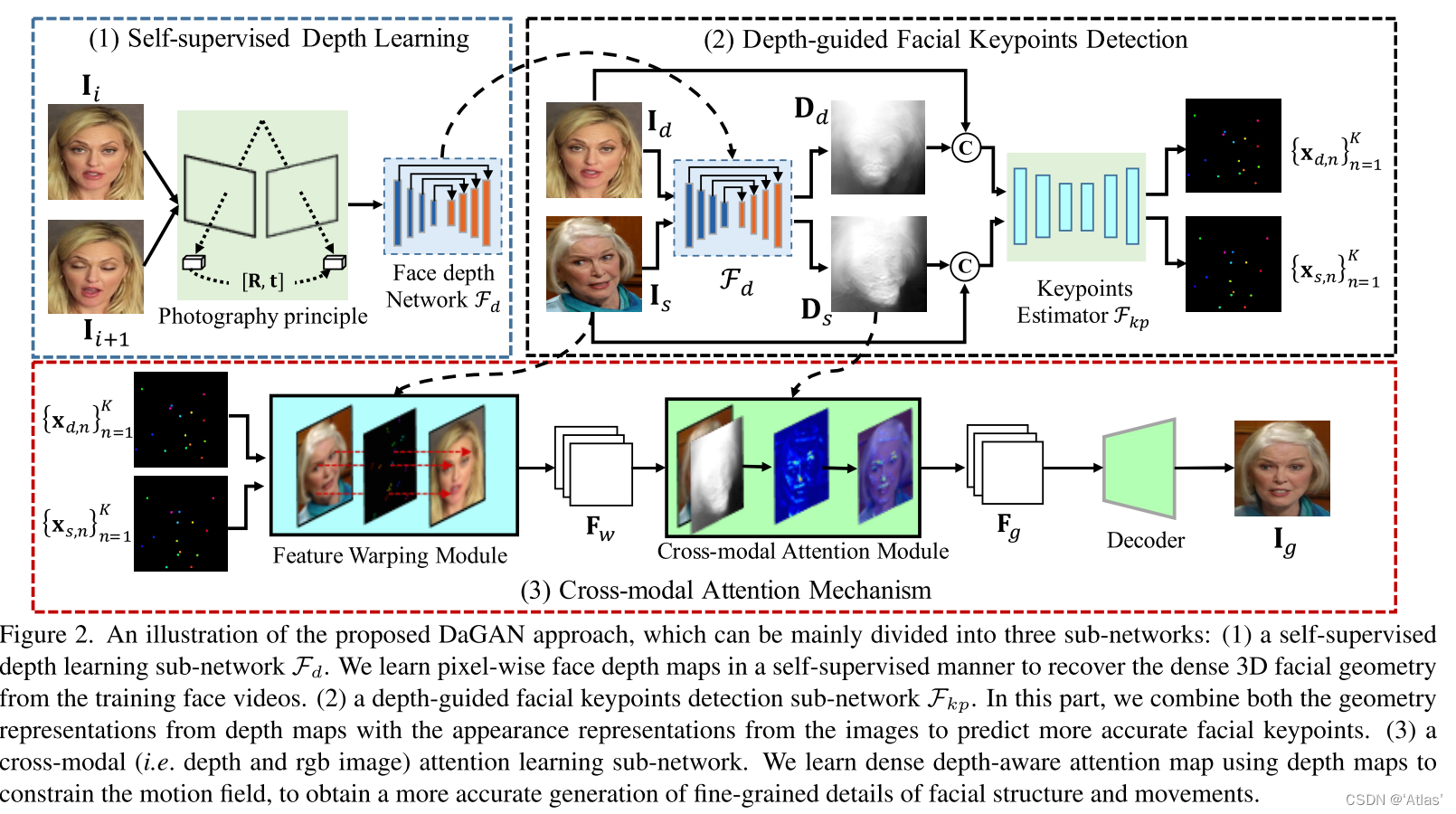
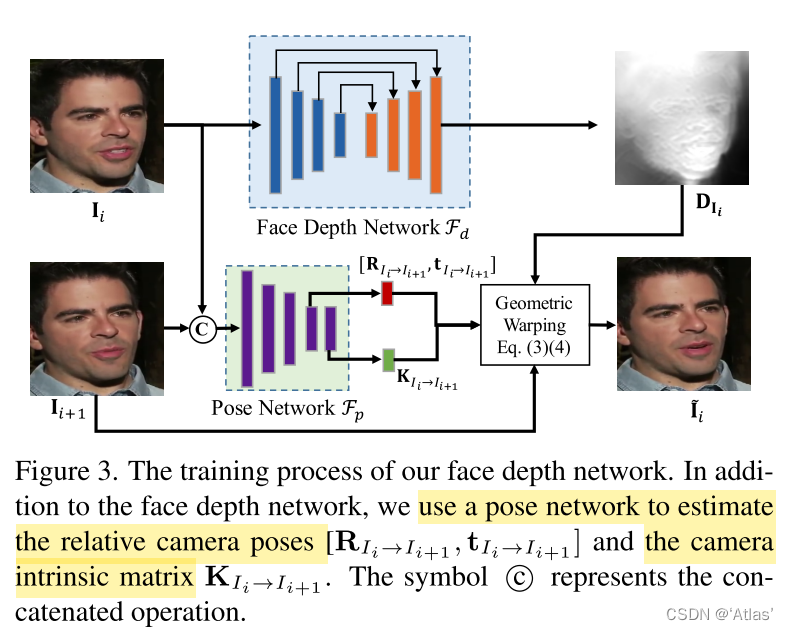
Self supervision Face Depth Learning
Author's reference SfM-Learner, Make optimization , Use consecutive frames I i + 1 I_{i+1} Ii+1 As the source diagram and I i I_i Ii As a target diagram , Learn set elements , Depth map D I i D_{I_i} DIi, Similar internal parameter matrix K I i − > I i + 1 K_{ {I_i}->I_{i+1}} KIi−>Ii+1, Related camera attitude R I i − > I i + 1 R_{ {I_i}->I_{i+1}} RIi−>Ii+1 And transformation t I i − > I i + 1 t_{ {I_i}->I_{i+1}} tIi−>Ii+1, And SfM-Learner The difference is the camera internal parameters K Need to learn ;
Flow chart 3:
1、 F d F_d Fd Extract the target graph I i I_i Ii Depth map of D I i D_{I_i} DIi;
2、 F p F_p Fp Extract learnable parameters R 、 t 、 K R、t、K R、t、K;
3、 According to the equation 3、4 Add source map I i + 1 I_{i+1} Ii+1 Get by geometric transformation I i ′ I'_i Ii′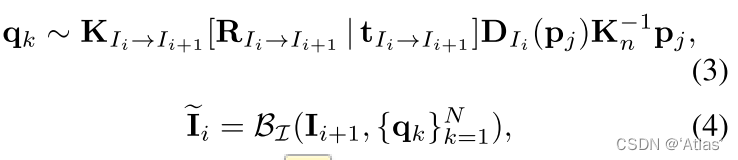
q k q_k qk Represents the source map I i + 1 I_{i+1} Ii+1 Distorted pixels on ;
p j p_j pj Represents the target graph I i I_i Ii Previous pixel ;
Loss function P e P_e Pe Such as the type 5 Shown , Use L1 Loss and SSIM Loss 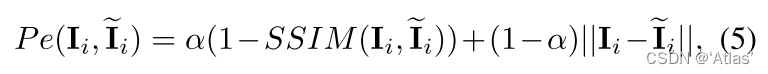
