Meta AI西雅图研究负责人Luke Zettlemoyer | 万亿参数后,大模型会持续增长吗?
2022-07-06 00:33:00
【智源社区】
导读:预训练语言模型正变得越来越大,在惊讶于其强大能力的同时,人们也不禁要问:语言模型的规模在未来会持续增长吗?Meta AI西雅图研究负责人,华盛顿大学计算机科学与工程学院Paul G. Allen教授Luke Zettlemoyer发表了题为“Large Language Models: Will they keep getting bigger? And, how will we use them if they do?”的主旨演讲,介绍了团队在大规模语言模型上的相关工作。Zettlemoyer教授围绕以下三个问题展开了讨论:
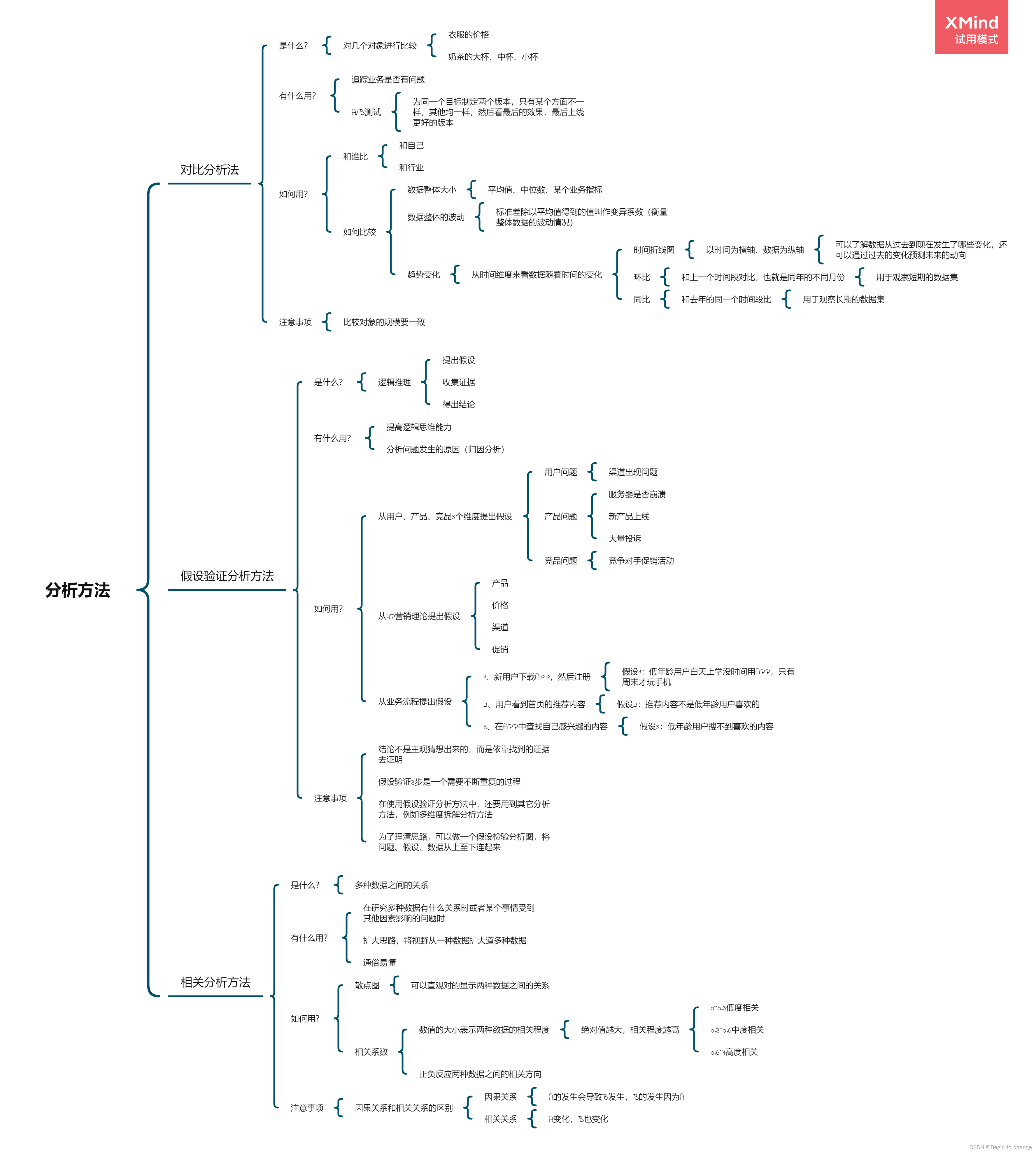
随着语言模型的规模不断增大,「语言模型的规模是否会持续增长」、「如何利用语言模型」成为了研究者们重点关注的问题。下图展示了预训练语言模型的参数规模与时间的关系,x轴代表时间,y轴代表参数规模,模型正在变得越来越大。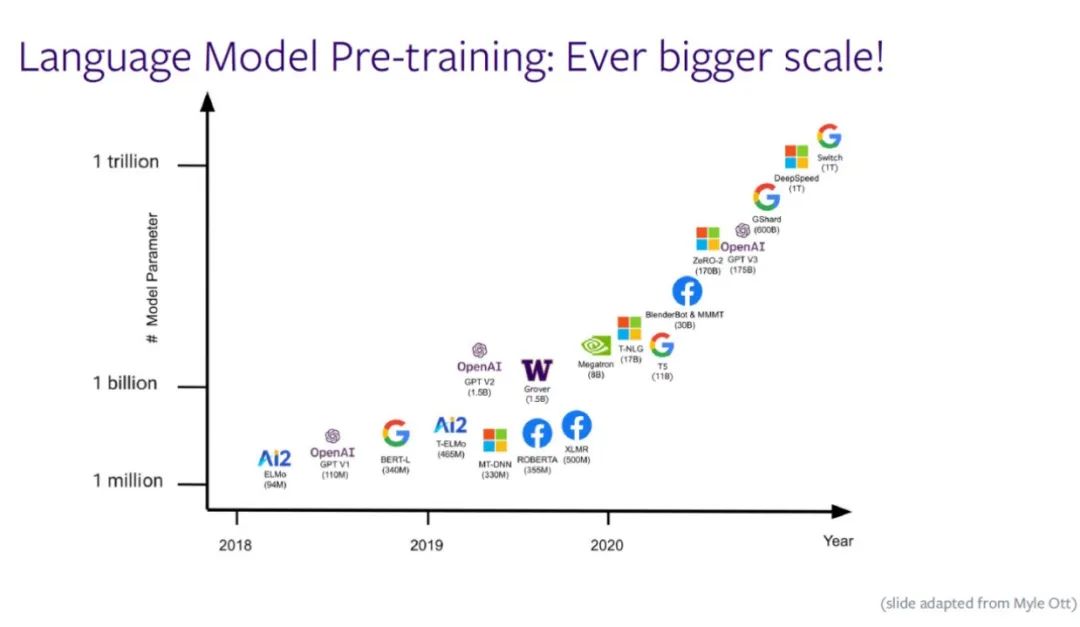
语言模型蕴含了语句的分布,当人们拥有语言模型后,就可以利用模型根据当前已有的单词预测之后可能出现的单词。尽管存在诸如BERT那样的双向语言模型,本文只讨论从左至右处理单词的语言模型。以Open AI的GPT系列模型为例,零样本学习的能力让该语言模型可以处理任何自然语言处理(NLP)任务。该模型将 NLP任务转换为序列到序列的任务。例如,输入一段关于任务的描述文字,模型依据之前学习到的知识对文本进行分类。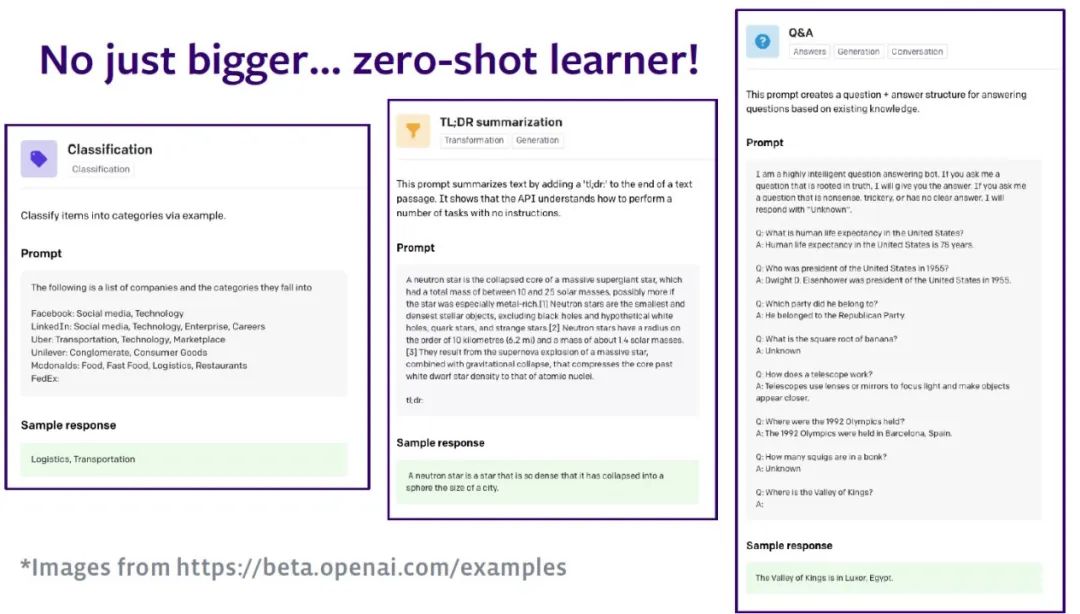
如下图所示,语言模型的参数量正接近一万亿,人们同时训练所有参数的难度越来越大。由于没有足够的数据或者算力作为支撑,模型难以得到充分的训练。近期,如PaLM、Chinchilla等模型尝试用较少的参数量、更多的数据和算力训练模型,控制了模型规模。
Zettlemoyer教授指出,如果人们真的想要将模型变得更大,最终不得不做出一些妥协:不再选择使用大型稠密的神经网络,而是采用稀疏化思想,使用模型的不同部分处理不同输入(例如,谷歌的 Switch模型)。即使采用最先进的GPU集群,算力需求仍然在接近计算设备的极限,必须在顶层架构上实现创新。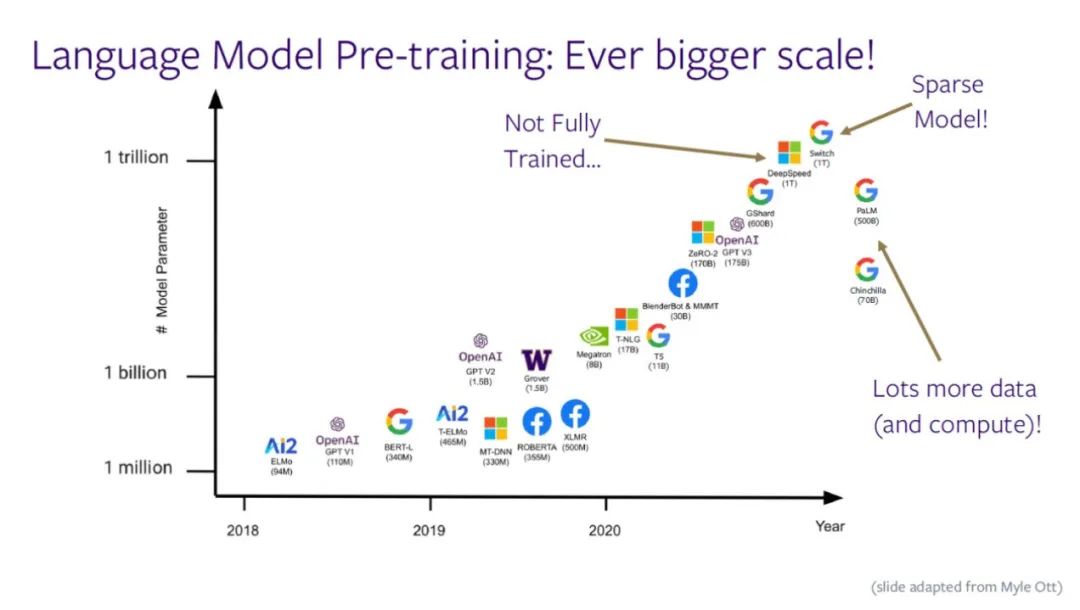
