当前位置:网站首页>Use of crawler manual 02 requests
Use of crawler manual 02 requests
2022-07-06 00:58:00 【A little black sauce】
Requests Use
The goal is : list Requests Common functions , Convenient access .
One . GET request
1. Basic usage
import requests
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text[:100])
print(r.cookies)
Running results :
<class 'requests.models.Response'>
200
<class 'str'>
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charse
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
2. Portability parameter (params Parameters )
import requests
data = {
'name': 'germey',
'age': 25
}
r = requests.get('https://httpbin.org/get', params=data)
print(r.text)
print(type(r.text))
print(r.json())
print(type(r.json()))
Running results : The return is json character string , Can be called directly json() Turn to dictionary
{
"args": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-620913df-3f5acf216ce4775c03354c66"
},
"origin": "192.168.1.1",
"url": "https://httpbin.org/get?name=germey&age=25"
}
<class 'str'>
{'args': {'age': '25', 'name': 'germey'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.22.0', 'X-Amzn-Trace-Id': 'Root=1-620913df-3f5acf216ce4775c03354c66'}, 'origin': '192.168.1.1', 'url': 'https://httpbin.org/get?name=germey&age=25'}
<class 'dict'>
3. Grab binary data ( picture , Audio , video )
import requests
r = requests.get('https://github.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)
Writing into a file can save binary data .
4. Add request header ( add to UA, agent , Anti theft chain and other parameters )
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get('https://httpbin.org/get', headers=headers)
print(r.text)
Running results :
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-62091775-6e03f96c398c288d0537dc48"
},
"origin": "192.168.1.1",
"url": "https://httpbin.org/get"
}
Two . POST request
import requests
data = {
'name': 'germey', 'age': '25'}
r = requests.post("https://www.httpbin.org/post", data=data)
print(r.text)
Running results :form The parameter in is POST Submitted parameters
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-62091826-3152bf7a1515a77d072a49b8"
},
"json": null,
"origin": "192.168.1.1",
"url": "https://www.httpbin.org/post"
}
3、 ... and . Respond to
1. Get response information
import requests
r = requests.get('https://httpbin.org/get')
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)
Running results :
<class 'int'> 200
<class 'requests.structures.CaseInsensitiveDict'> {'Date': 'Sun, 13 Feb 2022 14:48:27 GMT', 'Content-Type': 'application/json', 'Content-Length': '308', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
<class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[]>
<class 'str'> https://httpbin.org/get
<class 'list'> []
2. Perform different operations according to the response status code
import requests
r = requests.get('https://ssr1.scrape.center/')
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')
Running results : Ternary expression , sentence 1 if Conditions else sentence 2, Execute statement if condition is true 1, If the condition is false, execute the statement 2
