当前位置:网站首页>Accelerating spark data access with alluxio in kubernetes
Accelerating spark data access with alluxio in kubernetes
2022-07-06 01:30:00 【a_ small_ cherry】
brief introduction : Alluxio Is an open source memory based distributed storage system , It is suitable for big data on cloud and AI / ML Data arrangement scheme . This article mainly explains how to use alluxio Speed up spark The data access .

Image download 、 Domain name resolution 、 Time synchronization please click Alibaba open source mirror site
One 、 Background information
1. alluxio
Alluxio Is an open source memory based distributed storage system , It is suitable for big data on cloud and AI / ML Data arrangement scheme .Alluxio It can manage multiple underlying file systems at the same time , Unify different file systems under the same namespace , Let the upper client freely access different paths in the unified namespace , Data from different storage systems .
alluxio Of short-circuit Function can make alluxio Client direct access alluxio worker The working storage of the host , Instead of using the network stack to communicate with alluxio worker Complete communication , Can improve performance .
2. spark operator
Spark-operator Used to manage k8s In the cluster spark job. adopt spark-operator Can be in k8s Create... In the cluster 、 View and delete spark job.
Two 、 Prerequisite
The operation of this document depends on the following conditions :
- kubernetes colony : The version is greater than 1.8, The cluster of this experiment passed Alibaba cloud container service establish , Cluster name is "ack-create-by-openapi-1".

- Installed with linux perhaps mac Operating system computer as our experimental environment ( In this experiment , Suppose the computer name is alluxio-test). The computer needs to prepare the following environment :
- docker >= 17.06
- kubectl >= 1.8, Be able to connect kubernets colony ack-create-by-openapi-1
3、 ... and 、 The experimental steps
The experimental steps mainly include the following steps :
- Deploy alluxio
- Deploy spark-operator
- Make spark docker Mirror image
- Upload files to alluxio
- Submit spark job
Each step will be described below :
### 1. Deploy alluxio
Get into Container service application directory , Search in the search box in the upper right corner "alluxio", Then enter alluxio main interface , Pictured :

Then select will alluxio Install on the target cluster ( The cluster of this experiment is "ack-create-by-openapi-1"), Finally, click create , Pictured

Click create , Use kubectl To be installed alluxio Label the nodes of the component "alluxio=true", First, check which nodes the cluster has :
# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
cn-beijing.192.168.8.12 Ready master 21d v1.16.6-aliyun.1 192.168.8.12 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.13 Ready master 21d v1.16.6-aliyun.1 192.168.8.13 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.14 Ready master 21d v1.16.6-aliyun.1 192.168.8.14 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.15 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.15 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.16 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.16 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.17 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.17 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5You can see that there are three worker node , Respectively :
- cn-beijing.192.168.8.15
- cn-beijing.192.168.8.16
- cn-beijing.192.168.8.17
We label all three nodes "alluxio=true":
# kubectl label nodes cn-beijing.192.168.8.15 \
cn-beijing.192.168.8.16 \
cn-beijing.192.168.8.17 \
alluxio=trueUse kubectl Look at each pod Are they all in running state :
# kubectl get po -n alluxio
NAME READY STATUS RESTARTS AGE
alluxio-master-0 2/2 Running 0 4h1m
alluxio-worker-5zg26 2/2 Running 0 4h1m
alluxio-worker-ckmr9 2/2 Running 0 4h1m
alluxio-worker-dvgvd 2/2 Running 0 4h1mverification alluxio Is it in ready:
# kubectl exec -ti alluxio-master-0 -n alluxio bash
// Next step alluxio-master-0 pod In the implementation of
bash-4.4# alluxio fsadmin report capacity
Capacity information for all workers:
Total Capacity: 3072.00MB
Tier: MEM Size: 3072.00MB
Used Capacity: 0B
Tier: MEM Size: 0B
Used Percentage: 0%
Free Percentage: 100%
Worker Name Last Heartbeat Storage MEM
192.168.8.15 0 capacity 1024.00MB
used 0B (0%)
192.168.8.16 0 capacity 1024.00MB
used 0B (0%)
192.168.8.17 0 capacity 1024.00MB
used 0B (0%)2. Deploy spark-operator
Get into Container service application directory , Search in the search box in the upper right corner "ack-spark-operator", Then enter ack-spark-operator main interface , Pictured :