训练稠密模型时,任何输入都会被扔进整个模型,每一个参数都会参与计算。研究者们提出了数据并行、模型并行和流水线并行来加快计算,这些计算被部署到GPU集群的不同节点上。尽管如此,对于每一个输入,模型仍然要进行大量的计算,尤其是对那些大规模的模型。Zettlemoyer教授指出,采用稀疏模型进行条件计算可以仅使用模型的部分参数参与计算,节约大量计算资源。Transformer结构包含自注意力层和全连接层,输入在自注意力层中完成计算后输入到全连接层中,当语言模型规模扩大时,超过95%的参数都来自全连接层,Zettlemoyer 教授团队尝试将全连接层稀疏化。在采用诸如ReLU的激活函数时,实际上对神经网络进行了稀疏化,同样地,在训练大规模语言模型时,人们已经进行了某种程度上的条件计算。但是在实际训练时,我们无法事先知道应该计算的部分,也无法利用高效的矩阵乘法。为此,Zettlemoyer 教授团队试图将部分神经网络切开,将全连接层分成若干部分,将不同部分分配给不同的处理器,并设计了特定的路由机制。如下图所示的混合专家模型(mixture of experts)中,“Dogs bark”和“Cats purr”在训练时会被输入给模型。模型会将不同的单词通过路由输入给不同的专家网络,经过计算后会被重新整理成原来的顺序。Zettlemoyer教授指出,真正的挑战在于如何在保证性能的前提下,提高这一过程的效率。为此,Zettlemoyer 教授团队通过专家专门化和专家均衡化技术技术,使不同专家网络进行不同的计算,并且实现计算的均匀分配,达到性能的饱和令。标准的做法是在训练的过程中增加一些损失函数以确保均衡的路由,使用容量因子(capacity factor)确保不出现过载。这种方法引入了额外的损失函数和超参数,需要确保设定表现得稳定。Zettlemoyer 教授团队在2021年提出了BASE Layers,其主要特性如下:(1)没有引入额外的损失函数或者超参数(2)能达到数据并行90%的计算速度(3)每一个词例被分配到一个专家(4)所有专家都是均衡且饱和的。在实现专家均衡的部分,该模型将可训练的均衡替换为基于算法的均衡,形式化为线性分配问题,并采用拍卖算法求解。上图展示了三种不同的计算量下,用困惑度衡量的预训练模型的效果。困惑度越低代表模型训练效果越好。图中的蓝线代表BASE Layers的工作,与其他稠密模型效果相当,当模型越大时甚至效果更好。此外,该工作和Sparse MoE效果相当,略优于 Switch。接下来,Zettlemoyer教授介绍了Gururangan等人在2021年的工作DEMix Layers。