当前位置:网站首页>RDD conversion operator of spark
RDD conversion operator of spark
2022-07-06 02:04:00 【Diligent ls】
Catalog
One .value type
1.map()
mapping : new RDD Every element is made of the original RDD Each element in applies a function in turn f Got
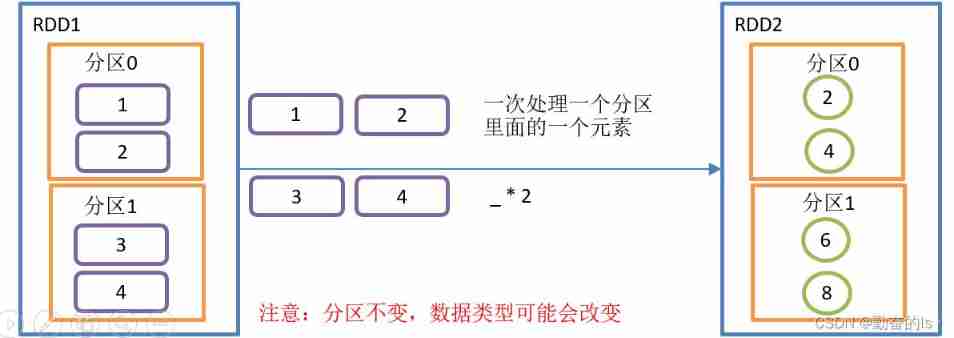
val value: RDD[Int] = sc.makeRDD(1 to 4, 2)
val rdd1: RDD[Int] = value.map(_*2)2.mapPartitions()
Execute on a partition by partition basis Map

val rdd2: RDD[Int] = value.mapPartitions(list=> {
println(" Calculate a number ") // Run twice Because there are two partitions
list.map(i => {
println(" Numbers ") // Run four times
i*2
})
})
rdd2.collect().foreach(println)notes : Use when space resources are large , After a partition data processing , primary RDD The data in the partition is released , May lead to OOM
3.mapPartitionsWithIndex()
Mapping with partition number , Create a RDD, Make each element form a tuple with the partition number , Make a new RDD
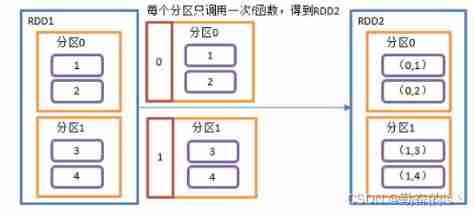
val rdd4: RDD[(Int, Int)] = value.mapPartitionsWithIndex((num,list)=> list.map(i=>(num,i)))
val rdd3: RDD[(Int, Int)] = value.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
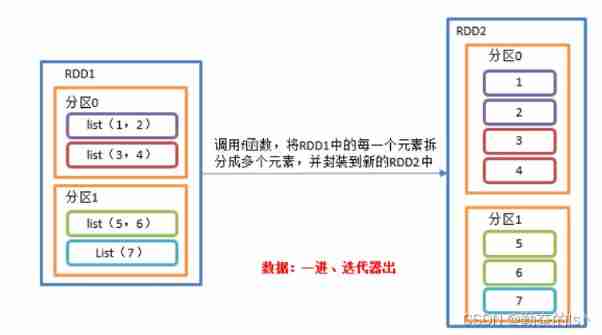
rdd3.collect().foreach(println)4.flatMap() flat
take RDD Every element in the application f Functions are converted to new elements in turn , And wrapped in RDD in . But in flatMap In operation ,f The return value of a function is a collection , And each element in the collection will be split and put into a new RDD in .
// Determine the partition
// flatMap Do not change the partition Keep the original partition
val rdd3: RDD[(Int, Int)] = value1.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd3.collect().foreach(println)
// Corresponding ( Long string , frequency ) => ( word , frequency ),( word , frequency )
val tupleRDD: RDD[(String, Int)] = sc.makeRDD(List(("hello world", 100), ("hello scala", 200)))
val value3: RDD[(String, Int)] = tupleRDD.flatMap(tuple => {
val strings: Array[String] = tuple._1.split(" ")
strings.map(word => (word, tuple._2))
})
value3.collect().foreach(println)
tupleRDD.flatMap(tuple => {
tuple._1.split(" ")
.map(word => (word,tuple._2))
})
// Partial function writing
val value4: RDD[(String, Int)] = tupleRDD.flatMap(tuple => tuple match {
case (line, count) => line.split(" ").map(word => (word, count))
})
value4.collect().foreach(println)