Sparse key motion modeling
1、 take RGB And F d F_d Fd Extract the depth map for concat;
2、 Through the key point estimation module F k p F_{kp} Fkp Get face sparse keys , Such as the type 6, Due to the introduction of depth map , Make the prediction key points more accurate ;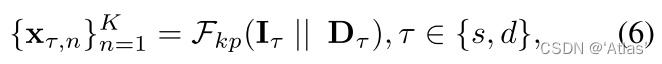
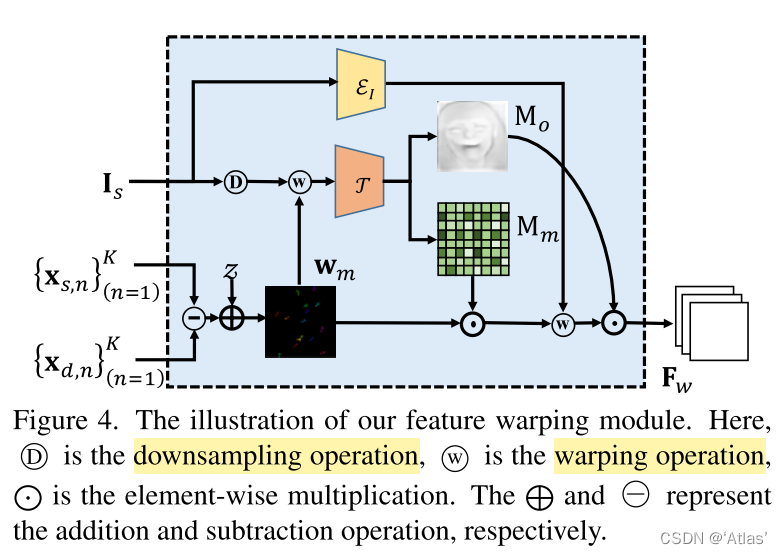
Feature distortion strategy , Pictured 4
1、 Such as the type 7, Calculate the initial offset between the original graph and the driving graph O n {O_n} On;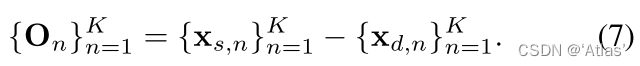
2、 Generate 2D coordinate map z;
3、 take O be applied to z, Get the motion area w m w_m wm;
4、 Use w m w_m wm Distort the downsampled image to get the initial distorted feature image ;
5、 Occlusion estimator τ \tau τ Predict the motion flow through the distorted characteristic graph mask M m M_m Mm And occlusion diagram M o M_o Mo;
6、 Use M m M_m Mm Distortion I s I_s Is Through the encoder ϵ I \epsilon_I ϵI Obtained appearance feature diagram , With the M o M_o Mo Fusion generation F w F_w Fw, Such as the type 8. F w F_w Fw It not only retains the original image information, but also extracts the motion information between two faces .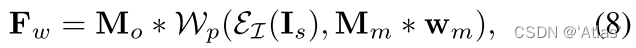
