当前位置:网站首页>NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
2022-07-06 01:34:00 【u013250861】
One 、 summary
1、prompt The meaning of
prompt As the name suggests, it is “ Tips ” It means , Someone should have played the game you drew. I guess , The other party draws a picture according to a word , Let's guess what he painted , Because there are too many soul painters , The style of painting is very strange , Or you don't have a heart , It's not easy to guess ! At this time, some prompt words will appear on the screen, such as 3 A word , Fruits , Isn't that a little easier to guess , After all 3 There are not many fruits in one word . See? , This is it. prompt The charm of , Let's have a little connection !( I'm not very good at painting , Just imagine , Hey, hey, hey ~~~)
2、 Abstract
This paper takes a new natural language processing paradigm , be called “prompt-based learning”.
- Different from the traditional supervised learning , The traditional supervised learning training model receives input x \boldsymbol{x} x , And output y Forecast as P ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x}) P(y∣x).
- be based on prompt Learning is a language model that directly models text probability . In order to use these models to perform prediction tasks , Use the template to input the original x \boldsymbol{x} x Change to a text string prompt with some unfilled slots x ′ \boldsymbol{x}^{\prime} x′ , Then use the language model probability to fill Unfilled information To get the final string x ^ \hat{\boldsymbol{x}} x^ , From which you can export the final output y \boldsymbol{y} y .
The framework is powerful and attractive , There are many reasons :
- It allows language models to be built on a large number of original texts Preliminary training ;
- And by defining a new prompt function , The model can execute few-shot even to the extent that zero-shot Study , To adapt to new scenarios with little or no marked data ;
3、NLP Several major changes in
3.1 Paradigm one : Fully supervised learning in the age of non neural networks ( Feature Engineering )
Fully supervised learning , That is, the task specific model is only in the input of the target task - Training on the output sample data set , It has played a central role in many machine learning tasks for a long time , natural language processing (NLP) No exception .
Because this fully supervised data set is not enough to learn high-quality models , In the early NLP Models rely heavily on Feature Engineering ,NLP Researchers or engineers use their domain knowledge to define and extract salient features from raw data , And provide appropriate inductive bias for the model , To learn from these limited data .
3.2 Formula Two : Fully supervised learning based on neural network ( Architecture Engineering )
With NLP The emergence of neural network models , While training the model itself , Learned significant characteristics , So the focus shifts to Structural Engineering , among , Provide sensing bias by designing a suitable network architecture that helps learn such features .
3.3 Formula 3 : Preliminary training , Fine tuning paradigm ( Target project )
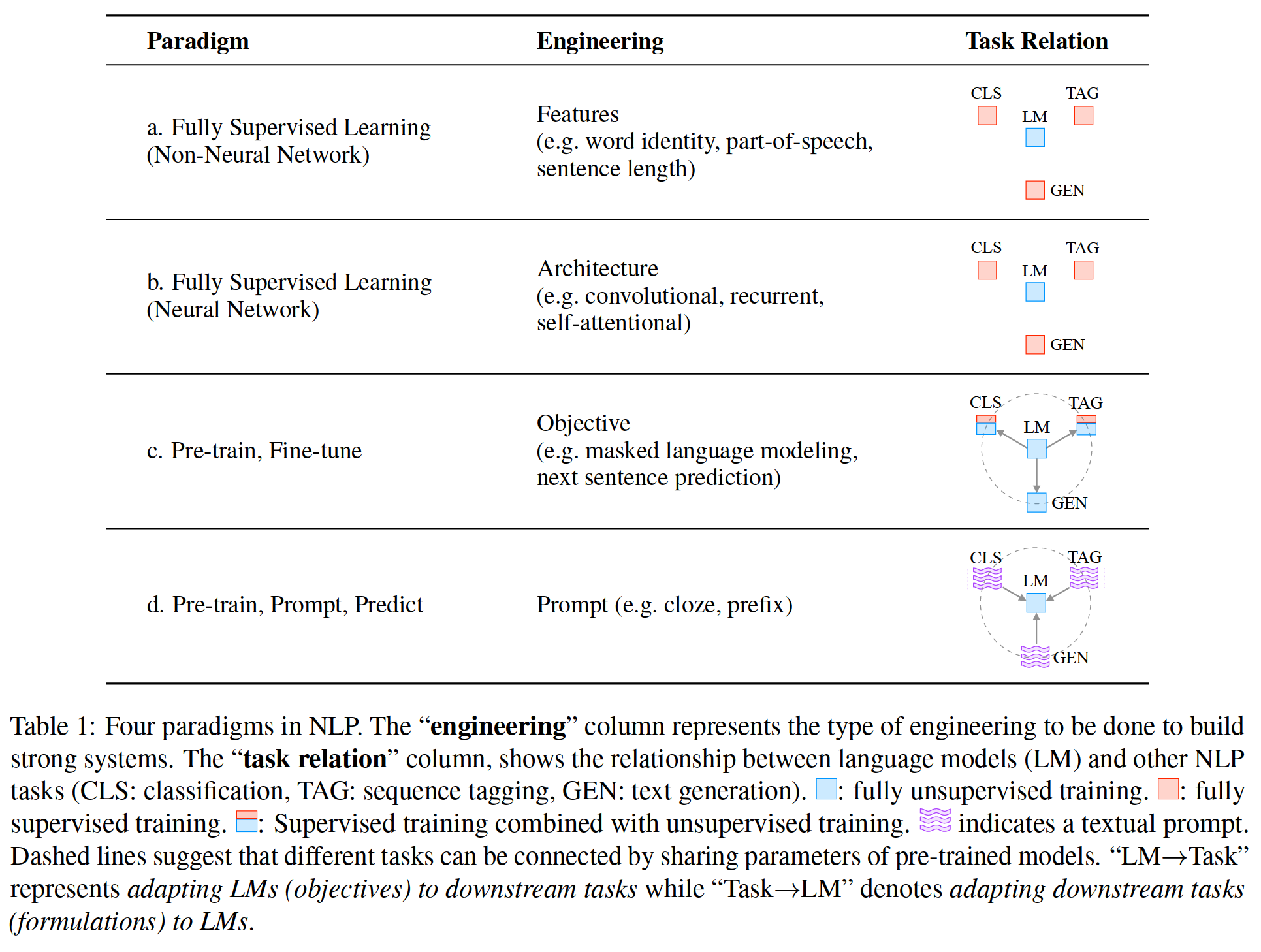
However , from 2017-2019 year ,NLP Great changes have taken place in the learning of models , This paradigm of complete supervision is now playing a smaller and smaller role . To be specific , The standard has shifted to the pre training and fine-tuning paradigm ( surface 1 c). In this paradigm , A model with a fixed architecture is pre trained as a language model (LM), Predict the probability of observed text data .
Because of training LMs The original text data required is very rich , Therefore, these can be trained on large data sets LMs, Learn the robust general features of modeling languages . then , Fine tune it by introducing additional parameters and using task specific objective functions , Make the above pre trained LM Adapt to different downstream tasks . In this paradigm , The focus is mainly on Target project , Design training objectives for pre training and fine-tuning stages . for example ,Zhang wait forsomeone (2020a) indicate , Introducing the loss function to predict significant sentences from documents will provide a better pre training model for text summarization .
It is worth noting that , Pre trained LM The main body of is usually fine tuned , To make it more suitable for solving downstream tasks .
3.4 Paradigm four : Preliminary training , Tips , Prediction paradigm (Prompt engineering )
By 2021 When writing this paper , We are in the middle of the second great change ,“pre-train, fine-tune” The program is called “pre-train, prompt, and predict” Replaced by . In this paradigm ,
- It's not pre trained through target Engineering LMs Adapt to downstream tasks ;
- Instead, with the help of text prompts, reformulate downstream tasks , Make it look more primitive LM Tasks solved during training ;
for example :
- When recognizing the emotions of social media Posts ,“ I missed the bus today .”, We can continue to prompt “ I feel __”, And ask the LM Fill in the blanks with an emotional word .
- perhaps , If we choose prompt “ English : I missed the bus today . French :__”,LM Maybe French translation can be used to fill the gap .
In this way , By selecting the appropriate prompt , We can manipulate model behavior , In order to train in advance LM Itself can be used to predict the required output , Sometimes it doesn't even require any additional task specific training .
- The advantage of this method is , Given an appropriate set of tips , A single person trained in a completely unsupervised manner LM It can be used to solve a large number of tasks .
- However , There is a trap : This method introduces the necessity of real-time engineering , That is to find the most appropriate prompt , With permission LM Solve the task at hand .
surface 1:NLP Four paradigms in .“Task Relation” Column shows the language model (LM) And others NLP Mission (CLS: classification 、 Mark : Sequence marker 、GEN: The text generated ) The relationship between . The dotted line indicates that different tasks can be connected by sharing the parameters of the pre training model .“LM→Task” To make LMs( The goal is ) Adapt to downstream tasks , and “Task”→LM” Indicates that the downstream task is adjusted to LMs.
Two 、 To prompt (Prompting) A formal description of
1、NLP Supervised learning in
In traditional NLP In the supervised learning system , Get input x \boldsymbol{x} x , It's usually text , And based on the model P ( y ∣ x ; θ ) P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta) P(y∣x;θ) Forecast output y \boldsymbol{y} y . y \boldsymbol{y} y It can be a label 、 Text or other kinds of output . In order to learn the parameters of the model θ, Use a dataset containing input and output pairs , And train a model to predict the conditional probability . for example :
- First , Text classification adopts input text x \boldsymbol{x} x , And from the fixed tag set Y \mathcal{Y} Y Forecast tags y \boldsymbol{y} y . for instance , Emotional analysis input x=“ I like this movie .” And predict the label y=++( Tag set y={++、+、~、-、–}).
- secondly , Conditional text generation uses input x \boldsymbol{x} x And generate another text y \boldsymbol{y} y . Machine translation is an example , Where the input is the text of a language , For example, Finnish x \boldsymbol{x} x=“Hyv ̈ a ̈ a huomenta.“ Output in English y \boldsymbol{y} y =“Good morning.”.
2、 Tips (Prompting)
The main problem of supervised learning is , To train the model P ( y ∣ x ; θ ) P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta) P(y∣x;θ) , It is necessary to provide monitoring data for the task , And for many tasks , These data cannot be found in large numbers .
NLP Based on tips (Prompt) The learning method tries to model text by learning x \boldsymbol{x} x Self probability P ( x ; θ ) P(\boldsymbol{x} ; \theta) P(x;θ) Of LM, And use this probability to predict y y y, Thus avoiding or reducing the need for large supervised data sets , So as to bypass this problem .
In this section , The paper is the most basic prompting The form is described mathematically , It includes a lot about prompting The job of , It can also be extended to other work . To be specific , Tips (prompting) Predict the one with the highest score in the three steps y ^ \hat{\boldsymbol{y}} y^ .
2.1 Add hints (Prompting)
In this step , Application prompt function f prompt ( ⋅ ) f_{\text {prompt }}(\cdot) fprompt (⋅) Text will be entered x \boldsymbol{x} x Change to prompt x ′ = f prompt ( x ) \boldsymbol{x}^{\prime}=f_{\text {prompt }}(\boldsymbol{x}) x′=fprompt (x) . There are two steps :
- Apply a template , This is a text string , There are two slots : An input slot [X] For input X, Another answer slot [Z] Answer text for intermediate generation Z, The answer text Z You will map to y \boldsymbol{y} y .
- Enter text with x \boldsymbol{x} x Fill the tank [X].
In emotional analysis , x \boldsymbol{x} x=“ I like this movie .”, The form of template may be “[X] Overall speaking , This is a [Z] The movie ”. then ,x′ Will become “ I like this movie . in general , This is a [Z] The movie .” The previous example is given .
In the case of machine translation , The template can be “Finnish:[X]English:[Z]” The form such as , The text of the input and answer is connected with the title of the indicating language .
surface 3 There are more examples .
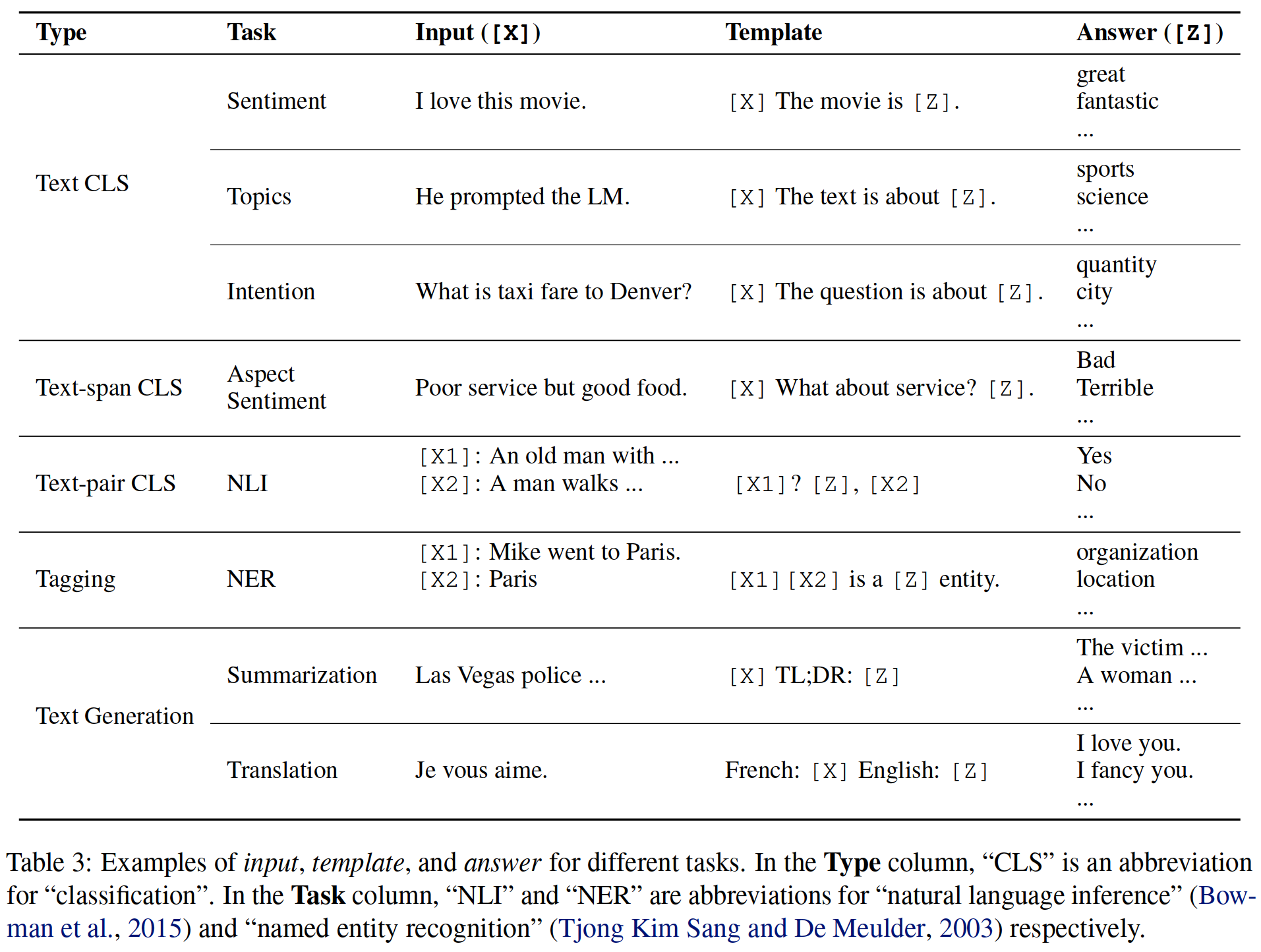
It is worth noting that :
- The above tips (prompt) Will be prompted middle or At the end of by z \boldsymbol{z} z Fill an empty slot . In the text below , The first type of prompt is called cloze prompt (cloze prompt,), The second type of prompt is called prefix prompt (prefix prompt), The input text is completely located in z \boldsymbol{z} z Before .
