当前位置:网站首页>Data Lake (13): spark and iceberg integrate DDL operations
Data Lake (13): spark and iceberg integrate DDL operations
2022-07-04 14:28:00 【Lansonli】

List of articles
Spark And Iceberg Integrate DDL operation
One 、CREATE TABLE Create table
Two 、CREATE TAEBL ... AS SELECT
1、 Create table hadoop_prod.default.mytbl, And insert data
2、 Use “create table ... as select” Syntax create table mytal2 And query
3、 ... and 、REPLACE TABLE ... AS SELECT
1、 Create table “hadoop_prod.default.mytbl3”, And insert data 、 Exhibition
2、 Rebuild table “hadoop_prod.default.mytbl3”, And insert the corresponding data
Four 、DROP TABLE
6、 ... and 、ALTER TABLE Partition operation
1、 Create table mytbl, And insert data
2、 Will table loc Columns are added as partition columns , And insert data , Inquire about
3、 take ts Columns are converted as partition columns , Insert data and query
Spark And Iceberg Integrate DDL operation
Use here Hadoop Catalog To demonstrate Spark And Iceberg Of DDL operation .
One 、CREATE TABLE Create table
Create table establish Iceberg surface , Creating tables can not only create ordinary tables, but also create partitioned tables , When inserting a batch of data into the partition table , The partitioned columns in the data must be sorted , Otherwise, a file closing error will appear , The code is as follows :
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
// Appoint hadoop catalog,catalog The name is hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.getOrCreate()
// Create a normal table
spark.sql(
"""
| create table if not exists hadoop_prod.default.normal_tbl(id int,name string,age int) using iceberg
""".stripMargin)
// Create a partition table , With loc Column as partition field
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl(id int,name string,age int,loc string) using iceberg partitioned by (loc)
""".stripMargin)
// When inserting data into a partitioned table , Partition columns must be sorted , Otherwise, the report will be wrong :java.lang.IllegalStateException: Already closed files for partition:xxx
spark.sql(
"""
|insert into table hadoop_prod.default.partition_tbl values (1,"zs",18,"beijing"),(3,"ww",20,"beijing"),(2,"ls",19,"shanghai"),(4,"ml",21,"shagnhai")
""".stripMargin)
spark.sql("select * from hadoop_prod.default.partition_tbl").show()The query results are as follows :

establish Iceberg In zoning , You can also use some conversion expressions to timestamp Column to convert , establish Hide partition , Common conversion expressions are as follows :
- years(ts): By year
// Create a partition table partition_tbl1 , Specify partition as year
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl1(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (years(regist_ts))
""".stripMargin)
// Insert data into table , Be careful , The inserted data needs to be sorted in advance , It has to be sorted , As long as the data of the same date are written together
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl1 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
// Query results
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl1
""".stripMargin).show()The results are as follows :
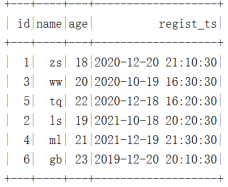
stay HDFS Middle is divided by year :
- months(ts): according to “ year - month ” Monthly level partition
// Create a partition table partition_tbl2 , Specify partition as months, According to “ year - month ” Partition
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl2(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (months(regist_ts))
""".stripMargin)
// Insert data into table , Be careful , The inserted data needs to be sorted in advance , It has to be sorted , As long as the data of the same date are written together
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl2 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
// Query results
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl2
""".stripMargin).show()The results are as follows :
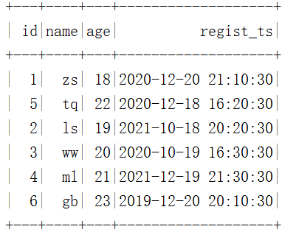
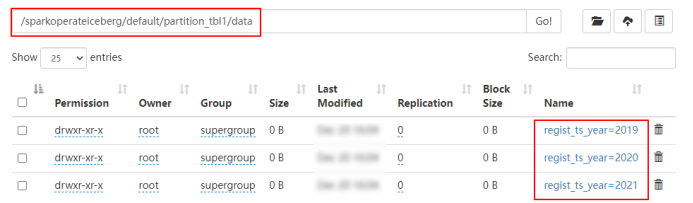
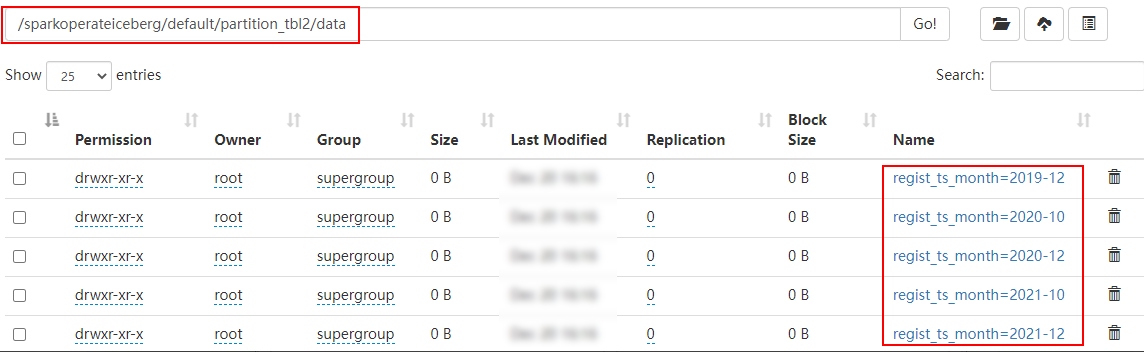
stay HDFS Is in accordance with the “ year - month ” partition :
- days(ts) perhaps date(ts): according to “ year - month - Japan ” Day level partition
// Create a partition table partition_tbl3 , Specify partition as days, According to “ year - month - Japan ” Partition
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl3(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (days(regist_ts))
""".stripMargin)
// Insert data into table , Be careful , The inserted data needs to be sorted in advance , It has to be sorted , As long as the data of the same date are written together
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl3 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
// Query results
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl3
""".stripMargin).show()The results are as follows :