Cross modal attention Mechanism
In order to effectively use the learned depth map to improve the generation ability , The author proposes cross modal attention Mechanism , Pictured 5.
1、 Through the depth encoder ϵ d \epsilon_d ϵd Extract depth map D s z D_{sz} Dsz Characteristics of figure F d F_d Fd;
2、 Through three separate 1X1 The convolution layer will F d F_d Fd、 F w F_w Fw It maps to 3 Hidden feature layer F q F_q Fq、 F k F_k Fk、 F v F_v Fv;
3、 Such as the type 9, adopt attention Generate F g F_g Fg.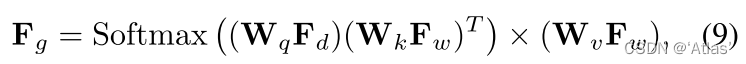
4、 Refined by decoder F g F_g Fg Generate the final image I g I_g Ig.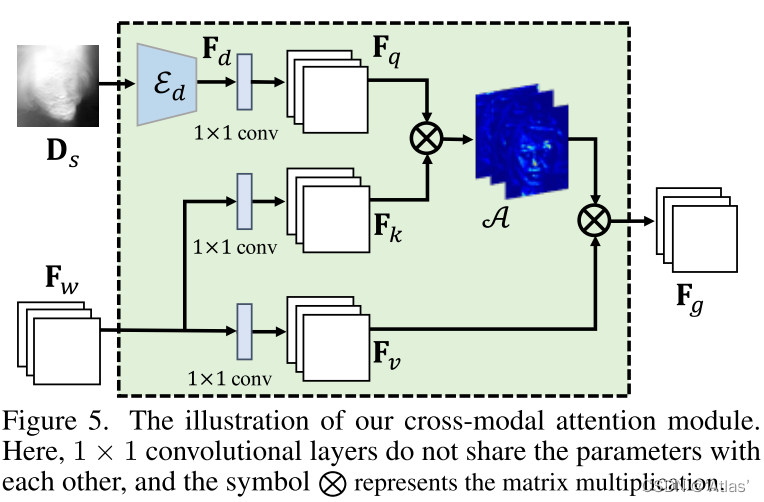
Training
During the training process, the original diagram and the driving diagram are the same , The loss function is as follows 10,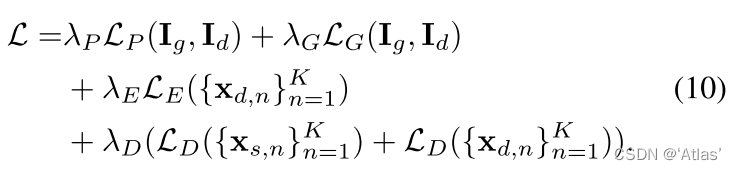
L P L_P LP For perceived loss ;
L G L_G LG Use the lowest double loss ;
L E L_E LE Equivariant loss , Ensure that the original image is transformed , The key points are transformed accordingly ;