- in many instances , These template words are not necessarily composed of natural language markers ; They can be virtual words ( for example , By digital ID Express ), Later, it will be embedded in continuous space , Some prompt methods even generate continuous vectors directly .
- [X] Number of slots and [Z] The number of slots can be flexibly changed according to the needs of the task at hand .
2.2 Answer search
Next , Search for the text with the highest score z ^ \hat{\boldsymbol{z}} z^ , To maximize LM Score of .
Let's start with Z Defined as z \boldsymbol{z} z A set of allowable values of . For generative tasks , Z \mathcal{Z} Z It can be the scope of the whole language , Or in the case of classification , Z \mathcal{Z} Z It can be a small part of a word in a language , For example, definition Z \mathcal{Z} Z ={“ good ”、“ good ”、“ good ”、“ bad ”、“ terrible ”}, To indicate that Y \mathcal{Y} Y ={++、+、~、-、–} Each class in .
surface 2: Tips (prompting) Terms and symbols of methods
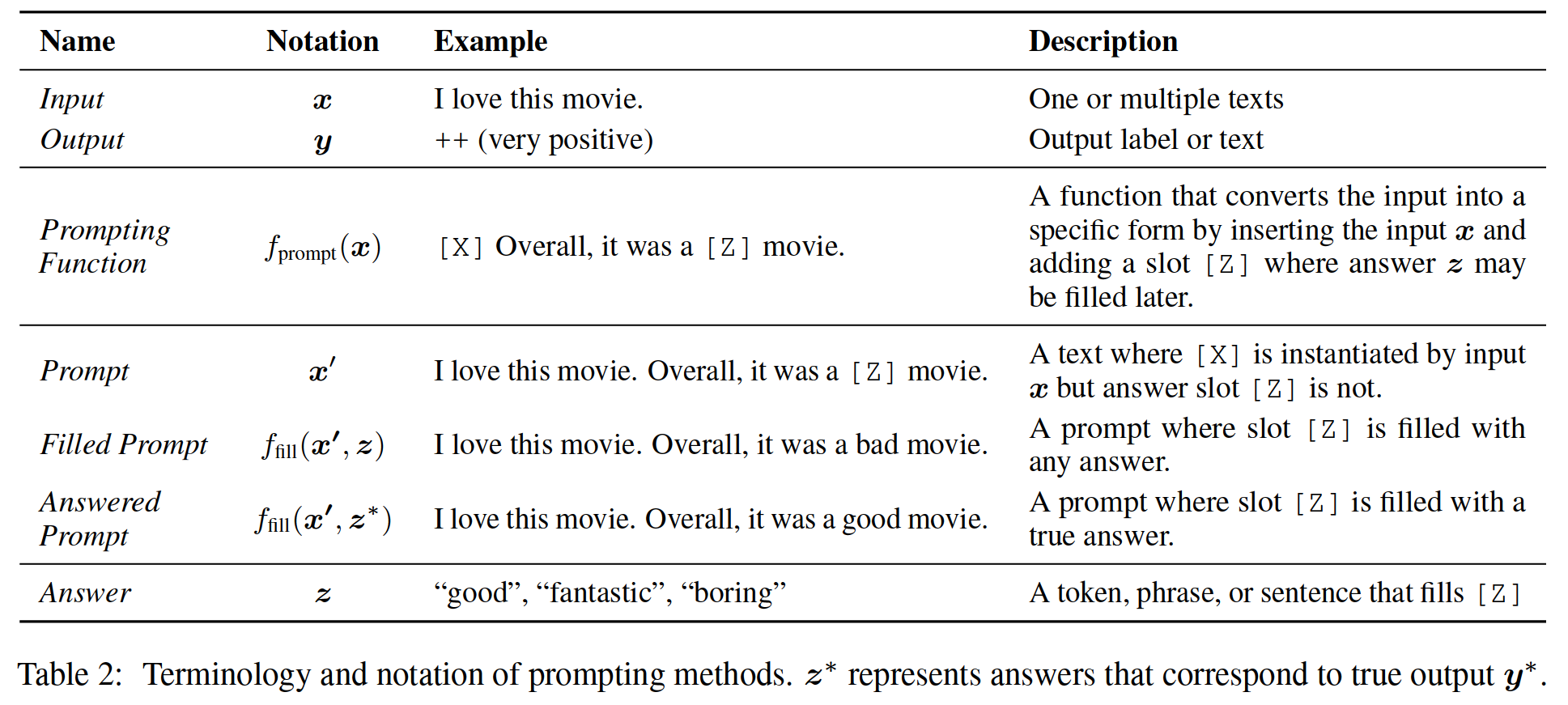
then , Define a function f fill ( x ′ , z ) f_{\text {fill }}\left(\boldsymbol{x}^{\prime}, \boldsymbol{z}\right) ffill (x′,z) , Use possible answers z \boldsymbol{z} z Fill tips x ′ \boldsymbol{x}^{\prime} x′ Position in [Z]. We will call any prompts that go through this process (prompt) As a filling prompt (prompt). especially , If the prompt is filled with the true answer , Call it the answered prompt (answered prompt)( surface 2 Shows an example ). Last , We use pre trained LM P ( ⋅ ; θ ) P(\cdot ; \theta) P(⋅;θ) Calculate the probability of the corresponding filling prompt to search the potential answer set z \boldsymbol{z} z .
z ^ = search z ∈ Z P ( f fill ( x ′ , z ) ; θ ) \hat{\boldsymbol{z}}=\operatorname{search}_{\boldsymbol{z} \in \mathcal{Z}} P\left(f_{\text {fill }}\left(\boldsymbol{x}^{\prime}, \boldsymbol{z}\right) ; \theta\right) z^=searchz∈ZP(ffill (x′,z);θ)
This search function can be the output with the highest search score argmax Search for , It can also be based on LM The probability distribution of randomly generated output samples .
2.3 Answer mapping
Last , Think of the answer with the highest score z ^ \hat{\boldsymbol{z}} z^ To the output with the highest score y ^ \hat{\boldsymbol{y}} y^ . In some cases , It's very simple , Because the answer itself is output ( For example, in language generation tasks , Such as translation ), But in other cases , Multiple answers may lead to the same output . for example , You can use many different emotional words ( for example “ good ”、“ Mythical ”、“ Wonderful ”) To represent a single category ( for example “+”), under these circumstances , It is necessary to map between the search answer and the output value .
3、 Tips (Prompting) Design considerations for
Now? , We already have the basic mathematical formula , We will explain some basic design considerations , These considerations will enter the prompt (prompting) Method , We will elaborate in the following sections :
chart 1: Tips (prompting) Type of method 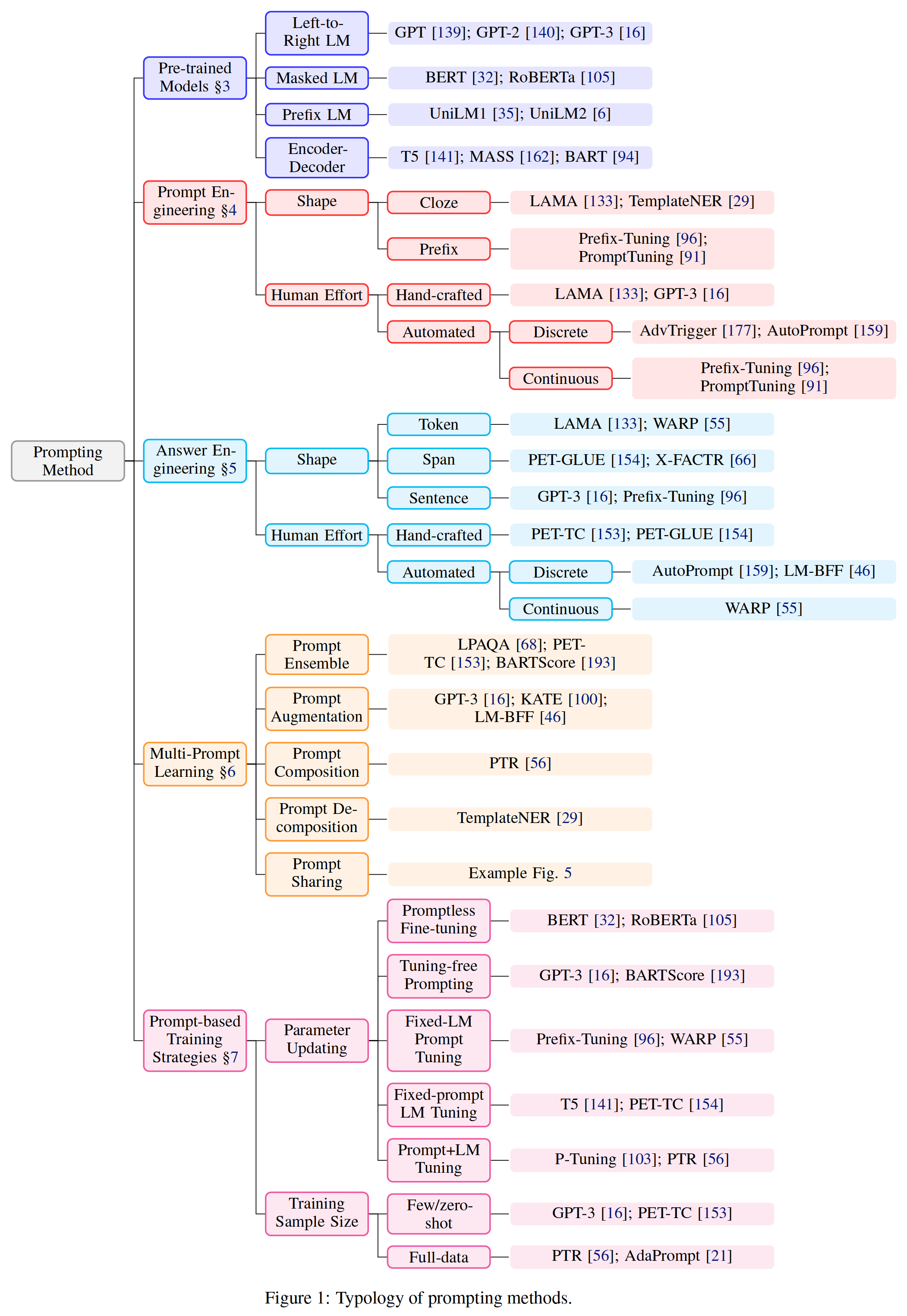
3.1 Pre training model selection
Pre training model selection : There are many kinds of pre training LMs Can be used to calculate P ( x ; θ ) P(\boldsymbol{x} ; \theta) P(x;θ). In the figure 1 §3 in , Introduced the pre trained LMs, Especially for the explanation, it is prompting (prompting) The utility in the method is a very important dimension .
3.2 Prompt design (Prompt Engineering)
Prompt design (Prompt Engineering): If you are prompted (prompt) Assigned task , Then choosing the right prompt not only has a great impact on accuracy , And it also has a great impact on the first task of the model . In the figure 1 §4 in , Discussed choosing which prompt to use as f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) Methods .
3.3 Answer design
Answer design : Depending on the task , We may want to design different Z \mathcal{Z} Z, There may also be mapping function . In the figure 1 §5 in , Different methods are discussed .
3.4 Extended paradigm
Extended paradigm : As mentioned above , The above equation represents only for achieving this prompting And the simplest of the various underlying frameworks proposed . In the figure 1 §6 in , This paper discusses the methods of extending this basic paradigm , To further improve the results or applicability .
3.5 Based on tips (prompt) Training strategies
Based on tips (prompt) Training strategies : There are also methods of training parameters , It can be a hint 、LM Or both . In the figure 1 §7 in , The paper summarizes different strategies , And their comparative advantages are introduced in detail .
3、 ... and 、 Pre trained language model
In view of pre training LMs In the pre training and fine tuning paradigm NLP A huge impact . The paper will focus on the main training objectives 、 Text noise type 、 Auxiliary training objectives 、 Attention mask 、 The typical architecture and preferred application scenarios are introduced in detail .
1、 Training objectives
Preliminary training LM The main training goal is almost always predicted by the text x \boldsymbol{x} x Some kind of goal composition of probability .
Standard language model (SLM) Our goal is to do just that , Training model to optimize the probability of text in the training corpus P ( x ) P(\boldsymbol{x}) P(x) . In these cases , Text is usually predicted by autoregression , Predict the markers in the sequence one at a time . This is usually done from left to right ( As follows ), But it can also be done in other order .
standard LM A popular alternative to targets is to denoise targets , The target will have some de-noising functions x ~ = f noise ( x ) \tilde{\boldsymbol{x}}=f_{\text {noise }}(\boldsymbol{x}) x~=fnoise (x) Apply to input sentences , Then give the noisy text P ( x ∣ x ~ ) P(\boldsymbol{x} \mid \tilde{\boldsymbol{x}}) P(x∣x~) Under the circumstances , Try to predict the original input sentence . There are two common styles of these goals :
- Damaged text reconstruction (CTR) These goals are achieved by calculating the loss of only the noisy part of the input sentence , Restore the processed text to its undamaged state .
- Full text reconstruction (FTR) These goals reconstruct the text by calculating the loss of the entire input text , Whether there is noise in the input text .
In the process of the training LMs The main training objectives of play an important role in determining their applicability to specific cue tasks . for example :
- Autoregression from left to right LMs It may be especially suitable for prefix hints (prefix prompts),
- The reconstruction goal may be more suitable for cloze tips (cloze prompts).
Besides , Use standards LM and FTR The model of target training may be more suitable for text generation tasks , And other tasks ( Such as classification ) Models that use any of these goal training can be used to develop .
2、 Noise types
surface 4: Detailed examples of different noise operations

In the training goal based on reconstruction , Used to get noisy text x ~ \tilde{\boldsymbol{x}} x~ The specific type of damage will affect the effect of the learning algorithm . Besides , Prior knowledge can be integrated by controlling the type of noise , for example , Noise can be concentrated on the substance of a sentence , This allows us to learn pre training models with particularly high prediction performance for entities . This paper introduces several types of ways to increase noise , And on the table 4 Detailed examples are given in .
- Mask (Masking), The text will be masked at different levels , Use a special token( Such as [MASK] Replacing a token Or more tokens fragment . It is worth noting that , The mask can be a random mask from some distribution , It can also be a mask specially designed to introduce prior knowledge , For example, the above example of masked entities , To encourage models to be good at predicting entities .
- Replace (Replacement) Substitution is similar to mask , The difference is token or multi-token span Not with [MASK] Replace , It's using another token Or pieces of information .
- Delete (Deletion) token or multi-token The clip will be deleted from the text , Without adding [MASK] Or any other token. This operation is usually associated with FTR loss Use it together .
- array (Permutation) First, divide the text into different segments (tokens、 Sub sentence fragments or sentences ), Then arrange these fragments into new text .
3、 The directionality of expression
In understanding pre training LMs And their differences , The last important factor to consider is the directionality of the calculation . Usually , There are two widely used methods to calculate such representations :
- From left to right (Left-to-Right), The representation of each word is calculated according to the word itself and all the previous words in the sentence . for example , If we have a sentence “ This is a good movie ”, that “ good ” The expression of a word will be calculated according to the previous word . In the calculation standard LM Goal or calculation FTR The output of the target , This factorization is particularly widely used .
- two-way (Bidirectional), Based on all the words in the sentence ( Include the word to the left of the current word ) Calculate the representation of each word . In the example above ,“ good ” Will be affected by all the words in the sentence , Even below “ The movie ”.