val value5: RDD[(String, Int)] = tupleRDD.flatMap{
case (line, count) => line.split(" ").map(word => (word, count))}
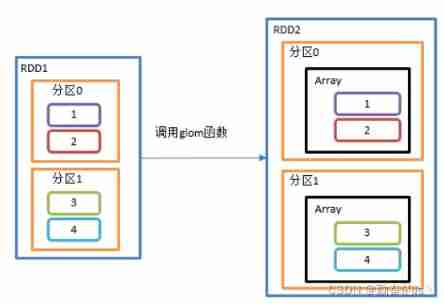
5.glom()
take RDD Each partition in becomes an array , And put it in a new RDD in , The element type in the array is consistent with that in the original partition
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[Array[Int]] = listRDD.glom()
val arraydemo: RDD[Int] = value.map(Array => (Array.max))
arraydemo.collect().foreach(println)
// From a sql In the script file Extract the corresponding sql
val lineRDD: RDD[String] = sc.textFile("input/1.sql",1)
// Use it directly spark Operator read sql Script files The content inside is broken up into lines
val value2: RDD[Array[String]] = lineRDD.glom()
//mkString Array to string
value2.map(array => array.mkString).collect().foreach(println)
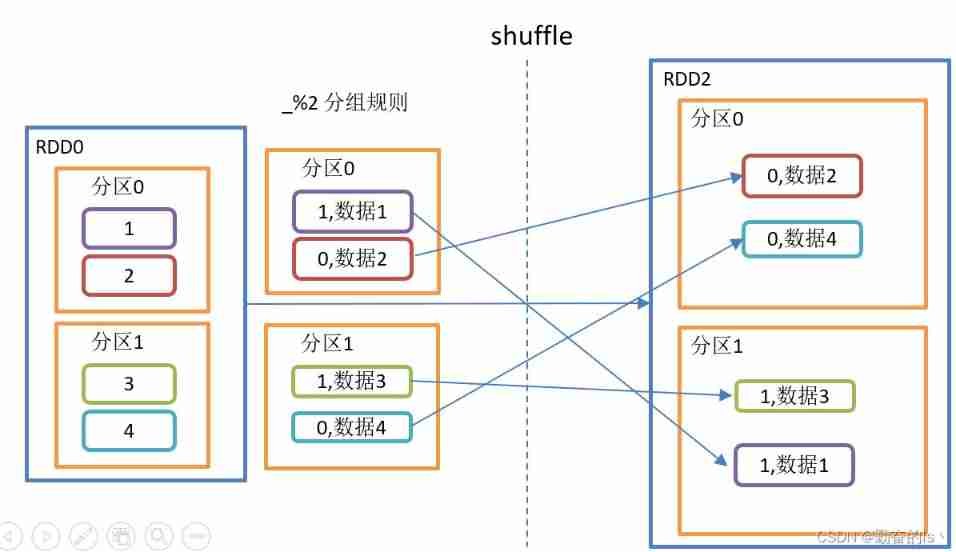
6.groupBy()
Will be the same K Put the corresponding value in an iterator
val sc: SparkContext = new SparkContext(conf)
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[(Int, Iterable[Int])] = listRDD.groupBy(i => i%2)
value.collect().foreach(println)
//(0,CompactBuffer(2, 4))
//(1,CompactBuffer(1, 3))
//groupby Realization wordcount
val text: RDD[String] = sc.textFile("input/1.txt")
val fmRDD: RDD[String] = text.flatMap(_.split(" "))
val value: RDD[(String, Iterable[String])] = fmRDD.groupBy(s => s)
value.collect().foreach(println)
val value1: RDD[(String, Int)] = value.mapValues(list => list.size)
value1.collect().foreach(println)
val value2: RDD[(String, Int)] = value.map({
case (word, list) => (word, list.size)
})
value2.collect().foreach(println)7.filter()
Receive a function with a Boolean return value as an argument . When a RDD call filter When the method is used , Will the RDD Apply... To each element in the f function , If the return value type is true, Then the element will be added to the new RDD in .
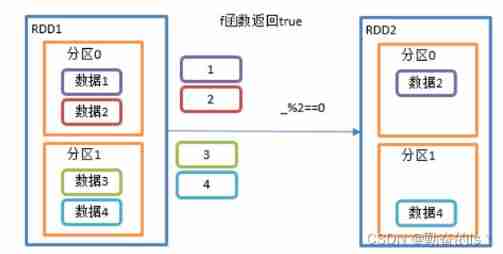
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[Int] = listRDD.filter(i => i%2 ==0)
value.collect().foreach(println)
// Filter
// Keep the partition unchanged 8.sample()
sampling , Sample from a large amount of data
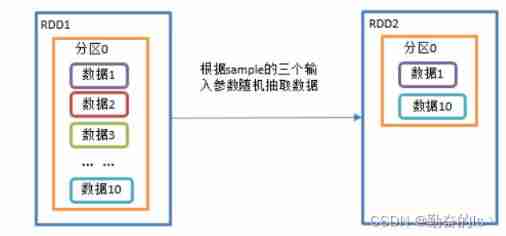
val listRDD: RDD[Int] = sc.makeRDD(1 to 10)
// Extract data without putting it back ( Bernoulli algorithm )
// Bernoulli algorithm : Also called 0、1 Distribution . For example, toss a coin , Or the front , Or the opposite .