stay HDFS Is in accordance with the “ year - month - Japan ” partition :
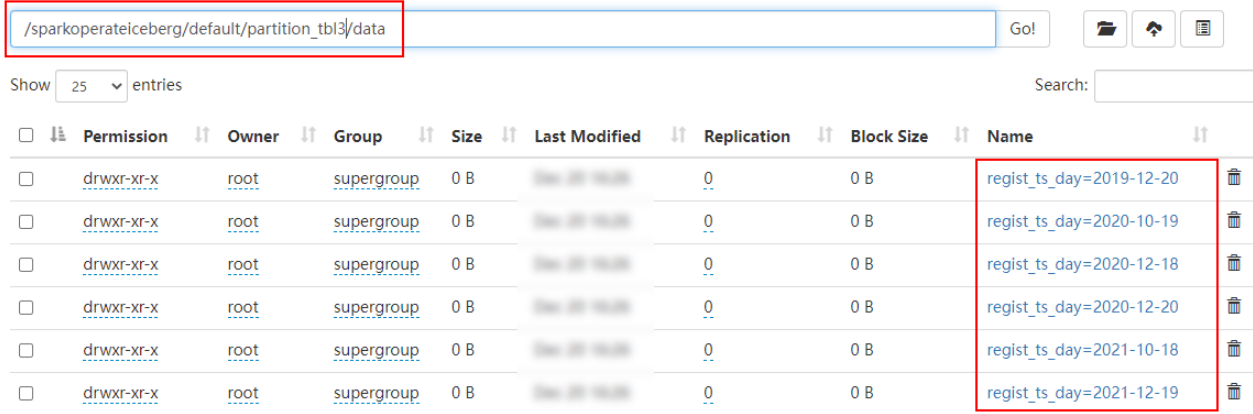
- hours(ts) perhaps date_hour(ts): according to “ year - month - Japan - when ” Hour level partition
// Create a partition table partition_tbl4 , Specify partition as hours, According to “ year - month - Japan - when ” Partition
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl4(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (hours(regist_ts))
""".stripMargin)
// Insert data into table , Be careful , The inserted data needs to be sorted in advance , It has to be sorted , As long as the data of the same date are written together
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl4 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
// Query results
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl4
""".stripMargin).show()The results are as follows :
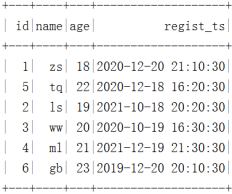
stay HDFS Is in accordance with the “ year - month - Japan - when ” partition :
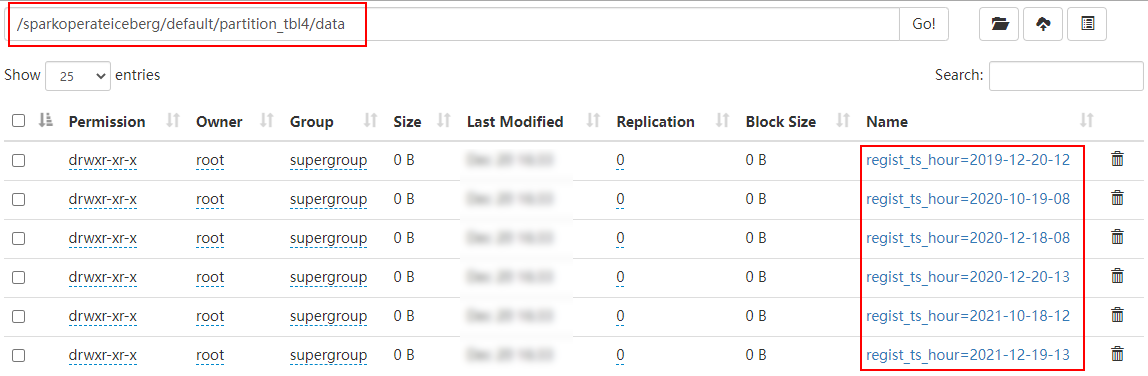
Iceberg The supported time partitions currently and in the future only support UTC,UTC It's international time ,UTC+8 It's international time plus eight hours , It's East eighth District time , It's Beijing time , So we can see that the partition time above is inconsistent with the data time .
In addition to the above commonly used time hidden partitions ,Iceberg And support bucket(N,col) Partition , This partitioning method can be based on hash Value and N The remainder determines the partition to which the data goes .truncate(L,col), This hidden partition can intercept the string of characters L length , The same data will be divided into the same partition .
Two 、CREATE TAEBL ... AS SELECT
Iceberg Support “create table .... as select ” grammar , You can create a table from the query statement , And insert the corresponding data , The operation is as follows :
1、 Create table hadoop_prod.default.mytbl, And insert data
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
// Appoint hadoop catalog,catalog The name is hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.getOrCreate()
// Create a normal table
spark.sql(
"""
| create table hadoop_prod.default.mytbl(id int,name string,age int) using iceberg
""".stripMargin)
// Insert data into table
spark.sql(
"""
|insert into table hadoop_prod.default.mytbl values (1,"zs",18),(3,"ww",20),(2,"ls",19),(4,"ml",21)
""".stripMargin)
// Query data
spark.sql("select * from hadoop_prod.default.mytbl").show()2、 Use “create table ... as select” Syntax create table mytal2 And query
