当前位置:网站首页>NLP generation model 2017: Why are those in transformer
NLP generation model 2017: Why are those in transformer
2022-07-06 00:23:00 【Ninja luantaro】
1、 Briefly describe Transformer Feedforward neural network in ? What activation function is used ? Related advantages and disadvantages ?
Feedforward neural network adopts two linear transformations , The activation function is Relu, The formula is as follows :
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0, xW_1 + b_1) W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
advantage :
- SGD The convergence rate ratio of the algorithm sigmoid and tanh fast ;( The gradient is not saturated , Solved the problem of gradient disappearance )
- Low computational complexity , There's no need to do exponential operations ;
- Suitable for backward propagation .
shortcoming :
- ReLU The output of is not zero-centered;
- ReLU It's very... During training ” fragile ”, Carelessness can cause neurons ” Necrosis ”. for instance : because ReLU stay x<0 Time gradient is 0, This leads to a negative gradient at this ReLU Set to zero , And this neuron may never be activated by any data . If this happens , So the gradient behind this neuron is always 0 了 , That is to say ReLU Neurons are dead , No longer responding to any data . In practice , If your learning rate It's big , It's very possible that you are on the Internet 40% All the neurons are dead . Of course , If you set a suitable smaller learning rate, This problem doesn't happen too often .,Dead ReLU Problem( Neuronal necrosis ): Some neurons may never be activated , Causes the corresponding parameters to never be updated ( In the negative part , The gradient of 0). There are two reasons for this phenomenon : Parameter initialization problem ;learning rate Too high results in too large parameter update during training . resolvent : use Xavier Initialization method , And avoid learning rate Set too large or use adagrad And so on learning rate The algorithm of .
