当前位置:网站首页>CVPR 2022 | greatly reduce the manual annotation required for zero sample learning, and propose category semantic embedding rich in visual information (source code download)
CVPR 2022 | greatly reduce the manual annotation required for zero sample learning, and propose category semantic embedding rich in visual information (source code download)
2022-07-04 14:03:00 【Computer Vision Research Institute】
Pay attention to the parallel stars
Never get lost
Institute of computer vision



official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage
Computer Vision Institute column
author :Edison_G
From Beijing University of Posts and telecommunications 、 Researchers from Mapu Institute and other institutions have proposed category embedding mining network , It improves the completeness of category embedding in visual space , It plays an important role in promoting knowledge transfer between categories in zero sample learning .
from 《 Almost Human 》
Zero sample learning aims to imitate human reasoning process , Using knowledge of visible categories , Identify invisible categories without training samples . Category embedding (class embeddings) It is a vector that describes category semantics and visual features , It can realize the transfer of knowledge between categories , Therefore, it plays an irreplaceable role in zero sample learning .
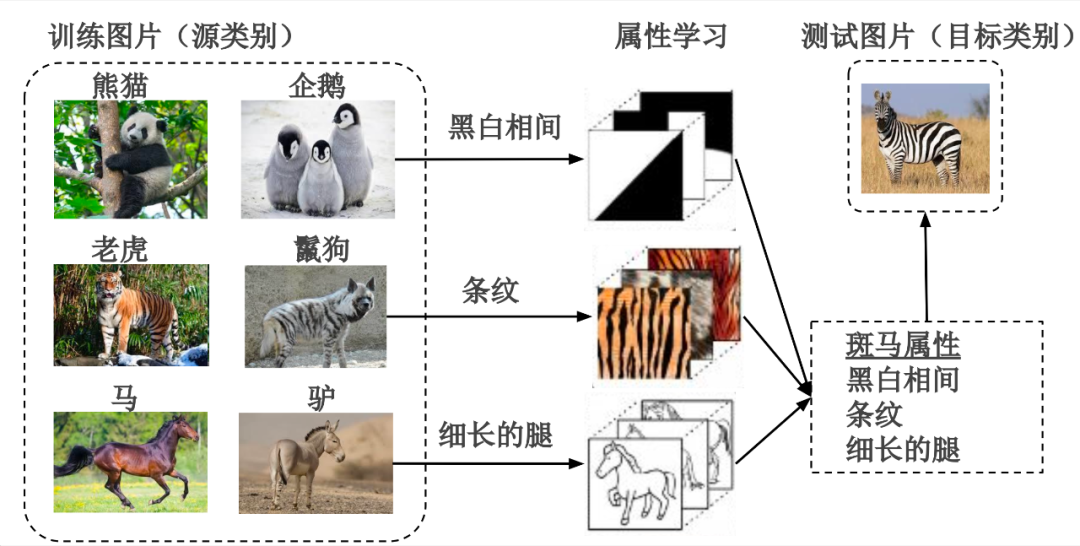
Zero sample classification diagram
As shown in the figure above , Because of attributes (attributes) Can be shared by different categories , Promote the transfer of knowledge between categories , Therefore, it is the most widely used category embedding . And in other computer vision tasks ( Such as face recognition 、 Fine grained classification 、 Fashion trend forecast ) Is widely used as auxiliary information .
However, the process of attribute annotation requires a lot of manpower input and expert knowledge , It limits the expansion of zero sample learning on new data sets . Besides , Limited by human cognitive limitations , Its labeled attributes cannot traverse the visual space , Therefore, some distinguishing features in the image cannot be captured by attributes , Result in poor learning effect of zero samples .
For the above problems , From Beijing University of Posts and telecommunications 、 Researchers from Mapu Institute and other institutions have proposed category embedding mining network (Visually-Grounded Semantic Embedding Network, VGSE), This article mainly answers two questions :(1) How to automatically discover category embedding with semantic and visual features from visible class images ;(2) How to... Without training samples , Forecast category embedding for invisible categories .

