当前位置:网站首页>[text data mining] Chinese named entity recognition: HMM model +bilstm_ CRF model (pytoch) [research and experimental analysis]
[text data mining] Chinese named entity recognition: HMM model +bilstm_ CRF model (pytoch) [research and experimental analysis]
2022-06-24 22:57:00 【vector<& gt;】
1️⃣ This post is 【 Text data mining 】 Big homework - Chinese Named Entity Recognition - Investigation and experimental analysis
2️⃣ In the previous natural language course, I also completed an experiment of named entity recognition 【 Let's get started NLP】 Chinese Academy of Sciences naturallanguageprocessing assignment 3 : use BiLSTM+CRF Realize Chinese named entity recognition (TensorFlow introduction )【 Code + The report 】, Used at that time TensorFlow Implemented a method , In this experiment, I learned Pytorch Realization HMM Models and BiLSTM+CRF Model .
Catalog
One 、 Task description
Named entity recognition (Named Entity Recognition,NER) It's natural language processing (Natural Language Processing,NLP) Domain subtasks , Usually interpreted as from an unstructured text , Identify those named entities (Named Entity Recognition, NER) It refers to the recognition of text fragments belonging to predefined categories from free text . Classes are known through the laws of historical practice 、 Recognize a well-known or defined entity , At the same time, it also represents the ability to discover new named entities in a wide range of texts according to the composition laws of existing entities . Entity is a semantic unit with rich meaning in text , The process of identifying entities is divided into two stages , First, determine the boundary range of the entity , Then assign the entity to its type .
such as :“ACM announce , Three creators of deep learning Yoshua Bengio, Yann LeCun, as well as Geoffrey Hinton To obtain the 2019 Turing Award in ”. that NER My task is to extract from this sentence
- Organization name :ACM
- The person's name :Yoshua Bengio, Yann LeCun,Geoffrey Hinton
- Time :2019 year
- Proper noun : Turing Award
NER The task was first organized by the 6th semantic understanding conference (Message Understanding Conference) Put forward , At that time, only some common entity categories were defined , Such as location 、 Institutions 、 Characters, etc . At present, the task of named entity recognition has gone deep into various vertical fields , Such as medical treatment 、 Financial etc. .
Two 、 chinese NER Method
1. A pattern matching method based on dictionary and rules
Pattern matching method was first used , Also known as NER Expert system approach (Expert System,ES).ES It is required to include the highest level of professional knowledge , Extract expert knowledge and transform it into rules . The pattern matching method based on dictionaries and rules requires domain experts to construct a large number of rule templates from grammar rules , accord with ES Definition of knowledge acquisition .
Pattern matching method has high accuracy , However, many entity recognition rules depend on domain experts , There is basically no reuse between domains . Besides , The domain dictionary should be maintained regularly , The emerging new entities and the irregularity of entities make it difficult to construct a complete dictionary . Even if there are shortcomings , The pattern matching method is still applied , Because the rules of some domain entities can be exhausted 95% above , Rules are still the first choice to extract some entities from the judicial documents , At the same time, in the later machine learning 、 Deep learning NER Adding rules and dictionaries to the model can improve the accuracy .
2. Based on statistical machine learning method
The age of statistical machine learning ,NER The development of is based on large-scale annotated corpus ( Supervisory data set ) Appearance , From compiling a comprehensive and inflexible rule system to expecting machines to automatically recognize language rules through large-scale corpus training . The linguistic knowledge in the corpus is reflected in the use of feature templates to explain the characteristics of entity context , Make the machine understand the meaning of the components around the entity , This is called feature extraction , The purpose is to improve the accuracy of the statistical model .
The method based on statistical machine learning is from the given 、 Start with the marked training set , By manually constructing features , And label each word in the text according to a specific model , Implement named entity recognition .
In the named entity recognition method based on machine learning , The marked words usually use IOBES Dimension sets represent , That is, each word can be used 5 Class label for classification annotation . Therefore, the method based on machine learning is also called sequence annotation method .
Typical entity recognition technology based on statistical machine learning :
- hidden Markov model (Hidden Markov Model,HMM)
- Maximum Entropy Markov model (Maximum Entropy Markov Model,MEMM)
- Support vector machine (Support Vector Machine,SVM) Model
- Conditional random field (Conditional Random Fields,CRF) Model
Named entity recognition model based on statistical machine learning algorithm has high requirements for feature selection , And it needs a rich corpus . It is applicable to fields with strong professionalism , It can improve the accuracy of word segmentation to a certain extent .
