当前位置:网站首页>sql优化之查询优化器
sql优化之查询优化器
2022-07-04 12:51:00 【氵奄不死的鱼】
本文大部分内容引用自代码搬运工.-MYSQL查询优化器
看本篇之前推荐看 innodb数据结构,缓冲区 熟悉数据库存数结构
MYSQL 逻辑结构
MySQL 使用典型的客户端/服务器(Client/Server)结构, 体系结构大体可以分为三层:客户端、服务器层以及存储引擎层。其中,服务器层又包括了连接管理、查询缓存 、SQL 接口、解析器、优化器、缓冲与缓存以及各种管理工具与服务等。逻辑结构图如下所示: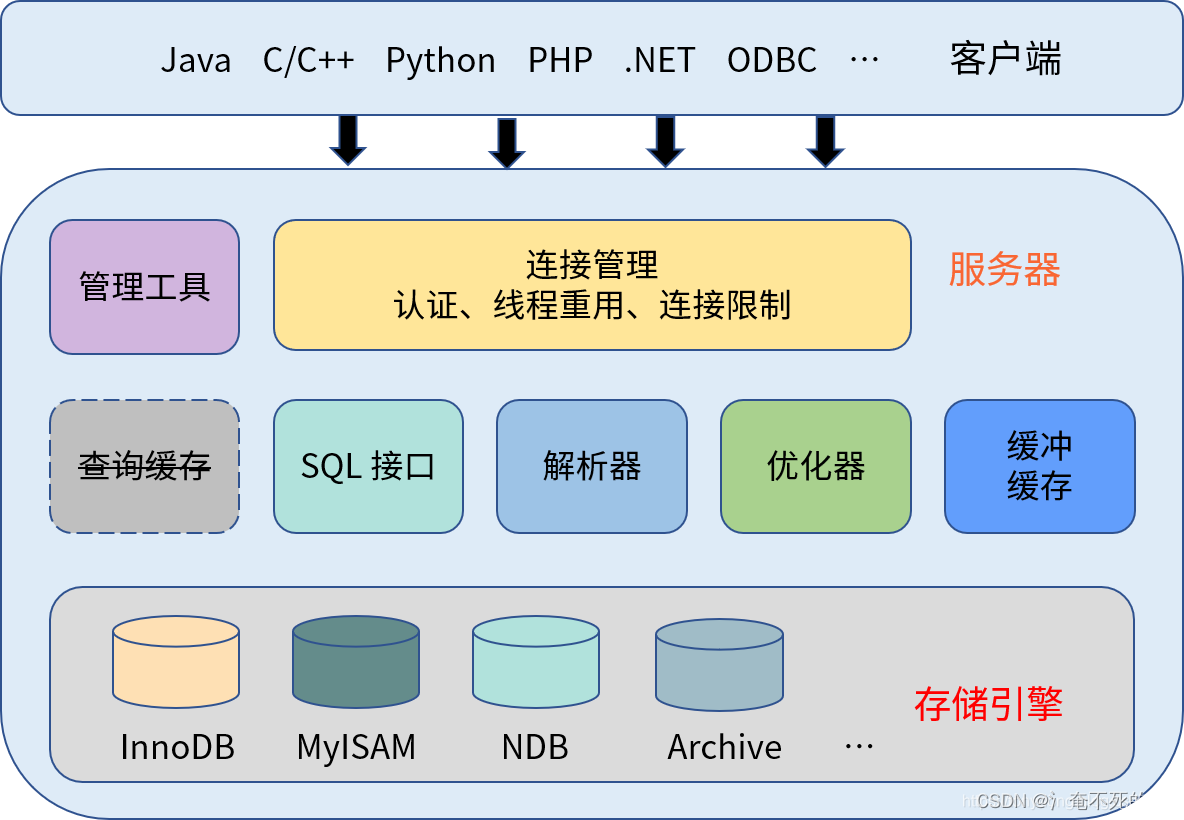
具体来说,每个组件的作用如下:
客户端,连接 MySQL 服务器的各种工具和应用程序。例如 mysql 命令行工具、mysqladmin 以及各种驱动程序等。
连接管理,负责监听和管理客户端的连接以及线程处理等。每一个连接到 MySQL 服务器的请求都会被分配一个连接线程。连接线程负责与客户端的通信,接受客户端发送的命令并且返回服务器处理的结果。
查询缓存 ,用于将执行过的 SELECT 语句和结果缓存在内存中。每次执行查询之前判断是否命中缓存,如果命中直接返回缓存的结果。缓存命中需要满足许多条件,SQL 语句完全相同,上下文环境相同等。实际上除非是只读应用,查询缓存的失效频率非常高,任何对表的修改都会导致缓存失效;因此,查询缓存在 MySQL 8.0 中已经被删除。
SQL 接口,接收客户端发送的各种 DML和 DDL 命令,并且返回用户查询的结果。另外还包括所有的内置函数(日期、时间、数学以及加密函数)和跨存储引擎的功能,例如存储过程、触发器、视图等。
解析器,对 SQL 语句进行解析,例如语义和语法的分析和检查,以及对象访问权限检查等。
优化器,利用数据库的统计信息决定 SQL 语句的最佳执行方式。使用索引还是全表扫描的方式访问单个表,多表连接的实现方式等。优化器是决定查询性能的关键组件,而数据库的统计信息是优化器判断的基础。
缓存与缓冲,由一系列缓存组成的,例如数据缓存、索引缓存以及对象权限缓存等。对于已经访问过的磁盘数据,在缓冲区中进行缓存;下次访问时可以直接读取内存中的数据,从而减少磁盘 IO。(查询缓存和缓冲不是一个东西)
存储引擎,存储引擎是对底层物理数据执行实际操作的组件,为服务器层提供各种操作数据的 API。MySQL 支持插件式的存储引擎,包括 InnoDB、MyISAM、Memory 等。
MYSQL执行流程
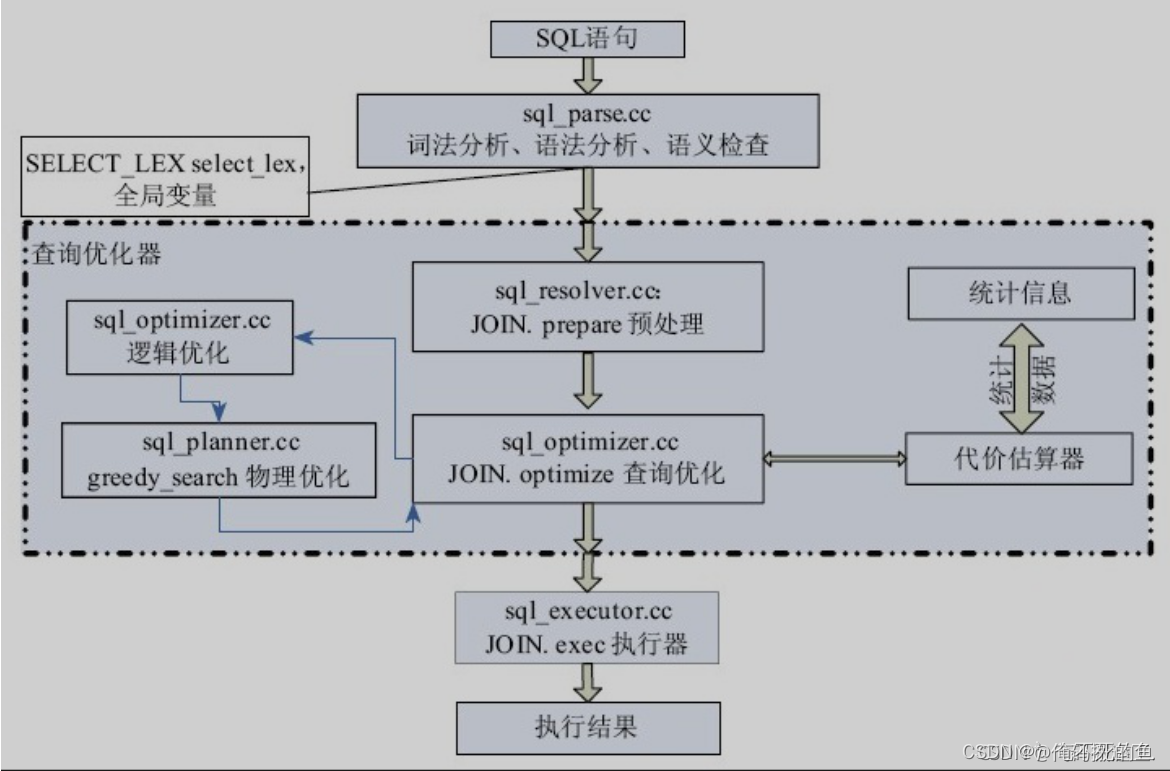
优化器
MySQL 查询优化器又叫成本优化器,使用基于成本的优化方式(Cost-based Optimization),以 SQL 语句作为输入,利用内置的成本模型和数据字典信息以及存储引擎的统计信息决定使用哪些步骤执行查询语句。
查询优化和地图导航的概念非常相似,我们通常只需要输入想要的结果(目的地),优化器负责找到最有效的实现方式(最佳路线)。需要注意的是,导航并不一定总是返回最快的路线,因为系统获得的交通数据并不可能是绝对准确的;与此类似,优化器也是基于特定模型、各种配置和统计信息进行选择,因此也不可能总是获得最佳执行
注意:mysql的优化器是基于查询成本的优化,不是基于查询时间的优化。
从高层次来说,MySQL Server 可以分为两部分:服务器层以及存储引擎层。其中,优化器工作在服务器层,位于存储引擎 API 之上。优化器的工作过程从语义上可以分为三个阶段:
- 逻辑转换,包括否定消除、等值传递和常量传递、常量表达式求值、外连接转换为内连接、子查询转换、视图合并等;
- 基于成本优化,包括访问方法和连接顺序的选择等;
- 执行计划改进,例如表条件下推、访问方法调整、排序避免以及索引条件下推。
逻辑转换
MySQL 优化器首先可能会以不影响结果的方式对查询进行转换,转换的目标是尝试消除某些操作从而更快地执行查询。
mysql> explain select * from user where id >1 and 1=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
1 row in set, 1 warning (0.02 sec)
mysql> show warnings;
+-------+------+--------------------------------------------------------------------------------------------
| Level | Code | Message|
+-------+------+--------------------------------------------------------------------------------------------
| Note | 1003 | /* select#1 */ select `test`.`user`.`id` AS `id`,`test`.`user`.`name` AS `name`,`test`.`user`.`age` AS `age`,`test`.`user`.`address` AS `address`,`test`.`user`.`birthday` AS `birthday` from `test`.`user` where (`test`.`user`.`id` > 1) |