In addition to the above two most common directions , You can also mix these two strategies in one model , Or adjust the representation in a random order , Although these strategies are not widely used . It is worth noting that , When implementing these strategies in neural models , This adjustment is usually achieved through the attention mask , It masks the values in the attention model , For example, popular Transformer framework (Vaswani et al.,2017). chart 2 Shows some examples of such attention masks .
chart 2: Three popular attention mask modes , Subscript t It means the first one t Time steps .(i,j) The shaded box at indicates that the attention mechanism is allowed to output time steps j Focus on input elements i. The white box indicates that the attention mechanism is not allowed to pay attention to the corresponding i and j Combine .

4、 Typical pre training methods
Here are four popular pre training methods , They come from the target 、 Different combinations of noise function and directivity .
It is described below , And in the picture 3 And table 5 In the summary .
chart 3: Preliminary training LMs A typical example of 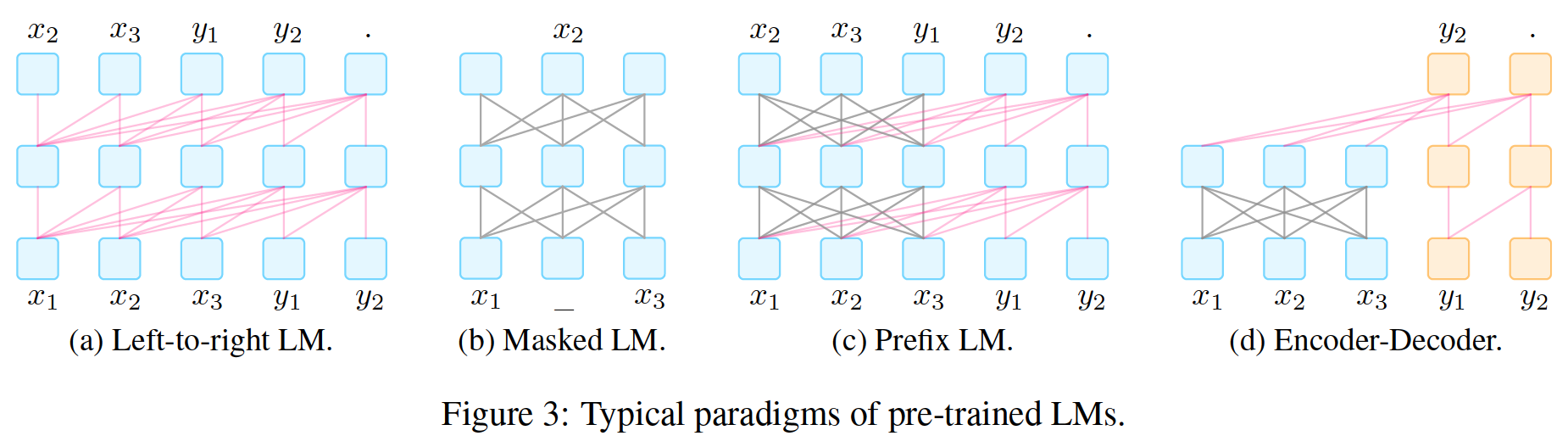
surface 5: Preliminary training LMs The typical architecture of .x and y Represent the text to be encoded and decoded respectively .SLM: Standard language model .CTR: Damaged text reconstruction .FTR: Full text reconstruction .†: Encoder decoder architecture usually only applies the objective function to the decoder .

4.1 Left to right language model
From left to right LMs(L2R LMs) It's a kind of autoregression LM, Predict upcoming words , Or a sequence of words x = x 1 , ⋯ , x n \boldsymbol{x}=x_{1}, \cdots, x_{n} x=x1,⋯,xn Distribution probability P ( x ) P(\boldsymbol{x}) P(x) . Usually, the chain rule from left to right is used to decompose the probability : P ( x ) = P ( x 1 ) × ⋯ P ( x n ∣ x 1 ⋯ x n − 1 ) P(\boldsymbol{x})=P\left(x_{1}\right) \times \cdots P\left(x_{n} \mid x_{1} \cdots x_{n-1}\right) P(x)=P(x1)×⋯P(xn∣x1⋯xn−1) . From left to right LMs Include GPT-3 and GPT-Neo etc. .
4.2 Mask language model
Although autoregressive language model provides a powerful tool for probabilistic modeling of text , But they also have shortcomings , For example, it is required to calculate the representation from left to right . When the focus shifts to downstream tasks ( Such as classification ) When generating the best representation , Many other options become possible , And it is usually preferable . A popular bi-directional objective function widely used in representational learning is the mask language model (MLM;Devlin et al.(2019)), The model aims to predict the mask text segment according to the surrounding context . for example , P ( x i ∣ x 1 , … , x i − 1 , x i + 1 , … , x n ) P\left(x_{i} \mid x_{1}, \ldots, x_{i-1}, x_{i+1}, \ldots, x_{n}\right) P(xi∣x1,…,xi−1,xi+1,…,xn) A word that represents a given surrounding context x i x_i xi Probability .
Use MLM The representative pre training models of include :BERT(Devlin wait forsomeone ,2019)、ERNIE(Zhang wait forsomeone ,2019;Sun wait forsomeone ,2019b) And many variants .
In the prompt method ,MLM It is usually best suited for natural language understanding or analysis tasks ( for example , Text classification 、 Natural language reasoning and extraction question answering ). These tasks are usually relatively easy to reformulate as cloze questions , This is consistent with the traditional training goal . Besides , Exploring will prompt When combined with fine tuning ,MLMs It is a pre trained selection model .
4.3 Prefix and codec
For conditional text generation tasks , Such as translation and abstract , Where input text x = x 1 , ⋯ , x n \boldsymbol{x}=x_{1}, \cdots, x_{n} x=x1,⋯,xn It is given. , The goal is to generate target text y \boldsymbol{y} y , We need a pre training model , This model can encode the input text , It can also generate output text . So , There are two popular architectures that share a common thread :(1) Use the encoder with full connection mask to check the source first x \boldsymbol{x} x Encoding , then (2) To the goal y \boldsymbol{y} y Do autoregressive decoding ( From left to right ).
- Prefix language model , Prefix LM It's a left to right LM, In prefix sequence x \boldsymbol{x} x For conditional pair y \boldsymbol{y} y decode , The sequence is encoded by the same model parameters , But with a fully connected mask . It is worth noting that , To encourage prefixes LM Learn better input representation , except y \boldsymbol{y} y Beyond the standard conditional language modeling goal , Usually in x \boldsymbol{x} x Apply corrupted text to rebuild the target .
- Encoder - decoder , Encoder - The decoder model is used from left to right LM Decoded model , Conditions y \boldsymbol{y} y It's the text x \boldsymbol{x} x The separate encoder of has a fully connected mask ; The parameters of encoder and decoder are not shared . And prefix LM similar , You can input x \boldsymbol{x} x Apply different types of noise .
UniLM 1-2(Dong et al.,2019;Bao et al.,2020) and ERNIE-M(Ouyang et al.,2020) Prefix is used in LMs, And the encoder - Decoder models are widely used in pre training models , Such as T5(Raffel et al.,2020)、BART(Lewis et al.,2020a)、MASS(Song et al.,2019) And its variants .
With a prefix LMs And the pre training model of codec example can be naturally used The text generated Mission , Use the input text to promting(Dou wait forsomeone ,2021) Or not promting(Yuan wait forsomeone ,2021a;Liu and Liu,2021).
However , Recent research shows that , Other non build tasks , Such as information extraction (Cui et al.,2021)、 Question and answer (Khashabi et al.,2020) And text generation evaluation (Yuan et al.,2021b), You can rephrase the generation problem by providing appropriate prompts .
therefore ,promting Method
- It widens the applicability of these generation oriented pre training models . for example , image BART Such a pre training model is in NER Less used in , and promting Method makes BART apply ,
- It breaks the difficulty of unified modeling between different tasks (Khashabi et al.,2020).
Four 、 Tips (Prompt) Design
Prompt design (Prompt engineering) Is to create a prompt function f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) The process of , This function can produce the most effective performance in downstream tasks .
In many previous jobs , This involves prompt Formwork design , That is, people or algorithms search for the best template for each task the model is expected to perform . Pictured 1 Of “Prompt Engineering” As shown in section , Must first consider prompt shape, Then decide whether to create the required type manually or automatically prompt, As follows .
1、 Type of tip (Prompt shape)
As mentioned above , There are two main types of prompts : Cloze prompt(Petroni et al.,2019;Cui et al.,2021), Used to fill the blank space of the text string ; Prefix prompt(Li and Liang,2021;Lester et al.,2021), Used to continue the string prefix . Which one to choose depends on the task and the model used to solve the task . Usually , For generation related tasks , Or use standard autoregression LM The task to be solved , Prefix hints are often more useful , Because they match the left to right characteristics of the model very well . For using masks LMs The task to be solved , Cloze tips are great for , Because they match the form of pre training tasks very well . The full-text reconstruction model is more general , It can be used with cloze or prefix prompts . Last , For some tasks involving multiple inputs , Such as text pair classification , Prompt template must contain two input spaces ,[X1] and [X2], Or more .
2、 Manual template design
Maybe create a hint (prompt) The most natural way is to manually create intuitive templates based on human introspection . for example :
- Groundbreaking LAMA Data sets (Petroni et al.,2019) Provides a manually created cloze template , To explore LMs Knowledge in .
- Brown wait forsomeone (2020 year ) Create a handmade prefix prompt (prompt), To handle various tasks , Including Q & A 、 The detection task of translation and common sense reasoning .
- Schick and Sch̉utze(2020、2021a、b) Use predefined templates in a small number of snapshot learning settings for text classification and conditional text generation tasks .
3、 Automatic template learning
Although the strategy of making templates by hand is intuitive , And allow various tasks to be solved with a certain degree of accuracy , But this method also has some problems :
- Creating and experimenting with these tips is an art that takes time and experience , Especially for some complex tasks , Such as semantic analysis (Shin wait forsomeone ,2021);
- Even experienced prompt designers may not be able to find the best prompt manually (Jiang wait forsomeone ,2020c).
To solve these problems , Many methods have been proposed to automate the template design process . especially , Automatically generated prompts can be further divided into :
- Discrete prompt ( The prompt is the actual text string );
- Continuous prompt ( The prompt is directly at the bottom LM Description in the embedded space of );
Another orthogonal design consideration is the cue function f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) Is static , Use basically the same prompt template for each input , It's still dynamic , Generate a custom template for each input . Both static and dynamic strategies are used for different kinds of discrete and continuous prompts , The paper will be mentioned below .
3.1 Discrete prompt (Discrete Prompts)
D1:Prompt Mining
Jiang wait forsomeone (2020c) The mining method of is a mining based method , You can enter in a given set of training x \boldsymbol{x} x And the output y \boldsymbol{y} y Automatically find the template . This method is from a large text corpus ( Like Wikipedia ) Extract contains x \boldsymbol{x} x and y \boldsymbol{y} y String , And find the middle word or dependent path between input and output . Frequent intermediate words or dependent paths can be used as templates , Such as “[X] Intermediate word [Z]”.
D2: Prompt Paraphrasing
The interpretation based method uses existing seed hints ( For example, build or mine manually ), And interpret it as a set of other candidate tips , Then select the prompt that achieves the highest training accuracy on the target task . This interpretation can be accomplished in many ways , Including translating prompts into another language , Then translate it back (Jiang wait forsomeone ,2020c), Replace with phrases from thesaurus (Yuan wait forsomeone ,2021b), Or use a specially optimized neural prompt rewriter , To improve the accuracy of the system using prompts (Haviv wait forsomeone ,2021). It is worth noting that ,Haviv wait forsomeone (2021) Enter x \boldsymbol{x} x Enter the prompt template and repeat , Allow different retells to be generated for each individual input .
D3: Gradient-based Search
Wallace et al.(2019a) For reality token Gradient based search , To find out what can trigger basic pre training LM Generate a short sequence of desired target predictions . This search is done iteratively , Step through the prompt to search for tags .Shin et al.(2020) Based on this method , Use downstream application training samples to automatically search for templates tokens, And show strong performance in the prompt scene .
D4: Prompt Generation
Other work regards the generation of prompts as text generation tasks , And use the standard natural language generation model to perform this task . for example ,Gao wait forsomeone (2021) take seq2seq Pre training model T5 Introduce the template search process . because T5 Has been pre trained on the task of filling in the missing span , They use T5 Generate template tags (tokens), The method is
- Specify where to insert the template tag in the template
- by T5 Provide training samples marked by decoding template .
Ben David wait forsomeone (2021) A domain adaptive algorithm is proposed , The algorithm is trained T5 Generate unique domain related features for each input (DRF; A set of keywords that describe domain information ). then , You can put these DRF Connect with input , Form a template , For further use by downstream tasks .
D5: Prompt Scoring
Davison wait forsomeone (2019 year ) Studied the tasks completed by the knowledge base , And use LMs For input ( head - Relationship - Tail triples ) Designed a template . They first handmade a set of templates as potential candidates , Then fill in the input and answer slots , Form a fill prompt . then , They use one-way LM Rate the completed prompts , choice LM Tips with the highest probability . This will generate a custom template for each individual input .
3.2 Continuous prompt (Continuous Prompts)
Because the purpose of prompt construction is to find a method , send LM Be able to perform tasks effectively , Not for human use , Therefore, it is not necessary to limit prompts to human interpretable natural language .
therefore , There are also some ways to check whether the prompt is executed directly in the model embedding space continuous prompts( Also known as soft prompts)).
say concretely , Continuous prompts eliminate two constraints :
- Relaxing the embedding of template words is natural language ( Such as English ) Embedded constraints of words .
- Cancel template by pre trained LM Limitations of parameterization . contrary , The template has its own parameters , It can be adjusted according to the training data of downstream tasks .
The following paper focuses on several representative methods :
- C1: Prefix adjustment
Prefix adjustment (Li and Liang,2021) It is a method of adding a continuous sequence of task specific vectors to the input in advance , Keep at the same time LM Parameter freezing . Mathematically speaking , This is included in the given trainable prefix matrix M ϕ M_{\phi} Mϕ And from θ \theta θ Parameterized fixed pre training LM Under the circumstances , Optimize the following log likelihood objectives .
max ϕ log P ( y ∣ x ; θ ; ϕ ) = max ϕ ∑ y i log P ( y i ∣ h < i ; θ ; ϕ ) \max _{\phi} \log P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta ; \phi)=\max _{\phi} \sum_{y_{i}} \log P\left(y_{i} \mid h_{<i} ; \theta ; \phi\right) ϕmaxlogP(y∣x;θ;ϕ)=ϕmaxyi∑logP(yi∣h<i;θ;ϕ)
In the equation 2 in , h < i = [ h < i ( 1 ) ; ⋯ ; h < i ( n ) ] h_{<i}=\left[h_{<i}^{(1)} ; \cdots ; h_{<i}^{(n)}\right] h<i=[h<i(1);⋯;h<i(n)] It's the time step i i i Series connection of all neural network layers . If the corresponding time step is within the prefix ( h i h_i hi yes M ϕ [ i ] M_{\phi}[i] Mϕ[i] ), Directly from M ϕ M_{\phi} Mϕ Copy , Otherwise use pre trained LM Calculation .
In the experiment ,Li and Liang(2021) The observed , This prefix based continuous learning is more sensitive to different initializations in low data environments than discrete prompts using notional words .
