当前位置:网站首页>数据仓库面试问题准备
数据仓库面试问题准备
2022-07-04 12:50:00 【51CTO】
一、如何理解数据体系
包含数据模型、数据分层、数据主题划分、数据治理、元数据管理、数据安全权限、数仓可视化产品的完整数仓服务体系
二、数仓的目标是什么
数据质量和数据服务两个角度
数据质量:有序、有结构地分类组织和存储数据,避免重复建设和数据不一致性,保证数据的规范性
数据服务:提高数据使用体验,包括数据的准确度、数据产品提升数据可视化服务的体感
追问:怎么理解分类组织和存储
分类组织:组织映射到数仓的主题划分(横向)、分层(纵向)
存储:针对生命周期管理、数据治理
三、事实表分几种
- 基于分层、以及明细表类型
根据分层,原子指标组成明细事实表DWD,派生指标组成汇总事实表DWS
明细事实表又分为:事务事实表、累积快照事实表、周期快照事实表
- 展开说。。。
事务型事实表用来描述业务过程,跟踪空间或者时间上某点的度量时间,保存的是最原子的数据,也可以称作“原子事实表”
周期快照事实表以具有规律性的、可预见的时间间隔记录事实,时间间隔如每天、每月、每年等。
累计快照事实表用来表述过程开始和结束之间的关键步骤时间,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点,当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。

四、指标有哪一些内容
内容:原子指标、派生指标、衍生指标
关系
派生指标= 原子指标+时间周期+修饰词
派生指标又分为:事务型指标、存量型指标和复合型指标
事务型指标:是指对业务活动进行衡量的指标。例如:新发商品数,订单支付金额。是修饰词+原子指标
存量型指标:是指对实体对象(如商品、会员)某些状态的统计。例如:商品总数是修饰词+原子指标+周期(一般是历史截至至当前某个时间)
复合型指标:在事务型指标和存量型指标的基础上复合而成。
- 业务中的关联
- 原子指标、修饰类型和修饰词,直接归属在业务过程下,其中修饰词继承修饰类型的数据域,例如:A渠道的支付金额,通过支付可以知道是属于支付主域的,渠道是修饰渠道主题域的,可以是跨域的组合
- 派生指标可以选择多个修饰词,修饰词之间的关系为“或”或者“且”,例如:新客购买电子品类支付金额,修饰词:新客且电子产品
- 派生指标唯一归属一个原子指标,继承原子指标的数据域,与修饰词的数据域无关。例如:A渠道的支付金额,还是说的是支付金额
- 一般而言,如果遇到同时有两个行为发生,需要多个修饰词、生成一个派生指标的情况,则选择时间靠后的行为创建原子指标,选择时间靠前的行为创建修饰词,例如:A渠道的支付金额,先经历了渠道后才产生的交易,渠道就发生比较前,后再进行消费产生支付金额,原子指标就比较靠后
- 引申整个体系架构
- 确定企业层级和业务部门的数仓,然后去确认主题域,再去梳理业务过程,基础数据就是原子指标,落到DWD形成明细事实表,加上修饰词变成派生指标,形成轻度DWS汇总事实表,维度会经过维度退化和事实表关联。
五、维度退化到单事务型事实表里面和宽表的区别
前者还是代表是解耦业务过程的事实表,宽表是跨业务过程进行融合的表,强调多个业务流程
边栏推荐
- Introducing testfixture into unittest framework
- Learning projects are self-made, and growth opportunities are self created
- 近日小结(非技术文)
- 205. 同构字符串
- R语言使用dplyr包的mutate函数对指定数据列进行标准化处理(使用mean函数和sd函数)并基于分组变量计算标准化后的目标变量的分组均值
- Haobo medical sprint technology innovation board: annual revenue of 260million Yonggang and Shen Zhiqun are the actual controllers
- Install and use MAC redis, connect to remote server redis
- MySQL8版本免安装步骤教程
- 吃透Chisel语言.03.写给Verilog转Chisel的开发者(没有Verilog基础也可以看看)
- Test evaluation of software testing
猜你喜欢
硬件基础知识-二极管基础
Understand chisel language thoroughly 06. Chisel Foundation (III) -- registers and counters

Detailed explanation of Fisher information quantity detection countermeasure sample code
【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
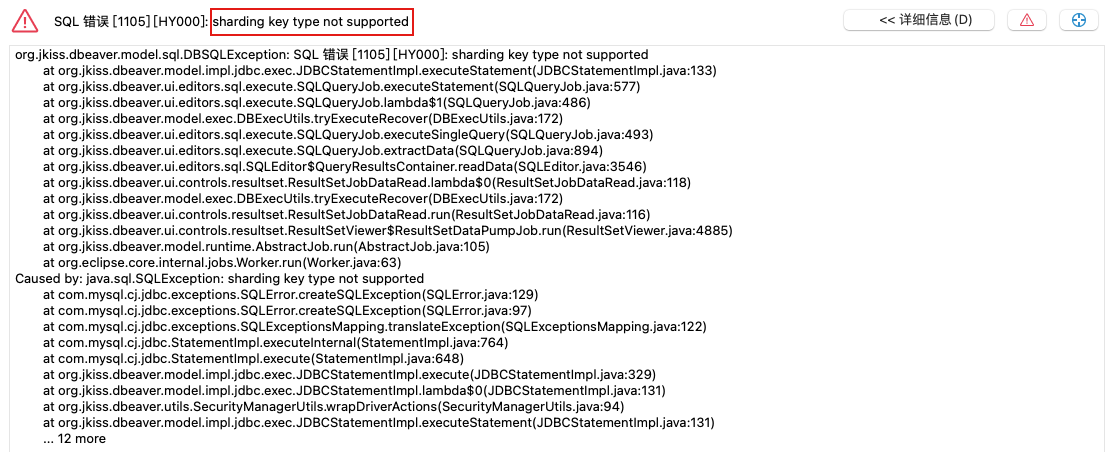
sharding key type not supported
392. Judgement subsequence
基于YOLOv1的口罩佩戴检测
[FAQ] summary of common causes and solutions of Huawei account service error 907135701
好博医疗冲刺科创板:年营收2.6亿 万永钢和沈智群为实控人
Qt如何实现打包,实现EXE分享
随机推荐
Summary of recent days (non-technical article)
奇妙秘境 码蹄集
2022 hoisting machinery command examination simulation 100 questions simulation examination platform operation
[FAQ] summary of common causes and solutions of Huawei account service error 907135701
Understand chisel language thoroughly 05. Chisel Foundation (II) -- combinational circuits and operators
Can mortgage with housing exclude compulsory execution
golang fmt.printf()(转)
CVPR 2022 | greatly reduce the manual annotation required for zero sample learning, and propose category semantic embedding rich in visual information (source code download)
吃透Chisel语言.10.Chisel项目构建、运行和测试(二)——Chisel中生成Verilog代码&Chisel开发流程
qt 怎么检测鼠标在不在某个控件上
以房抵债能否排除强制执行
Whether the loyalty agreement has legal effect
Interviewer: what is the internal implementation of hash data type in redis?
常见 content-type对应表
Hardware Basics - diode Basics
Common content type correspondence table
golang fmt. Printf() (turn)
测试流程整理(2)
[antd step pit] antd form cooperates with input Form The height occupied by item is incorrect
安装Mysql