Thesis link : https://arxiv.org/abs/2203.10444
Code link : https://github.com/wenjiaXu/VGSE
In order to fully mine the shared visual features among different categories ,VGSE The model clusters a large number of local image slices according to their visual similarity to form attribute clusters , Summarize the visual features shared by different categories of instances from the underlying features of the image . Besides VGSE The model proposes the category relation module , Learning category relationships with the help of a small number of external knowledge sources , Ability to transfer knowledge from source category to target category , Predict class embedding for target classes without training images . Compared with other attributes obtained from corpus based automatic mining ,VGSE Model in CUB、SUN、AWA2 Very competitive results are obtained on the zero sample classification dataset . As shown in the figure below , This paper can explore the visual features that are complementary to the manual annotation attributes , Improve the completeness of category embedding in visual space , It plays an important role in promoting knowledge transfer between categories in zero sample learning . This paper has been published by CVPR 2022 Employment .
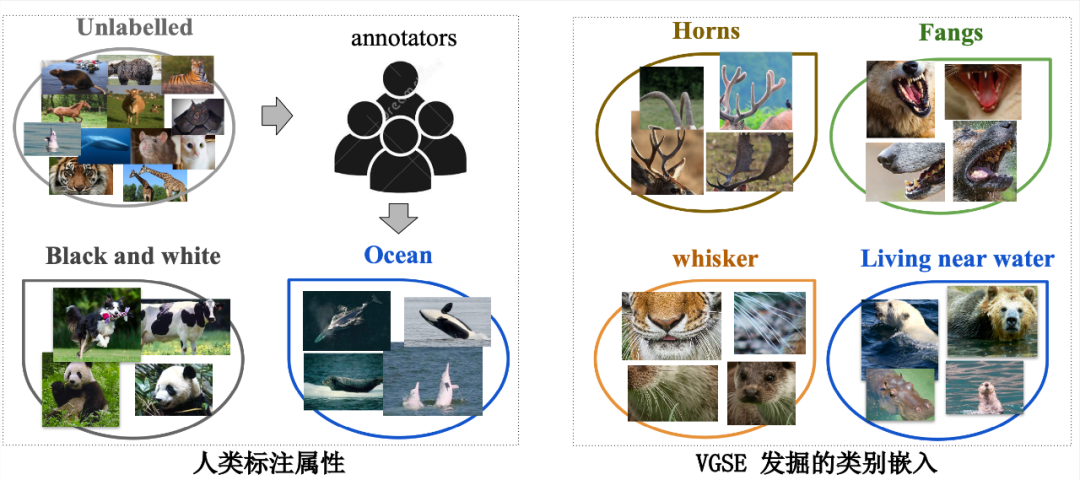
Category embedded mining model
Category embedded mining model VGSE The flow of the algorithm is shown below , The model is mainly composed of two modules :(1) Slice clustering module (Patch Clustering, PC) Take training data set as input , Cluster image slices into different clusters .(2) Category relation module (Class Relation, CR) Semantic embedding for predicting invisible classes .
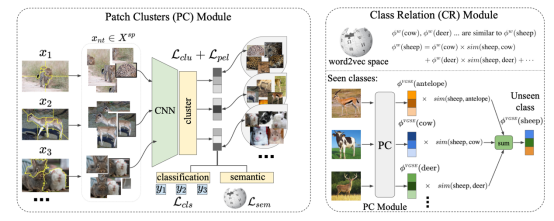
VGSE Model structure
Slice clustering module
Because attributes usually appear in local areas of the image , For example, animal body parts 、 The shape and texture of objects in the scene , Therefore, this paper proposes to use the clustering of image local slices to explore visual attribute clusters . In order to get the information that covers the whole semantic image area ( For example, animal head ) The image block of , The slice clustering module adopts the unsupervised compact watershed segmentation algorithm [4] Divide the image into regular shaped areas , Then the visual similarity of image slices is used for clustering .