+-------+------+--------------------------------------------------------------------------------------------
1 row in set (0.01 sec)
显然,查询条件中的 1=1 是完全多余的。没有必要为每一行数据都执行一次计算;删除这个条件也不会影响最终的结果。执行EXPLAIN语句之后,通过SHOW WARNINGS命令可以查看逻辑转换之后的 SQL 语句,从上面的结果可以看出 1=1 已经不存在了。
优化器和索引提示
子查询如递归函数一样,有时侯能达到事半功倍的效果,但是其执行效率较低。与表连接相比,子查询比较灵活,方便,形式多样,适合作为查询的筛选条件,而表连接更适合查看多表的数据。
一般情况下,子查询会产生笛卡儿积,表连接的效率要高于子查询。因此在编写 SQL 语句时应尽量使用连接查询。
表连接(内连接和外连接等)都可以用子查询替换,但反过来却不一定,有的子查询不能用表连接来替换。下面我们介绍哪些子查询的查询命令可以改写为表连接。
在检查那些倾向于编写成子查询的查询语句时,可以考虑将子查询替换为表连接,看看连接的效率是不是比子查询更好些。同样,如果某条使用子查询的 SELECT 语句需要花费很长时间才能执行完毕,那么可以尝试把它改写为表连接,看看执行效果是否有所改善。
优化器一般会将子查询优化成为连接查询。
explain SELECT
*
FROM
app_user
WHERE
app_user.KEY IN ( SELECT app_user_copy1.`key` FROM app_user_copy1 WHERE app_user.age = 18 AND app_user.id > app_user_copy1.id );
show WARNINGS;
select * from `test_bai`.`app_user` semi join (`test_bai`.`app_user_copy1`) on ((`test_bai`.`app_user_copy1`.`key` = `test_bai`.`app_user`.`key`) and (`test_bai`.`app_user`.`age` = 18) and (`test_bai`.`app_user`.`id` < `test_bai`.`app_user_copy1`.`id`))
外连接转换为内连接
在查询优化的过程中,内连接的表之间的连接顺序可以随意交换,where或on条件中只涉及单表的条件可以下推到表上作为表的过滤条件;而对于外连接来说,表的连接顺序不能随意交换,约束条件也不能随意的下推。如果可以将外连接转换为内连接,那么就可以简化查询优化过程。
外连接可转为内连接需满足的条件
为了描述方便,引入两个名词:
不空侧:外连接中所有数据都被输出的一侧。比如:左外连接的左表、右外连接的右表
可空侧:外连接中会被补空值的一侧。比如:左外连接的右表、右外连接的左表、全外连接的左表和右表
只要满足以下条件之一,就可以将外连接转换为内连接:
Where条件中有“严格”的约束条件,且该约束条件中引用了可空侧的表中列。这样,该谓词便可以将可空侧产生的空值都过滤掉了,使得最终结果等同于内连接。
explain select * from app_user left join app_user_copy1 on app_user.`key` = app_user_copy1.`key`
where app_user.age = 18 and app_user_copy1.id is not null;
优化后,变为内连
show WARNINGS;
\/* select#1 */ select `test_bai`.`app_user`.`id` AS `id`,`test_bai`.`app_user`.`name` AS `name`,`test_bai`.`app_user`.`email` AS `email`,`test_bai`.`app_user`.`phone` AS `phone`,`test_bai`.`app_user`.`gender` AS `gender`,`test_bai`.`app_user`.`password` AS `password`,`test_bai`.`app_user`.`age` AS `age`,`test_bai`.`app_user`.`create_time` AS `create_time`,`test_bai`.`app_user`.`update_time` AS `update_time`,`test_bai`.`app_user`.`key` AS `key`,`test_bai`.`app_user_copy1`.`id` AS `id`,`test_bai`.`app_user_copy1`.`name` AS `name`,`test_bai`.`app_user_copy1`.`email` AS `email`,`test_bai`.