spark.sql(
"""
|create table hadoop_prod.default.mytbl2 using iceberg as select id,name,age from hadoop_prod.default.mytbl
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl2
""".stripMargin).show()give the result as follows :
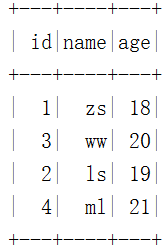
3、 ... and 、REPLACE TABLE ... AS SELECT
Iceberg Support “replace table .... as select ” grammar , You can rebuild a table from the query statement , And insert the corresponding data , The operation is as follows :
1、 Create table “hadoop_prod.default.mytbl3”, And insert data 、 Exhibition
spark.sql(
"""
|create table hadoop_prod.default.mytbl3 (id int,name string,loc string,score int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into table hadoop_prod.default.mytbl3 values (1,"zs","beijing",100),(2,"ls","shanghai",200)
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl3
""".stripMargin).show 
2、 Rebuild table “hadoop_prod.default.mytbl3”, And insert the corresponding data
spark.sql(
"""
|replace table hadoop_prod.default.mytbl2 using iceberg as select * from hadoop_prod.default.mytbl3
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl2
""".stripMargin).show()
Four 、DROP TABLE
Delete iceberg Table is executed directly :“drop table xxx” Sentence can be used , When deleting a table , The table data will be deleted , But the library directory exists .
// Delete table
spark.sql(
"""
|drop table hadoop_prod.default.mytbl
""".stripMargin) 
5、 ... and 、ALTER TABLE
Iceberg Of alter Operation in Spark3.x Version supports ,alter It generally includes the following operations :
- add to 、 Delete column
Add column operation :ALTER TABLE ... ADD COLUMN
Delete column operation :ALTER TABLE ... DROP COLUMN
//1. Create table test, And insert data 、 Inquire about
spark.sql(
"""
|create table hadoop_prod.default.test(id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into table hadoop_prod.default.test values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)
spark.sql(
"""
| select * from hadoop_prod.default.test
""".stripMargin).show()
//2. Add fields , to test Table increase gender Column 、loc Column
spark.sql(
"""
|alter table hadoop_prod.default.test add column gender string,loc string
""".stripMargin)
//3. Delete field , to test Table delete age Column
spark.sql(
"""
|alter table hadoop_prod.default.test drop column age
""".stripMargin)
//4. See the table test data
spark.sql(
"""
|select * from hadoop_prod.default.test
""".stripMargin).show()The final table shows fewer columns age Column , More gender、loc Column :