The slice clustering module is a differentiable deep neural network , Given image slice , The network first extracts the features of the image , Then through the clustering layer 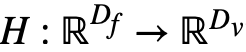 Predict the probability that the feature will be predicted in each attribute cluster :
Predict the probability that the feature will be predicted in each attribute cluster :
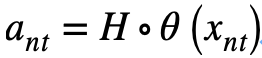
In this paper, the clustering loss function based on visual similarity is used to train the clustering network . Force image slicing 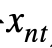 And its similar slice sets are clustered into the same attribute cluster :
And its similar slice sets are clustered into the same attribute cluster :
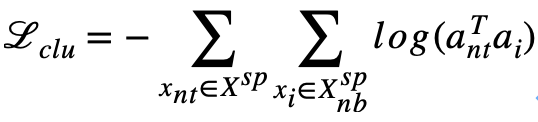
In order to enhance the discrimination of category embedding , So that it can distinguish the significant differences between categories , This paper proposes adding discernibility information , By learning the full connectivity layer , The prediction of each picture is mapped to its category prediction probability , Then the cross entropy loss training model is used :
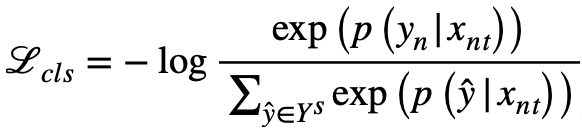
This article aims to learn about attribute clusters shared between categories , Promote the transfer of knowledge between categories , Therefore, attribute clusters are encouraged to contain semantic links between categories . To achieve this goal , By learning the full connectivity layer S, Map the embedding of each picture to the semantic tags of the category ( Use the... Of the category name here w2v vector ). And then through the regression loss training model , To strengthen the semantic connection of category embedding :
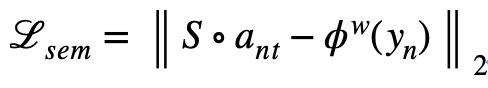
Final , The image embedding of a complete image is calculated by averaging the embedding of all slices in the image :
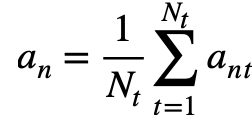
And the category  The embedding of is obtained by averaging all the images of this class :
The embedding of is obtained by averaging all the images of this class :
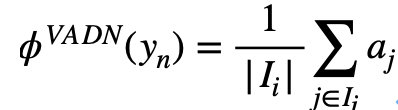
Category relation module
The embedding of visible classes can be predicted by the slice clustering module . But in reality, there are a lot of invisible classes , Its category embedding cannot be predicted by image . Because semantically related categories usually share some attributes , For example, pandas and zebras share “ Black and white “ attribute , Both elk and bull contain “ horn ” This property . This section proposes to learn the semantic similarity between visible and invisible classes , And predict the embedding of invisible classes through semantically related visible classes . Any external semantic knowledge , for example w2v、glove And other category semantic embedded or manually annotated attributes , Can be used to learn the relationship between two classes . Below to w2v An example is given to illustrate the proposed class relation mining module .
For a given visible class w2v Semantic label , And the semantic tags of invisible categories , In this section, you learned about similarity mapping , Where represents the similarity between the target class and the source class . Similarity mapping is learned through the following optimization problems :
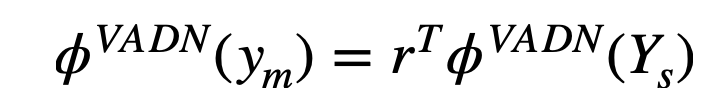
among , The attribute value of the target category is the weighted sum of all the attribute values of the source category .
experimental result
In this paper, three general zero sample classification datasets (CUB、AWA2、SUN) To verify the effectiveness of the proposed method .
The figure below shows AWA2 Attribute clusters learned from data sets . We will 10,000 The embedding and utilization of image slices t-SNE Map to 2D space . This paper samples several attribute clusters ( Use dots of the same color ) The image slices from the attribute cluster are marked in the figure .
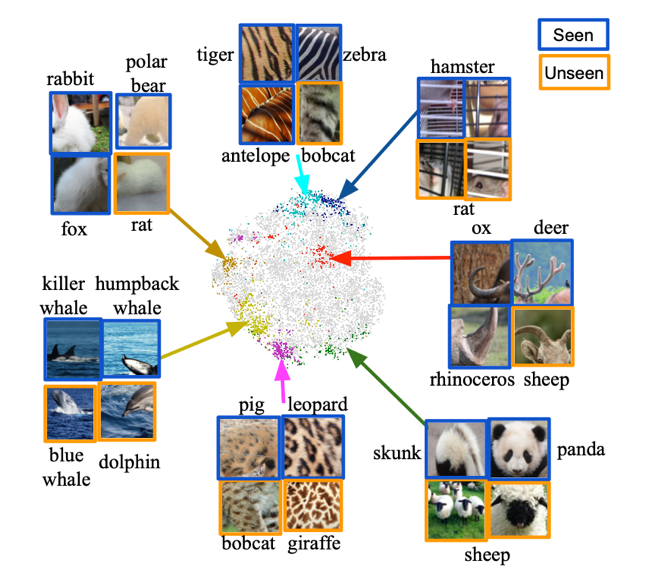
Mining attribute cluster visualization results
The data in the figure illustrates the following points : First , It can be observed that image slices in the same cluster tend to cluster together , And convey a consistent visual message , This indicates that image embedding provides discernible information . Besides , Almost all attribute clusters contain image slices from multiple categories . for example , Stripes from different animals , Although the color is slightly different, the texture is similar . This phenomenon shows that the category embedding studied in this paper contains the information shared between classes . Another interesting observation is , The model proposed in this paper can find the visual attributes neglected by human annotation , It can enhance the visual completeness of human annotation attributes .
