当前位置:网站首页>基于PaddleX的智能零售柜商品识别
基于PaddleX的智能零售柜商品识别
2022-07-04 12:50:00 【小段学长】
摘 要
在传统的零售柜中,实现自动识别的方法主要有:硬件分隔、根据重量判断、识别顾客的行为、射频识别标记等。本文基于深度学习在图像分类领域的优异性能,研究基于PaddleX的智能零售柜商品识别,相比于人工扫商品的条码或者顾客自主机器扫码、以及上述各种自动识别的方式效率更高,本实验借鉴原有项目,在使用PaddleX进行模型训练的过程中,检测模型使用PPYolo或者YOLOv3。骨干网络采用ResNet50,训练较为草率,效果并非那么明显。
关键词 图像分类;PaddleX;卷积神经网络;特征学习;图像识别
引言
随着我国经济的快速发展,国民可支配收入水平也在不断提高,人们对购物的关注点慢慢从价格转移到了消费过程的体验和感受。然而,无论是大型超市,还是小型便利店,在居民密集区以及消费高峰时段(如周末)总是会出现结算排队的现象,这无疑使消费者的购物体验大打折扣。要缓解结算排队现象,则需要增加收银人员,增设结算通道,该解决方案人工成本的增加过于昂贵。自助扫码结算技术的出现解决了人工成本增加的问题,但是本质上该技术只是将扫描条形码的操作由收银员完成转移到了由消费者完成。在这个过程中,顾客可能遇到扫描条码失败,无法完成结算等问题,使购物结算耗费更多时间。因此,该技术依然存在操作复杂,结算效率低等问题。将一些先进技术手段,如大数据,人工智能等运用到商品的销售过程中来,改变传统的扫条形码的结算方式,打造“新零售”,成为了一种不可避免的趋势。
近年来,国内外陆续出现了一些自动化零售商店,无人便利店等,如京东便利店,阿里巴巴无人超市,这表明使用人工智能来对商品的销售过程进行改造,实现零售场景的自动化,无人化已成为人工智能领域的热点之一。与新零售相比,传统零售人工参与的过程较多,自动化程度低,导致成本过高,同时服务的效率和体验的舒适感低。计算机视觉的发展使得商品识别技术日益成熟,使用基于图像的商品识别技术可以提高自动化程度,减少成本,提高效率,因此,设计和研发一种基于计算机视觉的批量商品自动识别与结算系统,具有重要的研究和应用价值。
目标检测作为图像处理和计算机视觉的一个重要分支,在许多领域得到了广泛的应用。智能零售柜作为智能零售系统的典型代表,可以在无售货员状态下提供自动化销售服务。在传统的零售柜中,实现自动识别的方法主要有:硬件分隔、根据重量判断、识别顾客的行为、射频识别标记等。这些传统的方法成本高,降低了柜子的空间利用率,限制商品种类。采用商品识别技术,相比于人工扫商品的条码或者顾客自主机器扫码、以及上述各种自动识别的方式效率更高,商店也能因此提高盈利,对于顾客也能减少顾客排队等待时间,消费过程更加便捷。
在此,商品检测,即获取商品在图像中的具体位置坐标。在商品识别系统中,商品识别任务建立在商品检测任务上,当一张图像中包含多个商品,只有先获取商品在图像中的位置后,才能利用识别算法获取其类别。如果商品检测的准确率高,区域精准,那么送入识别算法的图像便排除了许多背景干扰,提升了商品识别的准确率。目标检测算法用于将图像中所有感兴趣的物体找出,即确定该物体在图像中所处的位置,一般用矩形框来表示,同时对矩形框内的物体进行分类,确定其类别,这是计算机视觉领域的核心问题之一。我们可以利用目标检测算法来完成商品检测任务,但各种商品的外观,形状都不相同,顾客放置在结算台上的状态也千奇百怪,还存在光照,遮挡等影响因素,这些使得商品检测成为了极具挑战性的问题。
项目拟使用的方法:借鉴原有项目,在使用PaddleX进行模型训练的过程中,检测模型使用PPYolo或者YOLOv3。骨干网络采用ResNet50。数据集总数据量为5422张,共有113类商品,属于多分类问题。
1.PaddleX简介
PaddleX 集成智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
PaddleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
整体来说PaddleX具备如下三大优势:
一、全流程打通将深度学习开发从数据接入、模型训练、参数调优、模型评估、预测部署全流程打通,省去了对各环节间串连的代码开发与脚本调用,极大地提升了开发效率。