研究者们搜集了大量文档,将其由RoBERTa得到的表征依照相似度聚类,可视化结果表明语言数据是异质的。如图所示,医学文献大多都聚集在红色簇中,但计算机科学文献和新闻也都可以聚集在一起,这表明数据有其本身的结构。这启发我们:可以基于数据的这种特点拆分计算过程,从而让实现专家专门化。DEMix设计了领域特定的专家,固定了路由的过程。特定领域都由特定的专家处理,并且可以在需要的时候混合、增加或者移除特定的专家,强调快速适应。模型训练时,假定有对应的元数据指示数据所在的领域,不需要其它形式的均衡化。通过条件计算,领域专家可以被并行训练,尽管参数相比于稠密模型更多,但训练速度更快。为了验证模型效果,研究者们搜集了一些新领域的数据。评估时同样采用困惑度作为评价指标,所有模型的计算时长限制在48小时内,对比的模型包括GTP-3 small, medium, large, XL四种。研究者们假定在训练和测试时已知数据从属的领域。实验结果表明,DEMix在模型规模较小时更加有效,随着模型参数量增加,稠密模型和DEMix差距在缩小。进一步观察在最大的模型上的实验结果可以发现,DEMix 在新闻和Reddit数据集上的性能没有稠密模型好,但是如何对领域进行划分基于的是主观的判断,研究者在此使用了元数据,还需要进一步探究如何划分数据领域。研究者假定不知道输入具体所在的领域,通过 DEMix 对专家进行混合。一种方法是取小规模数据在所有专家上计算,得到领域的后验分布,这样就不需要额外的参数去混合专家。对100个输入序列,研究者们可视化了领域专家在所有领域上的分布,每个领域专家都和自己所在的领域密切相关,但是有一些更加异质化的领域(如WebText数据集)和其它领域也有一定关系。当研究者们分析领域专家在新领域上的相关度时,发现这种相关度比在训练集上的那些领域更加分散。意味着当模型遇到新领域时倾向于从各个不同的专家那里获得信息。实验结果显示,采用混合专家的DEMix模型在新领域中取得最好的结果。DEMix可以将模型的其他部分冻结,针对新数据计算领域的后验分布,增加一个新的专家并且投入一些新数据,从已有领域中后验概率最高的专家的参数开始继续训练。一些特定领域的专家(如有关仇恨言论的)在测试时可能是不需要的,通过移除这些专家某种意义上让模型不会暴露在这些特定领域。研究者们通过将全连接层替换为混合专家模型,如BaseLayers和DeMix Layers,以中小型的规模进行更有效的训练。这些简单的方法省去了微调。DEMix具有增加额外模块的能力,但是目前还不清楚哪一种方法能够更好的扩大模型规模。