Request Successfully
Four . Advanced usage
1. Upload files
import requests
files = {
'file': open('favicon.ico', 'rb')}
r = requests.post('https://www.httpbin.org/post', files=files)
print(r.text)
Running results :file Part is the uploaded file information , Binary content is partially omitted
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAABAAI..."
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "6665",
"Content-Type": "multipart/form-data; boundary=d4f2a858cbaf82294e38dc9d13398861",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-62091be0-0620970e4ce4ad2744525587"
},
"json": null,
"origin": "192.168.1.1",
"url": "https://www.httpbin.org/post"
}
2. Cookie Set up
Method 1 : Take from the response
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)
Running effect :
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315
Method 2 : Copy from browser , Put in the request header
import requests
headers = {
"Cookie": "PSTM=1642921828; BAIDUID=5D0366F594005428ED23CD344FFF8AB4:FG=1; BIDUPSID=C513DE1AABFEE265656D91ED68FFD990; BD_UPN=12314753; __yjs_duid=1_28bc45f4f2a7966986384542e284e0061642937695718; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; BD_CK_SAM=1; PSINO=5; BAIDUID_BFESS=5D0366F594005428ED23CD344FFF8AB4:FG=1; H_PS_645EC=75f2y6ETpxsjOyy%2Fh8Ps97om%2BQzF1lQ85oIBJWVzxjZ7a8PaM7IA2umnH%2Bw; COOKIE_SESSION=6097_1_9_9_0_12_1_0_8_9_3_1_0_0_0_0_0_1644493227_1644763447%7C9%2386341_20_1644493217%7C7; BD_HOME=1; BDUSS=NSdVpwWFAtd1I3YUg0MkNwek5WVEd0SmV1N2FOYkNjZHNPV1VGRVByVVJxekJpSVFBQUFBJCQAAAAAAAAAAAEAAABmANkpQXBwaGFvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABEeCWIRHgliYz; BDUSS_BFESS=NSdVpwWFAtd1I3YUg0MkNwek5WVEd0SmV1N2FOYkNjZHNPV1VGRVByVVJxekJpSVFBQUFBJCQAAAAAAAAAAAEAAABmANkpQXBwaGFvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABEeCWIRHgliYz; H_PS_PSSID=35104_31253_35833_35488_34584_35490_35871_35802_35326_26350_35883_35724_35877_35746; sug=3; sugstore=1; ORIGIN=0; bdime=0; BA_HECTOR=a4242h810h2k0005p71h0i7h00q"
}
r = requests.get("http://www.baidu.com/", headers=headers)
print(r.text)
Method 3 : structure RequestsCookieJar object
cookies = 'PSTM=1642921828; BAIDUID=5D0366F594005428ED23CD344FFF8AB4:FG=1; BIDUPSID=C513DE1AABFEE265656D91ED68FFD990; BD_UPN=12314753; __yjs_duid=1_28bc45f4f2a7966986384542e284e0061642937695718; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; BD_CK_SAM=1; PSINO=5; BAIDUID_BFESS=5D0366F594005428ED23CD344FFF8AB4:FG=1; H_PS_645EC=75f2y6ETpxsjOyy%2Fh8Ps97om%2BQzF1lQ85oIBJWVzxjZ7a8PaM7IA2umnH%2Bw; COOKIE_SESSION=6097_1_9_9_0_12_1_0_8_9_3_1_0_0_0_0_0_1644493227_1644763447%7C9%2386341_20_1644493217%7C7; BD_HOME=1; BDUSS=NSdVpwWFAtd1I3YUg0MkNwek5WVEd0SmV1N2FOYkNjZHNPV1VGRVByVVJxekJpSVFBQUFBJCQAAAAAAAAAAAEAAABmANkpQXBwaGFvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABEeCWIRHgliYz; BDUSS_BFESS=NSdVpwWFAtd1I3YUg0MkNwek5WVEd0SmV1N2FOYkNjZHNPV1VGRVByVVJxekJpSVFBQUFBJCQAAAAAAAAAAAEAAABmANkpQXBwaGFvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABEeCWIRHgliYz; H_PS_PSSID=35104_31253_35833_35488_34584_35490_35871_35802_35326_26350_35883_35724_35877_35746; sug=3; sugstore=1; ORIGIN=0; bdime=0; BA_HECTOR=a4242h810h2k0005p71h0i7h00q'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('http://www.baidu.com/', cookies=jar, headers=headers)