二、开源技术内核集成了PaddleCV领先的视觉算法和面向任务的开发套件、预训练模型应用工具PaddleHub、可视化分析工具VisualDL、模型压缩工具PaddleSlim等技术能力于一身,并提供简明易懂的Python API,实现完全开源开放,易于集成和二次开发,为您的业务实践全程助力。
三、产业深度兼容高度兼容Windows、Mac、Linux系统,同时支持NVIDIA GPU加速深度学习训练。本地开发、保证数据安全,高度符合产业应用的实际需求。
2.YOLO简介
YOLO是“You Only Look Once”的简称,它虽然不是最精确的算法,但在精确度和速度之间选择的折中,效果也是相当不错。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测精度,尤其对于小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。
YOLOv3仅使用卷积层,使其成为一个全卷积网络(FCN)。文章中,作者提出一个新的特征提取网络,Darknet-53。正如其名,它包含53个卷积层,每个后面跟随着batch normalization层和leaky ReLU层。没有池化层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,这样可以有效阻止由于池化层导致的低层级特征的损失。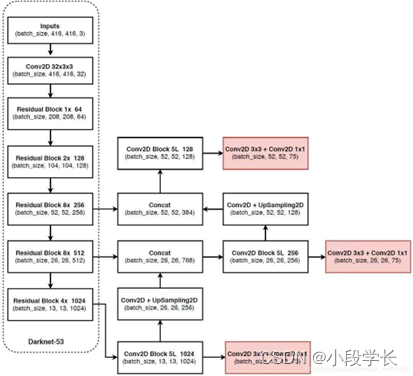
3.数据预处理
采集的数据处于稳定的光源下,图像的照明充足,图像质量极佳,但在实际的应用场景中,光照环境十分复杂,实验室内布置的环境无法完全模拟实际环境中的光照,因此我们需要对输入的图像进行预处理。除了对图像进行归一化处理,还进行了镜像翻转操作等数据增强操作,最重要的是对图像的亮度,饱和度等进行了调整,以模拟外界复杂的光照环境,增强模型对光照变换的鲁棒性。
数据集分为训练数据集、训练商品库。训练数据集包含图片数据及标注信息。图片数据集为密集商品图片,尺寸960x720,格式为jpg。数据集采用VOC格式,符合大多深度学习开发套件对数据集格式的要求,可满足paddlex或PaddleDetection的训练要求。本数据集总数据量为5422张,且所有图片均已标注,共有113类商品。本数据集以对数据集进行划分,其中训练集3796张、验证集1084张、测试集542张,部分如下图所示:
4.模型训练
在使用PaddleX进行模型训练的过程中,我们使用VOCDetection套件进行训练。
PaddleDetection内置30+模型算法及250+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级SOTA模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。https://github.com/PaddlePaddle/PaddleDetection - %E6%8F%90%E4%BE%9B%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E5%AE%9E%E4%BE%8B%E5%88%86%E5%89%B2%E5%A4%9A%E7%9B%AE%E6%A0%87%E8%B7%9F%E8%B8%AA%E5%85%B3%E9%94%AE%E7%82%B9%E6%A3%80%E6%B5%8B%E7%AD%89%E5%A4%9A%E7%A7%8D%E8%83%BD%E5%8A%9B提供目标检测、实例分割、多目标跟踪、关键点检测等多种能力,且https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.4/docs/images/ppdet.gifhttps://github.com/PaddlePaddle/PaddleDetection - %E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF%E8%A6%86%E7%9B%96%E5%B7%A5%E4%B8%9A%E6%99%BA%E6%85%A7%E5%9F%8E%E5%B8%82%E5%AE%89%E9%98%B2%E4%BA%A4%E9%80%9A%E9%9B%B6%E5%94%AE%E5%8C%BB%E7%96%97%E7%AD%89%E5%8D%81%E4%BD%99%E7%A7%8D%E8%A1%8C%E4%B8%9A应用场景覆盖工业、智慧城市、安防、交通、零售、医疗等十余种行业