对模型输入「What would you put meat on top of to cook it?」这样一个有关常识的问题,GPT-3会回答道:“hot dog bun”,但这并不是我们所期望的答案,我们希望的答案是类似于“A hot pan”。尽管这个例子看起来有些愚蠢,但是能够帮助我们理解语言模型遇到的问题。当研究者采用如Commonsense QA数据集中的常识性问题去测试模型时,模型可能会作出错误的选择。此时模型在做多项选择,“frying pan”是其中的一个选项,尽管该选项是正确的,但是其可以有多种表述。对于同一个事物,语言模型可能生成多种不同的表述。Zettlemoyer教授展示了语言模型针对该问题最可能的10个输出,发现其中部分是完全错误的,但另一部分答案与正确答案是正确的或者至少是相关的。图中蓝色的四个选项表达了同样地概念,只不过是锅的不同的表述。注意到当对同一事物有多种表述时,这些相同的表述相互竞争,最终导致了形式竞争(Surface Form Competition)问题。由于语言模型是一个针对词语的概率分布,当stove的概率为0.9时,frying pan的概率就不可能超过0.1。以 COPA数据集上的语言建模问题为例。假定前提为「酒吧关闭是因为」,需要从假设「太拥挤了」和「现在是凌晨三点」中选一个更为正确的答案。如果直接将前提输入模型,得到假设1和假设2的概率,会发现假设1概率更高,因为拥挤和酒吧往往关联性更高,但这是错误的。为了防止这样的错误,需要做一些调整。为此采用条件点互信息(PMI),选择更加宽泛的概念作为领域前提,例如在上述例子中选择“因为”作为领域前提(Domain Premise),通过计算领域前提下的条件概率重新调整答案。研究者们在不同数据集上测试了不同大小的模型,最大的模型参数量达到175B。实验对比了不同的调整方案,PMI 在大多数情况下该方案都取得了最好的结果。Zettlemoyer教授介绍了噪声通道语言模型提示学习方案。噪声通道模型出现于前深度学习时代,相比于给定问题输出答案,噪声通道模型依据答案计算问题的概率。当人们微调语言模型时,考虑到微调所有的参数计算量太大,往往仅微调模型的一部分。目前有多种微调方案,如prompt tuning,head tuning和transformation tuning。在prompt tuning时就可以引入通道模型。实验结果显示,在prompt tuning下采用通道模型的方案,相比于直接微调效果显著更好,head tuning成为了最有竞争力的基线,基于噪声通道的提示微调整体而言取得更好结果,尤其是在Yahoo和DBPedia数据集上。