当前位置:网站首页>LAB 信号量实现细节
LAB 信号量实现细节
2022-08-05 04:48:00 【别吓本抱抱】
信号量的实现与应用
实验内容
在Ubuntu下编写程序,用信号量解决生产者-消费者问题
在Ubuntu下编写应用程序pc.c,解决经典的生产者-消费者问题,完成下面的功能:- 建立一个生产者进程,N个消费者进程(N > 1)
- 用文件建立一个共享缓冲区
- 生产者进程依次向缓冲区写入整数0,1,2,…,M, M >= 500
- 消费者进程从缓冲区读数,每次读一个,并将读出的数字从缓冲区删除,然后将本进程ID+数字输出到标准输出
- 缓冲区同时最多只能保存10个数
pc.c中将会用到sem_open(),sem_unlink(),sem_wait(),sem_post()等信号量相关的系统调用,请查阅相关文档。
在0.11中实现信号量,用生产者-消费者程序检验之
Linux在0.11版还没有实现信号量,Linus把这件富有挑战的工作留给了你。如果能够实现一套山寨版的完全符合POSIX规范的信号量,无疑是很有成就感的。但时间暂时不允许我们这么做,所以先弄一套缩水版的类POSIX信号量,它的原型和标准并不完全相同,而且只包含如下系统调用:sem_t *sem_open(const char *name, unsigned int value); int sem_wait(sem_t *sem); int sem_post(sem_t *sem); int sem_unlink(const char *name);sem_t是信号量类型,根据实现的需要自定义sem_open
功能是创建一个信号量,或打开一个已经存在的信号量。name是信号量的名字。不同的进程可以通过提供同样的name而共享同一个信号量。如果该信号量不存在,就创建新的名为name的信号量;如果存在,就打开已经存在的名为name的信号量。value是信号量的初值,仅当新建信号量时,此参数才有效,其余情况下它被忽略。
当成功时,返回值是该信号量的唯一标识(比如,在内核的地址,ID等),由另外两个系统调用使用。如失败,返回值是NULL。sem_wait
信号量的P原子操作。如果继续运行的条件不满足,则令调用进程等待在信号量sem上。
返回0表示成功,返回-1表示失败。sem_post
信号量的V原子操作。如果有等待sem的进程,它会唤醒其中的一个。返回0表示成功,返回-1表示失败。sem_unlink
功能是删除名为name的信号量。返回0表示成功,返回-1表示失败。
在kernel目录下新建sem.c文件实现如下功能。然后将pc.c从Ubuntu移植到0.11下,测试自己实现的信号量。
实验报告
- 在
pc.c中去掉所有与信号量有关的代码,再运行程序,执行效果有变化吗?为什么会这样? - 实验的设计者在第一次编写生产者-消费者程序的时候,是这么做的:
这样可行吗?如果可行,那么它和标准解法在执行效果上会有什么不同?如果不可行,那么它有什么问题使它不可行?Producer() { P(Mutex); //互斥信号量 生产一个产品item; P(Empty); //空闲缓存资源 将item放到空闲缓存中; V(Full); //产品资源 V(Mutex); } Consumer() { P(Mutex); P(Full); 从缓存区取出一个赋值给item; V(Empty); 消费产品item; V(Mutex); }
- 在
实验过程
实验分析
1. 从生产者-消费者问题看进程同步
1.1 信号量实现进程同步