Choose to ack-spark-operator Install on the target cluster ( The cluster of this experiment is "ack-create-by-openapi-1"), And I'm gonna go ahead and create , Pictured :

sparkctl Is a for submitting spark job To k8s Command line tools for , Need to put sparkctl Install to us in " Prerequisite " The experimental environment mentioned in "alluxio-test" in :
# wget http://spark-on-k8s.oss-cn-beijing.aliyuncs.com/sparkctl/sparkctl-linux-amd64 -O /usr/local/bin/sparkctl
# chmod +x /usr/local/bin/sparkctl3. Make spark docker Mirror image
from spark The download page Download what you need spark edition , This experiment chooses saprk Version is 2.4.6. Run the following command to download spark:
# cd /root
# wget https://mirror.bit.edu.cn/apache/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgzWhen the download is complete , Perform the decompression operation :
# tar -xf spark-2.4.6-bin-hadoop2.7.tgz
# export SPARK_HOME=/root/spark-2.4.6-bin-hadoop2.7spark docker The image is submitted by us spark The image used in the task , This image needs to contain alluxio client jar package . Use the following command to get alluxio client jar package :
# id=$(docker create alluxio/alluxio-enterprise:2.2.1-1.4)
# docker cp $id:/opt/alluxio/client/alluxio-enterprise-2.2.1-1.4-client.jar \
$SPARK_HOME/jars/alluxio-enterprise-2.2.1-1.4-client.jar
# docker rm -v $id 1>/dev/nullalluxio client jar When the bag is ready , Start building images :
# docker build -t spark-alluxio:2.4.6 -f kubernetes/dockerfiles/spark/Dockerfile $SPARK_HOME Please remember the image name “spark-alluxio:2.4.6”, In the k8s Submit spark job This information will be used in .
After the image is built , There are two ways to deal with images :
- If there is a private image warehouse , Push the image to the private image warehouse , At the same time guarantee k8s Cluster nodes can pull The mirror
- If there is no private image warehouse , Then you need to use docker save Command to export the image , then scp To k8s Each node of the cluster , Use... On each node docker load Command to import the image , This ensures that the image exists on every node .
4. Upload files to alluxio
It was mentioned at the beginning of the article : This experiment is to submit a spark job To k8s in , The spark job The goal of is to count the number of occurrences of each word in a certain file . Now you need to send this file to alluxio On storage , This is just for convenience , Put... Directly alluxio master in /opt/alluxio-2.3.0-SNAPSHOT/LICENSE( The file path may be due to alluxio The version is a little different ) This file is transferred to alluxio On .
Use "kubectl exec" Get into alluxio master pod, And copy the LICENSE File to alluxio In the root directory of :
# kubectl exec -ti alluxio-master-0 -n alluxio bash
// Next step alluxio-master-0 pod In the implementation of
bash-4.4# alluxio fs copyFromLocal LICENSE /Then take a look at LICENSE This document is divided into block By alluxio What to put worker Yes .
# kubectl exec -ti alluxio-master-0 -n alluxio bash
// Next step alluxio-master-0 pod In the implementation of
bash-4.4# alluxio fs stat /LICENSE
/LICENSE is a file path.