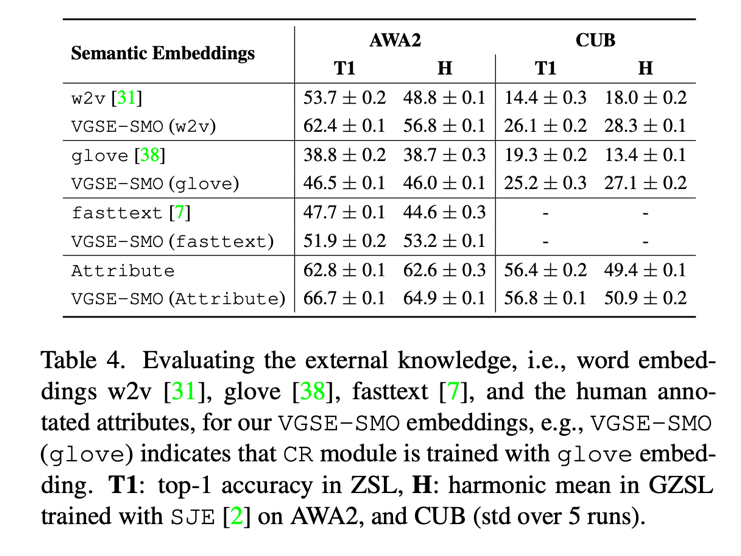
Table 1 It shows the class embedding VGSE-SMO With category w2v The representation of vectors on three data sets . To test the ability to embed two categories , We f-VAEGAN-D2[5] And so on , The results show that the category embedding proposed in this paper can greatly surpass w2v The performance of vectors .
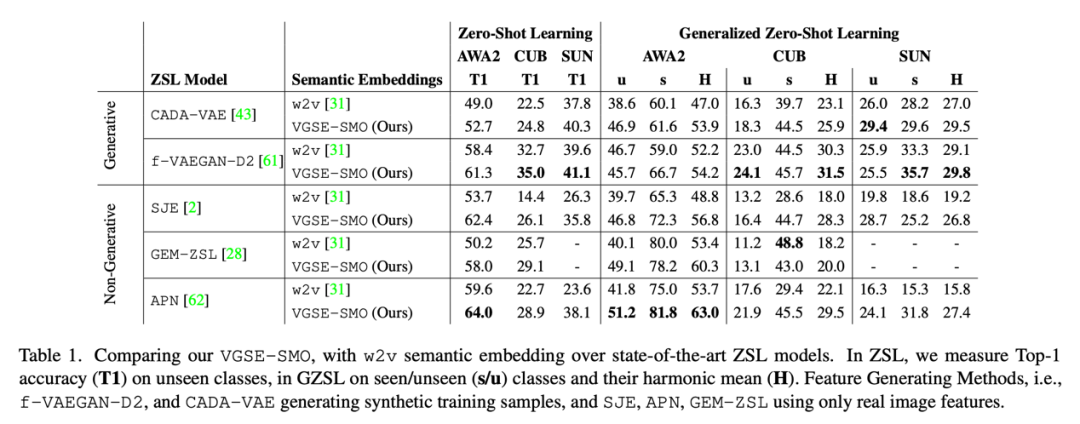
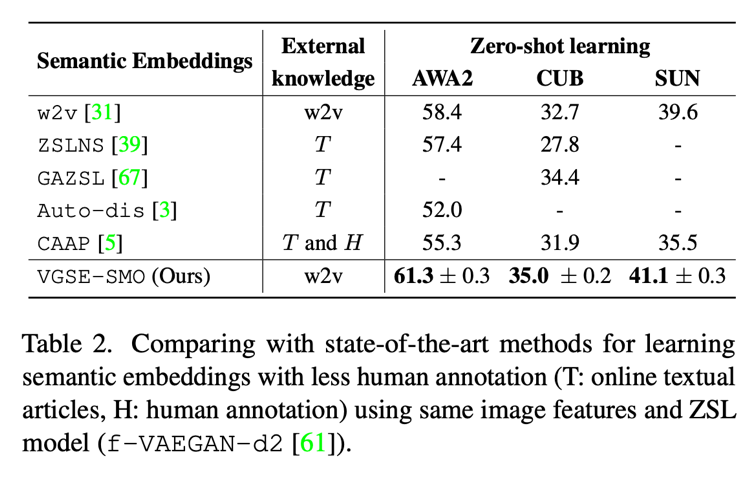
Table 2 In the task of zero sample classification, the effects of category embedding proposed in this paper and several other methods of corpus attribute mining are compared , The results show that the method in this paper only uses w2v In the case of vectors , The effect is better than other methods using online corpus .