生产者负责往缓冲区写入数据,消费者从缓冲区取走生产者写入的数据,缓冲区就是这个过程的共享资源。如果生产者还不曾向缓冲区写入数据,消费者就从缓冲区读取;或者生产者数据写入还未完成,消费者就读取。这两种情况消费者读取到的都是非法数据。如果缓冲区已满,生产者继续往其中写入数据,就会覆盖尚未被消费者读取的数据,造成数据丢失。就像多人参与的项目需要分工协调,多个进程对共享资源的使用也必须进行同步。进程同步就是让进程在必要的地方停下来,等待其他进程执行到满足一定的条件后,再继续执行,从而保证多个进程合理有序的推进。
就生产者-消费者问题,进程同步就是要保证:
对于生产者来说,当缓冲区满,也就是空闲缓冲区个数为0时,此时生产者不能继续向缓冲区写数,必须等待,直到有消费者从满缓冲区取走数后,再次有了空闲缓冲区,生产者才能向缓冲区写数。并且当缓冲区满时,先后有多个生产者均想往缓冲区写入,那么它们均需要等待,此时需要记录下等待的生产者的个数,以便缓冲区有空闲空间后,所有等待的生产者都会得到唤醒,确保请求写入的生产者最终都能写入到缓冲区。
对于消费者来说,当缓冲区空时,此时没有数可以被取走,消费者必须等待,直到有生产者向缓冲区写数后,消费者才能取数。并且如果当缓冲区空时,先后有多个消费者均想从缓冲区取数,那么它们均需要等待,此时需要记录下等待的消费者的个数,以便缓冲区有数可取后,所有等待的消费者都会得到唤醒,确保请求取数的消费者最终都能取到数。
也就是说,当多个进程需要协同合作时,需要根据某个信息,判断当前进程是否需要停下来等待;同时,其他进程需要根据这个信息判断是否有进程在等待,或者有几个进程在等待,以决定是否需要唤醒等待的进程。而这个信息,就是信号量。
信号量是一个计数器,用于为多个进程提供对共享数据对象的访问。为了获得共享资源,进程需要执行下列操作:
- 测试控制该资源的信号量。
- 若此信号量的值为正,则进程可以使用该资源。在这种情况下,进程会将信号量值减1,表示它使用了一个共享资源。
- 否则,若此信号量的值为0,则进程进入休眠状态,直至信号量值大于0。如果有进程正在休眠等待此信号量,则唤醒它们。
在实现信号量时,信号量可以取到负值,通过这个负值的大小,可以知道有几个进程正在休眠等待此信号量。比如下面的情况:
设有一整形变量sem,作为一个信号量。此时缓冲区为空,sem=0。
- 消费者C1请求从缓冲区取数,不能取到,睡眠等待。sem=-1<0,表示有一个进程因缺资源而等待。
- 消费者C2也请求从缓冲区取数,睡眠等待。sem=-2<0,表示有两个进程因缺资源而等待。
- 生产者P往缓冲区写入一个数,sem=sem+1=-1<=0,并唤醒等待队列的头进程C1,C1处于就绪态,C2仍处于睡眠等待。
- 生产者P继续往缓冲区写入一个数,sem=0<=0,并唤醒C2,C1、C2就处于就绪状态。
1.2 靠临界区保护信号量
1.2.1 竞争条件(Race Condition)
为了正确实现信号量,信号量值的测试及加减1操作应当是原子操作。原子操作不可分割,在执行时不会因为调度被打断,也就是说,原子操作的一系列指令要么一次执行完成,要么没有执行,不会出现执行一部分而被切换出去。如果信号量的操作不是原子的,就会发生问题。我们考虑以下代码:
x++; //x is an integer
该++操作符是个后增操作符,我们都知道它会执行什么操作:获取当前的x值,把x值加1,把加1后的新的值再保存到x中,该表达式的返回值即更新后的x值。该操作如何编译成机器码取决于架构,它看起来可能如下:
load x into reigster
add 1 to register
store register in x
假设有两个生产者同时对缓冲区可用资源数full进行full++操作,其中full = 5。以下是期望的输出:
| 时间 | 生产者1 | 生产者2 |