- ReLU No amplitude compression of data , Therefore, the range of data will continue to expand with the increase of the number of model layers .
2、 Why Join in Layer normalization modular ?
motivation : because transformer Stacked A lot of layers , Easy to Gradient disappearance or gradient explosion ;
reason :
After the data passes through the function of the network layer , No longer normalized , The deviation will be bigger and bigger , So we need to data again Do normalization ;
Purpose :
Before the data is sent into the activation function normalization( normalization ) Before , You need to use the input information normalization Converted to an average of 0 The variance of 1 The data of , Avoid the input data falling in the saturation area of the activation function The gradient disappears problem
3、 Why? transformer Block use LayerNorm instead of BatchNorm?LayerNorm stay Transformer Where is the location of ?
Normalization The goal is to stabilize the distribution ( Reduce the variance of each dimension data ).
Another way to ask this question is : Why is image processing used batch normalization The effect is good , Natural language processing uses layer normalization good ?
LayerNorm Is to normalize the hidden layer state dimension , and batch norm Yes sample batch size Dimensions are normalized . stay NLP The task is not like the image task batch size Is constant , Usually changing , therefore batch norm The variance of will be larger . and layer norm Can alleviate the problem .
Reference material :
About Transformer Those why
边栏推荐
- Huawei equipment configuration ospf-bgp linkage
- 建立时间和保持时间的模型分析
- notepad++正则表达式替换字符串
- Global and Chinese market of valve institutions 2022-2028: Research Report on technology, participants, trends, market size and share
- LeetCode 1598. Folder operation log collector