`app_user_copy1`.`phone` AS `phone`,`test_bai`.`app_user_copy1`.`gender` AS `gender`,`test_bai`.`app_user_copy1`.`password` AS `password`,`test_bai`.`app_user_copy1`.`age` AS `age`,`test_bai`.`app_user_copy1`.`create_time` AS `create_time`,`test_bai`.`app_user_copy1`.`update_time` AS `update_time`,`test_bai`.`app_user_copy1`.`key` AS `key` from `test_bai`.`app_user` join `test_bai`.`app_user_copy1` where ((`test_bai`.`app_user_copy1`.`key` = `test_bai`.`app_user`.`key`) and (`test_bai`.`app_user`.`age` = 18) and (`test_bai`.`app_user_copy1`.`id` is not null))
On连接条件中,如果不空侧列中的值是可空侧列的子集,且可空侧的值都不为NULL。典型的,不空侧的列为外键,可空侧的列为主键,且两者之间是主外键参考关系。
基于成本的优化
在真正执行一条查询语句之前,MYSQL的优化器会找出所有可以用来执行该语句的方案,并在对比这些方案后找出成本最低的方案。这个成本最低的方案就是所谓的执行计划。之后才会调用存储引擎提供的接口真正执行查询。总结一下,过程如下:
1、根据搜索条件,找出所有可能使用的索引。
2、计算全表扫描的代价。
3、计算使用不同索引执行查询的代价。
4、对比各种方案的代价,找出成本最低的方案。
为了找到最佳执行计划,优化器需要比较不同的查询方案。随着查询中表的数量增加,可能的执行计划会呈现指数级增长;MySQL里限制一个查询的join表数目上限为61,对于一个有61个表参与的join操作,理论上需要61!(阶乘)次的评估。
所以优化器不可能遍历所有的执行方案,一种更灵活的优化方法是允许用户控制优化器在查找最佳查询计划时的遍历程度。一般来说,优化器评估的计划越少,则编译查询所花费的时间就越少;但另一方面,由于优化器忽略了一些计划,因此可能找到的不是最佳计划。
控制优化程度
MySQL 提供了两个系统变量,可以用于控制优化器的优化程度:
optimizer_search_depth,优化器查找的深度。如果该参数大于查询中表的数量,可以得到更好的执行计划,但是优化时间更长;如果小于表的数量,可以更快完成优化,但可能获得的不是最优计划。该参数的默认值为 62;如果不确定是否合适,可以将其设置为 0,让优化器自动决定搜索的深度。
optimizer_prune_level, 告诉优化器根据对每个表访问的行数的估计跳过某些方案,这种启发式的方法可以极大地减少优化时间而且很少丢失最佳计划。因此,该参数的默认设置为 1(开启);如果确认优化器错过了最佳计划,可以将该参数设置为 0,不过这样可能导致优化时间的增加。
show variables like '%optimizer_prune_level%';
成本常量
一直在提成本,那么这个代价(成本)是怎么评估的呢?分为两个部分:
- IO成本:MySQL 读取一个页面的成本。
- CPU成本:CPU检测一条记录是否符合搜索条件的成本。
**总成本=IO成本+CPU成本
**上可以看出,我们需要三种数据:
核算IO成本需要读取的页面数量
核算CPU成本需要对比的记录数
每种操作对应的成本常量系数
我们来说说这些成本常量系数,成本常量可以通过 mysql 系统数据库中的 server_cost 和 engine_cost 两个表进行查询和设置。
select * from mysql.server_cost;
cost_name |cost_value|last_update |comment|default_value|
----------------------------|----------|-------------------|-------|-------------|
disk_temptable_create_cost | |2018-05-17 10:12:12| | 10.0|
disk_temptable_row_cost | |2018-05-17 10:12:12| | 1|
key_compare_cost | |2018-05-17 10:12:12| | 0.1|
memory_temptable_create_cost| |2018-05-17 10:12:12| | 2.0|
memory_temptable_row_cost | |2018-05-17 10:12:12| | 0.2|
row_evaluate_cost | |2018-05-17 10:12:12| | 0.2|
server_cost 中存储的是常规服务器操作的成本估计值:
cost_value 为空表示使用 default_value,其中:
disk_temptable_create_cost 和 disk_temptable_row_cost 代表了在基于磁盘的存储引擎(InnoDB 或 MyISAM)中使用内部临时表的评估成本。增加这些值会使得优化器倾向于较少使用内部临时表的查询计划。(group by / distinct等建立临时表)
key_compare_cost 代表了比较记录键的评估成本。增加该值将导致需要比较多个键值的查询计划变得更加昂贵。例如,执行 filesort 排序的查询计划比通过索引避免排序的查询计划相对更加昂贵。
memory_temptable_create_cost 和 memory_temptable_row_cost 代表了在 MEMORY 存储引擎中使用内部临时表的评估成本。增加这些值会使得优化器倾向于较少使用内部临时表的查询计划。
row_evaluate_cost 代表了计算记录条件的评估成本。增加该值会导致检查许多数据行的查询计划变得更加昂贵。例如,与读取少量数据行的索引范围扫描相比,全表扫描变得相对昂贵。
engine_cost 中存储的是特定存储引擎相关操作的成本估计值:
select * from mysql.engine_cost;
engine_name|device_type|cost_name |cost_value|last_update |comment|default_value|
-----------|-----------|----------------------|----------|-------------------|-------|-------------|
default | 0|io_block_read_cost | |2018-05-17 10:12:12| | 1.0|
default | 0|memory_block_read_cost| |2018-05-17 10:12:12| | 0.25|
engine_name 表示存储引擎,“default”表示所有存储引擎,也可以为不同的存储引擎插入特定的数据。cost_value 为空表示使用 default_value。其中,
io_block_read_cost 代表了从磁盘读取索引或数据块的成本。增加该值会使读取许多磁盘块的查询计划变得更加昂贵。例如,与读取较少块的索引范围扫描相比,全表扫描变得相对昂贵。
memory_block_read_cost 表示从数据库缓冲区读取索引或数据块的成本。
例 子:
**1、**我们来看一个例子,执行以下语句:
mysql> explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
+ -------------------------------------------------------------------- +
| EXPLAIN |
+ -------------------------------------------------------------------- +
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "9822.60"
},
"table": {
"table_name": "user",
"access_type": "ALL",
"possible_keys": [
"index_birthday"
],
"rows_examined_per_scan": 48308,
"rows_produced_per_join": 18209,
"filtered": "37.70",
"cost_info": {
"read_cost": "6180.60",
"eval_cost": "3642.00",
"prefix_cost": "9822.60",
"data_read_per_join": "14M"
},
"used_columns": [
"id",
"sex",
"name",
"age",
"birthday"
],
"attached_condition": "(`test`.`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
}
}
查询计划显示使用了全表扫描(access_type = ALL),而没有选择 index_birthday。可以在上面看到全表扫描的成本是9822.6,这个值是怎么来的呢?这就得提到MYSQL为每个表维护的一系列的统计信息了。可以通过SHOW TABLE STATUS查看表的统计信息。
查看表 user 的统计信息(show table status like ‘user’;):
Rows:表中的记录条数。对于MyISAM存储引擎,该值是准确的;对于InnoDB,该值是一个估值。
Data_length:表占用的存储空间字节数。对于MyISAM存储引擎,该值就是数据文件的大小;对于InnoDB引擎,该值就相当于聚簇索引占用的存储空间的大小。所以对于使用InnoDB引擎的表,Data_length = 聚簇索引的页面数量 * 每个页面的大小(默认16k)。
再来算一下上面的全表扫描的总成本9822.6怎么来的:
聚簇索引的页面数量(IO读取的页面数量) = 2637824 ÷ 16 ÷ 1024 = 161