|---|---|---|
| 1 | 把full加载到寄存器(5) | |
| 2 | 寄存器值加1(6) | |
| 3 | 把寄存器值赋给full(6) | |
| 4 | 把full加载到寄存器(6) | |
| 5 | 寄存器加1(7) | |
| 6 | 把寄存器值赋给full(7) |
但是,我们无法避免下面的情况:
| 时间 | 生产者1 | 生产者2 |
|---|---|---|
| 1 | 把full加载到寄存器(5) | |
| 2 | 寄存器值加1(6) | |
| 3 | 把full加载到寄存器中(5) | |
| 4 | 把寄存器值赋给full(6) | |
| 5 | 寄存器加1(6) | |
| 6 | 把寄存器值赋给full(6) |
很多其他组合也会带来不期望的结果。full++就是竞争条件。竞争条件(race condition)是指:当多个进程都企图对共享数据进行某种处理,而最后的结果又取决于进程运行的顺序,我们认为发生了竞争条件。
共享资源可以是以下任意一种:系统硬件、内核资源或内存中的数据。后者是最常见的,称为数据竞争(data reace)。
竞争所发生的窗口——需要同步的代码区,称为临界区。竞争的最根本的源头在于临界区是个窗口,在这个窗口内,正确的程序行为要求多个进程不要交替执行。为了阻止竞争条件,需要在这个窗口内执行同步访问操作,确保多个进程对临界区以互斥的方式访问。也就是说要让临界区成为一个原子操作。
1.2.2 通过锁机制实现临界区的原子性访问
实现临界区原子性访问的技术有很多,最常见的技术是锁。我们定义锁,并确保在进入临界区之前获取该锁。锁的实现机制确保一次只能持有一个锁。如果有另一个进程使用锁,新的进程在继续之前必须等待。如果不在临界区,就释放锁,让等待进程(如果有的话)持有锁并继续执行。
锁的实现有几种方法:
- 软件方法
- 适用于两个进程的Peterson算法
- 适用于多个进程的面包店算法
- 硬件方法
- 适用于单CPU的开关中断方法
- 硬件原子指令法
在Linux 0.11上比较简单的方法就是通过开关中断来阻止时钟中断,从而避免时间片耗完引发的调度,来实现临界区的原子性访问。但是开关中断的方法,只适合单CPU的情况,对于多CPU的情况,不适用。Linux 0.11就是单CPU,可以使用这种方法。
2. 用信号量解决生产者-消费者问题
2.1 用文件作为一个共享缓冲区
由于进程之间的地址空间是隔离的,所以多个进程需要共享数据就需要使用文件或共享内存。这里使用文件作为生产者消费者共享数据的介质,在其中开辟出10个整数的空间作为共享缓冲区,从而实现数据共享。
2.2 多个消费者读数的文件偏移量同步及读取结束判断
多个消费者在以互斥方式读取缓冲区数据时,必须指定正确的文件偏移量。假设消费者1读取结束时的文件偏移量是12。消费者2紧随消费者1从缓冲区取数,它就需要知道消费者1上次读取结束的位置是12,并从文件偏移量13处继续读取下一个数字。所以上次消费者读取结束时的文件偏移量是多个消费者需要同步的共享数据。为此将文件起始位置开始的一个整数的空间存放上次消费者读取结束时文件偏移量的值。
并且生产者是从0开始依次往缓冲区写数的,而消费者是从0开始读取的,由于信号量的作用可以保证生产者写数的顺序是每次写满缓冲区后再从缓冲区开始处从头写。所以消费者读取到的数字和该数字在缓冲区的位置/文件偏移量有数学关系。生产者写入完最后一个数字后就退出了,多个消费者进程是跟随调度算法随机从缓冲区取数的,但只有一个消费者会读取到生产者写入的最后一个数字,该消费者读取到最后一个数字就知道读取已经完毕,自己也可以退出了。但剩余的消费者无法读取到最后一个数字,所以不能判断读取是否结束。