L D L_D LD Loss through distance , Prevent facial keys from gathering ;
experiment
SOTA Methods to compare
stay VoxCeleb1 Data set with SOTA The comparison test results are shown in table 1、2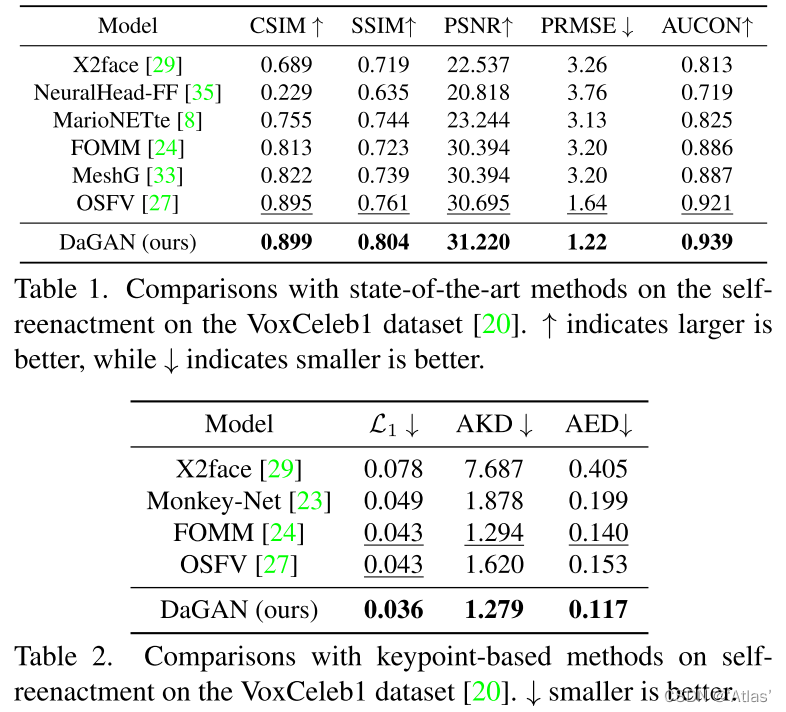
stay VoxCeleb1 On dataset , The effect of cross identity reproduction is shown in the figure 6
stay CelebV On dataset , And SOTA Method comparison test is shown in table 3, The effect of cross identity reproduction is shown in the figure 7
Ablation Experiment
FDN: Facial depth network ;
CAM: Cross modal attention Mechanism
Results such as table 4,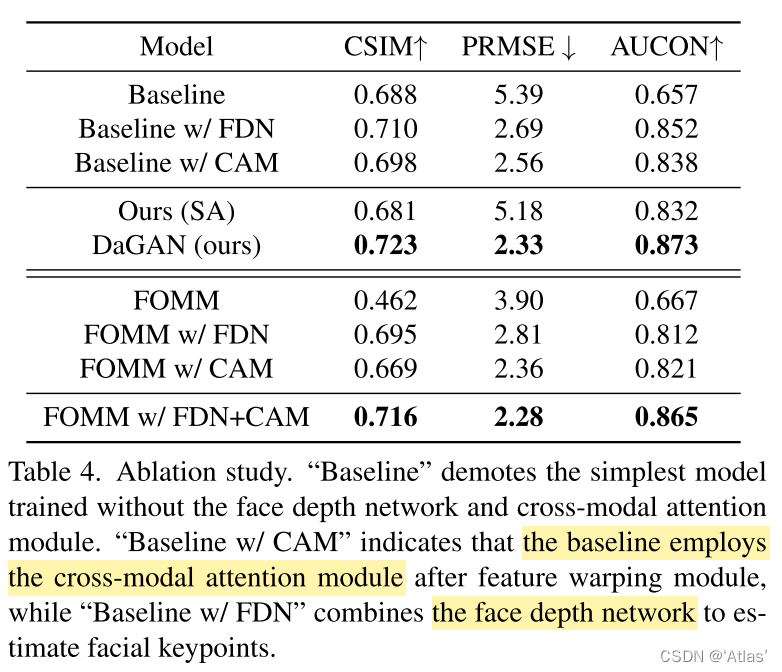
The generation effect is shown in the figure 8

DaGAN Effect video
Conclusion
DaGAN Use self-monitoring method to learn facial depth map , On the one hand, it is used for more accurate facial key point estimation ; On the other hand, design cross modal ( Depth map and RGB) Mechanism to obtain micro expression changes . therefore DaGAN Produce more realistic and natural results .
边栏推荐
- Carte de réflexion + code source + notes + projet, saut d'octets + jd + 360 + tri des questions d'entrevue Netease
- JDBC详解
- DaGAN论文解读