Similarly ,Lester wait forsomeone (2021) Preset input sequence with special marks , To form a template and directly adjust the embedding of these marks . And Li and Liang(2021) Compared with , This method adds fewer parameters , Because it will not introduce additional adjustable parameters in each network layer .Tsinpoukelli wait forsomeone (2021) Trained a visual encoder , The encoder encodes the image into a series of embedded , Can be used to prompt frozen autoregression LM Generate appropriate subtitles . They show that , The result model can be applied to visual language tasks ( Such as visual question and answer ) Perform a small amount of lens learning . Different from the above two works , stay (Tsinpoukelli et al.,2021) The prefix used in depends on the sample , That is, the representation of the input image , Instead of task embedding . - C2: Use discrete prompts to initialize adjustments
There are also ways to initialize the search for continuous prompts using prompts that have been created or found using the discrete prompt search method .
for example ,Zhong wait forsomeone (2021b) First use things like AUTOPROMPT(Shin wait forsomeone ,2020) Discrete search method definition template , Initialize the virtual according to the prompt found tokens, Then fine tune the embedding to improve the accuracy of the task . This work found , Using manual template initialization can provide a better starting point for the search process .Qin and Eisner(2021) It is recommended to learn a mixed soft template for each input , The weights and parameters of each template are jointly learned using training samples . The initial set of templates they use is either handmade templates , Or use “ Prompt mining ” Method . Similarly ,Hambardzumyan wait forsomeone (2021) The use of continuous formwork is introduced , Its shape follows the manual prompt template . - hard - Soft prompt hybrid adjustment
These methods do not use pure learnable prompt templates , Instead, insert some adjustable embedments into the hard prompt template .Liu wait forsomeone (2021b) Put forward “P-tuning”, That is, learning continuous prompts by inserting trainable variables into embedded input . To illustrate the interaction between prompt tags , They represent hint embedding as BiLSTM Output (Graves et al.,2013).P-tuning It also introduces the use of task related anchor tags in templates ( For example, in relation extraction “capital”), To further improve . These anchor marks were not adjusted during training .Han wait forsomeone (2021) Proposed rule prompt tuning (PTR), It uses handmade sub templates , Use logical rules to form a complete template . To enhance the presentation ability of the result template , They also inserted several virtual tokens, These virtual tokens The embedding of can use training samples and pre trained LMs Parameters are adjusted together .PTR The template token in contains the actual tokens and tokens. Experimental results demonstrate the effectiveness of this rapid design method in relation classification tasks .
5、 ... and 、 Answer design
It is different from designing a prompt design with appropriate input for the prompt method , The answer is designed to search the answer space Z \mathcal{Z} Z And raw output Y \mathcal{Y} Y Mapping , So as to generate an effective prediction model . chart 1 Of “ Answer design ” This part explains two aspects that must be considered when implementing the answer project :
- Determine the granularity of the answer ;
- Choose the answer design method ;
1、 Answer granularity
In practice , How to choose the granularity of acceptable answers depends on the task we want to perform .
- Tokens: In the process of the training LM One of the vocabularies token, Or a subset of the vocabulary .
- Span: A short multi-token fragment . These tips are usually used with cloze tips .
- Sentence: A sentence or document . These are usually used with prefix hints .
token Or text range answer space is widely used in classification tasks ( for example , Emotional categories ;Yin wait forsomeone (2019)), But it can also be used for other tasks , Such as relation extraction (Petroni wait forsomeone ,2019) Or named entity recognition (Cui wait forsomeone ,2021).
Long phrase or sentence answers are usually used in language generation tasks (Radford et al.,2019), But it can also be used for other tasks , Such as answering multiple-choice questions ( The scores of multiple phrases are compared with each other ;Khashabi et al.(2020)).
2、 Answer space design method
The next question to answer is , If the answer is not used as the final output , How to design an appropriate answer space Z \mathcal{Z} Z And to the output space Y \mathcal{Y} Y Mapping .
2.1 Manual design
In manual design , Space for potential answers Z \mathcal{Z} Z And to Y \mathcal{Y} Y The mapping of is manually built by interested system or benchmark designers . You can take a variety of strategies to implement this design .
- Unconstrained space
- in many instances , Answer space Z \mathcal{Z} Z Are all marks (Petroni et al.,2019)、 Fixed length span (Jiang et al.,2020a) Or tag sequence (Radford et al.,2019) Space . In these cases , The most common is to use identity mapping to put the answer Z \mathcal{Z} Z Map directly to the final output Y \mathcal{Y} Y .
- Confined space
However , There are also cases where the output space may be constrained . This is usually used for tasks with limited tag space , Such as text classification or entity recognition , Or multiple choice question answering system .
To illustrate ,Yin wait forsomeone (2019) Manually designed related topics (“ health ”、“ Finance ”、“ Politics ”、“ sports ” etc. )、 mood (“ anger ”、“ Joy ”、“ sad ”、“ Fear ” etc. ) Or a list of words related to other aspects of the text to be classified .Cui wait forsomeone (2021) Manual design NER List of tasks , Such as “ personnel ”、“ Location ” etc. . In these cases , It is necessary to answer Z \mathcal{Z} Z And basic classes Y \mathcal{Y} Y Mapping between .
Answer about multiple choice questions , Usually use LM To calculate the output probability in multiple selection ,Zweig et al.(2012) This is an early example .
2.2 Discrete answer search
Same as the prompt created manually , Manually created answers are important for getting LM It may be suboptimal in terms of achieving ideal prediction performance . therefore , There is some work in automatic answer search , Although less work than searching for ideal tips . These functions are also applicable to discrete answer spaces ( In this section, ) And continuous answer space ( following ).
Explanation of the answer (Answer Paraphrasing) These methods start from the initial answer space Z ′ \mathcal{Z}^{\prime} Z′ Start , Then use free translation to expand the answer space to expand its coverage (Jiang wait forsomeone ,2020b). Give a pair of answers and output * z ′ , y * \left\langle\boldsymbol{z}^{\prime}, \boldsymbol{y}\right\rangle *z′,y* , Let's define a function , This function generates a set of explained answers z ′ z^{\prime} z′ . The probability of the final output is defined as the marginal probability of all the answers in the interpretation set P ( y ∣ x ) = ∑ z ∈ nara ( z ′ ) P ( z ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x})=\sum_{\boldsymbol{z} \in \operatorname{nara}\left(\boldsymbol{z}^{\prime}\right)} P(\boldsymbol{z} \mid \boldsymbol{x}) P(y∣x)=∑z∈nara(z′)P(z∣x) . This interpretation can be done in any way , but Jiang wait forsomeone (2020b) Special use of back translation , First translate into another language , Then back translate , To generate a list of multiple paraphrase answers .
Prune and search (Prune-then-Search) In these methods , First, generate multiple plausible answers Z ′ \mathcal{Z}^{\prime} Z′ Initial pruning answer space , Then the algorithm searches further on the pruned space to select the final answer set . Please note that , In some papers introduced below , They defined a label from y \boldsymbol{y} y To single answer mark z \boldsymbol{z} z Function of , This tag is often called a descriptor (Schick and Sch̉utze,2021a).Schick and Sch̉utze(2021a);
- Schick wait forsomeone (2020 year ) A tag containing at least two alphabetic characters was found , These characters are common in large unlabeled datasets . In the search step , They maximize the possibility of training data by labeling , Iteratively calculate words as labels y \boldsymbol{y} y The representative answer z \boldsymbol{z} z The applicability of .
- Shin wait forsomeone (2020 year ) Use [Z] The context representation of the tag is used as input to learn the logic classifier . In the search step , They use learning in the first step logistic The classifier selects the top with the highest probability score k A sign . These selected tags will form the answer .
- Gao wait forsomeone (2021) First, a pruned search space is constructed Z ′ \mathcal{Z}^{\prime} Z′, Determined according to the training samples [Z] Generation probability of position , Choose the former k A vocabulary . then , According to the training sample zero-shot precision , Choose only Z ′ \mathcal{Z}^{\prime} Z′ A subset of , Further reduce the search space . In the search step , They use fixed templates and each answer mapping pair using training data LM Fine tuning , And choose the best tag word as the answer according to the accuracy of the development set .
Label decomposition (Label Decomposition) When performing relationship extraction ,Chen wait forsomeone (2021b) It will automatically decompose each relationship label into its constituent words , And use it as an answer . for example , about per:city_of_death The relationship between , The decomposed tag word will be {person,city,death}. The probability of the answer range will be calculated for each token Sum of probabilities .
2.3 Continuous answer search
Few works discuss the use of soft response token The possibility of , Soft response token It can be optimized by gradient descent .
Hambardzumyan wait forsomeone (2021) Assign each category label a virtual token, And optimize each category token Embed and prompt token The embedded , Because the answer token Optimize directly in the embedded space , They don't use LM The embeddedness of learning , Instead, learn to embed for each tag from scratch .
6、 ... and 、 More tips (Multi-Prompt) Study
up to now , The hint engineering method discussed in this paper mainly focuses on building a single hint of input . However , A lot of research shows that , Using multiple prompts can further improve the effectiveness of the prompt method , These methods are called multi cue learning methods .
In practice , There are several ways to extend single prompt learning to multiple prompts , These tips have multiple motivations . We are in the picture 1 Sum graph 4 Of “ More tips to learn ” Some representative methods are summarized .
chart 4: Different multi cue learning strategies . We use different colors to distinguish different components , Use the following abbreviations ,“PR” A hint ,“Ans PR” Indicates the answer prompt ,“Sub PR” Indicates sub prompt 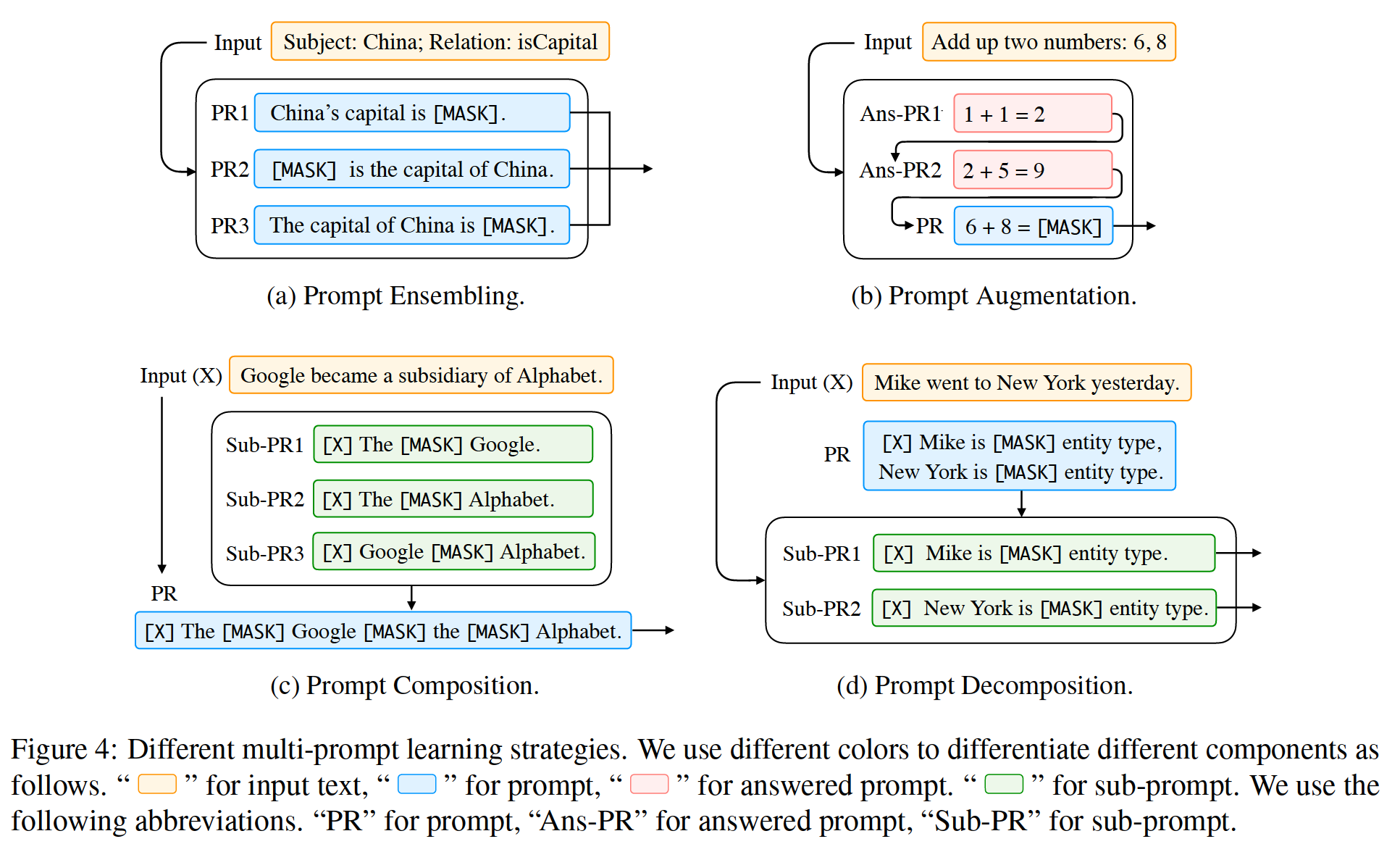
1、 Tips (Prompt) Integrate
Prompt ensembling It is the process of using multiple unanswered prompts to predict the input during reasoning . chart 4-(a) An example is shown in . Multiple prompts can be discrete prompts , It can also be a continuous prompt . This rapid integration can (1) Take advantage of the complementary advantages of different tips ,(2) Reduce the cost of rapid design , Because choosing a tip with the best performance is very challenging ,(3) Stabilize the performance of downstream tasks .
Instant sensing is related to the sensing method used to combine multiple systems , These systems have a long history in machine learning (Ting and Witten,1997;Zhou wait forsomeone ,2002;Duh wait forsomeone ,2011). The current research also draws on the ideas of these works , An effective method of rapid integration is obtained , As follows .
7、 ... and 、 Tips (Prompting) Method training strategy
Use the method in the above section , Now you can clearly understand how to get appropriate tips and corresponding answers . Now? , This paper discusses the method of explicit training model consistent with the prompt method , Pictured 1 Of “ Training strategy ” Described in part .
1、 Training settings
in many instances , You can use the prompt method , There is no need for downstream tasks LM Do any specific training , Just use trained LM To predict text P ( x ) P(\boldsymbol{x}) P(x) Probability , And apply it as is to fill in the cloze or prefix prompts defined for the specified task . This is often referred to as zero-shot Set up , Because there is no training data for the task of interest .
However , There are also ways to use training data to train models , And cooperate with the prompt method . These include complete data learning , Many training examples are used to train the model , Or use a few examples to train the model few-shot learning. In the latter case , Tips are particularly useful , Because there are usually not enough training examples to completely specify the required behavior , Therefore, using prompts to push the model in the right direction is particularly effective .
One thing to note is that , about §4 Many of the tip engineering methods described in , Although the annotated training samples are not explicitly used for the training of downstream task models , But they are usually used to build or verify the hints that downstream tasks will use . just as Perez et al.(2021) Pointed out , It can be said that this is not really about downstream tasks zero-shot learning.
2、 Parameter update method
In prompt based downstream task learning , There are usually two types of parameters , From :
- Pre training model ;
- Prompted parameters ;
Which part of the parameters should be updated is an important design decision , This may lead to different levels of applicability in different scenarios .
The paper summarizes five adjustment strategies ( As shown in the table 6 Shown )(i) Whether the foundation has been adjusted LM Parameters of ,(ii) Whether there are additional prompt related parameters ,(iii) If there are additional prompt related parameters , Whether these parameters have been adjusted .
surface 6: Characteristics of different adjustment strategies .“Additional”( additional ) Express LM Whether there are other parameters besides parameters ,“Tuned”( adjustment ) Indicates whether the parameter is updated .