// Concrete realization : According to the seed and random algorithm to calculate a number and the second parameter setting probability comparison , Less than the second parameter to , Don't
// The first parameter : Whether the extracted data is put back ,false: Don't put back
// The second parameter : The probability of extraction , The scope is [0,1] Between ,0: Not at all ;1: Take all ;
// The third parameter : Random number seed
// The random algorithm is the same , The seeds are the same , Then the random number is the same
// Do not enter parameters , The nanosecond value of the current time taken by the seed , So the random results are different
val value1: RDD[Int] = listRDD.sample(false,0.5,10)
value1.collect().foreach(println)
// Extract data and put it back ( Poisson algorithm )
// The first parameter : Whether the extracted data is put back ,true: Put back ;false: Don't put back
// The second parameter : The probability of duplicate data , The range is greater than or equal to 0. Represents the number of times each element is expected to be extracted
// The third parameter : Random number seed
val value2: RDD[Int] = listRDD.sample(true,2.3,100)
value2.collect().foreach(println)9. distinct()
duplicate removal , Put the de duplicated data into the new RDD in
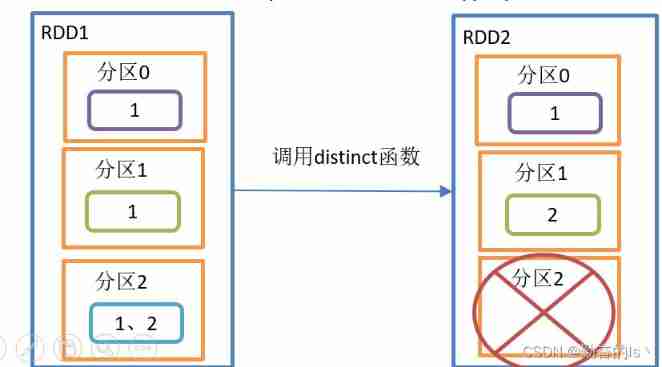
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,5,4,2,3,1,6),2)
val value: RDD[Int] = listRDD.distinct()
//distinct Will exist shuffle The process 10.coalesce()
Merge partitions , Reduce the number of partitions , Used after big data set filtering , Improve the execution efficiency of small data sets .
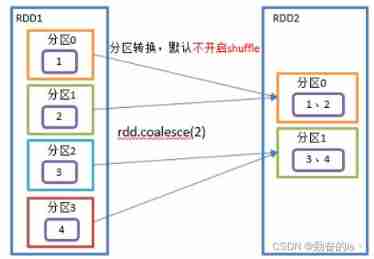
// Reduce partitions
// Many to one relationship Don't go shuffle
val coalrdd: RDD[Int] = listRDD.coalesce(2)
val rdd3: RDD[(Int, Int)] =
coalrdd.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd3.collect().foreach(println)
println("===============")
// Expansion of zoning
// Must go shuffle Otherwise, it doesn't make sense
val listRDD1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val coalrdd2: RDD[Int] = listRDD1.coalesce(5,true)
val rdd4: RDD[(Int, Int)] =
coalrdd2.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd4.collect().foreach(println)11.repartition()
Repartition , This operation actually performs coalesce operation , Parameters shuffle The default value is true. Regardless of the number of partitions RDD Convert to less partitions RDD, Or the one with fewer partitions RDD Convert to a with a large number of partitions RDD,repartition All operations can be completed , Because it will go through shuffle The process .
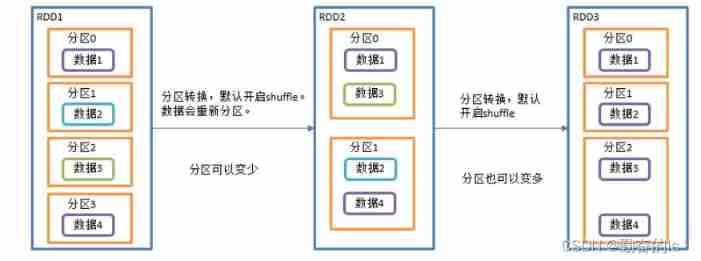
val sc: SparkContext = new SparkContext(conf)
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[Int] = listRDD.repartition(4)
val rdd3: RDD[(Int, Int)] = value.mapPartitionsWithIndex((num,list)=>list.map((num,_)))12.sortBy()
Sort , This operation is used to sort the data . Before sorting , Data can be passed through f Function to process , And then according to f Function to sort the results , The default is positive order . New after sorting RDD The number of partitions is the same as the original RDD The number of partitions is consistent .