其数据模型较大,预测速度比YOLOv3-DarkNet53更快,适用于服务端。当然,也可以更改其他模型。训练了多轮,最终mAP可以达到65%以上,训练过程可视化如下: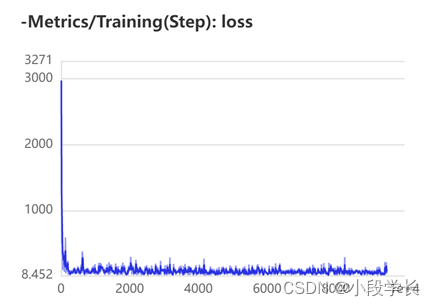
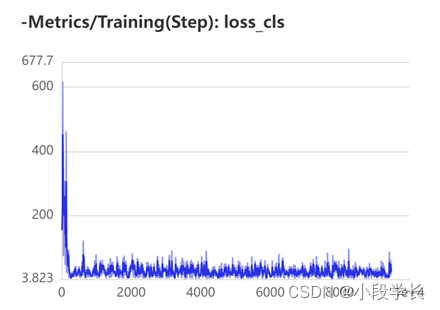
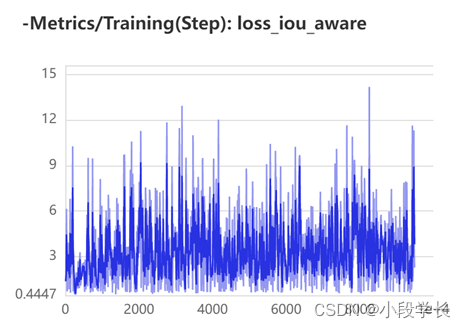
从以上 loss 曲线中我们可以看出,随着训练次数的增多,模型的损失在不断下降。模型的训练逐渐符合预期,损失函数的值趋于平缓。根据效果的设定的改变策略,此时进行了调整,损失值再次下降,最终训练效果趋于正常值,模型训练基本完成。
5.评价指标
常用的目标检测模型的评价指标有 IoU,recall,precision,mAP,Accuracy等。
(1)IOU:交并比(Intersection over Union,IoU),是衡量定位精确度的一种方式。交并比,顾名思义,是计算两个边界框交集和并集的比例的函数。在计算机检测任务中,如果IOU≥ 0.5,就认为预测的边界框结果正确,其中 0.5 是一个阈值,是根据经验所设定的。如果对检测结果要求十分严格,也可将阈值适当设置的高一些,比如 0.6,0.7;但阈值一定是小于 1,大于 0 的数值,因为如果预测的边界框和实际的边界框完全重合,IOU= 1。阈值很少设定为 0.5 以下。
(2)recall,precision:召回率(recall),表征某个类的召回(查全)效果,是标签为正样本的实例中预测正确的频率。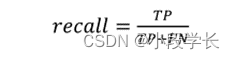
精确率(precision),表征分类器的分类效果(查准),是在预测为正样本的实例中预测正确的频率值。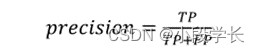
其中,真正例(TP)表示将正样本预测为正样本,假反例(FN)表示将正样本预测为负样本,假正例(FP)表示将负样本预测为正样本,真反例(TN)表示将负样本预测为负样本。在检测任务中,IOU 的阈值设定为 0.5,则 TP 表示 IOU 大于0.5 的检测框数量,FP 表示 IOU 小于等于 0.5 的检测框数量,FN 表示应该有框但并没有预测结果框的检测框数量。
(3)mAP:各类 AP 的平均值(mean average precision,mAP)。要计算 mAP,需要先绘制出各类别的 PR 曲线(precision-recall 曲线)来计算出 AP,AP 是 PR曲线下的面积,即 0-1 之间所有的 recall 值的 precision 值的均值。得到各类的 AP后,对各类的 AP 求平均值得到 mAP。
(4)Accuracy :准确率将测试集图像(all)中每一张图像都输入网络,进行前向得到预测结果(边界框和类别),如果预测结果与标注文件中的结果一致,包括检测框个数,位置则正确的图片数量(true)加一。
6.测试结果
在自行构建的测试集上对模型进行测试。此处的实验平台为带 GPU 的服务器,实验编程开发环境为MATLAB2019b, 计算设备为个人计算机, 为Intel Core i7-9750H ,主频为2.60GHz,显存为8GB。内存为 16GB,测试时只使用一块 GPU。检测模块只需要定位出商品的位置,因此所有的测试结果都与商品类别无关。测试过程中 IOU 的阈值设定为 0.5,测试结果如下图所示,并展示了部分结果图像。
从展示的测试结果中可以看出,该检测模型具有较强的鲁棒性,光照等因素的影响(图片暗一些或明亮一些)对检测结果不会造成太大的影响。模型在单个物体检测上效果最佳,准确率接近 80%,在多物体检测上,效果略微逊色,但也达到了令人满意的效果。在此总结了模型表现不佳的几种情况:(1)当台面上有多个物体且摆放十分紧密时,容易出现检测框错误(错检)(2)在商品过小或图像中商品有遮挡的检测中,容易出现未检测到目标商品(漏检)的情况。
由于遮挡严重,模型并未能检测到该商品,甚至人眼一开始也可能忽略这个被遮挡的商品的存在。
7.总结与展望
本文的主要研究内容为面向智能零售的商品识别系统,针对此研究内容查阅了众多文献资料,对商品识别的研究背景及意义进行了总结。了解了国内外现有的商品识别技术的研究现状,目前国内外对于商品的智能检测已有相当多的方案,各有优劣,但方案都已趋于成熟,本次实验只是对前人已实现的项目进行一个复现,因为训练时间较短,训练效果仍不够理想,我们会在以后的时间进行改进。