- 【翻译】云原生观察能力微调查。普罗米修斯引领潮流,但要了解系统的健康状况仍有障碍...
- Solution of intelligent management platform for suppliers in hardware and electromechanical industry: optimize supply chain management and drive enterprise performance growth
- [玩转Linux] [Docker] MySQL安装和配置
- How to access localhost:8000 by mobile phone
- Pytorch common loss function
- 终于可以一行代码也不用改了!ShardingSphere 原生驱动问世
- Characteristic colleges and universities, jointly build Netease Industrial College
猜你喜欢

Mysql Information Schema 学习(二)--Innodb表
DaGAN论文解读

数学知识——高斯消元(初等行变换解方程组)代码实现

Solution of intelligent management platform for suppliers in hardware and electromechanical industry: optimize supply chain management and drive enterprise performance growth
深入分析,Android面试真题解析火爆全网
![[translation] linkerd's adoption rate in Europe and North America exceeded istio, with an increase of 118% in 2021.](/img/09/106adc222c06cbd2f4f66cf475cce2.jpg)
[translation] linkerd's adoption rate in Europe and North America exceeded istio, with an increase of 118% in 2021.

Dark horse -- redis
Interface test tool - postman
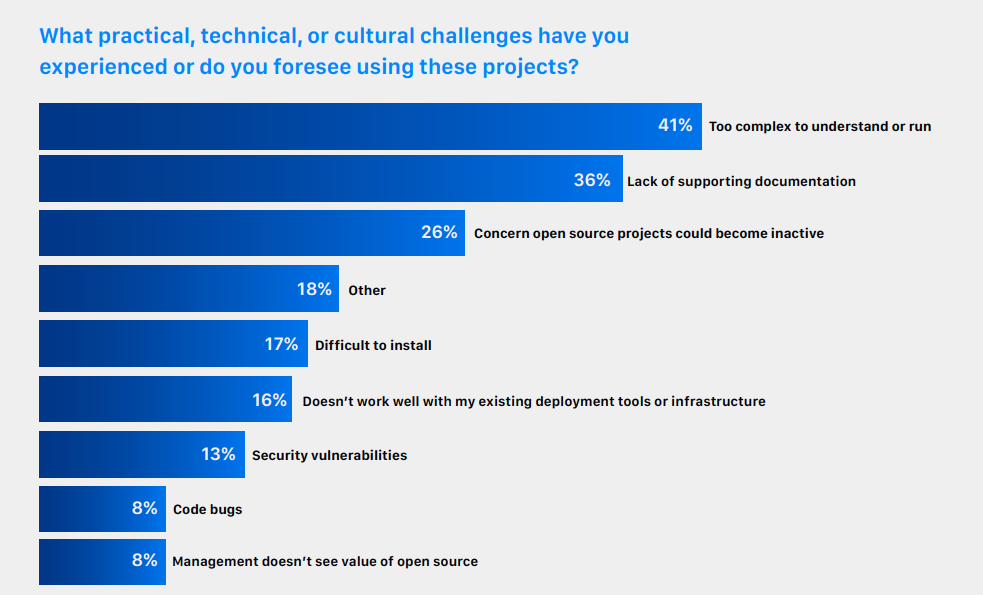
【翻译】云原生观察能力微调查。普罗米修斯引领潮流,但要了解系统的健康状况仍有障碍...