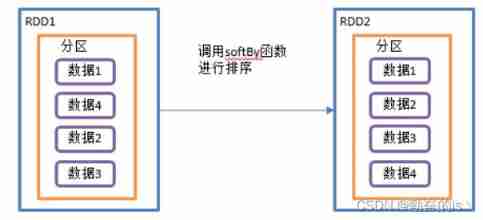
val listRDD: RDD[Int] = sc.makeRDD(List(1,6,5,4,2,3,4,9),2)
val value: RDD[Int] = listRDD.sortBy(i => i)
value.collect().foreach(println)
println("==================")
// spark The sorting of can achieve global order
// Guarantee 0 The data of partition No. is greater than or equal to 1 Data from partition number
// sortBy Need to go shuffle
val value2: RDD[Int] = listRDD.sortBy(i => i,false)
val rdd3: RDD[(Int, Int)] = value2.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd3.collect().foreach(println)
// (0,9)
// (0,6)
// (0,5)
// (1,4)
// (1,4)
// (1,3)
// (1,2)
// (1,1)13. pipe()
Call script , The Conduit , For each partition , All called once shell Script , Returns the output of RDD
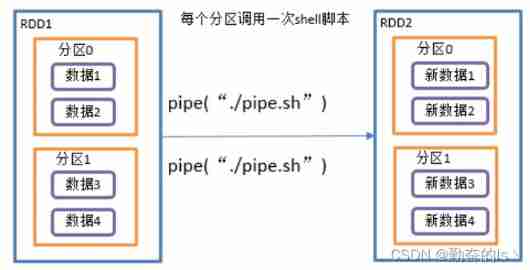
Two 、 double value
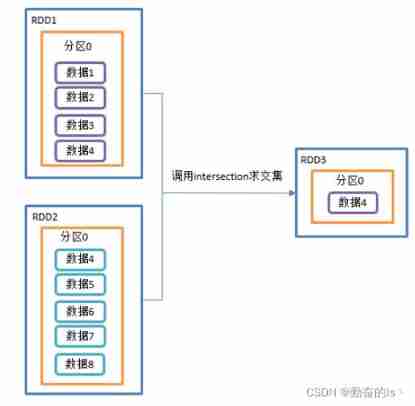
1.intersection()
Find the intersection
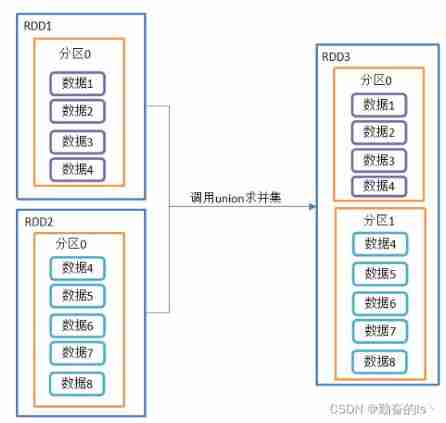
2.union()
Union
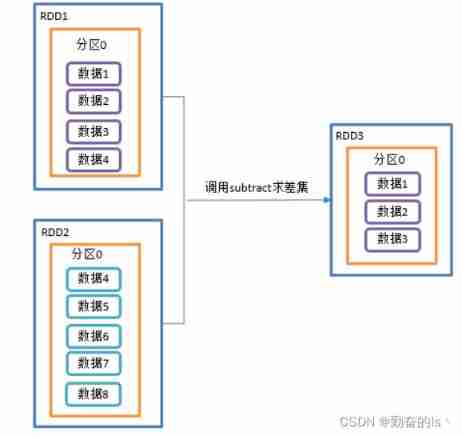
3.subtract()
Difference set
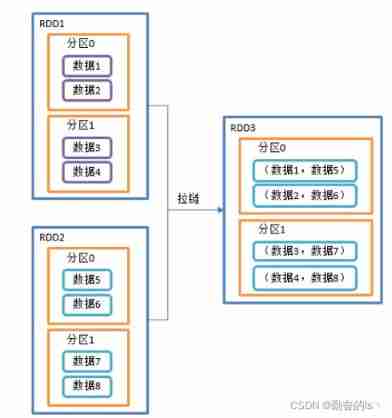
4.zip()
zipper , This operation can combine two RDD The elements in , Merge in the form of key value pairs . among , Key value alignment Key For the first time 1 individual RDD The elements in ,Value For the first time 2 individual RDD The elements in .
Put two RDD Combine into Key/Value Formal RDD, There are two default RDD Of partition The number and the number of elements are the same , Otherwise, an exception will be thrown .
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val listRDD1: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
// Ask the meeting to break up and repartition I need to go shuffle
// By default, partitions with more intersections are used
val demo01: RDD[Int] = listRDD.intersection(listRDD1)
demo01.collect().foreach(println)
// Union
// Union does not go shuffle
// Just put two RDD Get the partition data of The number of partitions is equal to two RDD The sum of the number of partitions
val demo02: RDD[Int] = listRDD.union(listRDD1)
val rdd3: RDD[(Int, Int)] = demo02.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd3.collect().foreach(println)
// Difference set
// Need to rewrite partition go shuffle You can write the number of partitions by yourself
println("=======================")
val demo03: RDD[Int] = listRDD.subtract(listRDD1)
val rdd4: RDD[(Int, Int)] = demo03.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
rdd4.collect().foreach(println)
// Zip the elements at the corresponding positions of the same partition together Become a 2 Tuples
// zip Only two can be operated rdd Have the same number of partitions and elements
val demo04: RDD[(Int, Int)] = listRDD.zip(listRDD1)
demo04.mapPartitionsWithIndex((num,list) => list.map((num,_))).collect().foreach(println)3、 ... and 、KEY-VALUE type
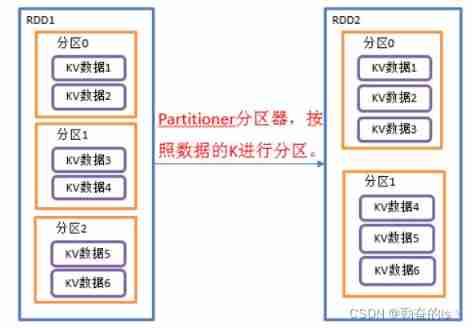
1.partitionBy()
according to key Value repartition , If the original RDD And the new RDD If it's consistent, no zoning will be done , Otherwise, it will occur Shuffle The process .