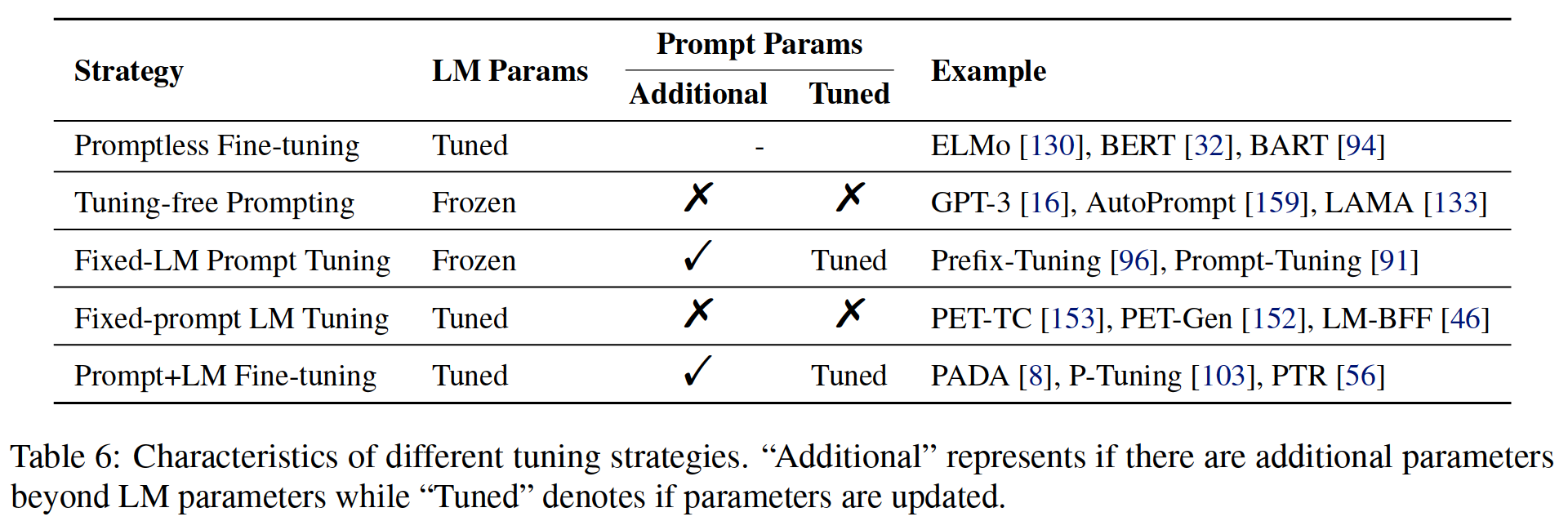
2.1 Promptless Fine-tuning
Before the popularization of self prompt method , Pre training and fine-tuning strategies have been widely used in NLP. ad locum , We call silent pre training and fine tuning promptless fine-tuning, In contrast to the cue based learning method introduced in the following section .
In this strategy , Given a task data set , all ( Or part of it (Howard and Ruder,2018;Peters et al.,2019)) Preliminary training LM The parameters of will be updated by introducing gradients from downstream training samples .
Typical examples of pre training models adjusted in this way include BERT and RoBERTa.
It's a simple 、 Powerful and widely used methods , But it may over fit or learning instability on small data sets (Dodge et al.,2020). Models are also prone to catastrophic forgetting ,LM Lost the ability to do what you can do before fine-tuning (McCloskey and Cohen,1989).
The advantage is simplicity , There is no need to prompt Design . Adjust all LM Parameters can make the model adapt to a larger training data set . The disadvantage is that LMs It may be over fitting or unstable to learn on a small data set .
2.2 Tuning-free Prompting
Generate the answer directly without adjustment prompt , Just follow the prompts without changing the pre trained LMs Parameters of , Such as §2 The simplest form of prompt in . Such as §6.2 Described , You can choose to use the answer prompt to add input , This combination of unadjusted cues and increased cues is also known as context learning (Brown et al.,2020).
No adjustment prompt Typical examples of include LAMA【133】 and GPT-3【16】.
- The advantage is high efficiency , No parameter update process is required . There is no catastrophic forgetting , because LM The parameters remain unchanged . Apply to zero-shot learning.
- The disadvantage is that prompt is the only way to provide task specification , Therefore, a lot of engineering design is needed to achieve high accuracy . Especially in context learning environments , It may be slow to provide many answer tips during the test , Therefore, large training data sets cannot be easily used
2.3 Fixed-LM Prompt Tuning
In addition to the parameters of the pre training model, other scenarios that prompt relevant parameters are also introduced , Fix LM Prompt adjustment uses the monitoring signal obtained from the downstream training samples to update only the prompted parameters , While maintaining the entire pre training LM unchanged . A typical example is Prefix-Tuning and WARP.
- The advantage is similar to no adjustment prompt , It can keep LMs Knowledge in , Apply to few-shot scene . It is usually more accurate than no adjustment prompt .
- The disadvantage is that Do not apply to zero-shot scene . Although in few-shot Effective in the scene , However, in big data settings, the representation ability is limited . It is necessary to prompt the project by selecting super parameters or seed prompts . The prompt can not be explained or operated manually .
2.4 Fixed-prompt LM Tuning
Fixed-prompt LM adjustment LM Parameters of , Just like in the standard pre training and fine tuning examples , But you also use prompts with fixed parameters to specify model behavior . This may lead to improvement , Especially in few-shot Scene .
The most natural way is to provide a discrete text template , Apply to every training and test example . Typical examples include PET-TC、PET-Gen、LM-BFF.
Logan IV wait forsomeone (2021) Recently observed , By allowing answers to engineering and parts LM Fine tuning , Can reduce prompt design . for example , They defined a very simple template ,null prompt, The input and mask are directly connected “[X][Z]”, There are no template words , And found that this can achieve competitive accuracy .
- The advantage is to prompt or answer the project to assign tasks more comprehensively , Allow more effective learning , Especially in a few scenes .
- The disadvantage is that although it may not be as much as there are no hints , But still need prompt or answer design . Fine tune a downstream task LMs It may not work for another task .
2.5 Prompt+LM Tuning
In this setting , Relevant parameters will be prompted , These parameters can be fine tuned together with all or part of the parameters of the pre training model . Representative examples include PADA、P-Tuning.
It is worth noting that , This setting is very similar to the standard pre training and fine tuning examples , But adding hints can provide additional guidance at the beginning of model training .
- The advantage is that this is the most expressive method , May be suitable for high data settings .
- The disadvantage is that all parameters of the model need to be trained and stored . It may be too suitable for small data sets .
8、 ... and 、 application
In the previous chapter , This paper studies from the perspective of the mechanism of the method itself prompting Method .
In this section , The paper will organize the prompt method from the perspective of application . We are on the table 7-8 These applications are listed in . And summarized in the following chapters .
surface 7-8: About promting Summary of work 
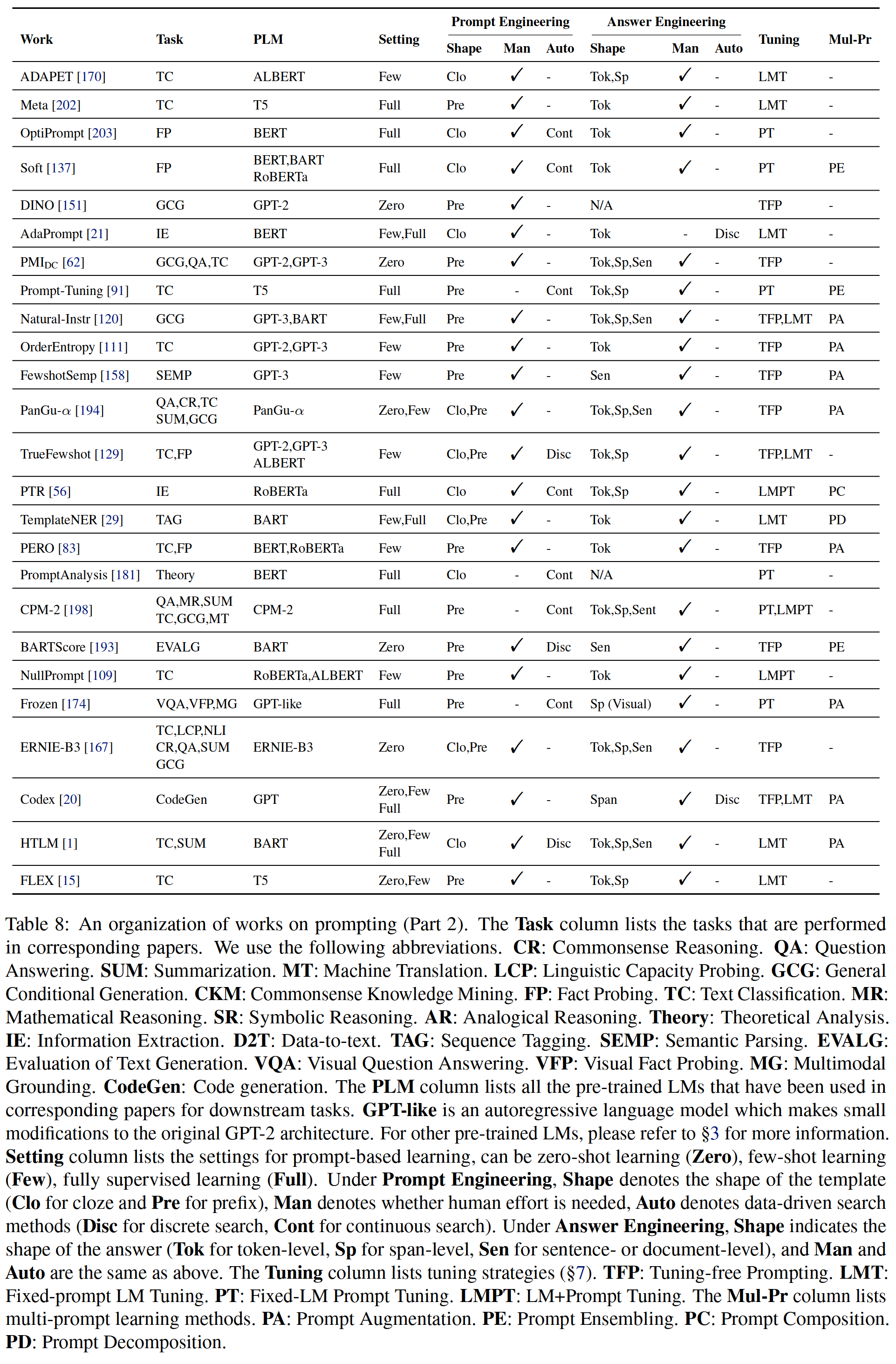
surface 7-8 Abbreviation description : The task column lists the tasks performed in the corresponding paper .
- The paper uses the following abbreviations .
- CR: Commonsense reasoning .
- QA: Question and answer .
- SUM: Text in this paper, .
- MT: Machine translation .
- LCP: Exploration of language ability .
- GCG: General condition generation .
- CKM: Common sense knowledge mining .
- FP: Fact finding .
- TC: Text classification .
- MR: Mathematical reasoning .
- SR: Symbolic reasoning .
- AR: reasoning from analogy .
- Theory: The theoretical analysis .
- IE: information extraction .
- D2T: Data to text .
- TAG: Sequence marker .
- SEMP: Semantic analysis .
- EVALG: Evaluation of text generation .
- VQA: Visual Q & A . Visual fact detection .
- MG: Multimode grounding .
- CodeGen: Code generation .
- PLM The column lists all pre trained LMs.GPT-like It is an autoregressive language model , It's to the original GPT-2 The architecture has been slightly modified .
- Setting Column lists the settings for prompt based learning , It can be zero-shot learning (Zero)、few-shot learning (Few)、fully supervised learning (Full)..
- In prompt design :
- Shape Indicates the type of template (Clo Means cloze ,Pre Indicates prefix ),
- Man Indicates whether manpower is needed ,
- Auto Represents a data-driven search method (Disc Represents discrete search ,Cont Indicates continuous search ).
- stay “ Answer design ” Next ,Shape Indicates the granularity of the answer (Tok Express token Level ,Sp Indicates the segment level ,Sen Indicates sentence or document level ),Man and Auto Same as above .
- Tuning Column lists the adjustment strategies (§7).TFP: There is no need to adjust the prompt .LMT: Fixed prompt LM adjustment .PT: Fix LM Prompt tuning .LMPT:LM+ Prompt adjustment .Mul-Pr Column lists multi prompt learning methods .PA: Prompt amplification .PE: Prompt integration .PC: Prompt synthesis .PD: Prompt decomposition .
1、 Knowledge exploration
Fact finding (Factual Probing) Fact finding ( Also known as fact retrieval ) It is one of the earliest scenarios to apply the prompt method . The motivation to explore this task is to quantify pre trained LM The amount of factual knowledge carried by the internal representation of . In this task , The parameters of the pre training model are usually fixed , By converting the original input to §2.2 Cloze prompts defined in to retrieve knowledge , Cloze prompts can be made manually or found automatically . Relevant data sets include LAMA(Petroni et al.,2019) and X-FACTR(Jiang et al.,2020a). Because the answer is predefined , Fact retrieval only focuses on finding valid templates , And use these templates to analyze the results of different models . Discrete template search (Petroni et al.,2019,2020;Jiang et al.,2020c,a;Haviv et al.,2021;Shin et al.,2020;Perez et al.,2021) And continuous template learning (Qin and Eisner,2021;Liu et al.,2021b;Zhong et al.,2021b) And rapid integrated learning (Jiang et al.,2020c;Qin and Eisner,2021) Have been explored in this context .
Language exploration (Linguistic Probing) In addition to factual knowledge , Large scale pre training also allows LMs Dealing with language phenomena , Such as analogy (Brown et al.,2020)、 no (Ettinger,2020)、 Semantic role sensitivity (Ettinger,2020)、 Semantic similarity (Sun et al.,2021)、 Can't understand (Sun et al.,2021) And rare words (Schick and Sch̉utze,2020). The above knowledge can also be obtained by presenting language exploration tasks in the form of natural language sentences , These tasks will be performed by LM complete .
2、 Classification based tasks
Cue based learning has been widely explored in classification based tasks , In these tasks , Tip templates can be built relatively easily , For example, text classification (Yin wait forsomeone ,2019) And natural language reasoning (Schick and Sch̉utze,2021a). Prompt the key to classification based tasks is to reformat them into appropriate prompts . for example ,Yin et al.(2019) Use hint , Such as “ The theme of this document is [Z]”, Then feed it to Mask pre training LMs In the middle of Slot filling .
Text classification (Text Classification) For text categorization tasks , Most previous work used cloze prompts , Prompt design (Gao wait forsomeone ,2021;Hambardzumyan wait forsomeone ,2021;Lester wait forsomeone ,2021) And answer design (Schick and Sch̉utze,2021a;Schick wait forsomeone ,2020;Gao wait forsomeone ,2021) Have been widely explored . Most of the existing studies explored in “ Fixed prompt LM adjustment ” Strategy ( For the definition, see §7.2.4) Of few-show Settings , Prompt the effectiveness of learning for text classification .
Natural language reasoning (Natural Language Inference-NLI)NLI It aims to predict the relationship between two given sentences ( for example , implication (entailment)). Similar to the text classification task , For natural language reasoning tasks , Usually use cloze to fill in the blank (Schick and Sch̉utze,2021a). About prompt design , Researchers mainly focus on few-shot Template search in the learning environment , Answer space $$ Usually manually pre selected from the vocabulary .
3、 information extraction
Unlike classification tasks , In the classification task , Cloze questions can usually be constructed intuitively , For information extraction tasks , Building hints usually requires more sophisticated skills .
3.1 Named entity recognition
Named entity recognition (NER) Is to recognize named entities in a given sentence ( For example, person names 、 Location ) The task of .
Prompt based learning is applied to sequence representation tasks ( Such as NER) The difficulty is that , Different from classification :
- Each unit to be predicted is a token Or fragments , Instead of the entire input text ,
- Tags in sample context (token) There is a potential relationship between labels .
in general , The application of cue based learning in marking tasks has not been fully explored .