I/O成本:161 * 1.0 = 161
CPU成本:48308 * 0.2 = 9661.6
总成本:161 + 9661.6 = 9822.6
再看为什么没有选择 index_birthday索引呢?可以通过优化器跟踪可以看到具体原因。
优化器跟踪(optimizer_trace):从MySQL5.6版本开始,optimizer_trace 可支持把MySQL查询执行计划树打印出来,对深入分析SQL执行计划,COST成本都非常有用,打印的内部信息比较全面。):从MySQL5.6版本开始,optimizer_trace 可支持把MySQL查询执行计划树打印出来,对深入分析SQL执行计划,COST成本都非常有用,打印的内部信息比较全面。
优化器跟踪输出主要包含了三个部分: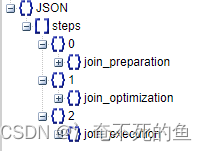
join_preparation,准备阶段,返回了字段名扩展之后的 SQL 语句。对于 1=1 这种多余的条件,也会在这个步骤被删除。
join_optimization,优化阶段。其中 condition_processing 中包含了各种逻辑转换,经过等值传递之后将条件 id=age 转换为了 age=1。另外 constant_propagation 表示常量传递,trivial_condition_removal 表示无效条件移除。
join_execution,执行阶段。
开启optimizer_trace:
mysql> SET optimizer_trace="enabled=on";
Query OK, 0 rows affected (0.00 sec)
使用优化器跟踪查看:
mysql> select * from information_schema.optimizer_trace\G
*************************** 1. row ***************************
QUERY: explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `user`.`id` AS `id`,`user`.`sex` AS `sex`,`user`.`name` AS `name`,`user`.`age` AS `age`,`user`.`birthday` AS `birthday` from `user` where (`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`user`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
"rows_estimation": [
{
"table": "`user`",
"range_analysis": {
"table_scan": {
"rows": 48308,
"cost": 9824.7
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_name",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_birthday",
"usable": true,
"key_parts": [
"birthday",
"id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_birthday",
"ranges": [
"0x21a00f <= birthday <= 0x61c90f"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 18210,
"cost": 21853,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`user`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 48308,
"access_type": "scan",
"resulting_rows": 18210,
"cost": 9822.6,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 18210,
"cost_for_plan": 9822.6,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`user`",
"attached": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"refine_plan": [
{
"table": "`user`"
}
]
}
]
}
},
{
"join_explain": {
"select#": 1,
"steps": [
]
}
}
]
}
使用全表扫描的总成本为9822.60,使用范围扫描的总成本为 21853。这是因为查询返回了 user表中大部分的数据,通过索引范围扫描,然后再回表反而会比直接扫描表更慢。