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[(Int, Int)] = listRDD.map((_,1))
// according to key Modulo partition of partition data
val hp: RDD[(Int, Int)] = value.partitionBy(new HashPartitioner(2))
hp.mapPartitionsWithIndex((num,list)=>list.map((num,_))).collect().foreach(println)
2. Custom partition
To implement a custom partition , Need to inherit org.apache.spark.Partitioner class , And implement the following three methods .
(1)numPartitions: Int: Return the number of partitions created .
(2)getPartition(key: Any): Int: Returns the partition number of the given key (0 To numPartitions-1).
(3)equals():Java The standard way to judge equality . The implementation of this method is very important ,Spark You need to use this method to check whether your partition object is the same as other partition instances , such Spark To judge two RDD Is the partition method the same
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[(Int, Int)] = listRDD.map((_,1))
val hp: RDD[(Int, Int)] = value.partitionBy(new MyPartition)
hp.mapPartitionsWithIndex((num,list)=>list.map((num,_))).collect().foreach(println)
sc.stop()
}
// Custom partition
class MyPartition extends Partitioner{
override def numPartitions: Int = 2
// Get the partition number => According to the key value Determine which partition to assign
// spark The partition of can only be used for key partition
override def getPartition(key: Any): Int = {
key match {
case i:Int => i%2
case _ => 0
}
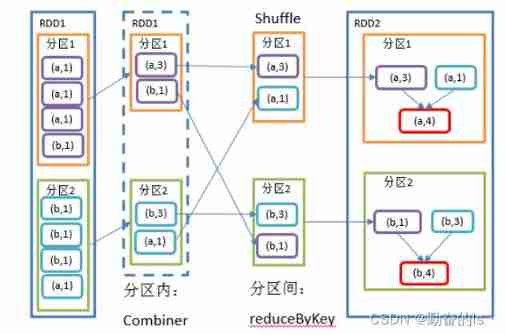
3.reduceByKey()
Elements follow the same Key Yes Value Aggregate . It has many overload forms , You can also set up new RDD The number of partitions .
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val tuplerdd: RDD[(Int, Int)] = listRDD.map( (_ ,1))
val result1: RDD[(Int, Int)] = tuplerdd.reduceByKey((res,elem) => res - elem)
result1.collect().foreach(println)
// The verification results