Cui wait forsomeone (2021) Recently, a method of using BART Template based NER Model , The model enumerates text spans , The generation probability of each type of manual template is considered . for example , Given an input “Mike I went to New York yesterday ”, To determine the entity “Mike” The type of , They use templates “Mike It's a [Z] Entity ”, Answer space Z from “person” or “organization” Equivalent composition .
3.2 Relationship extraction
Relationship extraction is a task of predicting the relationship between two entities in a sentence .Chen wait forsomeone (2021b) First, we discuss the fixed prompt LM adjustment (fixed-prompt LM Tuning) Application in relation extraction , It also discusses two main challenges that hinder the prompt method from inheriting directly from the classification task :
- The larger the label space ( for example , In the category of binary emotion (2)vs Relationship extraction (80)), This leads to the more difficult response design .
- In relation extraction , Different marks in input sentences may be more or less important ( for example , Entities mentioned are more likely to participate in the relationship ), however , Because the original prompt template treats every word equally , Therefore, it is difficult to reflect in the classification prompt template .
In order to solve the above problems ,Chen wait forsomeone (2021b) An adaptive answer selection method is proposed to solve the problem (1), And aim at the problem (2) Build task oriented prompt templates , Among them, they use special marks ( Such as [e]) To highlight the entities mentioned in the template . Similarly ,Han wait forsomeone (2021) Through a variety of prompt synthesis techniques ( Pictured 4 Shown ) Merge entity type information .
3.3 Semantic analysis
Semantic analysis is the task of generating structured semantic representation given natural language input .Shin wait forsomeone (2021) adopt (1) Frame the semantic analysis task into the interpretation task (Berant and Liang,2014) and (2) Limit the decoding process by only allowing valid output according to syntax , Explored the use of LMs Conduct few-shot The task of semantic analysis . They use §7.2.2 Experiment with the context learning settings described in , Select the answered prompt that is semantically close to the given test example ( It is determined by the conditional generation probability of giving another training example to generate a test example ). It turns out that , Use pre trained LMs Rewriting the semantic analysis task is effective .
4、NLP Medium “ Reasoning ”
About whether the deep neural network can perform “ Reasoning ” Or just memorize patterns based on a large amount of training data , Still controversial (Arpit wait forsomeone ,2017 year ;Niven and Kao,2019 year ). therefore , Many people try to explore the reasoning ability of models by defining benchmark tasks that span different scenarios . The following paper will introduce in detail how to use prompt methods in these tasks .
4.1 Commonsense reasoning
There are many benchmark data set tests NLP Common sense reasoning in the system (Huang et al.,2019;Rajani et al.,2019;Lin et al.,2020;Ponti et al.,2020).
Some frequently attempted tasks involve solving Winograd Pattern (Leveque wait forsomeone ,2012), This requires the model to identify the antecedents of ambiguous pronouns in the context , Or sentences that involve completing a given multiple choice . For the former , An example might be “ The trophy doesn't fit in the brown suitcase , Because it's too big .” The task of this model is to infer “ it ” Does it mean trophy or “ suitcase ”. By replacing “ it ”, And calculate the probability of different choices , Pre trained LMs You can perform quite well by choosing the choice that achieves the highest probability (Trinh and Le,2018). For the latter , An example could be “ Eleanor offered to prepare some coffee for her guests . Then she realized that she didn't have clean coffee .”. The candidate's choice is “ glass ”、“ bowl ” and “ Spoon ”. In the process of the training LM Our task is to choose the most common sense candidate from the three candidates . For such tasks , We can also score the generation probability of each candidate task , And choose the task with the highest probability (Ettinger,2020).
4.2 Mathematical reasoning
Mathematical reasoning is the ability to solve mathematical problems , For example, arithmetic addition 、 Function is evaluated .
In pre training LMs In the background of , The researchers found that , Pre training embedding and LMs You can perform simple operations when the number of bits is small , Such as addition and subtraction , But it will fail when the number of digits is large (Naik wait forsomeone ,2019;Wallace wait forsomeone ,2019b;Brown wait forsomeone ,2020).Reynolds and McDonell(2021) Discussed more complex mathematical problems ( for example 、 、 、 ) Reasoning problem , And through serialization problem reasoning to improve LM performance .
5、 Question answering system
Question answering system (QA) Designed to answer a given input question , Usually based on context documents .
QA It can be in many formats , for example :
- Draw out QA( Identify content from the context document that contains the answer ; for example ,SQuAD(Rajpurkar et al.,2016));
- multi-select QA( The model must be selected from multiple options ; for example RACE(Lai et al.,2017));
- Free form QA( The model can return any text string as a response ; For example, narration QA(Koˇcisḱy et al.,2018)).
Usually , Use different modeling frameworks to deal with these different formats . Use LMs solve QA problem ( Prompt method may be used ) One of the advantages of , Different formats can be solved in the same framework QA Mission . for example ,Khashabi et al.(2020) Based on seq2seq The pre training model of ( Such as T5) And appropriate hints from context and questions , Will many QA The task is rephrased as a text generation problem .Jiang wait forsomeone (2020b) Use sequence to sequence pre training model (T5、BART、GPT2) Carefully studied such prompt based QA System , It is observed that these pre training models are QA The probability in the task does not predict whether the model is correct .
6、 The text generated
Text generation is a series of tasks involving text generation , Usually based on other information . By using prefix prompts and autoregressive pre training LMs, Prompt method can be easily applied to these tasks .Radford et al.(2019) It shows that this kind of model is performing generation tasks ( Such as text summarization and machine translation ) Impressive ability in , Use hint ( Such as “ Translated into French ,[X],[Z]).Brown wait forsomeone (2020 year ) Perform context learning for text generation (§7.2.2), Use manual templates to create prompts , And use the prompts of multiple answers to increase input .Schick and Sch̉utze(2020) Explored fixed tips LM adjustment (§7.2.4), In order to use hand-made templates few-shot Text in this paper, .(Li and Liang,2021) Study fixed LM Prompt adjustment (§7.2.3), In order to be in few-shot Set up text summarization and data to text generation , The learnable prefix tag is added to the input in advance , The parameters in the pre training model remain frozen .Dou wait forsomeone (2021) Explored hints in text summary tasks +LM Adjustment strategy (§7.2.5), Use the learnable prefix prompt , And initialized by different types of pilot signals , Then you can work with pre trained LMs Parameters are updated together .
7、 Automatic evaluation of text generation
Yuan wait forsomeone (2021b) prove ,prompting Learning can be used to automatically evaluate the generated text . To be specific , They conceptualize the evaluation of generated text as a text generation problem , Modeling with pre trained sequences , Then use the prefix prompt to make the evaluation task closer to the pre training task . They found through experiments that , When using the pre trained model , Just add phrases to the translated text “such as”, Can significantly improve German English Machine Translation (MT) The relevance of the assessment .
8、 Multimodal learning
Tsinpoukelli wait forsomeone (2021) take prompting Learning applications range from text-based NLP Move to a multimodal environment ( Vision and language ). Usually , They are fixed LM Prompt adjustment strategy and prompt amplification technology . They specifically represent each image as a series of continuous embeddings , And use this prefix to prompt the pre training whose parameters have been frozen LM The generation of textual , Such as image title . Experimental results show that , Lens learning ability is very low : In some demonstrations ( Answer tips ) With the help of the , The system can quickly learn words of new objects and new visual categories .
9、 Meta application
There are also many applications of hint technology that are not NLP Mission , Instead, train useful elements of a strong model for any application .
Field adaptation Domain adaptation is to transform a model from a domain ( Such as news text ) Adjust to another field ( Such as social media text ) Practice .Ben David wait forsomeone (2021) Use domain related features(DRF) To add the original text input , And use seq2seq The pre training model regards sequence marking as an inter sequence problem .
debit (Debiasing)Schick wait forsomeone (2021) Find out LMs Self diagnosis and self debit can be performed according to biased or biased instructions . for example , To self diagnose whether the generated text contains violent information , We can use the following templates “ The following text contains violence .[X][Z]”. Then we fill in with the input text [X], And look at [Z] Generation probability at , If “ yes ” The probability is greater than “ no ”, Then we will assume that a given text contains violence , vice versa . To perform a debit when generating text , We first calculate the next word given the original input P ( x t ∣ x < t ; θ ) P\left(x_{t} \mid \boldsymbol{x}_{<t} ; \theta\right) P(xt∣x<t;θ) Probability . then , We add the self diagnostic text input to the above original input , Calculate the next word P ( x t ∣ [ x < t ; x diagnosis ] ; θ ) P\left(x_{t} \mid\left[\boldsymbol{x}_{<t} ; \boldsymbol{x}_{\text {diagnosis }}\right] ; \theta\right) P(xt∣[x<t;xdiagnosis ];θ) Probability . These two probability distributions of the next marker can be combined , To suppress unwanted properties .
Dataset construction Schick and Sch̉utze(2021) It is recommended to use pre trained LMs Generate a data set for a given instruction . for example , Suppose we have an unlabeled data set , Each sample is a sentence . If we want to build a dataset containing semantically similar sentence pairs , Then we can use the following template for each input sentence :“ Write two sentences with the same meaning [X][Z]”, And try to generate a sentence with the same meaning as the input sentence .
10、 resources
The paper also collects some useful resources for different prompt based applications .
surface 9: For prompt based learning few-shot and zero-shot Data sets .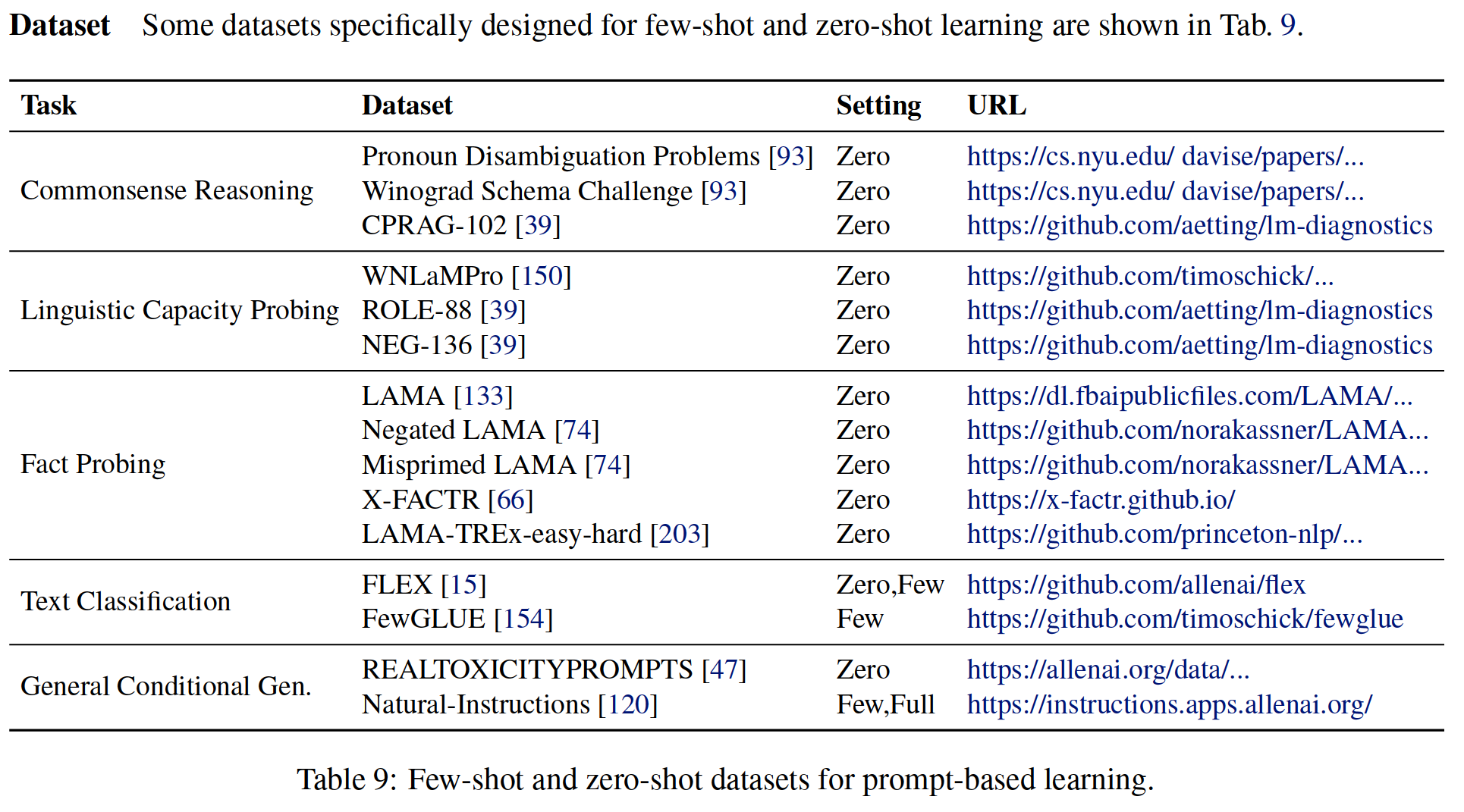
surface 10: Common tips and answers for different tasks .[ Ten ] and [Z] Indicates the slot used for input and reply respectively .V Express LM The vocabulary of . You can use the resource column to find more tips for each task .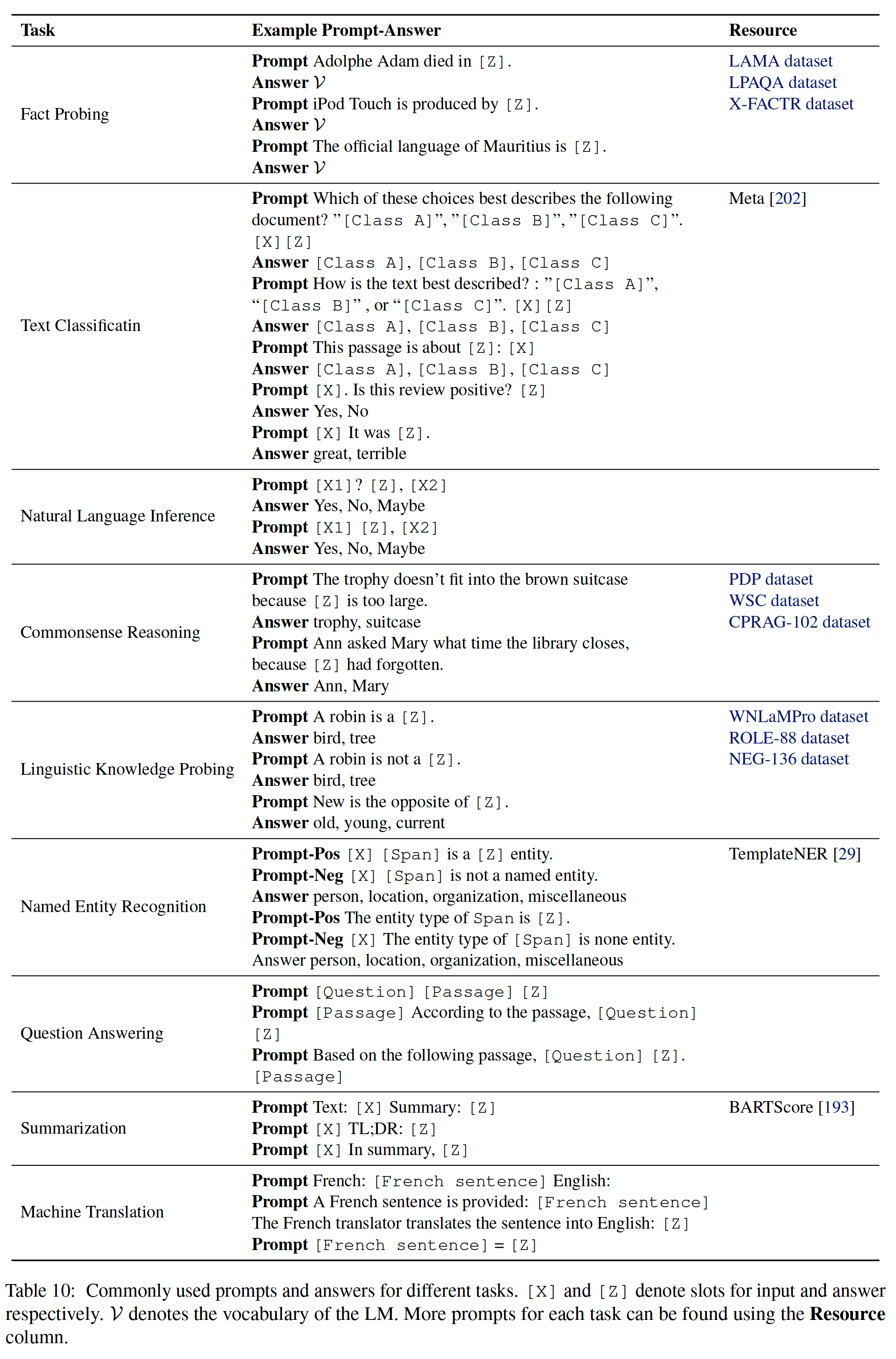
As shown in the table 10、 The paper collects the existing common manual design prompt, It can be used as a ready-made resource for future research and Application .