综上,可以用上次消费者读取结束时读到的数字替代读取结束时的文件偏移量。这样,两者之间的数学关系为:
上次读取结束时的文件偏移量 = (上次读取结束时读到的数字 % 缓冲区的长度 + 1(文件偏移量0的位置用于保存该读取到的数字) ) * sizeof(int)
同时,不能读取到最后一个数字的剩余消费者可以根据该数字判断读取是否完毕。
3. 信号量的实现
3.1 信号量的组成
- 需要有一个整形变量value,作为共享数据的计数器。
- 需要一个等待队列,在缺少共享资源时存放等待该资源的进程。
- 需要有一个名字在多个进程之间引用该信号量。
同时,系统需要支持多个信号量,可以考虑将这些信号量存放在一个数组中。这样,在新建信号量时要在数组中寻找空闲空间存放该信号量。在使用信号量的名字打开该信号量时,需要在数组中查找该信号量的名字。在删除该信号量时,需要删除该信号量的名字并将该信号量所占的数组位置标记为可用。
3.2 等待队列的构造
当前进程调用sem_wait()函数进行信号量的P操作时,如果缺乏资源就需要将当前进程阻塞在等待队列上;当调用sem_post()函数进行信号量的V操作时,如果有进程阻塞在等待队列,就唤醒队首进程。所以等待队列的构造有两种思路:一是自己创建等待队列,然后手动将需要阻塞的进程置为不可中断睡眠状态,将其放入等待队列。或将需要唤醒的队首进程出队,并将其由不可中断睡眠置为就绪状态;另外一种是利用Linux 0.11提供的sleep_on()函数实现进程的睡眠,用wake_up()函数唤醒进程,由于sleep_on()函数会利用睡眠进程内核栈中的tmp变量形成一个隐式的等待队列,所以无需我们在自己构造等待队列。
- 自己创建等待队列
下图表明利用数组Q[n]来实现一个最多容纳n-1个元素的队列的一种方式。该队列有一个属性Q.head指向队头元素,而属性Q.tail则指向下一个新元素将要插入的位置。队列中的元素存放在位置Q.head,Q.head+1,…,Q.tail-1,并在最后的位置“环绕”,感觉好像位置1紧邻在位置n后面形成一个环序。当Q.head == Q.tail时,队列为空。初始时有Q.head = Q.tail = 0。如果试图从空队列中删除一个元素,则队列发生下溢。当Q.head = Q.tail + 1时,队列是满的,此时若试图插入一个元素,则队列发生上溢。
在sem_wait()中需要阻塞当前进程时手动将current->state置为不可中断睡眠(TASK_UNINTERRUPTIBLE)。在sem_post()中如果等待队列非空,则将队头进程出队,并将其状态置为就绪(TASK_RUNNING)。
2. 利用sleep_on睡眠并形成等待队列,利用wake_up唤醒
关于sleep_on函数中隐式等待队列的形成可以参考之前的实验3:进程运行轨迹的跟踪与统计>实验过程>1. 进程状态的切换>4. 不可中断睡眠sleep_on 中的解释。
而wake_up函数只是负责显式唤醒队列头进程。唤醒队列头之后,由sleep_on将队列中的后续进程挨个唤醒。
1. sem_wait实现
考虑到sleep_on()会形成一个隐式的等待队列,而wake_up()只要唤醒了等待队列的头结点,就可以依靠sleep_on()内部的判断语句:c if (tmp) tmp->state = 0;
实现依次唤醒全部的等待进程。所以,sem_wait()的代码实现,必须考虑到这个情况。
参考linux 0.11内部的代码,对于进程是否需要等待的判断,不能用简单的if语句,而应该用while()语句。假设在sem_wait中使用if语句:c if (sem->value < 0) sleep_on(&(sem->queue));