FileInfo{fileId=33554431, fileIdentifier=null, name=LICENSE, path=/LICENSE, ufsPath=/opt/alluxio-2.3.0-SNAPSHOT/underFSStorage/LICENSE, length=27040, blockSizeBytes=67108864, creationTimeMs=1592381889733, completed=true, folder=false, pinned=false, pinnedlocation=[], cacheable=true, persisted=false, blockIds=[16777216], inMemoryPercentage=100, lastModificationTimesMs=1592381890390, ttl=-1, lastAccessTimesMs=1592381890390, ttlAction=DELETE, owner=root, group=root, mode=420, persistenceState=TO_BE_PERSISTED, mountPoint=false, replicationMax=-1, replicationMin=0, fileBlockInfos=[FileBlockInfo{blockInfo=BlockInfo{id=16777216, length=27040, locations=[BlockLocation{workerId=8217561227881498090, address=WorkerNetAddress{host=192.168.8.17, containerHost=, rpcPort=29999, dataPort=29999, webPort=30000, domainSocketPath=, tieredIdentity=TieredIdentity(node=192.168.8.17, rack=null)}, tierAlias=MEM, mediumType=MEM}]}, offset=0, ufsLocations=[]}], mountId=1, inAlluxioPercentage=100, ufsFingerprint=, acl=user::rw-,group::r--,other::r--, defaultAcl=}
Containing the following blocks:
BlockInfo{id=16777216, length=27040, locations=[BlockLocation{workerId=8217561227881498090, address=WorkerNetAddress{host=192.168.8.17, containerHost=, rpcPort=29999, dataPort=29999, webPort=30000, domainSocketPath=, tieredIdentity=TieredIdentity(node=192.168.8.17, rack=null)}, tierAlias=MEM, mediumType=MEM}]}You can see LICENSE This file has only one block(id by 16777216), It's on ip by 192.168.8.17 Of k8s Node . We use kubectl Check that the node name is cn-beijing.192.168.8.17 :
# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
cn-beijing.192.168.8.12 Ready master 21d v1.16.6-aliyun.1 192.168.8.12 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.13 Ready master 21d v1.16.6-aliyun.1 192.168.8.13 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.14 Ready master 21d v1.16.6-aliyun.1 192.168.8.14 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.15 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.15 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.16 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.16 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.5
cn-beijing.192.168.8.17 Ready <none> 21d v1.16.6-aliyun.1 192.168.8.17 <none> Aliyun Linux 2.1903 (Hunting Beagle) 4.19.57-15.1.al7.x86_64 docker://19.3.55. Submit spark job
The following steps will submit a spark job To k8s In the cluster , The job Mainly calculation alluxio in /LICENSE The number of times each word of the file appears .
Steps in 3.4 We get LICENSE This file contains block All at the node cn-beijing.192.168.8.17 On , In this experiment , We pass the designation node selector Give Way spark driver and spark executor All run on nodes cn-beijing.192.168.8.17, Verify closing alluxio Of short-circuit In case of function ,spark executor and alluxio worker Whether the communication between them is completed through the network stack .
- explain : If it's opening alluxio Of short-circuit In case of function , also spark executor With the file it wants to access ( This experiment is /LICENSE This file ) Of block In the same k8s Node , that spark executor Medium alluxio client With this k8s nodes alluxio worker The communication between them is through domain socket Way to complete .
First generate the submission spark job Of yaml file :
# export SPARK_ALLUXIO_IMAGE=< step 3.3 Made in image, namely spark-alluxio:2.4.6>
# export ALLUXIO_MASTER="alluxio-master-0"
# export TARGET_NODE=< step 3.4 Acquired LICENSE Of documents block Storage nodes , namely cn-beijing.192.168.8.17>
# cat > /tmp/spark-example.yaml <<- EOF
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-count-words
namespace: default
spec:
type: Scala
mode: cluster
image: "$SPARK_ALLUXIO_IMAGE"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.JavaWordCount
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.6.jar"