// It needs to be reduced twice In the primary partition Primary partition
// The first element between partitions depends on the number of partitions The smaller the number, the higher
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("a", 1), ("a", 1), ("b", 1), ("b", 1), ("b", 1), ("b", 1), ("a", 1),("c",1)), 2)
val result2: RDD[(String, Int)] = value1.reduceByKey((res,elem) => res - elem)
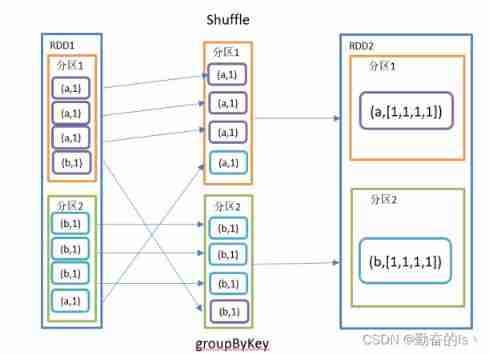
result2.collect().foreach(println)4.groupByKey()
according to key Regroup , For each key To operate , But only one seq, No aggregation
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,1,2,3,4),2)
val tupleRDD: RDD[(Int, Int)] = listRDD.map((_, 1))
val result: RDD[(Int, Iterable[(Int, Int)])] = tupleRDD.groupBy(tuple => tuple._1)
result.collect().foreach(println)
//(4,CompactBuffer((4,1), (4,1)))
//(2,CompactBuffer((2,1), (2,1)))
//(1,CompactBuffer((1,1), (1,1)))
//(3,CompactBuffer((3,1), (3,1)))
val result2: RDD[(Int, Iterable[Int])] = tupleRDD.groupByKey()
result2.collect().foreach(println)
//(4,CompactBuffer(1, 1))
//(2,CompactBuffer(1, 1))
//(1,CompactBuffer(1, 1))
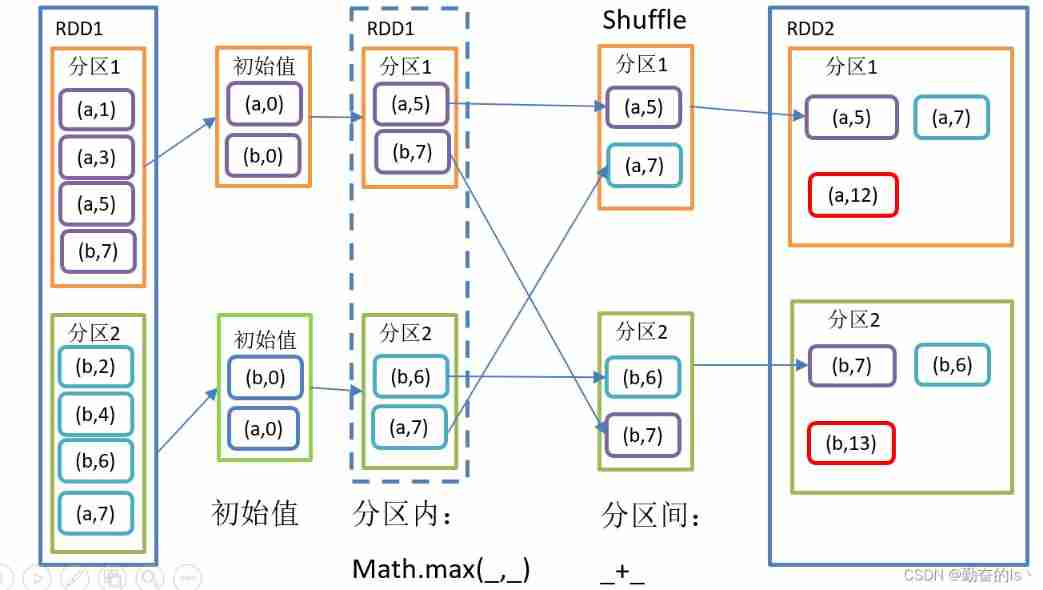
//(3,CompactBuffer(1, 1))5.aggregateByKey()
according to Key Handle intra - and inter partition logic
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
val result1: RDD[(String, Int)] = value1.aggregateByKey(10)(_ + _,_ + _)
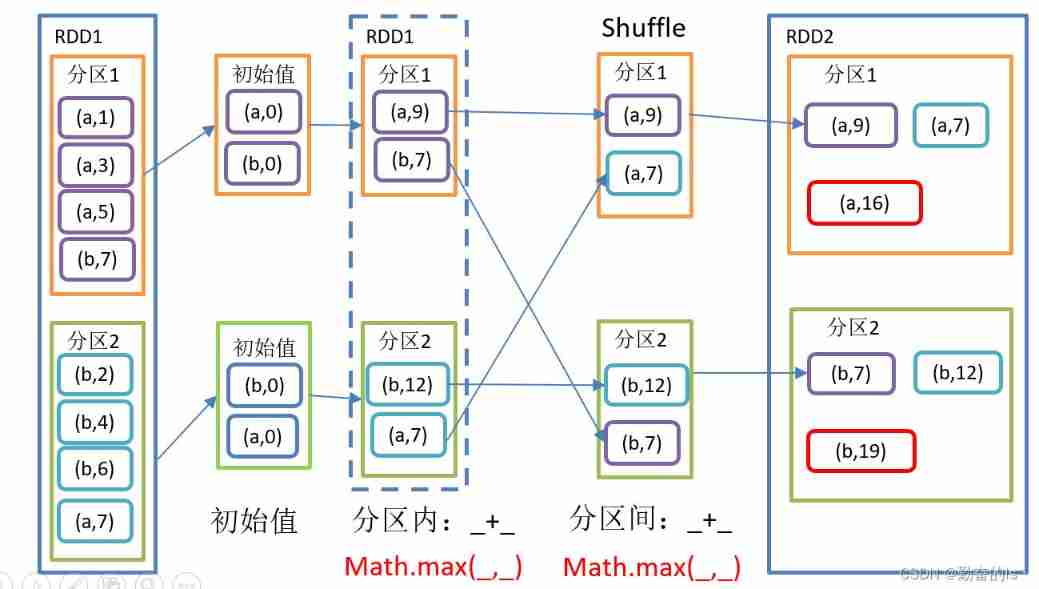
result1.collect().foreach(println)6.foldByKey()
That is, the same within and between partitions aggregateByKey()
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
value1.foldByKey(10)(_ + _).collect().foreach(println)
value1.foldByKey(10)((res,elem) => math.max(res,elem)).collect().foreach(println)7.combineByKey()
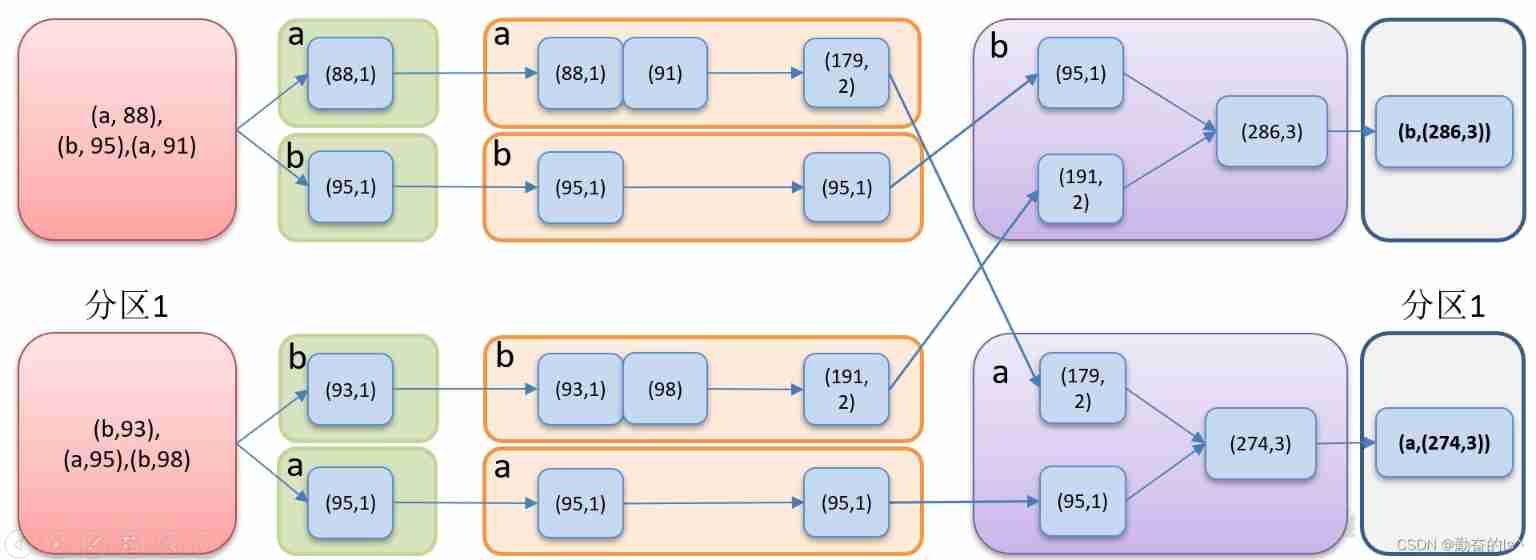
Operation within and between partitions after structure conversion , For the same Key, take Value Merge into a collection .