however , Statistical machine learning NER Limited by high-quality large-scale annotated corpus and rich 、 The need for feature templates that are not afraid of the challenges of corpus changes , The cost of building feature templates is huge, but the accuracy will be improved accordingly , So in the follow-up NER Developing , The retention of feature engineering can also help entity recognition .
3. Methods based on deep learning
Deep learning provides a solution to replace complex and huge feature engineering , Let the machine automatically find out the potential feature template set .PLM The dynamic training word vector makes the text get a better vectorized representation , Then we use the feature extractor to extract text features , Then the predicted sequence tag is obtained by the decoder , As follows :
- Input text based on static word vector or dynamic PLM To quantify (Input Representation,IR), Specifically, it is divided into word based (character) Or words (word) The way , Or combine the two ways of information (hybrid) To quantify .IR Phases need to be effectively integrated
Word and word information , It can also be used as an aid to feature engineering using statistical machine learning methods . - Text encoding layer (Context Encoder,CE) Or sequence modeling layer , about IR The vectorized text output in the phase is further extracted by the feature extractor .
- Tag decoding layer (Tag Decoder,TD), take CE The best sequence label is obtained by the vector input decoding network of layer output .
In the method of deep learning ,Word2vec-BILSTM-CRF The combination made the English NER The best effect , Then it was applied to Chinese NER in , The era of deep learning BERT-BILSTM-CRF The combination of
It has also become a reference for performance improvement . The accuracy of table depth learning is high , However, it still needs large-scale annotation data sets and high resource computing power ,PLM The application of is a burden to the training of small models .
3、 ... and 、 Experimental instructions
1. Experimental environment
- Windows os
- python 3.6.2
- torch 1.2.0+cpu
2. Running steps
python3 main.py: Training and evaluation models , Will print out the accuracy of the model 、 Recall rate 、F1 Fractional value and confusion matrix .
python3 test.py: After training, load the model for evaluation
3. Directory description
│ data.py: Data processing and loading scripts
│ evaluate.py: Validation script
│ evaluating.py: Used to evaluate the model , Calculate the accuracy of each label , Recall rate ,F1 fraction
│ main.py: The main function
│ output.txt: Save model test results
│ test.py: The test script
│ utils.py
│
├─ckpts: Save the model after the training
│ bilstm_crf.pkl
│ hmm.pkl
│
├─models: Specific model implementation
│ bilstm_crf.py
│ config.py: Model parameters and training parameters
│ crf.py
│ hmm.py
│ util.py: Tool function
│
├─ResumeNER: test / verification / training corpus
│ dev.char.bmes
│ test.char.bmes
│ train.char.bmes
Four 、 experimental data
The data set used in this experiment is ACL 2018Chinese NER using Lattice LSTM Resume data collected from sina finance , The format of the data is as follows , Each line of it consists of a word and its corresponding annotation , Dimension sets use BIOES(B Indicates the beginning of an entity ,E Indicates the end of the entity ,I Represents inside an entity ,O Represents a non entity ), Separate sentences with a blank line .
Dong B-TITLE
things M-TITLE
Meeting M-TITLE
Secret M-TITLE
book E-TITLE
、 O
vice B-TITLE
total M-TITLE
the M-TITLE
The reason is E-TITLE
. O
Zhang B-NAME
Wild goose M-NAME
ice E-NAME
5、 ... and 、 Model overview
Model one :HMM
HMM summary
Hidden Markov model describes the random generation of unobservable state random sequences by a hidden Markov chain , The process of generating an observation from each state and generating a random sequence of observations . Hidden Markov model consists of A,B,π Sole determination ,A,B,π Three elements called hidden Markov model .
Hidden Markov studies the problem of the interaction between the changing laws of two things , In this case , Changes in the weather can affect the state of algae ( When the weather is fine, the seaweed becomes dry ).
- Sequence of States Q: Indicates the background nature of the decision ( a sunny day , rain …)
- Watch the sequence O: Represents the observed foreground appearance ( Damp , dry …)
- π : Represents the initial state , That is, the starting value of the state sequence
- transition matrix A: Describe the probability of state change before and after . such as , The present moment is rain , The probability that the next moment is a cloud is 0.3, The present moment is the cloud , The probability that the next moment will be sunny is 0.8
- Observation probability matrix B: Describe the probability of deriving a representation from a state at the same time . such as , At present, the probability of seaweed drying is 0.6, The probability of seaweed drying on cloudy days is 0.25.
The above five tuples constitute HMM Basic structure . Besides , Hidden Markov model has two assumptions
- The observed variables only depend on the state variables at the current time .( The green arrow )
- The current state only depends on the state of the previous moment .( The red arrow )