arguments:
- alluxio://${ALLUXIO_MASTER}.alluxio:19998/LICENSE
sparkVersion: "2.4.5"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 2.4.5
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
nodeSelector:
kubernetes.io/hostname: "$TARGET_NODE"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.5
nodeSelector:
kubernetes.io/hostname: "$TARGET_NODE"
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
EOFthen , Use sparkctl Submit spark job:
# sparkctl create /tmp/spark-example.yamlFour 、 experimental result
When the task is submitted , Use kubectl see spark driver Log :
# kubectl get po -l spark-role=driver
NAME READY STATUS RESTARTS AGE
spark-alluxio-1592296972094-driver 0/1 Completed 0 4h33m
# kubectl logs spark-alluxio-1592296972094-driver --tail 20
USE,: 3
Patents: 2
d): 1
comment: 1
executed: 1
replaced: 1
mechanical: 1
20/06/16 13:14:28 INFO SparkUI: Stopped Spark web UI at http://spark-alluxio-1592313250782-driver-svc.default.svc:4040
20/06/16 13:14:28 INFO KubernetesClusterSchedulerBackend: Shutting down all executors
20/06/16 13:14:28 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Asking each executor to shut down
20/06/16 13:14:28 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)
20/06/16 13:14:28 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/06/16 13:14:28 INFO MemoryStore: MemoryStore cleared
20/06/16 13:14:28 INFO BlockManager: BlockManager stopped
20/06/16 13:14:28 INFO BlockManagerMaster: BlockManagerMaster stopped
20/06/16 13:14:28 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/06/16 13:14:28 INFO SparkContext: Successfully stopped SparkContext
20/06/16 13:14:28 INFO ShutdownHookManager: Shutdown hook called
20/06/16 13:14:28 INFO ShutdownHookManager: Deleting directory /var/data/spark-2f619243-59b2-4258-ba5e-69b8491123a6/spark-3d70294a-291a-423a-b034-8fc779244f40
20/06/16 13:14:28 INFO ShutdownHookManager: Deleting directory /tmp/spark-054883b4-15d3-43ee-94c3-5810a8a6cdc7Finally, we login to alluxio master On , Check the statistical value of relevant indicators :
# kubectl exec -ti alluxio-master-0 -n alluxio bash
// Next step alluxio-master-0 pod In the implementation of
bash-4.4# alluxio fsadmin report metrics
Cluster.BytesReadAlluxio (Type: COUNTER, Value: 290.47KB)
Cluster.BytesReadAlluxioThroughput (Type: GAUGE, Value: 22.34KB/MIN)
Cluster.BytesReadDomain (Type: COUNTER, Value: 0B)
Cluster.BytesReadDomainThroughput (Type: GAUGE, Value: 0B/MIN)BytesReadAlluxio and BytesReadAlluxioThroughput Represents data transferred from the network stack ;BytesReadDomain and BytesReadDomainThroughput Represents data from domain socket transmission . You can see All data is transferred from the network stack ( Even if spark executor and LICENSE Of documents block In the same k8s Node ).
5、 ... and 、 Reference documents
- spark-on-k8s-operator/spark-pi.yaml at master · GoogleCloudPlatform/spark-on-k8s-operator · GitHub
- Running Spark on Alluxio in Kubernetes - Alluxio v2.7 (stable) Documentation
In this paper, from : stay kubernetes of use alluxio Speed up spark The data access - Alicloud developer community
边栏推荐
- 记一个 @nestjs/typeorm^8.1.4 版本不能获取.env选项问题
- Poj2315 football games
- [le plus complet du réseau] | interprétation complète de MySQL explicite
- Test de vulnérabilité de téléchargement de fichiers basé sur dvwa
- How does the crystal oscillator vibrate?
- Mongodb problem set
- [技术发展-28]:信息通信网大全、新的技术形态、信息通信行业高质量发展概览
- 剑指 Offer 38. 字符串的排列
- Basic operations of databases and tables ----- unique constraints
- c#网页打开winform exe
猜你喜欢