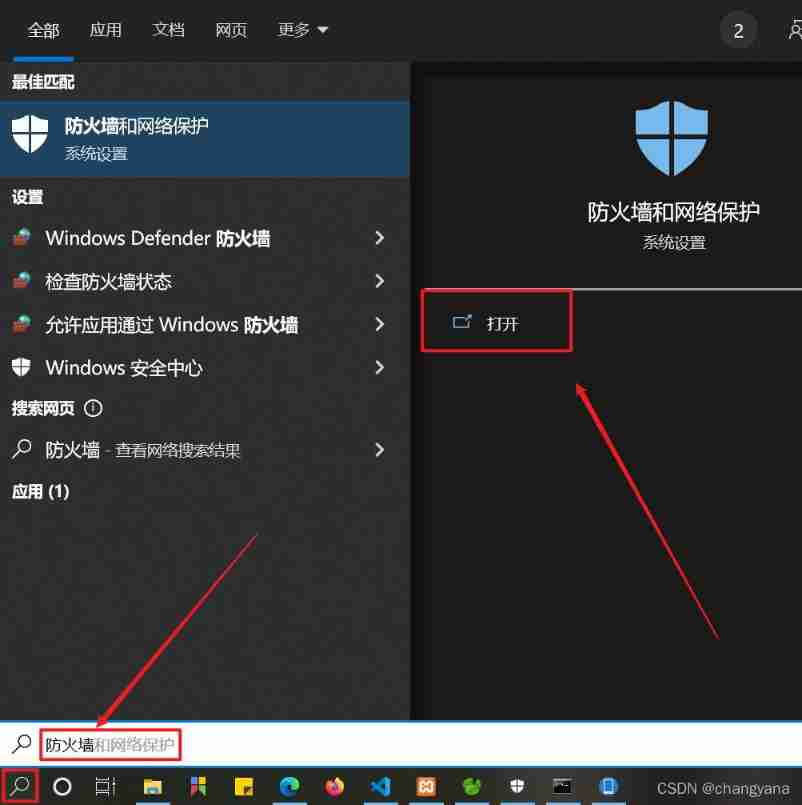
How to access localhost:8000 by mobile phone

随机推荐
【翻译】数字内幕。KubeCon + CloudNativeCon在2022年欧洲的选择过程
An error occurs when installing MySQL: could not create or access the registry key needed for the
C # - realize serialization with Marshall class
Using clip path to draw irregular graphics
How to customize animation avatars? These six free online cartoon avatar generators are exciting at a glance!
Zero foundation entry polardb-x: build a highly available system and link the big data screen
[translation] micro survey of cloud native observation ability. Prometheus leads the trend, but there are still obstacles to understanding the health of the system
【翻译】Linkerd在欧洲和北美的采用率超过了Istio,2021年增长118%。
Meilu biological IPO was terminated: the annual revenue was 385million, and Chen Lin was the actual controller
深入分析,Android面试真题解析火爆全网
Leetcode 30. 串联所有单词的子串
打家劫舍III[后序遍历与回溯+动态规划]
A popular explanation will help you get started
通俗的讲解,带你入门协程
Php+redis realizes the function of canceling orders over time
Use of deg2rad and rad2deg functions in MATLAB
[translation] supply chain security project in toto moved to CNCF incubator
Interface test tool - postman
It's super detailed in history. It's too late for you to read this information if you want to find a job
Tensorflow2.0 self defined training method to solve function coefficients