NER In essence, it can be regarded as a sequence annotation problem ( Predict... For each word BIOES Mark ), In the use of HMM solve NER This kind of sequence labeling problem , What we can observe is a sequence of words ( Observation sequence ), What is not observed is the annotation corresponding to each word ( Sequence of States ).
Corresponding ,HMM The three elements of can be explained as , The initial state distribution is the probability of each annotation as the first word of a sentence , The state transition probability matrix is the probability of transition from one annotation to the next , The observation probability matrix means that under a certain label , The probability of generating a word . according to HMM The three elements of , We can define the following HMM Model :
"""Args: N: Number of States , Here corresponds to the type of existing annotation M: The number of observations , How many different words are there """
self.N = N
self.M = M
# State transition probability matrix A[i][j] From i The state shifts to j The probability of States
self.A = torch.zeros(N, N)
# Observation probability matrix , B[i][j] Express i Generate in state j Probability of observation
self.B = torch.zeros(N, M)
# Initial state probability Pi[i] Indicates that the initial time is state i Probability
self.Pi = torch.zeros(N)
HMM Training
HMM The training process of the model corresponds to the learning problem of hidden Markov model , In fact, it estimates the three elements of the model according to the maximum likelihood method , That is, the initial state distribution mentioned above 、 State transition probability matrix and observation probability matrix . When estimating the initial state distribution , Suppose a tag is used as the tag of the first word of a sentence in the data set for k, The total number of sentences is N, Then the probability of the mark as the first word of the sentence can be approximately estimated as k/N, Using this method , Approximate estimate HMM The three elements of .
After model training , Use the trained model to decode , Sentences not seen in a given model , Find the corresponding annotation of each word in the sentence , For this decoding problem , The method used is Viterbi (viterbi) Algorithm .
viterbi algorithm
Viterbi search algorithm : Dynamic programming is used to reduce the computational complexity 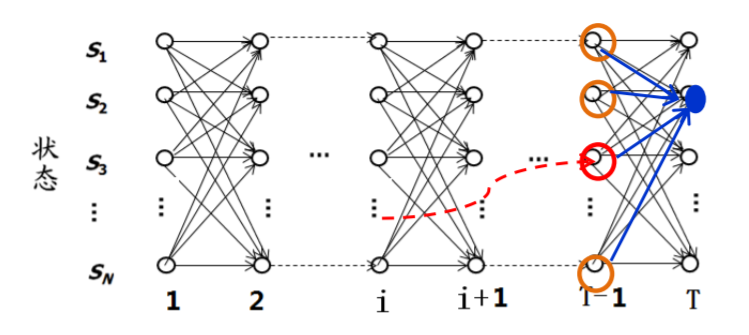
- If the probability maximum path ( Or the shortest path ) the i At some point in time , We can definitely find S The shortest path to the point ( Can be i The shortest path record at the time point )
- from S To E Your path must pass through i At some point in time
- When from state i Enter into i+1 State calculation S To i+1 In the state of , Only consider i State the shortest paths of all nodes and their paths to i+1 The distance between States is enough .
Model two :BiLSTM_CRF
The structure of the model is shown in the figure below , The most important thing in the input layer is look-up Layer processing results in word embedding ; The intermediate neural network layer is a two-way network LSTM, The output passes through a softmax; Finally, in the transition matrix A Under the limitation of , adopt CRF Layers get prediction labels 
LSTM And BiLSTM
LSTM Used to solve common problems RNN Long distance dependence of the model : The farther away the node is from the current node, the smaller the impact on the current node processing , Cannot model long-term dependencies .
RNN It consists of many cyclic units , In standard RNN in , This repeating unit has only one very simple structure , For example, a tahn layer .
LSTM It is also a circular structure , It's just that this repeating unit is beginning to get complicated .
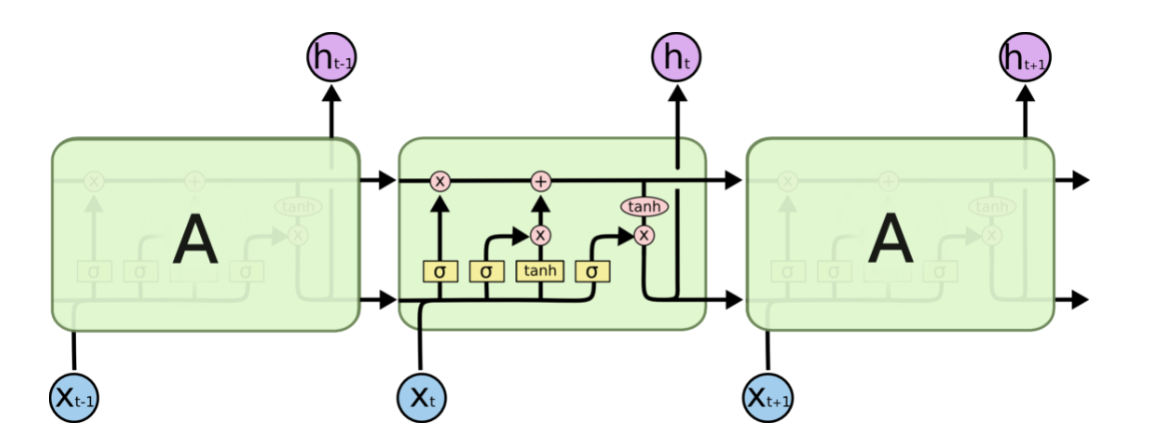
In the illustration above , Every black line carries a whole vector , Output from one node to input to other nodes . Pink circle represents pointwise The operation of , Like the sum of vectors , And the Yellow matrix is the learned neural network layer . The lines together represent the connection of vectors , Separate lines indicate that the content is copied , And distribute it to different locations .