国家级非遗传承人高清旺《四大美人》皮影数字藏品惊艳亮相!

现货白银的一般操作方法

黄金价格走势k线图如何看?
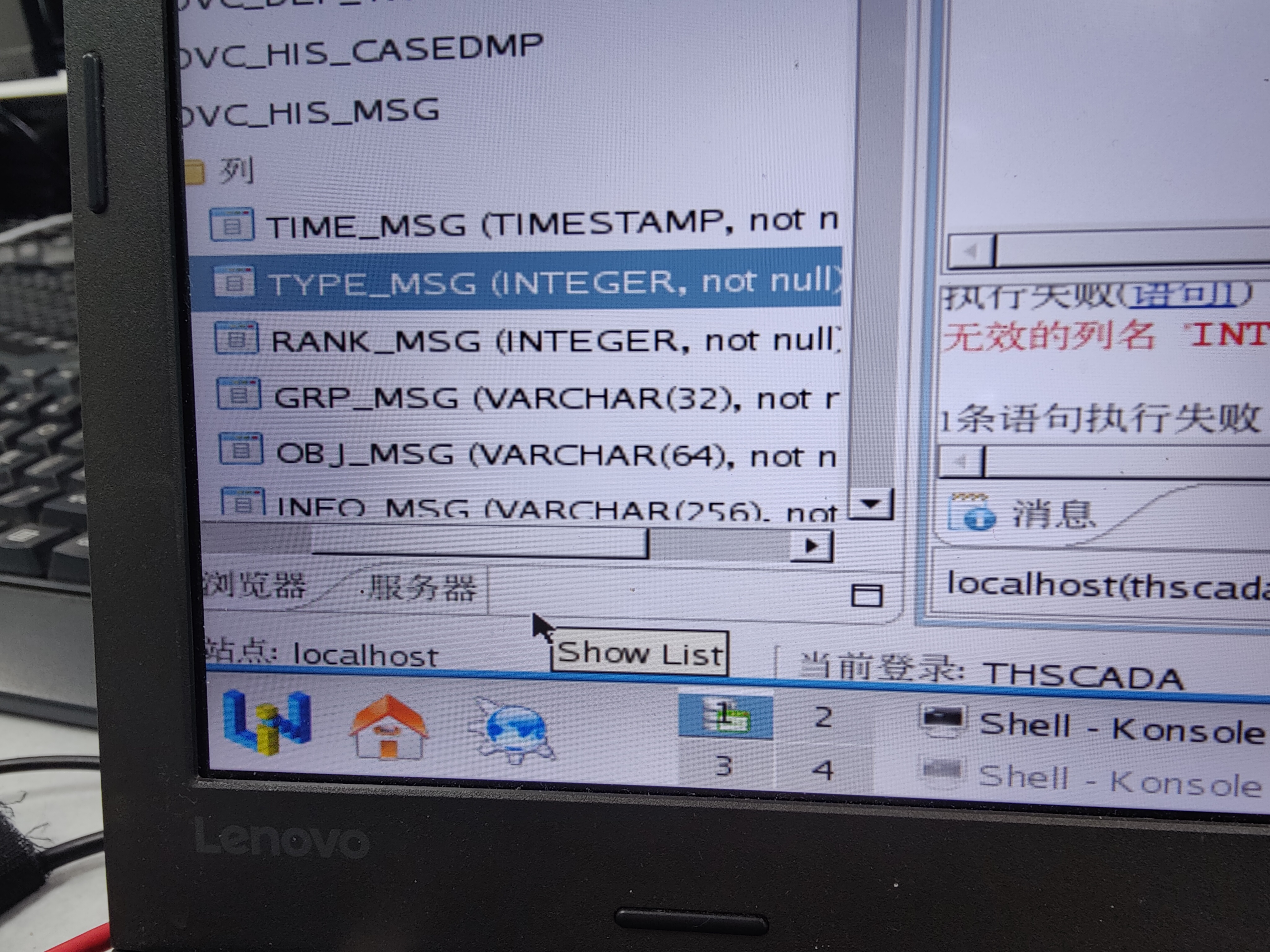
Who knows how to modify the data type accuracy of the columns in the database table of Damon
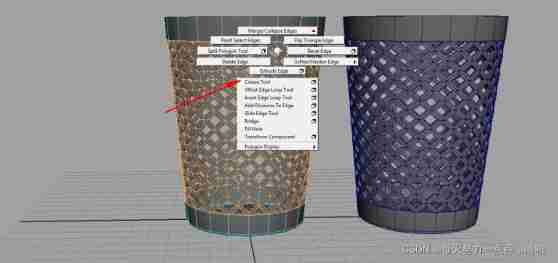
Maya hollowed out modeling