Ten 、 Tips (Prompt) On the topic
Prompt What is the essence of learning ? What does it have to do with other learning methods ? In this section , The paper will prompt Learning is connected with other similar learning methods .
surface 11: And promting Other research topics related to methods
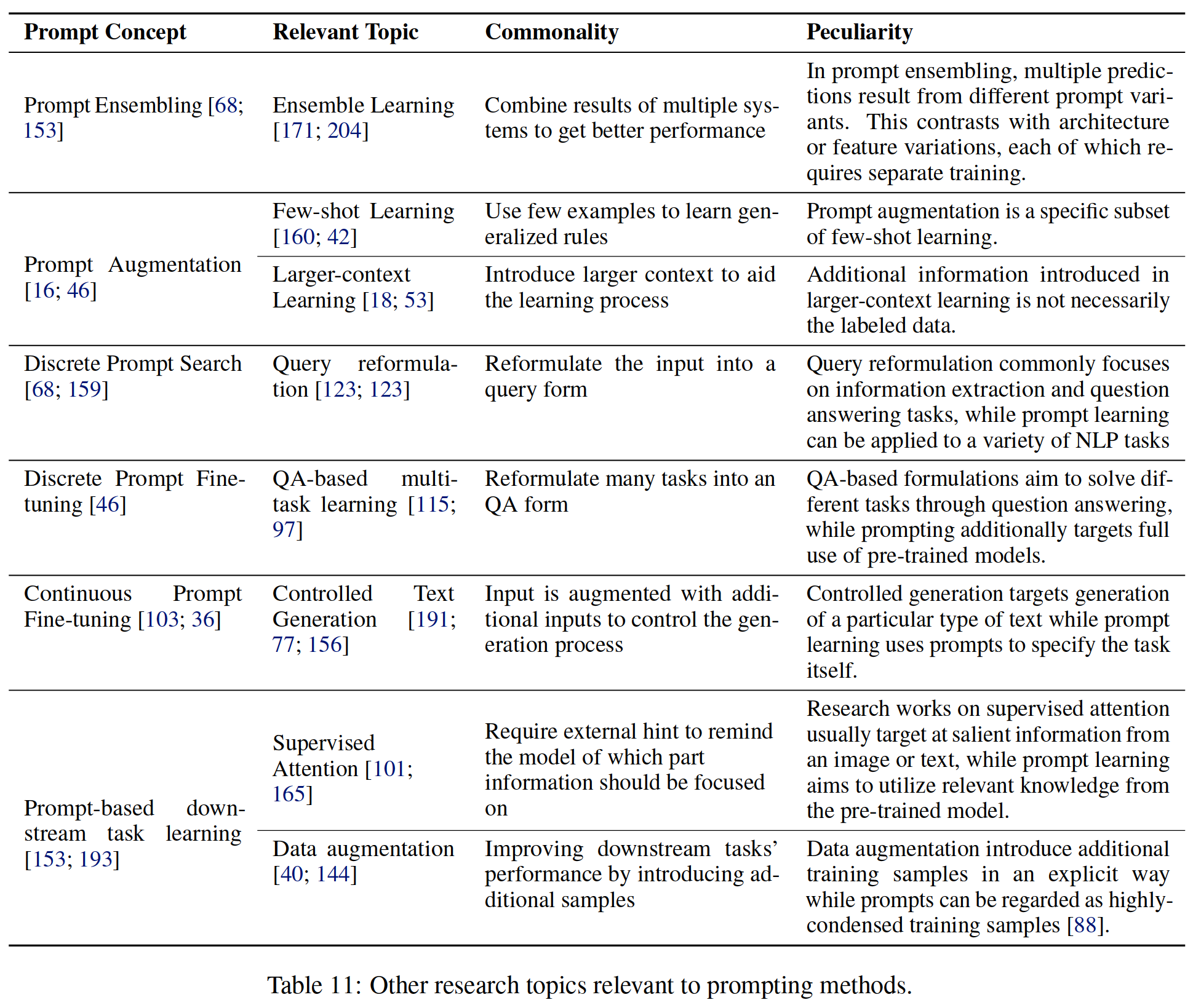
1、 Integrated learning
Integrated learning (Ting and Witten,1997;Zhou wait forsomeone ,2002) It is a technology that aims to use the complementarity of multiple systems to improve task performance . Usually , The different systems used in the integration are due to the architecture 、 Training strategy 、 Data sorting and / Or different choices of random initialization . stay prompt ensembling(§6.1) in , Selecting a prompt template becomes another way to generate multiple results to be combined . This has an obvious advantage , That is, you don't need to train the model many times . for example , When using discrete prompts , You can simply change these prompts during the reasoning phase (Jiang wait forsomeone ,2020c).
2、Few-shot Learning
Few-shot Learning It aims to use less training samples , Learning machine learning systems in the context of data scarcity .
Realization Few-shot Learning There are many ways to do it , Including model agnostic meta learning (Finn et al.,2017b)( Learning characteristics quickly adapt to new tasks )、 Embedded learning (Bertineto et al.,2016)( Embed each sample into a low dimensional space with dense similar samples ), Memory based learning (Kaiser et al.,2017)( Each sample is represented by the weighted average of the memory content ) etc. (Wang et al.,2020).
Prompt Amplification can be seen as implementation few-shot Learning Another way ( Also known as startup based Few-shot Learning(Kumar and Talukdar,2021)).
Compared with the previous method ,Prompt Amplification directly adds several labeled samples in advance to the currently processed samples , From pre trained LMs To acquire knowledge , Even without any parameter adjustment .
3、Larger-context Learning
Larger-context Learning It aims to increase input by using additional background information , For example, from the training set (Cao wait forsomeone ,2018) Or external data sources (Guu wait forsomeone ,2020) Information retrieved , So as to improve the performance of the system . Prompt enhancement can be seen as adding relevant tag samples to the input , But a smaller difference is in larger context learning , The context introduced is not necessarily marked data .
4、 Query rewriting
Query rewriting (Mathieu and Sabatier,1986;Dauḿe III and Brill,2004) Usually used for information retrieval (Nogueira and Cho,2017) And Q & A tasks (Buck wait forsomeone ,2017;Vakulenko wait forsomeone ,2020), Its purpose is to expand the input query by using related query words (Hassan,2013) Or generate definitions to get more relevant text ( Document or answer ). be based on Prompt There are several common points between learning and query refactoring , for example (1) Both aim to make better use of some existing knowledge base by asking the right questions (2) Knowledge base is usually a black box , User unavailable , Therefore, researchers must learn how to make the best exploration based on problems only .
There are also differences : The knowledge base in traditional query rewriting problem is usually search engine (Nogueira and Cho,2017), or QA System (Buck wait forsomeone ,2017). by comparison , For prompt based learning , Papers usually define this knowledge base as LM, And you need to find the right query to get the right answer . The input format in real-time learning changes the form of the task . for example , An original text classification task has been transformed into a cloze problem , So how (1) Develop appropriate task formulas , as well as (2) Correspondingly, changing the modeling framework brings additional complexity . These steps are not required in traditional query formulas . Despite these differences , However, some methods in query rewriting research can still be used for reference for rapid learning , For example, the input query is decomposed into multiple sub queries (Nogueira et al.,2019), Similar to fast decomposition .
5、QA-based Task Formulation
QA-based Task Formulation It aims to integrate different NLP Conceptualize the task as a question and answer .(Kumar et al.,2016;McCann et al.,2018) Is trying to put multiple NLP The task is unified to QA Early works in the framework . later , In information extraction (Li et al.,2020;Wu et al.,2020) And text categorization (Chai et al.,2020) This idea is further explored in . These methods are very similar to the prompt methods introduced here , Because they use text questions to specify the task to be performed . However ,Prompting A key point of the method is how to better use pre training LMs Knowledge in , And previously advocated QA This knowledge is not widely involved in our work .
6、 Controlled generation
Controlled generation aims to incorporate various types of guidelines other than input text into the generation model (Yu wait forsomeone ,2020 year ). To be specific , The guidance signal can be a style marker (Sennrich et al.,2016b;Fan et al.,2018)、 Length specifications (Kikuchi et al.,2016)、 Domain tag (Chu et al.,2017) Or any other information used to control the generated text . It can also be a keyword (Saito wait forsomeone ,2020 year )、 Relational triples (Zhu wait forsomeone ,2020 year ) Even highlighted phrases or sentences (Grangier and Auli,2018 year ;Liu wait forsomeone ,2021c), To plan the content of the generated text . In a way , Many of the prompt methods described here are controllable generation , The prompt is usually used to specify the task itself . therefore , It is easier to find the commonalities between these two types :(1) Add additional information to the input text to better generate , And these extra signals ( Usually ) It's a learnable parameter .(2) If “ Controlled generation ” Equipped based on seq2seq Pre training model of ( Such as BART), It can be regarded as using input dependent prompts and prompts +LM Tips for fine tuning strategies (§7.2.5), for example GSum(Dou wait forsomeone ,2021), Among them, tips and pre training LM Parameters can be adjusted .
Besides , Some of the obvious differences between controlled generation and prompt based text generation are :(1) In the controlled generation work , Usually control the generated style or content (Fan et al.,2018;Dou et al.,2021), The basic tasks remain the same . They don't necessarily need pre trained models . contrary , The main motivation for using prompts to generate text is to specify the task itself and make better use of the pre trained model .(2) Besides , At present, most of the work on prompt learning in text generation shares a dataset or task level prompt (Li and Liang,2021). Only a few works have explored input dependent (Tsinpoukelli wait forsomeone ,2021). However , This is a common and effective setting in controlled text generation , This may provide a valuable direction for the future rapid learning work .
7、 Have supervisory attention
From long text sequence (Liu et al.,2016;Sood et al.,2020)、 Images (Sugano and Bulling,2016;Zhang et al.,2020b) Or knowledge base (Yu et al.,2020;Dou et al.,2021) When extracting useful information from objects , Knowing that paying attention to important information is a key step . Supervision attention (Liu wait forsomeone ,2017b) Designed to be based on the fact that fully data-driven attention may be over adapted to certain artifacts , Clearly supervise the attention of the model (Liu wait forsomeone ,2017a). In this regard , Instant learning and monitoring attention share some ideas , Both of these ideas aim to extract significant information with some clues , These clues need to be provided separately . To solve this problem , Supervised attention method attempts to use additional loss function to learn to predict real attention on manually labeled corpus (Jiang wait forsomeone ,2015;Qiao wait forsomeone ,2018;Gan wait forsomeone ,2017). About prompting The study of learning can also draw on the views of these documents .
8、 Data to enhance
Data enhancement is a technology designed to increase the amount of data available for training by modifying existing data (Fadaee et al.,2017;Ratner et al.,2017). just as (Scao and Rush,2021) Recently observed , Adding hints can achieve the same goal as adding them equally in classification tasks 100 Similar accuracy improvements for data points , This shows that using hints in downstream tasks is similar to implicit data expansion .
Ten 、 Challenge
1、 Tips (Prompt) Design
1.1 Tasks other than classification and generation
Most of the existing prompt based learning work revolves around text classification or generation based tasks .
There is less discussion about the application of information extraction and text analysis tasks , Mainly because the design of the prompt is not so simple .
We expect , In the future, when the prompt method is applied to these tasks , These tasks need to be reformulated , In order to solve these tasks using methods based on classification or text generation , Or implement an effective answer project , Express structured output in appropriate text format .
1.2 Structured information Prompting
many NLP Tasks , The input contains some different structures , For example, trees 、 chart 、 Table or relational structure .
How to best express these structures in real-time or response engineering is a major challenge .
Existing studies (Chen wait forsomeone ,2021b) Encode vocabulary information by using additional tags to prompt , For example, entity tags .Aghajanyan wait forsomeone (2021) A structured prompt based on hypertext markup language is proposed , For finer grained web The text generated . However , Apart from that , More complex structural types have not been explored to a large extent , This is a potentially interesting area of research .
1.3 Template and answer combination
The performance of the model will depend on the template used and the answer considered .
How to search or learn the best combination of template and answer at the same time is still a challenging problem .
The current work usually chooses the answer before choosing the template (Gao wait forsomeone .2021;Shin wait forsomeone ,2020 year ), but Hambardzumyan wait forsomeone (2021) It has proved the initial potential of learning both at the same time .
2、 The answer is engineering
Multi category and long answer category tasks For classification based tasks , The answer project faces two major challenges :
- When there are too many classes , How to choose the right answer space has become a difficult combinatorial optimization problem .
- When using more tokens Response time , Although some suggestions have been made tokens Decoding method , But how to use LMs For more than tokens The best decoding is still unknown (Jiang wait forsomeone ,2020a).
Generate multiple answers to tasks For text generation tasks , Qualified answers can be semantically equivalent , But grammatically different . up to now , Almost all works use prompting Learn to generate text , Rely on only one answer , There are only a few exceptions (Jiang wait forsomeone ,20
3、 Choice of adjustment strategy
Such as §7 Described , There are many ways to adjust the prompt 、LMs Or both . However , Since this research field is in its infancy , We still lack a systematic understanding of the trade-offs between these methods . This field can benefit from systematic exploration , For example, the exploration in the pre training and fine tuning paradigm about the trade-offs between these different strategies (Peters et al.,2019).
4、 Multiple prompts (Prompt) Study
Prompt Ensembling In the prompt integration method , As we consider more tips , Space and time complexity will increase . How to extract knowledge from different hints remains to be explored .Schick and Sch̉utze(2020、2021a、b) Annotate large datasets using an integration model , To extract knowledge from multiple prompts . Besides , How to choose the tips suitable for ensemble also remains to be explored . For text generation tasks , At present, there is no research on instant integrated learning , This may be due to the complexity of integrated learning in text generation . To solve this problem , Some recently proposed neural fusion methods , Such as refactoring (Liu wait forsomeone ,2021c), It can be regarded as a method of rapid fusion in text generation tasks .
Prompt Synthesis and decomposition Both hint synthesis and decomposition aim to solve the difficulty of complex task input by introducing multiple sub hints . In practice , How to make the right choice between the two is a crucial step . From experience , For those marks (Ma and Hovy,2016) or span(Fu et al.,2021) Prediction task ( for example ,NER), You can consider prompt decomposition , And for those span Relationship prediction (Lee et al.,2017) Mission ( for example , Entities collectively refer to ), Tip synthesis will be a better choice . future , You can explore in more scenes de-/ The general idea of combination .
Prompt amplification The existing cue amplification methods are limited by the input length , That is, you cannot provide too many prompts for input . therefore , How to choose informative tips , It is an interesting but challenging problem to arrange them in proper order (Kumar and Talukdar,2021).