LSTM The key is cell state , The horizontal line runs through the top of the graph . Cell state is like a conveyor belt . Run directly across the chain , There are only a few linear interactions . It's easy to keep the message going on .

LSTM There is something called... Through careful design “ door ” The ability to remove or add information to the cellular state . A door is a way to let information go through selectively . They include One sigmoid Neural network layer and a pointwise Multiplication operation . The following figure shows a door structure :
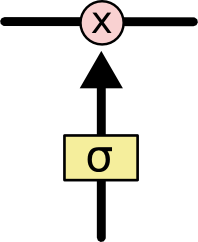
Sigmoid Layer output 0 To 1 Value between , Describe how much of each part can pass through .0 representative “ No amount is allowed to pass through ”,1 It means “ Allow any amount to pass through ”.LSTM With three doors , To protect and control cell state .
Oblivion gate : Decide what information to discard from the cellular state .

Input gate : Decide what new information will be stored in the cell state

Output gate : Decide what value to output

LSTM Can only predict the output of the next time according to the timing information of the previous time , But in some cases , The output of the current moment is not only related to the previous state , It may also have something to do with the state of the future . For example, predicting the missing words in a sentence not only needs to be judged according to the previous text , You also need to consider the content behind it , Really based on context judgment .
So-called Bi-LSTM It can be seen as Two layer neural network , The first layer is the starting input of the series from the left , In text processing, it can be understood as input from the beginning of a sentence , The second layer is the starting input of the series from the right , In text processing, it can be understood as input from the last word of a sentence , Do the same processing as the first layer . Finally, the two results are processed .
Conditional random field CRF
Use only BiLSTM and softmax There will be some problems with the model . If conditional random fields are not used , after softmax after , Will select a tag output with the greatest probability , The largest one in the first column is 0.14, So it corresponds to “ in ” The label of should be B-Location(B representative Begin), Represents the beginning of place names ; The largest probability in the second column is 0.31, The corresponding label is still B-Location, Obviously , Two words next to each other cannot be the beginning of a place name , So how to solve this problem ? This is the job of conditional random fields 
The reason why there are two consecutive B, Because there are no constraints between outputs , The model should be told , If the previous word is Begin, The label of the last word cannot be Begin. that CRF How do you accomplish this limitation ? It is achieved by specifying the probability of the output sequence through a transition matrix .