**2、**接下来我们将数据行比较的成本常量 row_evaluate_cost 从 0.2 改为 1,并且刷新内存中的值:
update mysql.server_cost
set cost_value=1
where cost_name='row_evaluate_cost';
flush optimizer_costs;
然后重新连接数据库,再次获取执行计划的结果如下:
mysql> explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
+ -------------------------------------------------------------------- +
| EXPLAIN |
+ -------------------------------------------------------------------- +
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "54631.01"
},
"table": {
"table_name": "user",
"access_type": "range",
"possible_keys": [
"index_birthday"
],
"key": "index_birthday",
"used_key_parts": [
"birthday"
],
"key_length": "4",
"rows_examined_per_scan": 18210,
"rows_produced_per_join": 18210,
"filtered": "100.00",
"index_condition": "(`test`.`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"cost_info": {
"read_cost": "36421.01",
"eval_cost": "18210.00",
"prefix_cost": "54631.01",
"data_read_per_join": "14M"
},
"used_columns": [
"id",
"sex",
"name",
"age",
"birthday"
]
}
}
}
此时,优化器选择的范围扫描(access_type = range),虽然它的成本增加,但是使用全表扫描的代价更高。
row_evaluate_cost 的还原成默认设置并重新连接数据库:
优化器和索引提示
虽然通过系统变量 optimizer_switch 可以控制优化器的优化策略,但是一旦改变它的值,后续的查询都会受到影响,除非再次进行设置。
另一种控制优化器策略的方法就是优化器提示(Optimizer Hint)和索引提示(Index Hint),它们只对单个语句有效,而且优先级比 optimizer_switch 更高。
优化器提示使用 /*+ … */ 注释风格的语法,可以对连接顺序、表访问方式、索引使用方式、子查询、语句执行时间限制、系统变量以及资源组等进行语句级别的设置。
例如,在没有使用优化器提示的情况下: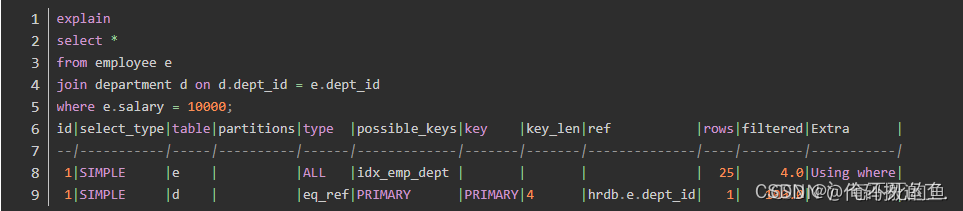
优化器选择 employee 作为驱动表,并且使用全表扫描返回 salary = 10000 的数据;然后通过主键查找 department 中的记录。
然后我们通过优化器提示 join_order 修改两个表的连接顺序: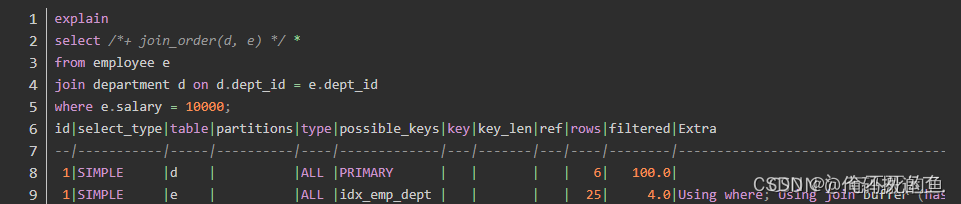
此时,优化器选择了 department 作为驱动表;同时访问 employee 时选择了全表扫描。我们可以再增加一个索引相关的优化器提示 index: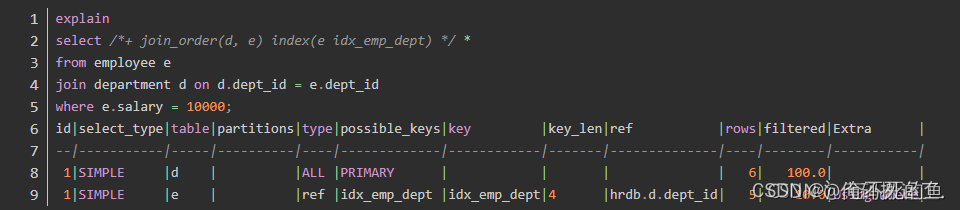
最终,优化器选择了通过索引 idx_emp_dept 查找 employee 中的数据。
其他还有很多,比如 USE INDEX 提示优化器使用某个索引,IGNORE INDEX 提示优化器忽略某个索引,FORCE INDEX 强制使用某个索引。。。。等等。
小表驱动大表
为什么要用小表驱动大表
MySQL 表关联的算法是 Nest Loop Join
NLJ是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法:
1、Simple Nested Loop Join(SNLJ)
// 伪代码
for (r in R) {
for (s in S) {
if (r satisfy condition s) {
output <r, s>;
}
}
}
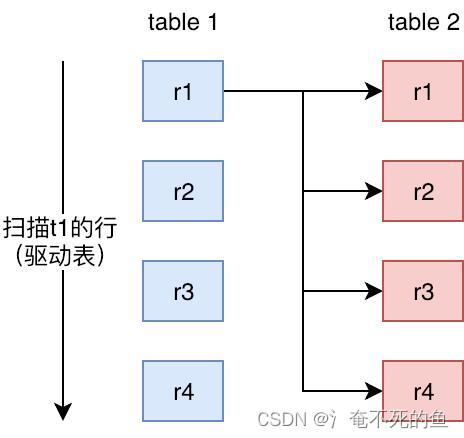
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时。(合关联子查询耗费相同,一般不可能采用这种方式进行join)
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 * 1万 =1亿次,这种查询效率会非常慢。
2、Index Nested Loop Join(INLJ)
// 伪代码
for (r in R) {