- To be ranked high
Rename the syntax :ALTER TABLE ... RENAME COLUMN, The operation is as follows :
//5. To be ranked high
spark.sql(
"""
|alter table hadoop_prod.default.test rename column gender to xxx
|
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.test
""".stripMargin).show()The columns shown in the final table gender The column becomes xxx Column :

6、 ... and 、ALTER TABLE Partition operation
alter Partition operations include adding partitions and deleting partitions , This partition operation is in Spark3.x Later supported ,spark2.4 Version not supported , And when you use it , Must be in spark Add... To the configuration spark.sql.extensions attribute , Its value is :org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions, Partition conversion is also supported when adding partitions , The grammar is as follows :
- Add partition syntax :ALTER TABLE ... ADD PARTITION FIELD
- Delete partition Syntax :ALTER TABLE ... DROP PARTITION FIELD
The specific operation is as follows :
1、 Create table mytbl, And insert data
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
// Appoint hadoop catalog,catalog The name is hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//1. Create a normal table
spark.sql(
"""
| create table hadoop_prod.default.mytbl(id int,name string,loc string,ts timestamp) using iceberg
""".stripMargin)
//2. Insert data into table , And query
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(1,'zs',"beijing",cast(1608469830 as timestamp)),
|(3,'ww',"shanghai",cast(1603096230 as timestamp))
""".stripMargin)
spark.sql("select * from hadoop_prod.default.mytbl").show()stay HDFS The data storage and results in are as follows :


2、 Will table loc Columns are added as partition columns , And insert data , Inquire about
//3. take loc Columns are added as partitions , You must add config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") To configure
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field loc
""".stripMargin)
//4. To watch mytbl Continue inserting data in , Previously, the data was not partitioned , After that, the data is partitioned
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()stay HDFS The data storage and results in are as follows :
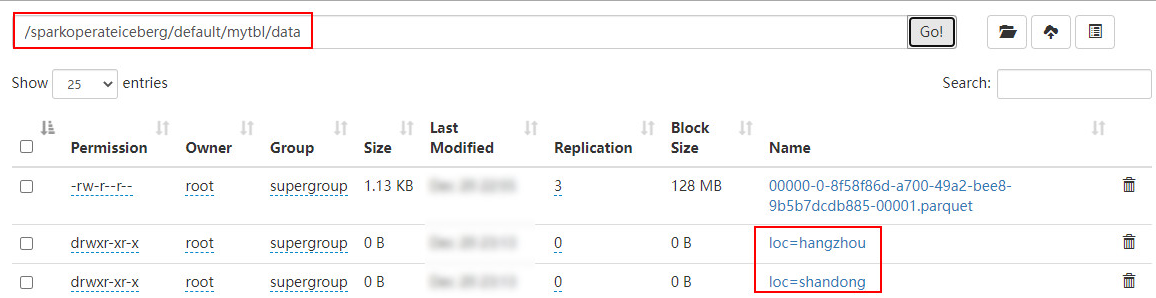