现在sem=-1,生产者往缓冲区写入了一个数,sem=0<=0,此时应该将等待队列队首的进程唤醒。当被唤醒的队首进程再次调度执行,从sleep_on()函数退出,不会再执行此if判断,而直接从if语句退出,继续向下执行。而等待队列后面被唤醒的进程随后也会被调度执行,同样也不会执行if判断,退出if语句,继续向下执行,这显然是不应该的。因为生产者只往缓冲区写入了一个数,被等待队列的队首进程取走了,由于等待队列的队首进程已经取走了那个数,它应该已经将sem修改为sem=-1,其他等待的进程应该再次执行if判断,由于sem=-1<0,会继续睡眠。要让其他等待进程再次执行时,要重新进行判断,所以不能是if语句了,必须是下面的while语句:c while (sem->value < 0) sleep_on(&(sem->queue));
下面是我第一次实现sem_wait()的代码:c int sys_sem_wait(sem_t *sem) { cli(); sem->value--; while( sem->value < 0 ) sleep_on(&(sem->queue)) sti(); return 0; }
这么做的问题在于:假如当前有两个消费者因为缓冲区为空而阻塞,此时sem->value = -2。接着生产者往空缓冲区放入了一个数字,执行sem_post操作,将value值加1,此时sem->value = -2+1 = -1 <= 0,唤醒队首进程。队首进程从sleep_on函数退出,进入while (sem->value < 0)的判断,由于此时还有一个消费者阻塞,所以sem->value = -1,这就导致该队首进程又被阻塞,明明现在缓冲区有一个数可取,但之前阻塞的两个消费者仍是阻塞,不能取数。出错的原因在于:信号量减1的语句,要放在while判断后面,因为执行while判断时,进程有可能睡眠,而这种情况下,是不需要记录有多少个进程在睡眠的,因为sleep_on函数形成的隐式的等待队列已经记录下了进程的等待情况。
正确的sem_wait()代码如下:c int sys_sem_wait(sem_t *sem) { cli(); while( sem->value <= 0 ) // sleep_on(&(sem->queue)); //这两条语句顺序不能颠倒,很重要,是关于信号量能不 sem->value--; //能正确工作的!!! sti(); return 0; }
2. sem_post的实现
`sem_post`的实现必须结合`sem_wait`的实现分析。假设当前缓冲区为空,没有数可取,`sem->value = 0`。
消费者1执行`sem_wait`,由于信号量减1的指令在while判断后面,此时`value = 0`,消费者1阻塞。
消费者2执行`sem_wait`,同样`value = 0`,消费者2阻塞。
生产者执行`sem_post`,信号量的值加1,此时`value = 1`,要唤醒等待队列的队首进程消费者1。所以`sem_post`中的if判断应该为:
```c
if (sem->value <= 1)
wake_up(&(sem->queue));
```
消费者1执行,唤醒消费者2,跳出while判断,将信号量的值减1,此时`value = 0`。消费者1继续向下执行。
如果消费者2接着执行,由于之前生产者放入到缓冲区的唯一一个数已经被消费者1取走,所以此时`value = 0`,消费者2执行while判断,不满足条件,重新阻塞。
由此得到,`sem_post`中唤醒进程的判断条件为:`sem->value <= 1`。
`sem_post`实现如下:
```c
int sys_sem_post(sem_t *sem)
{
cli();
sem->value++;
if( (sem->value) <= 1)
wake_up(&(sem->queue));
sti();
return 0;
}
```
边栏推荐
- The first performance test practice, there are "100 million" a little nervous
- MySql index learning and use; (I think it is detailed enough)
- About the installation of sklearn library
- [BJDCTF2020]EasySearch
- creo怎么测量点到面的距离
- iMedicalLIS listener (2)
- 【8.3】代码源 - 【喵 ~ 喵 ~ 喵~】【树】【与】
- 浅析主流跨端技术方案
- [Surveying] Quick Summary - Excerpt from Gaoshu Gang
- Mysql的undo log详解
猜你喜欢
The log causes these pits in the thread block, you have to guard against
程序开发的一些常规套路(一)
作业8.4 进程间的通信 管道与信号
Four-digit display header design
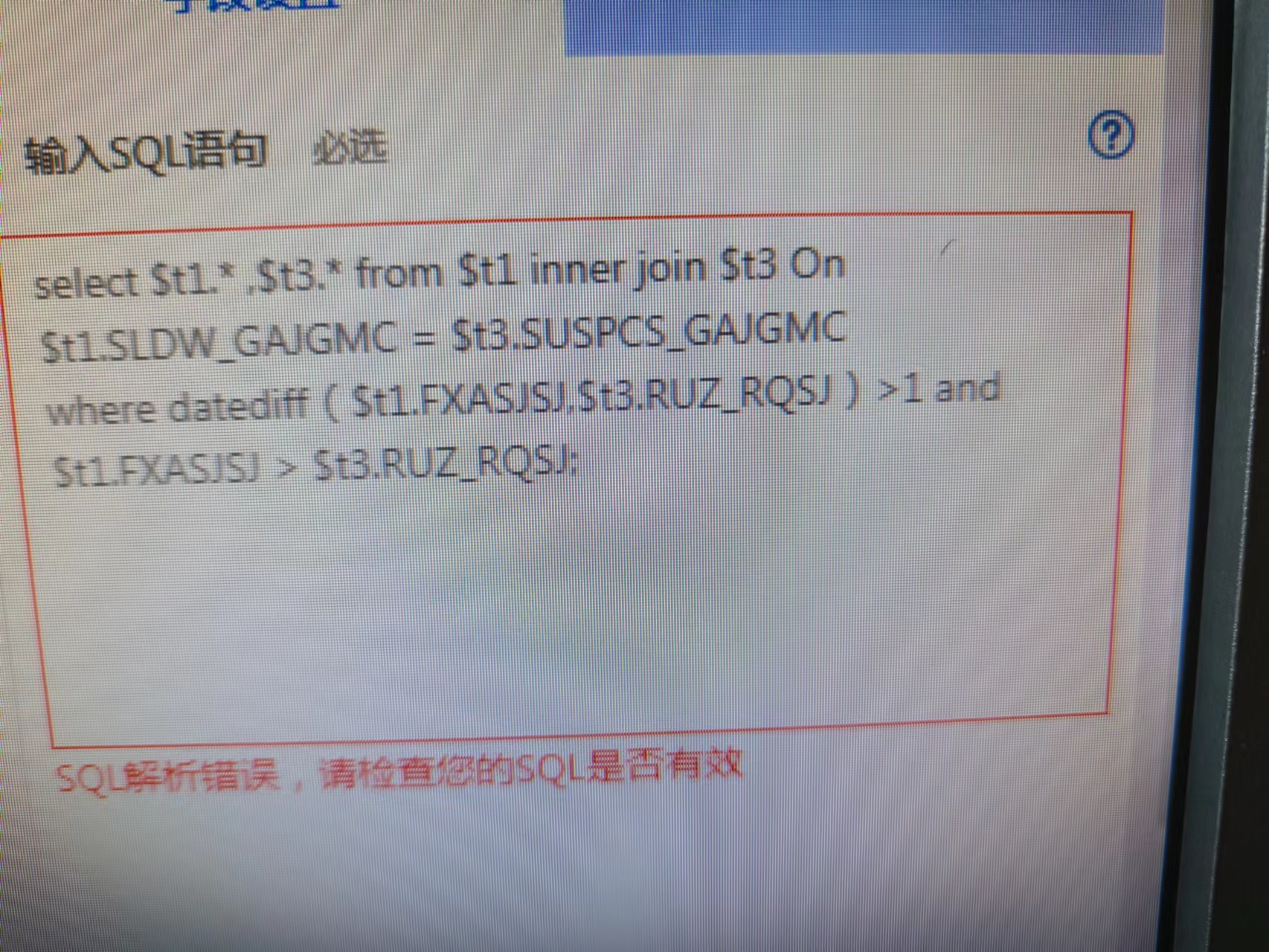
请写出SparkSQL语句
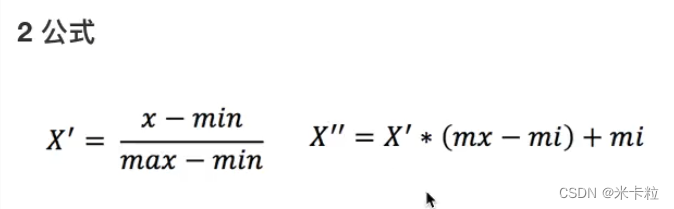
Feature preprocessing

Error creating bean with name ‘configDataContextRefresher‘ defined in class path resource

数字孪生技术在电力系统中的应用现状

flink读取mongodb数据源

如何解决复杂的分销分账问题?
随机推荐
动力小帆船制作方法简单,电动小帆船制作方法
How to identify false evidence and evidence?
The log causes these pits in the thread block, you have to guard against
【树莓派】树莓派调光
Paparazzi: Surface Editing by way of Multi-View Image Processing
UE4 更改组件变量 (以修改第一人称角色模板的最大行走速度和跳跃高度为例)
日志导致线程Block的这些坑,你不得不防
35岁的软件测试工程师,月薪不足2W,辞职又怕找不到工作,该何去何从?
[MRCTF2020] Ezpop (detailed)
DEJA_VU3D - Cesium功能集 之 059-腾讯地图纠偏
什么是ASEMI光伏二极管,光伏二极管的作用
[Surveying] Quick Summary - Excerpt from Gaoshu Gang
狗仔队:表面编辑多视点图像处理
[informix] Resolving startup errors and solutions
Please write the SparkSQL statement
【转】什么是etcd
Shell(4) Conditional Control Statement
[SWPU2019]Web1
[CISCN2019 华东南赛区]Web11
Shell(4)条件控制语句