- LeetCode 斐波那契序列
- 7.5 simulation summary
- LeetCode 6006. Take out the least number of magic beans
- Global and Chinese markets for pressure and temperature sensors 2022-2028: Research Report on technology, participants, trends, market size and share
- Knowledge about the memory size occupied by the structure
猜你喜欢
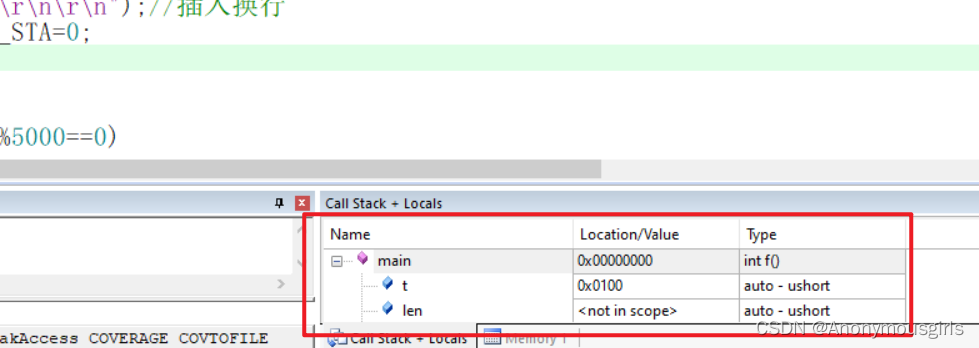
Set data real-time update during MDK debug
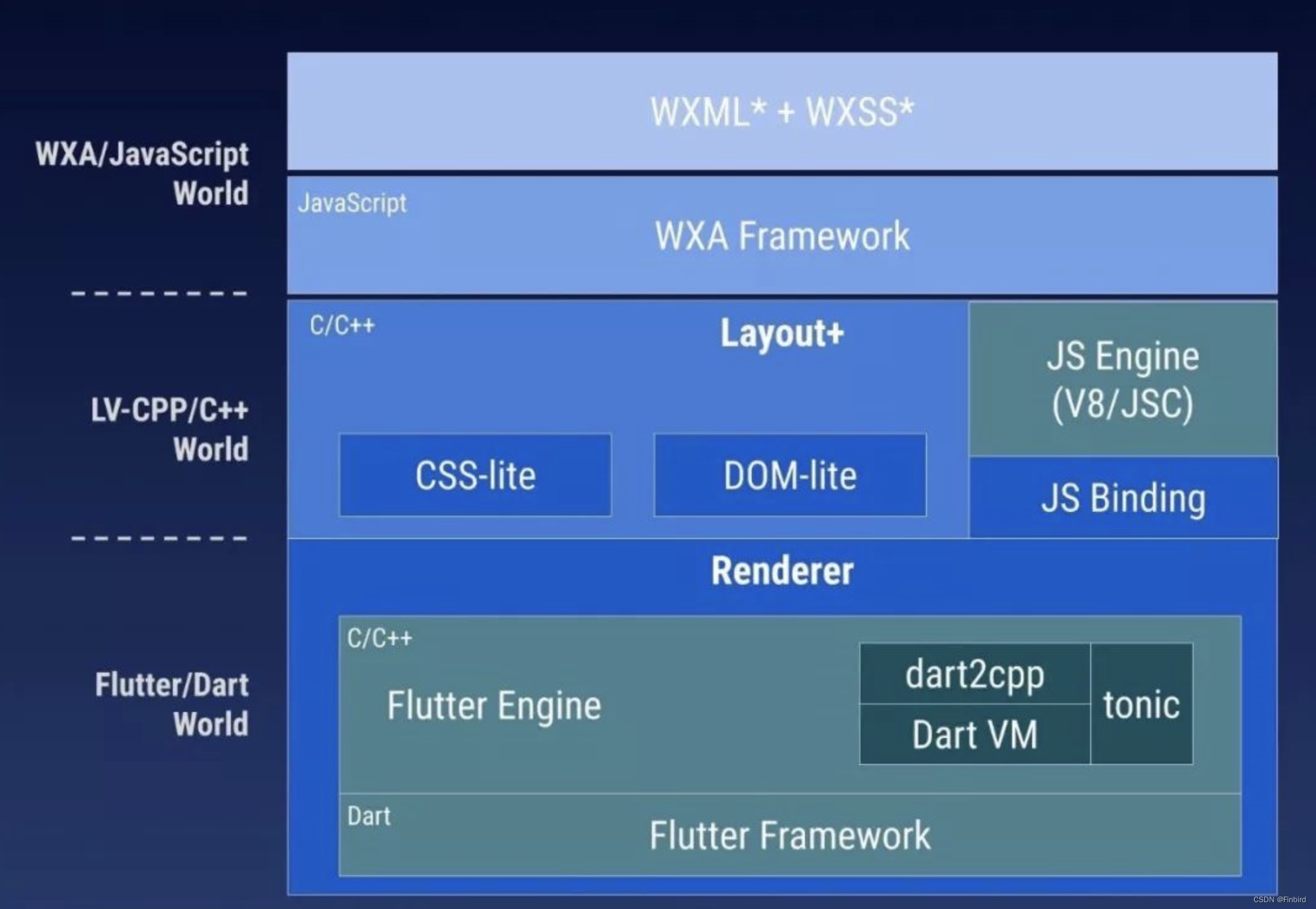
How to use the flutter framework to develop and run small programs
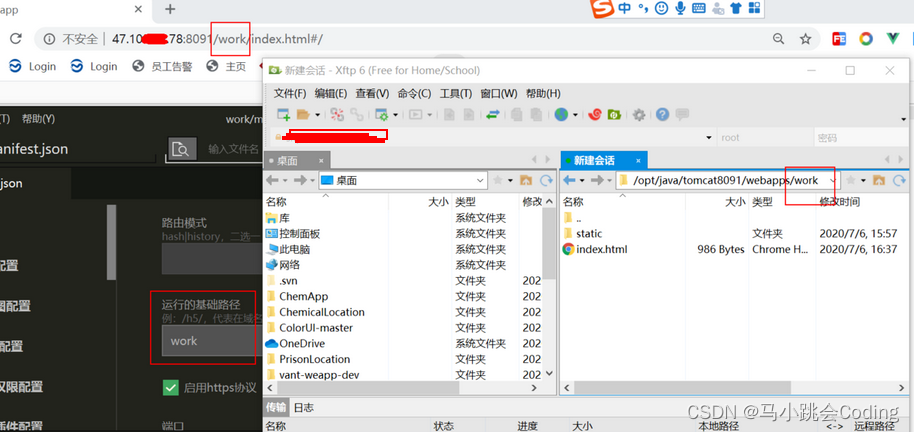
Uniapp development, packaged as H5 and deployed to the server
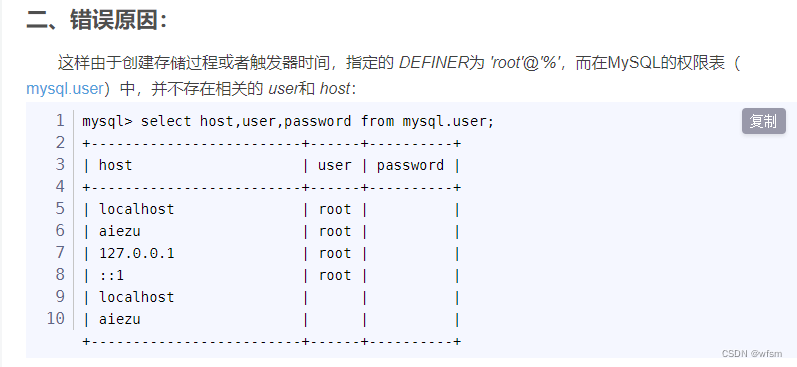
Problems encountered in the database
MySql——CRUD
Hardware and interface learning summary
关于slmgr命令的那些事
Hudi of data Lake (1): introduction to Hudi
uniapp开发,打包成H5部署到服务器
Configuring OSPF GR features for Huawei devices
随机推荐
Codeforces round 804 (Div. 2) [competition record]
Reading notes of the beauty of programming
Global and Chinese market of valve institutions 2022-2028: Research Report on technology, participants, trends, market size and share
7.5模拟赛总结
DEJA_VU3D - Cesium功能集 之 055-国内外各厂商地图服务地址汇总说明
Global and Chinese market of water heater expansion tank 2022-2028: Research Report on technology, participants, trends, market size and share
Atcoder beginer contest 254 [VP record]
[Online gadgets] a collection of online gadgets that will be used in the development process
Go learning --- structure to map[string]interface{}
从底层结构开始学习FPGA----FIFO IP核及其关键参数介绍
How to solve the problems caused by the import process of ecology9.0
QT -- thread
Permission problem: source bash_ profile permission denied
Spark-SQL UDF函数
[QT] QT uses qjson to generate JSON files and save them
Key structure of ffmpeg - avformatcontext
LeetCode 6005. The minimum operand to make an array an alternating array
XML Configuration File
OS i/o devices and device controllers
Spark DF增加一列