for (si in SIndex) {
if (r satisfy condition si) {
output <r, s>;
}
}
}
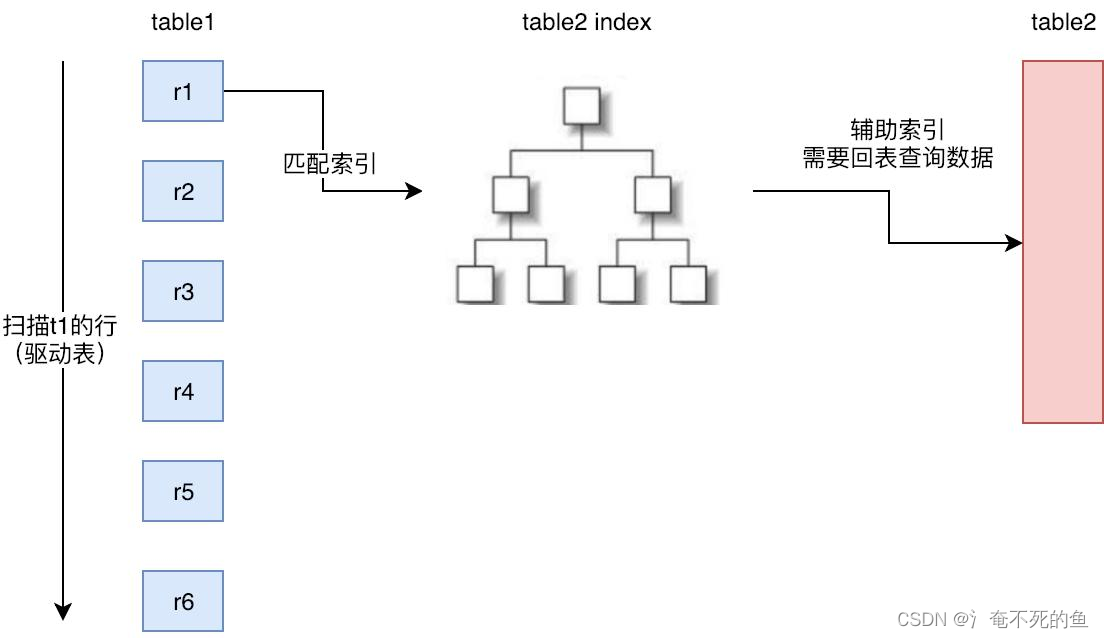
NLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
- 索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能:
**原来的匹配次数 = 外层表行数 * 内层表行数
**优化后的匹配次数= 外层表的行数 * 内层表索引的高度
- 使用场景:只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接。
- 由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作。
3、Block Nested Loop Join(BNLJ)
- 缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了外层循环的次数。
- 当不使用Index Nested-Loop Join的时候,默认使用Block Nested-Loop Join。
- 即使使用了join buffer也是减少了外循环次数,减少内循环的io次数,但是记录记录之间的连接条件比较(cpu计算)次数还是不能少的,因此如果连接值不是索引,并且表的数据量较大,那么将会是灾难
// 伪代码
for (r in R) {
for (sbu in SBuffer) {
if (r satisfy condition sbu) {
output <r, s>;
}
}
}
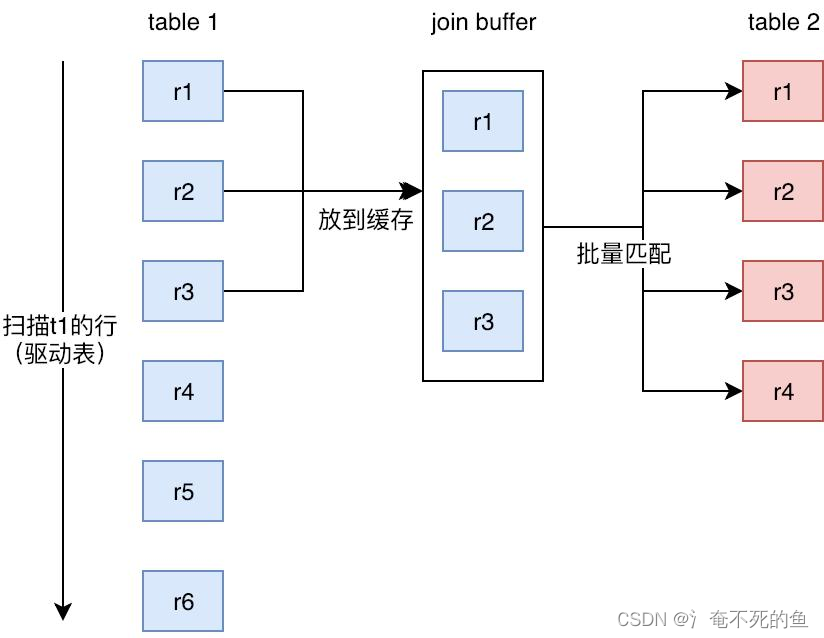
什么是Join Buffer?
(1)Join Buffer会缓存所有参与查询的列而不是只有Join的列。
(2)可以通过调整join_buffer_size缓存大小
(3)join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
(4)使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。(5)这里猜测joinbuf存储的数据,是类似map一样的映射。即在内循环时获取
如何优化JOIN速度
- 用小结果集驱动大结果集,减少外层循环的数据量:
如果小结果集和大结果集连接的列都是索引列,mysql在内连接时也会选择用小结果集驱动大结果集,因为索引查询的成本是比较固定的,这时候外层的循环越少,join的速度便越快。 - 为匹配的条件增加索引:争取使用INLJ,减少内层表的循环次数
- 增大join buffer size的大小:当使用BNLJ时,一次缓存的数据越多,那么外层表循环的次数就越少
- 减少不必要的字段查询:
(1)当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,外层表的循环次数就越少;
(2)当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度。(未经验证,只是一个推论)
排序: 根据驱动表的字段排序
对驱动表可以直接排序,对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序(既废内存,又废cpu)!
执行计划改进
ICP(Index Condition Pushdown) - 索引条件下推
索引条件下推,也叫索引下推,英文全称Index Condition Pushdown,简称ICP。
索引下推是MySQL5.6新添加的特性,用于优化数据的查询。
在MySQL5.6之前,通过使用非主键索引进行查询的时候,存储引擎通过索引查询数据,然后将结果返回给MySQL server层,在server层判断是否符合条件。
在MySQL5.6及以上版本,可以使用索引下推的特性。当存在索引的列做为判断条件时,MySQL server将这一部分判断条件传递给存储引擎,然后存储引擎会筛选出符合MySQL server传递条件的索引项,即在存储引擎层根据索引条件过滤掉不符合条件的索引项,然后回表查询得到结果,将结果返回给MySQL server。
可以看到,有了索引下推的优化,在满足一定的条件下,存储引擎层会在回表查询之前对数据进行过滤,可以减少存储引擎回表查询的次数。
举个例子
假设有一张用户信息表user_info,有三个字段name, level, weapon(装备),建立联合索引(name, level),user_info表初始数据如下:
| id | name | level | weapon |
|---|---|---|---|
| 1 | 大彬 | 1 | 键盘 |
| 2 | 盖聂 | 2 | 渊虹 |
| 3 | 卫庄 | 3 | 鲨齿 |
| 4 | 大铁锤 | 4 | 铁锤 |
假如需要匹配姓名第一个字为"大",并且level为1的用户,SQL语句如下:
SELECT * FROM user_info WHERE name LIKE "大%" AND level = 1;
那么这条SQL具体会怎么执行呢?