In this matrix , The first row and the first column represent that the previous word is B-Location, The last word is B-Location Probability , According to the above description , This probability should be very small , Even 0. So joined CRF The model structure should be as shown in the following figure :
6、 ... and 、 Model to evaluate
- TP: Predict a positive class as a positive class number ;
- FN: Predict positive class as negative class number ;
- FP: The negative class is predicted to be a positive class number ;
- TN: The negative class is predicted to be the number of negative classes ;
The evaluation index :
- F1 value :𝐅𝟏 = 𝟐𝐓𝐏/(𝟐𝐓𝐏 + 𝐅𝐏 + 𝐅𝐍)
- Recall rate :𝐑 = 𝐓𝐏/(𝐓𝐏 + 𝐅𝐍)
- Accuracy rate :𝐀𝐜𝐜 = (𝐓𝐏 + 𝐓𝐍)/(𝐓𝐏 + 𝐅𝐍 + 𝐅𝐏 + 𝐓𝐍)
HMM
precision recall f1-score
B-RACE 1.0000 0.9286 0.9630
E-LOC 0.5000 0.5000 0.5000
E-NAME 0.9000 0.8036 0.8491
E-TITLE 0.9514 0.9637 0.9575
B-LOC 0.3333 0.3333 0.3333
M-TITLE 0.9038 0.8751 0.8892
M-NAME 0.9459 0.8537 0.8974
B-CONT 0.9655 1.0000 0.9825
M-EDU 0.9348 0.9609 0.9477
B-NAME 0.9800 0.8750 0.9245
E-PRO 0.6512 0.8485 0.7368
M-ORG 0.9002 0.9327 0.9162
E-RACE 1.0000 0.9286 0.9630
E-CONT 0.9655 1.0000 0.9825
B-EDU 0.9000 0.9643 0.9310
M-PRO 0.4490 0.6471 0.5301
B-ORG 0.8422 0.8879 0.8644
E-ORG 0.8262 0.8680 0.8466
B-PRO 0.5581 0.7273 0.6316
M-LOC 0.5833 0.3333 0.4242
O 0.9568 0.9177 0.9369
M-CONT 0.9815 1.0000 0.9907
B-TITLE 0.8811 0.8925 0.8867
E-EDU 0.9167 0.9821 0.9483
avg/total 0.9149 0.9122 0.9130
BiLSTM_CRF
precision recall f1-score
B-RACE 1.0000 0.9286 0.9630
E-LOC 1.0000 0.8333 0.9091
E-NAME 0.9904 0.9196 0.9537
E-TITLE 0.9819 0.9819 0.9819
B-LOC 1.0000 1.0000 1.0000
M-TITLE 0.9439 0.8933 0.9179
M-NAME 0.9277 0.9390 0.9333
B-CONT 1.0000 1.0000 1.0000
M-EDU 0.9598 0.9330 0.9462
B-NAME 1.0000 0.8929 0.9434
E-PRO 0.9091 0.9091 0.9091
M-ORG 0.9680 0.9593 0.9637
E-RACE 1.0000 1.0000 1.0000
E-CONT 1.0000 1.0000 1.0000
B-EDU 0.9561 0.9732 0.9646
M-PRO 0.7927 0.9559 0.8667
B-ORG 0.9658 0.9693 0.9675
E-ORG 0.9276 0.9042 0.9158
B-PRO 0.8788 0.8788 0.8788
M-LOC 1.0000 1.0000 1.0000
O 0.9558 0.9873 0.9713
M-CONT 1.0000 1.0000 1.0000
B-TITLE 0.9434 0.9288 0.9360
E-EDU 0.9820 0.9732 0.9776
avg/total 0.9580 0.9575 0.9575
Reference resources :NLP actual combat - Chinese Named Entity Recognition Need to put data.py In the document word, tag = line.strip(‘\n’).split() Change it to word, tag = line.strip(‘\r\n’).split()
边栏推荐
- EPICS record Reference 3 - - field available for all Records
- Combine pod identity in aks and secret in CSI driver mount key vault
- Memory alignment of structures
- Web security XSS foundation 06
- Row and column differences in matrix construction of DX HLSL and GL glsl
- Analyze the implementation process of oauth2 distributed authentication and authorization based on the source code
- Leetcode algorithm refers to offer II 027 Palindrome linked list
- vulnhub DC: 2
- 环境配置 | VS2017配置OpenMesh源码和环境
- Certificate photo processing
猜你喜欢