As mentioned earlier , The class relation module proposed in this paper can use a variety of external semantic knowledge to learn class similarity ,Table 4 Shows the effect of using different semantic knowledge .
This paper investigates the semantic consistency and visual consistency of the category embedding . Random selection 50 Attribute clusters , And show the 30 A picture . The user is first asked to view an example image of the attribute cluster . Then answer the following questions to measure the effect of attribute clusters .

User survey interface
It turns out that , stay 88.5% and 87.0% Under the circumstances , Users think that the attribute clusters mined by this method convey consistent visual and semantic information .
summary
To reduce the manual annotation required for zero sample learning , Improve the semantic and visual completeness of category embedding , This paper presents an automatic class embedding mining network VSGE Model , It can use the visual similarity of image slices to explore category embedding . The results on three datasets show that , The class embedding scheme proposed in this paper can effectively improve the quality of semantic embedding , And it can mine fine-grained attributes that are difficult for human beings to label . Besides playing an important role in zero sample learning , The category embedding proposed in this paper can also provide new ideas for other attribute related research .
reference :
[1] Al-Halah, Ziad, and Rainer Stiefelhagen. "Automatic discovery, association estimation and learning of semantic attributes for a thousand categories." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[2] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Proceedings of the Advances in neural information processing systems. 2013.
[3] Wang, Xiaolong, Yufei Ye, and Abhinav Gupta. "Zero-shot recognition via semantic embeddings and knowledge graphs." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Neubert, Peer, and Peter Protzel. "Compact watershed and preemptive slic: On improving trade-offs of superpixel segmentation algorithms." Proceedings of the IEEE International Conference on Pattern Recognition. 2014.
[5] Xian, Yongqin, et al. "f-vaegan-d2: A feature generating framework for any-shot learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
THE END
Please contact the official account for authorization.

The learning group of computer vision research institute is waiting for you to join !
ABOUT
Institute of computer vision
The Institute of computer vision is mainly involved in the field of deep learning , Mainly devoted to face detection 、 Face recognition , Multi target detection 、 Target tracking 、 Image segmentation and other research directions . The Research Institute will continue to share the latest paper algorithm new framework , The difference of our reform this time is , We need to focus on ” Research “. After that, we will share the practice process for the corresponding fields , Let us really experience the real scene of getting rid of the theory , Develop the habit of hands-on programming and brain thinking !
VX:2311123606

边栏推荐
- Web knowledge supplement
- 小程序直播 + 电商,想做新零售电商就用它吧!