3D vision - 4 Getting started with gesture recognition - using mediapipe includes single frame and real time video
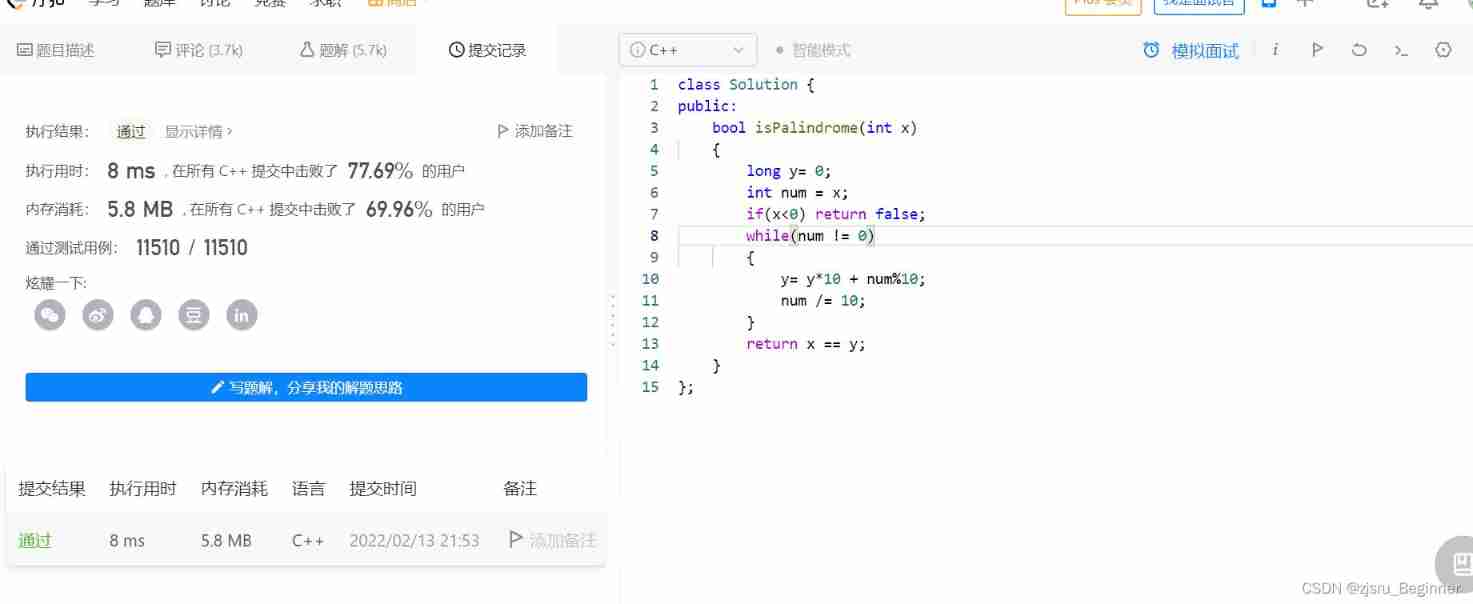
Force buckle 9 palindromes

Basic operations of databases and tables ----- non empty constraints

Some features of ECMAScript
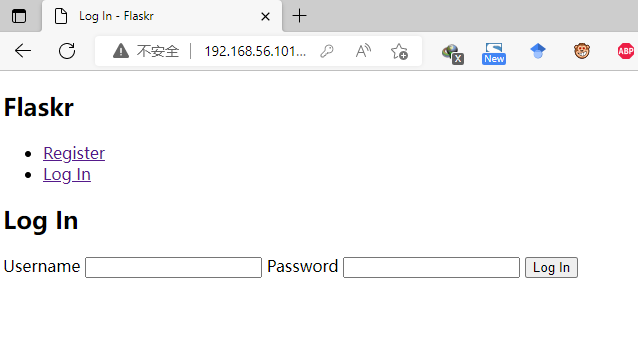
【Flask】官方教程(Tutorial)-part2:蓝图-视图、模板、静态文件
随机推荐
SPIR-V初窺
Folio.ink 免费、快速、易用的图片分享工具
Huawei converged VLAN principle and configuration
How does Huawei enable debug and how to make an image port
The basic usage of JMeter BeanShell. The following syntax can only be used in BeanShell
NLP第四范式:Prompt概述【Pre-train,Prompt(提示),Predict】【刘鹏飞】
Format code_ What does formatting code mean
【Flask】响应、session与Message Flashing
现货白银的一般操作方法
【已解决】如何生成漂亮的静态文档说明页
Leetcode study - day 35
Loop structure of program (for loop)
基於DVWA的文件上傳漏洞測試
Docker compose configures MySQL and realizes remote connection
A Cooperative Approach to Particle Swarm Optimization
Vulhub vulnerability recurrence 75_ XStream
Maya hollowed out modeling
Superfluid_ HQ hacked analysis
MCU lightweight system core
Code Review关注点