下面分情况进行分析。
先来看看MySQL5.6以前的版本。
前面提到MySQL5.6以前的版本没有索引下推,其执行过程如下: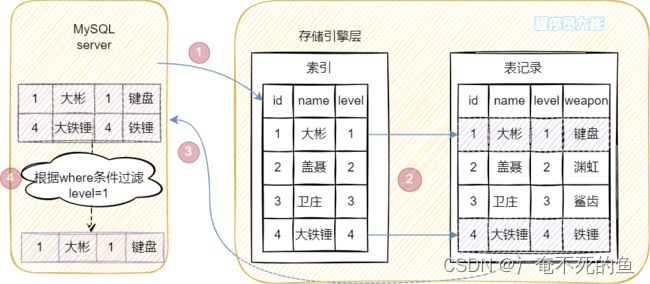
查询条件name LIKE 不是等值匹配,根据最左匹配原则,在(name, level)索引树上只用到name去匹配,查找到两条记录(id为1和4),拿到这两条记录的id分别回表查询,然后将结果返回给MySQL server,在MySQL server层进行level字段的判断。整个过程需要回表2次。
然后看看MySQL5.6及以上版本的执行过程,如下图。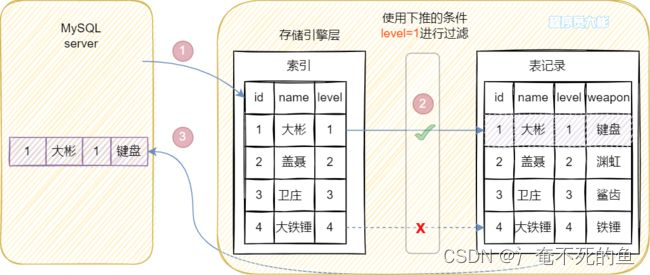
相比5.6以前的版本,多了索引下推的优化,在索引遍历过程中,对索引中的字段先做判断,过滤掉不符合条件的索引项,也就是判断level是否等于1,level不为1则直接跳过。因此在(name, level)索引树只匹配一个记录,之后拿着此记录对应的id(id=1)回表查询全部数据,整个过程回表1次。
可以使用explain查看是否使用索引下推,当Extra列的值为Using index condition,则表示使用了索引下推。
总结
从上面的例子可以看出,使用索引下推在某些场景下可以有效减少回表次数,从而提高查询效率。
排序避免
实际上就是在根据条件查询时,因为索引时有序的,如果条件有序那么直接可以根据索引的读取顺序作为排序结果。而不需要额外排序
例子
-- key有索引
explain select * from app_user where app_user.age < 1999 order by app_user.key -- Using filesort
explain select * from app_user where app_user.key < 1999 order by app_user.key -- 避免排序
我们知道 sql 语言中,用户不能显示地命令数据库进行排序操作。对用户隐藏这样操作正式SQL的设计思想。但数据库有些命令会对结果进行排序,当数据量较大时,排序会非常耗时。本文我们讨论如何避免无谓的排序,提升SQL执行效率。
MySQL 支持两种排序方式 filesort 和 index, Using index 是扫描索引完成的排序,而 Using filesort 是利用内存甚至磁盘完成排序的。因此,index 效率高,filesort 效率低。
会进行排序的SQL 命令
- GROUP BY 子句
- ORDER BY 子句
- 聚合函数(SUM,COUNT,AVG,MAX,MIN)
- DISTINCT
- 集合运算(UNICON,INTERSECT,EXCEPT)
- 窗口函数(RANK,ROW_NUMBER等)
排序和分组的优化其实是十分像的,本质是先排序后分组,遵循索引创建顺序的最左匹配原则。因此,这里以排序为例。
explain select app_user.age from app_user where app_user.age < 1999 group by app_user.age -- Using filesort
边栏推荐
- Ruichengxin micro sprint technology innovation board: annual revenue of 367million, proposed to raise 1.3 billion, Datang Telecom is a shareholder
- R语言使用dplyr包的mutate函数对指定数据列进行标准化处理(使用mean函数和sd函数)并基于分组变量计算标准化后的目标变量的分组均值
- File creation, writing, reading, deletion (transfer) in go language
- Gorm data insertion (transfer)
- 吃透Chisel语言.08.Chisel基础(五)——Wire、Reg和IO,以及如何理解Chisel生成硬件
- golang fmt. Printf() (turn)
- MongoDB常用28条查询语句(转)
- 吃透Chisel语言.05.Chisel基础(二)——组合电路与运算符
- The game goes to sea and operates globally
- Haobo medical sprint technology innovation board: annual revenue of 260million Yonggang and Shen Zhiqun are the actual controllers
猜你喜欢
TestSuite and testrunner in unittest
【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
Unity Shader学习(三)试着绘制一个圆
为什么图片传输要使用base64编码

205. 同构字符串
安装Mysql

Applet live + e-commerce, if you want to be a new retail e-commerce, use it!
Understand chisel language thoroughly 11. Chisel project construction, operation and test (III) -- scalatest of chisel test
MATLAB中tiledlayout函数使用
瑞吉外卖笔记
随机推荐
Use the default route as the route to the Internet
Yingshi Ruida rushes to the scientific and Technological Innovation Board: the annual revenue is 450million and the proposed fund-raising is 979million
LifeCycle
按照功能对Boost库进行分类
Understand chisel language thoroughly 09. Chisel project construction, operation and testing (I) -- build and run chisel project with SBT
What is the real meaning and purpose of doing things, and what do you really want
Deming Lee listed on Shenzhen Stock Exchange: the market value is 3.1 billion, which is the husband and wife of Li Hu and Tian Hua
Excel快速合并多行数据
吃透Chisel语言.07.Chisel基础(四)——Bundle和Vec
自主工业软件的创新与发展
基于PaddleX的智能零售柜商品识别
[antd] how to set antd in form There is input in item Get input when gourp Value of each input of gourp
Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
常见 content-type对应表
Assertion of unittest framework
海外游戏代投需要注意的
JVM memory layout detailed, illustrated, well written!
学习项目是自己找的,成长机会是自己创造的
Idea shortcut keys
吃透Chisel语言.05.Chisel基础(二)——组合电路与运算符