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
// Reduce the above elements ( word ,("product",21))
val value: RDD[(String, (String, Int))] = value1.combineByKey(
i => ("product", i),
// In partition calculation The initial value after the structure conversion is the same as the partition key Reduce the element value of
(res: (String, Int), elem: Int) => (res._1, res._2 * elem),
// Inter zone calculation Make each partition the same key Of res Values are merged
(res: (String, Int), elem: (String, Int)) => (res._1, res._2 * elem._2)
)
value.collect().foreach(println)
println("==========================")
val list: List[(String, Int)] = List(
("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val listRDD1: RDD[(String, Int)] = sc.makeRDD(list)
val result2: RDD[(String, (Int, Int))] = listRDD1.combineByKey(
// take (a,88) => (a,(88,1)) Because the operator has internally followed key Aggregated So when writing, only write value
i => (i, 1),
(res: (Int, Int), elem: Int) => (res._1 + elem, res._2 + 1),
// Accumulate within the partition Make the same partition the same key Merge the values of (88,1) and 91 => (179,2)
// Accumulation between partitions Make different partitions the same key The binary combination of (179,2) and (95,1) => (274,3)
(res: (Int, Int), elem: (Int, Int)) => (res._1 + elem._1, res._2 + elem._2)
)
result2.mapValues({
case (res,elem) => res.toDouble/elem
}).collect().foreach(println)
difference :

8.sortByKey()
according to K Sort , In a (K,V) Of RDD On the call ,K Must be realized Ordered Interface , Return to a press key sorted (K,V) Of RDD
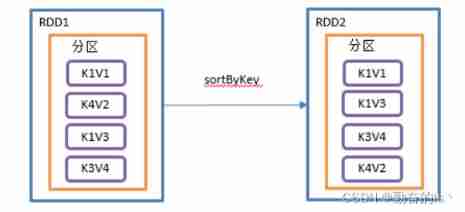
val value: RDD[(String, Int)] = sc.makeRDD(
List(("a", 110), ("b", 27), ("a", 11), ("b", 21)), 2)
// By default range Comparator ( Try to ensure that the amount of data in each partition is uniform , And there's order between partitions , Elements in one partition must be smaller or larger than those in another partition ; But the order of the elements in a partition is not guaranteed .)
// Fixed use of key Sort Can't use value
value.sortByKey(false).collect().foreach(println)
// Use value Sort
// have access to sortBy The bottom layer is still sortbykey
value.sortBy(_._2).collect().foreach(println)9.mapValues()
Only right value Make changes
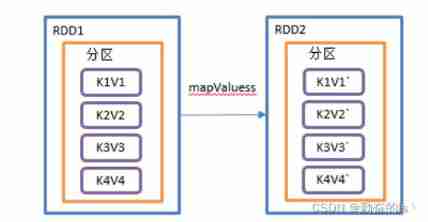
val value: RDD[(String, Int)] = sc.makeRDD(
List(("a", 110), ("b", 27), ("a", 11), ("b", 21)), 2)
value.mapValues(i => i*2).collect().foreach(println)10.join()
In the type of (K,V) and (K,W) Of RDD On the call , Return to the same key All the corresponding elements are aligned together (K,(V,W)) Of RDD
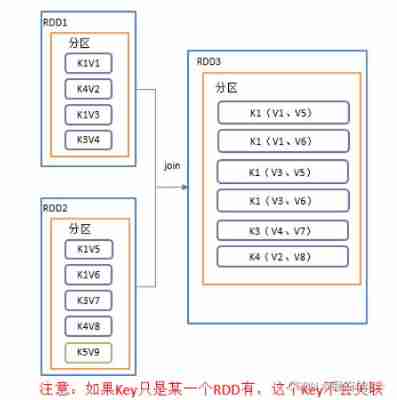
val value: RDD[(String, Int)] = sc.makeRDD(
List(("a", 110), ("b", 27), ("a", 11), ("b", 21)), 2)
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 110), ("b", 27), ("a", 11), ("b", 21)), 2)
// Will be the same key Merge
// join go shuffle Use hash Comparator
// Try to make sure that join Before key It's not repeated If there is duplication The final result will be repeated
value.join(value1).collect().foreach(println)
// Solve repetition
value.groupByKey().join(value1).collect().foreach(println)11.cogroup()