与实验环境相比,真实生活场景下的结算环境更加复杂多变,因此还有很多方面待改进和优化:
(1)增加结算台的摄像头数量,从更多的角度对商品进行图像采集。本次设计的商品识别系统使用了两个摄像头,在采集的图像中容易出现商品互相遮挡的情况,导致识别错误。从更多的角度采集图像后可以解决这一问题,从而进一步提高商品识别的准确率。
(2)使用较少的训练图像,得到较好的模型。本文使用了很少的商品图像进行模型训练与测试,而且这仅仅是部分类的商品,实际生活中的商品种类远大于此,所需的数据集图像的数量不可估量。因此寻找一种使用少量图像训练得到较好模型效果的方法十分重要。
参 考 文 献
[1]基于PaddleX的无人柜商品识别demo .https://aistudio.baidu.com/aistudio/projectdetail/3474742?channelType=0&channel=0&qq-pf-to=pcqq.group
[2] 智能零售柜商品识别.https://aistudio.baidu.com/aistudio/projectdetail/2250826?channelType=0&channel=0
[3] 迟海涛.人工智能视域下新零售时代业态结构研究[J].商业经济研究,2019(09):51-53.
[4]陈靖文.面向智能零售的商品自动识别系统设计与实现[J]杭州电子科技大学2021(02)
[5] 随玉腾. 基于深度学习的商品识别研究[D].青岛科技大学,2019.
[6]基于深度学习的超市商品图像识别方法研究[D]. 胡正委.中国科学技术大学 2018
欢迎大家加我微信交流讨论(请备注csdn上添加)
边栏推荐
猜你喜欢
Redis —— How To Install Redis And Configuration(如何快速在 Ubuntu18.04 与 CentOS7.6 Linux 系统上安装 Redis)

2022G3锅炉水处理考试题模拟考试题库及模拟考试
结合案例:Flink框架中的最底层API(ProcessFunction)用法
JVM series - stack and heap, method area day1-2
Qt如何实现打包,实现EXE分享
Understanding and difference between viewbinding and databinding

吃透Chisel语言.09.Chisel项目构建、运行和测试(一)——用sbt构建Chisel项目并运行
2022g3 boiler water treatment examination question simulation examination question bank and simulation examination
MySQL 5 installation and modification free
MySQL8版本免安装步骤教程
随机推荐
SQL language
硬件基础知识-二极管基础
How to choose a technology stack for web applications in 2022
安装trinity、解决报错
一次 Keepalived 高可用的事故,让我重学了一遍它
苹果5G芯片研发失败:继续依赖高通,还要担心被起诉?
C basic supplement
XML入门三
[C question set] of VII
C语言程序设计
【R语言数据科学】:交叉验证再回首
30: Chapter 3: develop Passport Service: 13: develop [change / improve user information, interface]; (use * * * Bo class to accept parameters, and use parameter verification)
XML入门一
使用默认路由作为指向Internet的路由
C language dormitory management query software
One of the solutions for unity not recognizing riders
JVM 内存布局详解,图文并茂,写得太好了!
Openharmony application development how to create dayu200 previewer
392. 判断子序列
如何在 2022 年为 Web 应用程序选择技术堆栈