print(r.text)
3. Session maintain
Keep logged in Cookies
import requests
requests.get('https://www.httpbin.org/cookies/set/number/123456789')
r = requests.get('https://www.httpbin.org/cookies')
print(r.text)
s = requests.Session()
s.get('https://www.httpbin.org/cookies/set/number/123456789')
r = s.get('https://www.httpbin.org/cookies')
print(r.text)
Running results :
{
"cookies": {}
}
{
"cookies": {
"number": "123456789"
}
}
4. SSL Certificate validation
problem : Some websites will verify SSL certificate , You cannot access without a certificate file
import requests
response = requests.get('https://ssr2.scrape.center/')
print(response.status_code)
Running results : Report errors
requests.exceptions.SSLError: HTTPSConnectionPool(host='ssr2.scrape.center', port=443): Max retries exceeded with url: / (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')])")))
resolvent : Cancel SSL verification
import requests
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)
Running results : The alarm , But the response code 200
C:\Users\Apphao\anaconda3\lib\site-packages\urllib3\connectionpool.py:1004: InsecureRequestWarning: Unverified HTTPS request is being made to host 'ssr2.scrape.center'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning,
200
Cancel the terminal alarm printing by closing the alarm information or capturing the alarm information
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)
Running results :
200
200
You can also specify SSL Certificate file
import logging
import requests
r = requests.get('https://ssr2.scrape.center/', cert=('/path/server.crt', '/path/server.key'))
print(response.status_code)
5. timeout
wait for 1 second , If the timeout occurs, an exception is thrown
import requests
r = requests.get('https://www.httpbin.org/get', timeout=1)
print(r.status_code)
Connect to the server and wait 1 second , Read server wait 2 second
import requests
r = requests.get('https://www.httpbin.org/get', timeout=(1,2)
print(r.status_code)
Wait forever , Copy None Or not timeout Parameters
import requests
r = requests.get('https://www.httpbin.org/get', timeout=None)
print(r.status_code)
6. Identity Authentication
Mode one : Pass on HTTPBasicAuth object
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('https://ssr3.scrape.center/', auth=HTTPBasicAuth('admin', 'admin'))
print(r.status_code)
Mode two : Direct tuple ( convenient )
import requests
r = requests.get('https://ssr3.scrape.center/', auth=('admin', 'admin'))
print(r.status_code)
Mode three : Use OAuth1 modular
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECRET',
'USER_OAUTH_TOKEN', 'USER_OAUTH_TOKEN_SECRET')
r = requests.get(url, auth=auth)
print(r.status_code)
7. Agent settings
import requests
proxies = {
'http': 'http://10.10.10.10:1080',
'https': 'https://10.10.10.10:1080'
}
requests.get('https://httpbin.org/get', proxies=proxies)
8. Prepared Request