Prompt share All of the above considerations relate to a single task 、 Apply hints in the domain or language . We can also consider prompt share , That is, instant learning is applied to multiple tasks 、 Domain or language . Some key issues that may arise include how to design separate prompts for different tasks , And how to adjust the interaction between them . up to now , This field has not been explored . chart 5 It shows a simple multi task and multi prompt learning strategy , Among them, the prompt template part is shared .
chart 5: multitasking 、 Multi prompt learning in multi domain or multi language learning 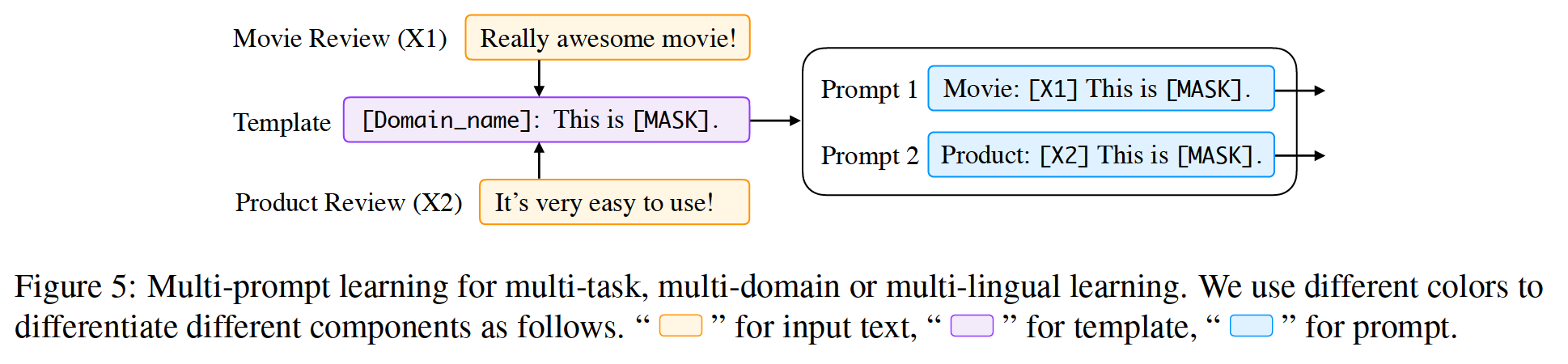
5、 Selection of pre training model
Due to a lot of pre training LMs To choose from ( see §3), How to choose them to make better use of cue based learning is an interesting and difficult problem . Although the paper has introduced the concept (§3.4) How for different NLP Task selection different pre training model examples , But there is little or no systematic comparison of different pre training LMs The benefits of instant learning .
6、 Tips (Prompting) Theoretical and empirical analysis
Although they have achieved success in many scenes , However, there is a lack of theoretical analysis and guarantee of instant learning .Wei wait forsomeone (2021) indicate , Soft prompt adjustment can relax the non degenerate assumption required for downstream recovery ( The generation probability of each marker is linearly independent )( That is, restore the ground truth tag of the downstream task ), Easier to extract task specific information .Saushi wait forsomeone (2021) confirmed , Text classification task can be rephrased as sentence completion task , Thus, language modeling becomes a meaningful pre training task .Scao and Rush(2021) Experience shows that , In the classification task , Tips are usually equivalent to average 100 Data points .
7、 Tips (Prompts) The portability of
To what extent do understanding cues depend on the model , And improving the transitivity of tips is also an important topic .(Perez et al.,2021) indicate , Tips for choosing in optimized less shot learning scenarios ( There is a larger validation set to select prompts ) It can well generalize models of similar size , And in the real less lens learning scene, the selection prompt ( There are only a few training samples ) The generalization effect in a model of similar size is not as good as the previous setting . When the size of the model in the two scenes varies greatly , Poor portability .
8、 A combination of different examples
It is worth noting that ,prompting Most of the success of paradigms is based on pre training and fine-tuning paradigms ( Such as BERT) Developed pre training model . However , Whether the effective pre training method for the latter is also applicable to the former , Or can we completely rethink our pre training methods , To further improve the accuracy or ease of use of prompt based learning ? This is an important research problem , It has not been widely covered by literature .
9、 Prompt the calibration of the method
calibration (Gleser,1996) It refers to the ability of the model to make good probability prediction . When using pre trained LMs( Such as BART) To predict the answer , We need to be careful , Because the probability distribution is usually not well calibrated .Jiang wait forsomeone (2020b) The observed ,QA Pre training model in task ( Such as BART、T5、GPT-2) The probability of is well calibrated .Zhao wait forsomeone (2021) Three traps have been identified ( Most labels deviate 、 Recent deviation and common mark deviation ), These three traps lead to pre trained LMs Some answers are preferred when providing answer tips . for example , If the prompt of the final answer has a positive label , Then this will make the model tend to predict positive words . To overcome these shortcomings ,Zhao wait forsomeone (2021) First, use context free input ( for example , Prompt for “ Input : Sub role play . mood : Negative input : Beautiful movies . mood : Positive input : Do not apply . mood :”) To get the initial probability distribution P0, Then they use real input ( for example , The prompt will be “ Input : A sub standard performance . mood : Negative input : Beautiful movies . mood : Positive input : amazing . mood :”) To get the probability distribution P1. Last , Using these two distributions, the calibrated generation probability distribution can be obtained . However , This method has two disadvantages :(1) It brings the overhead of finding appropriate context free input ( for example , It's using “ Do not apply ” still “ nothing ”), as well as (2) Basic pre training LM The probability distribution of has not been calibrated .
Even if we have a calibrated probability distribution , When we assume a true answer for an input , We also need to be careful . This is because all surface forms of the same object will compete for finite probability mass (Holtzman wait forsomeone ,2021). for example , If we regard the real answer as “Whirlpool bath”, Then its generation probability is usually low , because “Bathtub” The word has the same meaning , It will occupy a high probability . To solve this problem , We can (i) Execute answer design , Use the method of interpretation (§5.2.2) Build a comprehensive set of real answers , perhaps (ii) Calibrate the probability of words according to the prior possibility of words in the context (Holtzman et al.,2021).
11、 ... and 、 Meta analysis
In this section , We aim to conduct a meta-analysis of existing research work in different dimensions , Yes prompting Methods of existing research to conduct quantitative aerial view .
1、 Timeline
Firstly, the paper takes the form of timeline , Some existing research papers are summarized in chronological order , It is hoped that this will help researchers unfamiliar with this topic understand the development of this field .
2、 Trend analysis
chart 6: Meta analysis of different dimensions . Statistics are based on tables 7-8. stay (d) in , We use the following abbreviations .TC: Text classification ,FP: Fact finding ,GCG: General condition generation ,QA: Question and answer ,CR: Commonsense reasoning ,SUM: Abstract ,O: other 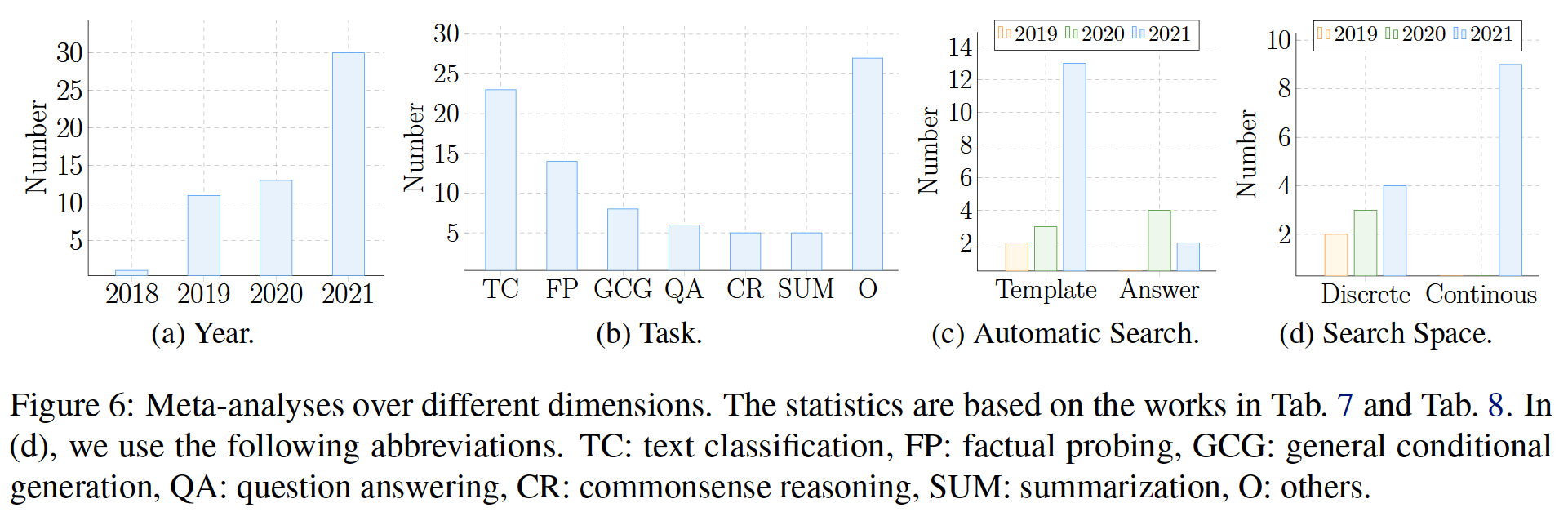
The paper also calculates the number of papers based on prompts in different dimensions .
year With all kinds of pre training LMs Appearance , Cue based learning has become an increasingly active research field , Pictured 6-(a) Shown . We can see ,2021 There has been a sharp surge , This may be due to GPT-3 The popularity of (Brown et al.,2020), This greatly improves the prompt in few-shot Penetration in a multitasking environment .
Mission In the figure 6-(b) The number of works studying various tasks is drawn in . For less 5 Tasks of related works , Group them into “ other ”. As shown in the bar chart , Most cue based learning tasks revolve around text classification and fact inquiry . We speculate that this is because for these tasks , Template design and answer design are relatively easy , Experiments are relatively cheap in calculation .
Prompt And answer search As mentioned in the previous sections ,Prompt And answer search are important tools for using pre trained language models in many tasks . The current research mainly focuses on template search , Instead of searching for answers , Pictured 6-(c) Shown .
The possible reasons are :(1) For conditional generation tasks ( Such as abstract or translation ), Real references can be used directly as answers . Although many sequences may have the same semantics , But how to effectively carry out multi reference learning in conditional text generation is a very important problem .(2) For classification tasks , Most of the time , It is relatively easy to use domain knowledge to select tag words .
Discrete search and continuous search At present, there is less research on automatic answer search , Therefore, my paper analyzes the automatic template search . as time goes on , The continuous search from discrete search to fast engineering has changed , Pictured 6-(d) Shown . The possible reasons are :(1) Discrete search is more difficult to optimize than continuous search ,(2) soft promt Have greater presentation ability .
Twelve 、 summary
In this paper , We summarize and analyze several paradigms in the development of statistical natural language processing technology , It is believed that cue based learning is a promising new paradigm , It may represent another major change in the way we view natural language processing . First , The paper hopes that this survey can help researchers more effectively 、 A more comprehensive understanding of the paradigm of instant learning , And grasp its core challenges , So as to make more scientific progress in this field . Besides , review §1 Four kinds proposed in NLP Summary of research paradigm , We hope to highlight the similarities and differences between them , Make the research on these paradigms more mature , And may provide catalyst , Inspire people to work towards the next paradigm shift .
Reference material :
Easy to start with Prompt( The attached code )
GitHub:OpenPrompt,An Open-Source Framework for Prompt-learning
Prompt application —— Information extraction (NER & RE) Mission
Big model Prompt Tuning Technology sharing
Prompt In Chinese classification few-shot Try in the scene
prompt Is it all right
NAACL2022-Prompt Related papers & Yes Prompt View of the
NLP The new paradigm of pre training language model Prompt Conclusion 1 :Pattern-Exploiting Training(PET) Build templates manually
prompt Template mode summary record
Paper reading :Prompt Unified NLP The new paradigm Pre-train, Prompt, and Predict
The development of modern natural language processing technology “ Fourth normal form ”
NLP Four paradigms of
from 4 Detailed explanation of the latest paper NLP The new paradigm ——Continuous Prompt
Prompt special column - An overview
边栏推荐
- Redis守护进程无法停止解决方案
- VMware Tools安装报错:无法自动安装VSock驱动程序
- Leetcode skimming questions_ Sum of squares
- Opinions on softmax function
- Basic operations of database and table ----- set the fields of the table to be automatically added
- Basic operations of databases and tables ----- default constraints
- Blue Bridge Cup embedded stm32g431 - the real topic and code of the eighth provincial competition
- 干货!通过软硬件协同设计加速稀疏神经网络
- Who knows how to modify the data type accuracy of the columns in the database table of Damon
- 【Flask】官方教程(Tutorial)-part2:蓝图-视图、模板、静态文件
猜你喜欢
基於DVWA的文件上傳漏洞測試

伦敦银走势中的假突破
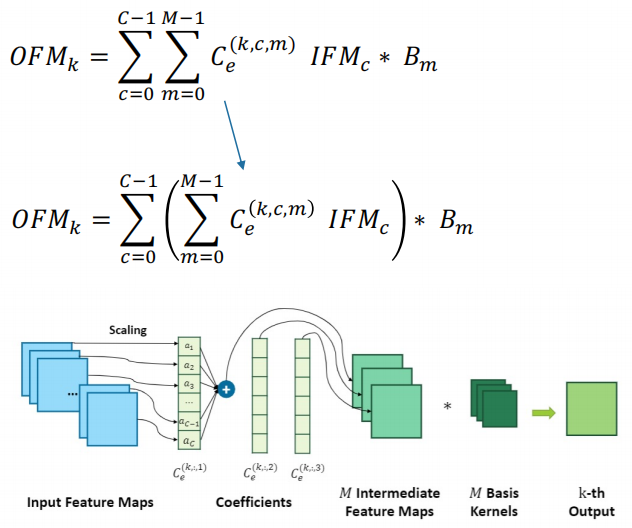
干货!通过软硬件协同设计加速稀疏神经网络
3D model format summary
![[Jiudu OJ 09] two points to find student information](/img/35/25aac51fa3e08558b1f6e2541762b6.jpg)
[Jiudu OJ 09] two points to find student information
Alibaba canal usage details (pit draining version)_ MySQL and ES data synchronization
MUX VLAN configuration

Basic operations of databases and tables ----- default constraints
False breakthroughs in the trend of London Silver
Accelerating spark data access with alluxio in kubernetes
随机推荐
【已解决】如何生成漂亮的静态文档说明页
ORA-00030
一圖看懂!為什麼學校教了你Coding但還是不會的原因...
General operation method of spot Silver
internship:项目代码所涉及陌生注解及其作用
XSS learning XSS lab problem solution
[the most complete in the whole network] |mysql explain full interpretation
竞赛题 2022-6-26
Force buckle 9 palindromes
[机缘参悟-39]:鬼谷子-第五飞箝篇 - 警示之二:赞美的六种类型,谨防享受赞美快感如同鱼儿享受诱饵。
国家级非遗传承人高清旺《四大美人》皮影数字藏品惊艳亮相!
【SSRF-01】服务器端请求伪造漏洞原理及利用实例
Leetcode skimming questions_ Invert vowels in a string
IP storage and query in MySQL
Who knows how to modify the data type accuracy of the columns in the database table of Damon
01.Go语言介绍
Docker compose configures MySQL and realizes remote connection
Leetcode 剑指 Offer 59 - II. 队列的最大值
【全網最全】 |MySQL EXPLAIN 完全解讀
Remember that a version of @nestjs/typeorm^8.1.4 cannot be obtained Env option problem