Be careful : Adding partition fields is a metadata operation , The existing table data will not be changed , New data will be written using the new partition , Existing data will remain in the original layout .
3、 take ts Columns are converted as partition columns , Insert data and query
//5. take ts Columns are added as partition columns by partition transformation
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field years(ts)
""".stripMargin)
//6. To watch mytbl Continue inserting data in , Previously, the data was not partitioned , After that, the data is partitioned
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
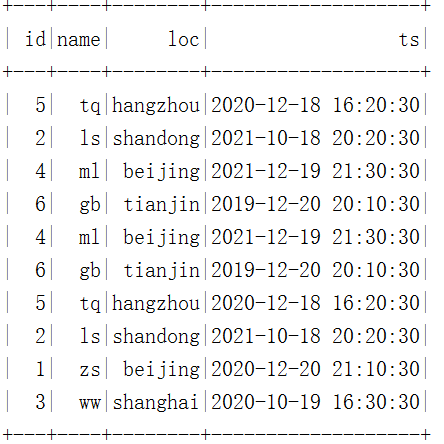
spark.sql("select * from hadoop_prod.default.mytbl").show()stay HDFS The data storage and results in are as follows :
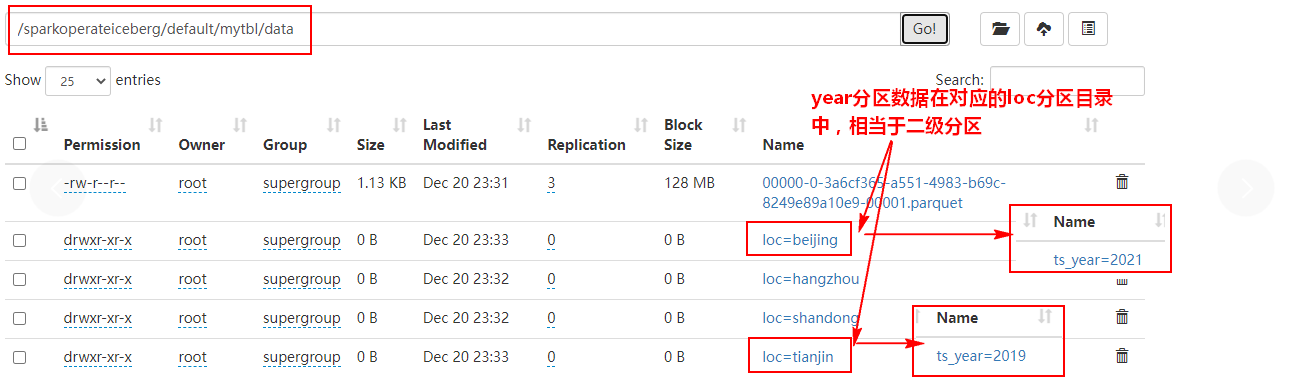
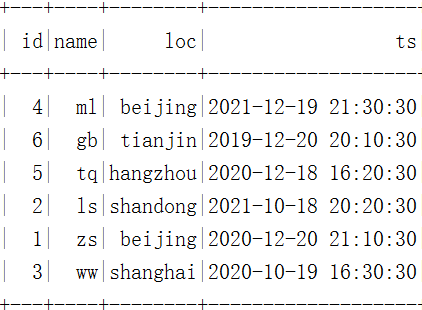
4、 Delete partition loc
//7. Delete table mytbl Medium loc Partition
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field loc
""".stripMargin)
//8. Go on to the table mytbl Insert data , And query
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()stay HDFS The data storage and results in are as follows :

Be careful : Because there are ts The corresponding partition after partition conversion , So continue inserting data loc Zoning null
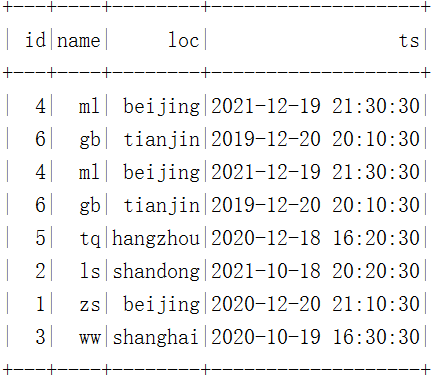
5、 Delete partition years(ts)
//9. Delete table mytbl Medium years(ts) Partition
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field years(ts)
""".stripMargin)
//10. Go on to the table mytbl Insert data , And query
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()stay HDFS The data storage and results in are as follows :

- Blog home page :https://lansonli.blog.csdn.net
- Welcome to thumb up Collection Leaving a message. Please correct any mistakes !
- This paper is written by Lansonli original , First appeared in CSDN Blog
- When you stop to rest, don't forget that others are still running , I hope you will seize the time to learn , Go all out for a better life
边栏推荐
- Redis daily notes
- LifeCycle
- 商业智能BI财务分析,狭义的财务分析和广义的财务分析有何不同?
- DDD application and practice of domestic hotel transactions -- Code
- 【MySQL从入门到精通】【高级篇】(五)MySQL的SQL语句执行流程
- Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
- Migration from go vendor project to mod project
- Talk about 10 tips to ensure thread safety
- Incremental ternary subsequence [greedy training]
- Test evaluation of software testing
猜你喜欢




随机推荐
2022 game going to sea practical release strategy
DDD application and practice of domestic hotel transactions -- Code
gin集成支付宝支付
Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)
Leetcode T48:旋转图像
电商系统中红包活动设计
docker-compose公网部署redis哨兵模式
R language uses follow up of epidisplay package The plot function visualizes the longitudinal follow-up map of multiple ID (case) monitoring indicators, and uses stress The col parameter specifies the
Visual Studio调试方式详解
One architecture to complete all tasks - transformer architecture is unifying the AI Jianghu on its own
The mouse wheel of xshell/bash/zsh and other terminals is garbled (turn)
R语言dplyr包summarise_if函数计算dataframe数据中所有数值数据列的均值和中位数、基于条件进行数据汇总分析(Summarize all Numeric Variables)
数据仓库面试问题准备
富文本编辑:wangEditor使用教程
为什么图片传输要使用base64编码
利用Shap值进行异常值检测
Data warehouse interview question preparation
MySQL的存储过程练习题
Nowcoder rearrange linked list
基于51单片机的超声波测距仪