requests Internal implementation , After mastering it, you can control it more carefully and flexibly requests request
from requests import Request, Session
url = 'https://httpbin.org/post'
data = {
'name': 'germey'}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
Running effect : Hair harmony POST Request the same
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-62092798-72199d8761a339441af9b39c"
},
"json": null,
"origin": "192.168.1.1",
"url": "https://httpbin.org/post"
}
边栏推荐
- [groovy] JSON serialization (jsonbuilder builder | generates JSON string with root node name | generates JSON string without root node name)
- golang mqtt/stomp/nats/amqp
- 猿桌派第三季开播在即,打开出海浪潮下的开发者新视野
- FFT learning notes (I think it is detailed)
- Gartner released the prediction of eight major network security trends from 2022 to 2023. Zero trust is the starting point and regulations cover a wider range
- 【文件IO的简单实现】
- The third season of ape table school is about to launch, opening a new vision for developers under the wave of going to sea
- Cannot resolve symbol error
- servlet(1)
- Lone brave man
猜你喜欢

282. Stone consolidation (interval DP)

激动人心,2022开放原子全球开源峰会报名火热开启

Arduino hexapod robot
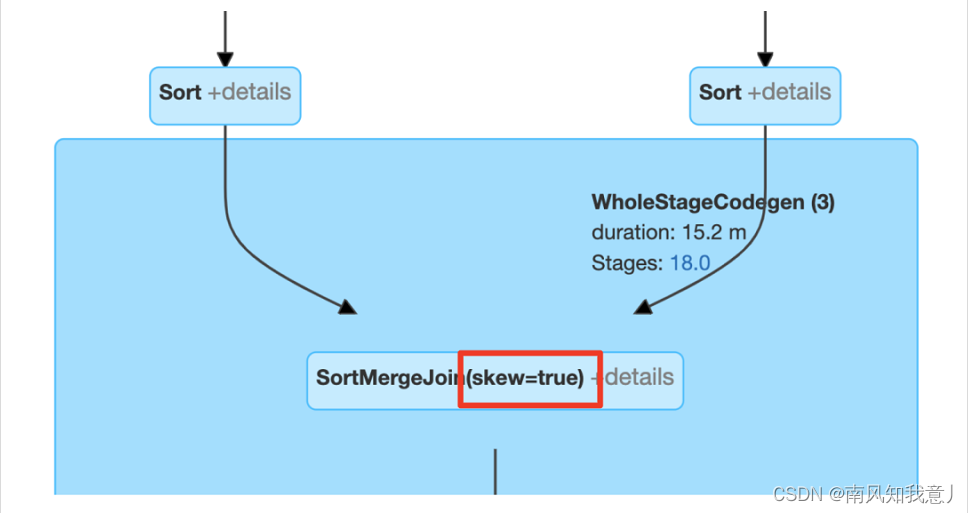
Spark AQE
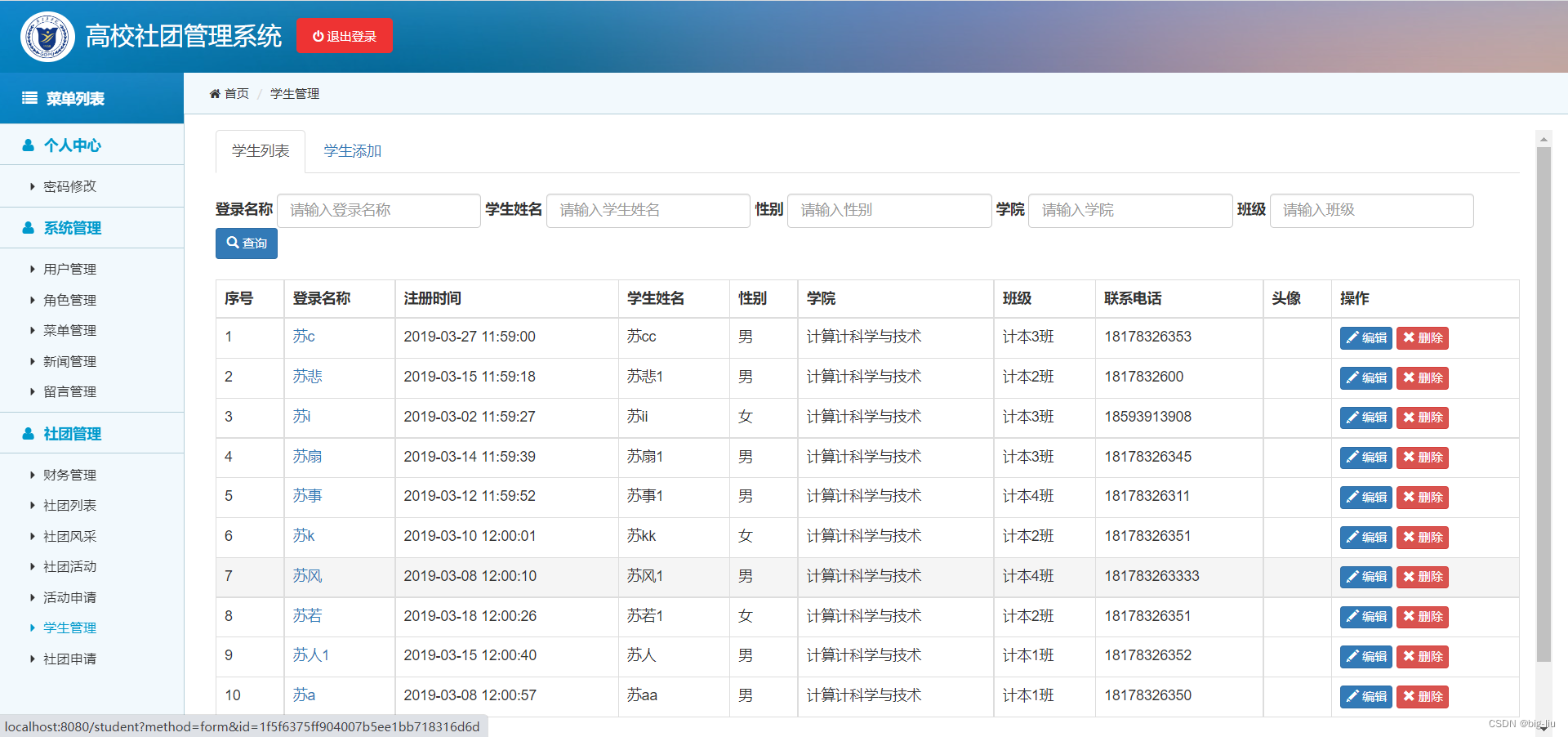
毕设-基于SSM高校学生社团管理系统
![[groovy] JSON string deserialization (use jsonslurper to deserialize JSON strings | construct related classes according to the map set)](/img/bf/18ef41a8f30523b7ce57d03f93892f.jpg)
[groovy] JSON string deserialization (use jsonslurper to deserialize JSON strings | construct related classes according to the map set)
![[groovy] XML serialization (use markupbuilder to generate XML data | create sub tags under tag closures | use markupbuilderhelper to add XML comments)](/img/d4/4a33e7f077db4d135c8f38d4af57fa.jpg)
[groovy] XML serialization (use markupbuilder to generate XML data | create sub tags under tag closures | use markupbuilderhelper to add XML comments)

KDD 2022 | EEG AI helps diagnose epilepsy
1791. Find the central node of the star diagram / 1790 Can two strings be equal by performing string exchange only once

Cf:c. the third problem
随机推荐
Browser reflow and redraw
SAP Spartacus home 页面读取 product 数据的请求的 population 逻辑
Xunrui CMS plug-in automatically collects fake original free plug-ins
MobileNet系列(5):使用pytorch搭建MobileNetV3并基于迁移学习训练
cf:H. Maximal AND【位运算练习 + k次操作 + 最大And】
Hundreds of lines of code to implement a JSON parser
MIT博士论文 | 使用神经符号学习的鲁棒可靠智能系统
synchronized 和 ReentrantLock
How to make your own robot
ADS-NPU芯片架构设计的五大挑战
vSphere实现虚拟机迁移
Arduino六足机器人
Questions about database: (5) query the barcode, location and reader number of each book in the inventory table
Dedecms plug-in free SEO plug-in summary
How spark gets columns in dataframe --column, $, column, apply
Zhuhai laboratory ventilation system construction and installation instructions
The growth path of test / development programmers, the problem of thinking about the overall situation
95后CV工程师晒出工资单,狠补了这个,真香...
Gartner发布2022-2023年八大网络安全趋势预测,零信任是起点,法规覆盖更广
Pbootcms plug-in automatically collects fake original free plug-ins