- unity不识别rider的其中一种解决方法
- ViewBinding和DataBinding的理解和区别
- How to choose a technology stack for web applications in 2022
- Secretary of Homeland Security of the United States: domestic violent extremism is one of the biggest terrorist threats facing the United States at present
- C语言中学生成绩管理系统
- find命令报错: paths must precede expression(转)
- 忠诚协议是否具有法律效力
- 吃透Chisel语言.07.Chisel基础(四)——Bundle和Vec
猜你喜欢
.Net之延迟队列
Introduction to reverse debugging PE structure resource table 07/07
Unittest中的TestSuite和TestRunner
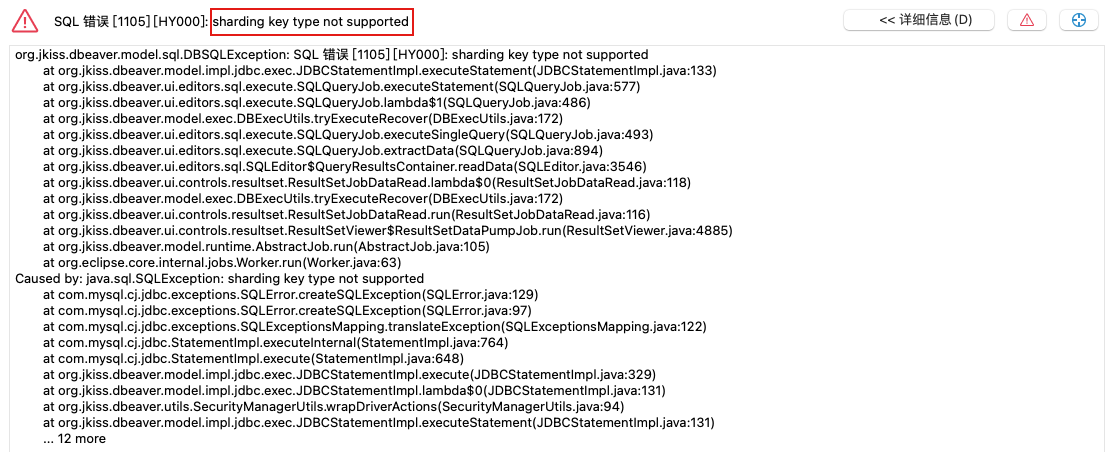
sharding key type not supported
MySQL 5 installation and modification free
字节面试算法题

博士申请 | 西湖大学学习与推理系统实验室招收博后/博士/研究实习等
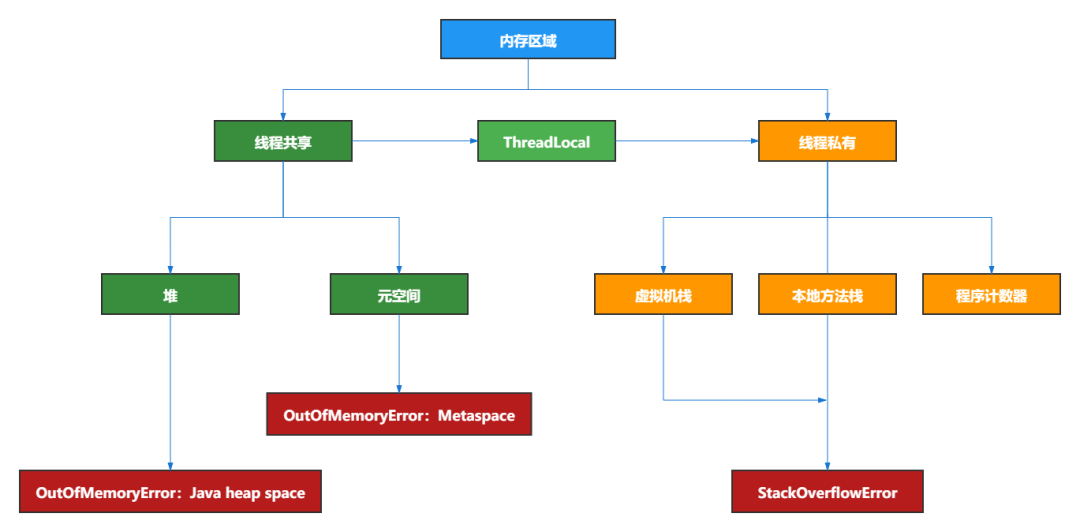
JVM 内存布局详解,图文并茂,写得太好了!

面试官:Redis中哈希数据类型的内部实现方式是什么?
JVM memory layout detailed, illustrated, well written!
随机推荐
JVM series - stack and heap, method area day1-2
结合案例:Flink框架中的最底层API(ProcessFunction)用法
C语言集合运算
吃透Chisel语言.07.Chisel基础(四)——Bundle和Vec
WS2818M是CPC8封装,是三通道LED驱动控制专用电路外置IC全彩双信号5V32灯可编程led灯带户外工程
Interview disassembly: how to check the soaring usage of CPU after the system goes online?
2022年山东省安全员C证考试题库及在线模拟考试
go语言中的文件创建,写入,读取,删除(转)
Scripy framework learning
Worried about "cutting off gas", Germany is revising the energy security law
小程序直播 + 电商,想做新零售电商就用它吧!
MySQL8版本免安装步骤教程
IP 实验室月复盘 · 第 5 期
mac redis安装与使用,连接远程服务器 redis
#yyds干货盘点# 解决名企真题:连续最大和
Dgraph: large scale dynamic graph dataset
程序员的焦虑
吃透Chisel语言.06.Chisel基础(三)——寄存器和计数器
常见 content-type对应表
华昊中天冲刺科创板:年亏2.8亿拟募资15亿 贝达药业是股东