1)尽管语言模型能够计算语句的概率,但形式竞争可能会导致错误的答案;2)PMI通过评估答案编码了多少问题的信息,来调整答案的概率;3)直接学习Noisy channel prompting model甚至能取得更好的效果。Zettlemoyer教授简要回顾了多语言和多模态的预训练模型,同时强调了开放科学的重要性。如今的模型接受不同的监督信号,近期的工作有XGLM,这是一种生成式的多语言模型;HTLM,这是一种应用于文档级别格式文本的模型;CM3,多模态的模型;InCoder用于生成或者填充代码的模型。此外,OPT是第一个公开的达到GPT-3规模的语言模型。在HTLM模型中,将文档结构用于预训练和提示模型,例如在进行摘要任务时,可以用<title>标签作为提示。我们也可以获取海量的HTML文档用于预训练。HTLM甚至能自动补全提示,例如下图中模型根据文本内容,自动生成了HTML标签如<title>和<body>。在CM3模型中,研究者们将html文件的<img>标签中的图像离散化成序列,这样就构成了多模态的序列混合了文字和图像token,之后便可以将其视作一般的序列使用语言模型进行处理,并进行诸如跨模态的零样本学习。InCoder是一种能够生成缺失代码或者注释的模型,其在大规模拥有开源许可的代码数据集上进行训练。Zettlemoyer教授表示,预训练模型能接收多种监督信号,图像、文字等都可以被离散化从而进行预训练。开放科学和模型共享具有重要意义。结语:
最后,Zettlemoyer教授回到了演讲最初提出的三个问题:Zettlemoyer教授表示目前模型的规模还在继续增长研究者们仍会投入更多的算力,在未来条件计算可能会得到重大突破;我们仍未找到充分利用语言模型的方式,零次学习和少样本学习都是值得研究的方向,不过这也取决于追求的性能以及代码的开源程度;Zettlemoyer教授指出,文本数据不是必备的,研究人员还可以尝试使用其它结构或者模态提供监督信号。

Richard Sutton:经验是AI的终极数据,四个阶段通向真正AI的发展之路梅宏院士:如何构造人工群体智能?| 智源大会特邀报告回顾图灵奖得主Adi Shamir最新理论,揭秘对抗性样本奥秘 | 智源大会特邀报告回顾 原网站版权声明
本文为[智源社区]所创,转载请带上原文链接,感谢
https://hub.baai.ac.cn/views/18647



![[designmode] composite mode](/img/9a/25c7628595c6516ac34ba06121e8fa.png)