In the type of (K,V) and (K,W) Of RDD On the call , Return to one (K,(Iterable<V>,Iterable<W>)) Type of RDD
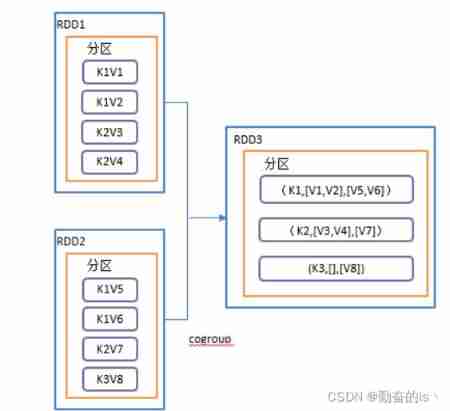
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6)))
rdd.cogroup(rdd1).collect().foreach(println)12. seek top3
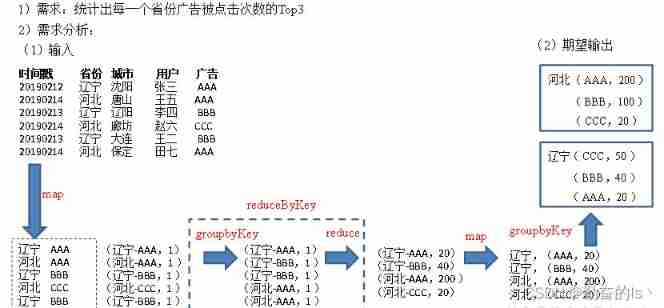
val listRDD: RDD[String] = sc.textFile("input/agent.log")
val result1: RDD[(String, Int)] = listRDD.map({
line => {
val strings: Array[String] = line.split(" ")
(strings(1) + "-" + strings(2), 1)
}
}).reduceByKey(_ + _)
result1.collect().foreach(println)
val result2: RDD[(String, Iterable[(String, Int)])] = result1.map({ case (res, sum) => {
val strings01: Array[String] = res.split("-")
(strings01(0), (strings01(1), sum))
}
}).groupByKey()
val result3: RDD[(String, List[(String, Int)])] = result2.mapValues({
datas => {
datas.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(3)
}
})
// Abbreviation result3.mapValues(_.toList.sortWith(_._2 > _._2).take(3))
result3.collect().foreach(println)
边栏推荐
- Xshell 7 Student Edition
- module ‘tensorflow. contrib. data‘ has no attribute ‘dataset
- [flask] official tutorial -part3: blog blueprint, project installability
- [flask] official tutorial -part2: Blueprint - view, template, static file
- 【Flask】官方教程(Tutorial)-part1:项目布局、应用程序设置、定义和访问数据库
- leetcode-2.回文判断
- Blue Bridge Cup embedded_ STM32 learning_ Key_ Explain in detail
- 01. Go language introduction
- 【Flask】官方教程(Tutorial)-part3:blog蓝图、项目可安装化
- Paddle framework: paddlenlp overview [propeller natural language processing development library]
猜你喜欢
Extracting key information from TrueType font files
![Grabbing and sorting out external articles -- status bar [4]](/img/1e/2d44f36339ac796618cd571aca5556.png)
Grabbing and sorting out external articles -- status bar [4]
A basic lintcode MySQL database problem
PHP campus movie website system for computer graduation design

SPI communication protocol

Basic operations of database and table ----- delete data table

500 lines of code to understand the principle of mecached cache client driver
![[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry](/img/94/05b2ff62a8a11340cc94c69645db73.png)
[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry

Numpy array index slice
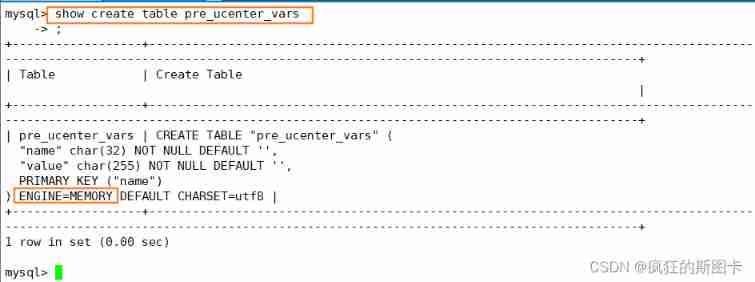
Concept of storage engine
随机推荐
抓包整理外篇——————状态栏[ 四]
Genius storage uses documents, a browser caching tool
[detailed] several ways to quickly realize object mapping
dried food! Accelerating sparse neural network through hardware and software co design
How to set an alias inside a bash shell script so that is it visible from the outside?
正则表达式:示例(1)
500 lines of code to understand the principle of mecached cache client driver
TrueType字体文件提取关键信息
[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry
Mongodb problem set
Unreal browser plug-in
Basic operations of database and table ----- set the fields of the table to be automatically added
[depth first search notes] Abstract DFS
Force buckle 1020 Number of enclaves
C web page open WinForm exe
Leetcode3. Implement strstr()
Basic operations of databases and tables ----- default constraints
Redis key operation
Sword finger offer 12 Path in matrix
Numpy array index slice