Chapter 10 project communication management
Spark 离线开发框架设计与实现
See how sparksql supports enterprise level data warehouse

Win10 or win11 printer cannot print
![[untitled]](/img/ed/847e678e5a652da74d04722bbd99ff.jpg)
[untitled]

Nuscenes -- remedies for missing image files or 0-size images encountered during dataset configuration

ACL (access control list) basic chapter - Super interesting learning network

【Mongodb】READ_ ME_ TO_ RECOVER_ YOUR_ Data, the database is deleted maliciously

【ROS玩转Turtlesim小海龟】
![[postgraduate entrance examination English] prepare for 2023, learn list8 words](/img/25/d1f2c2b4c0958d381db87e5ef96df9.jpg)
[postgraduate entrance examination English] prepare for 2023, learn list8 words

随机推荐
倍加福(P+F)R2000修改雷达IP
EPICS记录参考4--所有输入记录都有的字段和所有输出记录都有的字段
Analyze the implementation process of oauth2 distributed authentication and authorization based on the source code
Unable to use the bean introduced into the jar package
It's hard to hear C language? Why don't you take a look at my article (7) input and output
Based on the codeless platform, users deeply participated in the construction, and digital data + Nanjing Fiberglass Institute jointly built a national smart laboratory solution
Talk about GC mechanism often asked in interview
See how sparksql supports enterprise level data warehouse
双亲委派机制
Research and investment strategy report on China's bridge anticorrosive coating industry (2022 Edition)
C language operators and expressions
[postgraduate entrance examination English] prepare for 2023, learn list9 words
关于某手滑块的一些更新(6-18,js逆向)
Market trend report, technical innovation and market forecast of solar roof system in China
Learn more about the practical application of sentinel
Solution to the login error of tangdou people
Basic principles of spanning tree protocol
Database transaction Transanction
别再乱用了,这才是 @Validated 和 @Valid 的真正区别!!!
Principles of Ethernet port mirroring, link aggregation and VLAN Technology