当前位置:网站首页>Spark AQE
Spark AQE
2022-07-06 00:28:00 【The south wind knows what I mean】
Spark AQE
cbo shortcoming
We all know , Previous CBO, Are based on static information Implement the plan to optimize , We all know static statistical information , Not necessarily accurate , such as hive Medium catalog The statistical information recorded in can be considered untrustworthy , The execution plan optimized on the basis of inaccurate statistical information is not necessarily optimal .AQE It was born to solve this problem , With spark The official response to AQE Continuous optimization , Here are some user scenarios to show AQE How it works
Optimize Shuffles The process
Spark shuffles It can be considered as the most important factor affecting query performance , stay shuffle When , How many configurations reducer It has always been spark Users' persistent problems , I believe a lot of use spark My friends are configuring spark.sql.shuffle.partitions Parameter time , Are somewhat confused , The configuration is too large , There will be many small task Affect operating performance , The configuration of small , It will lead to task The number is small , Single task Pull a lot of data , So as to bring GC,spill disk , even to the extent that OOM The problem of , I believe many friends have met executor lost, fetch failure And so on , The essential problem here is that we don't know how much real data is , Even if I know , Because this parameter is global , One of us application There are different query Between , Even the same one query The same job Different stage Between shuffle read The amount of data is not the same , So it is difficult to use a fixed value to unify .
Now? AQE It realizes dynamic adjustment shuffler partition number The mechanism of , Running different query Different stage When , Will be based on map End shuffle write The actual amount of data , To decide how many reducer To deal with it , In this way, no matter how the amount of data changes , Through different reducer Number to balance the data , So as to ensure a single reducer The amount of data pulled is not too large .
Here's the thing to note ,AQE It's not everything ,AQE I don't know map How many copies of data does the client need to separate , So in actual use , You can put spark.sql.shuffle.partitions The parameter is set larger .
adjustment Join Strategy
In cost optimization , choice join The type of is an important part , Because choose at the right time broadcast join, Just avoid shuffle, It will greatly improve the efficiency of implementation , But if the static data is wrong , For a larger ( The statistics look small ) Of relation the broadcast, I'll just put driver Memory burst .
AQE in , It will judge according to the real data at runtime , If there is a table smaller than broadcast join Configured threshold , Will implement the plan shuffle join Dynamically change it to broadcast join.
Handle Join Data skew in the process
Data skew has always been a difficult problem , Data skew , seeing the name of a thing one thinks of its function , It refers to some of the data key It's a huge amount of data , And then according to hash When you partition , The amount of data in a partition is particularly large , This data distribution will lead to serious performance degradation , Especially in sort merge join Under the circumstances , stay spark ui You can see up here , Some task The amount of data pulled is much larger than others task, The running time is also much longer than others task, Thus, this short board slows down the overall running time . Because of some task Pull most of the data , It will lead to spill To disk , In this case , It will be slower , More seriously , Put it right away. executor Memory burst .
Because it is difficult for us to know the characteristics of the data in advance , So in join It is difficult to avoid data skew through static statistical information , Even with hint, stay AQE in , By collecting runtime statistics , We can dynamically detect tilted partitions , Thus, the inclined partition , Split sub partitions , Each sub partition corresponds to one reducer, So as to mitigate the impact of data skew on performance .
from Spark UI Upper observation AQE Operating condition
Understand AQE Query Plans
AQE The execution plan of is dynamically changed during operation , stay spark 3.0 in , in the light of AQE Several specific execution plan nodes are introduced ,AQE Will be in Spark UI It also shows the initial plan , And the final optimized plan , Now let's show it in a graphic way .
The AdaptiveSparkPlan Node
Open the AQE, One or more... Will be added to the query AdaptiveSparkPlan Node as query Or the root node of the subquery , Before and during execution ,isFinalPlan Will be marked as false, query After execution ,isFinalPlan Will turn into true, Once marked true stay AdaptiveSparkPlan The plan under the node will no longer change .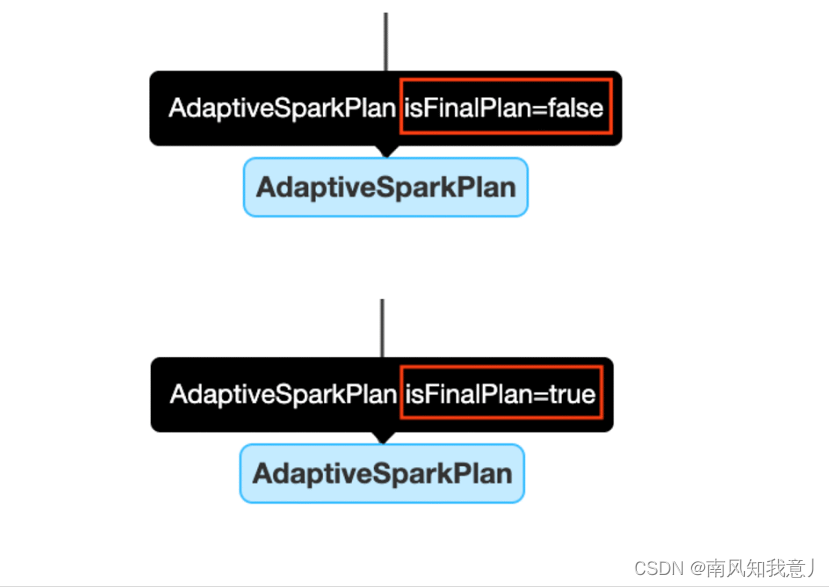
The CustomShuffleReader Node
CustomShuffleReader yes AQE The key link in optimization , This operator node will be based on the previous stage Real statistical data after operation , Dynamically adjust the latter stage The number of partitions , stay spark UI On , The mouse is on it , If you see coalesced Marked words , Just explain AQE A large number of small partitions have been detected , According to the configured partition data volume , Merge them together , You can turn it on details, You can see the original partition data , The number of partitions that have been merged .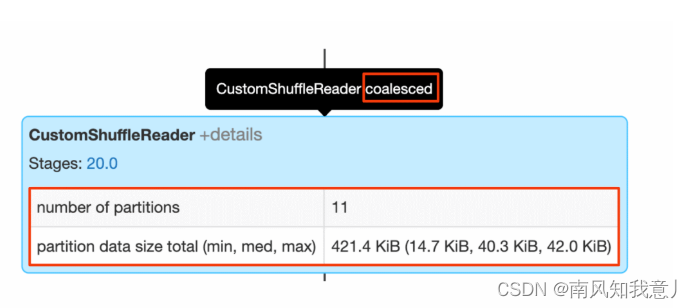
When there is a skewed When marking , explain AQE stay sort-merge During the calculation of , A tilted partition was detected ,details You can see it in it , How many inclined partitions are there , The number of partitions that have been split from these slanted partitions .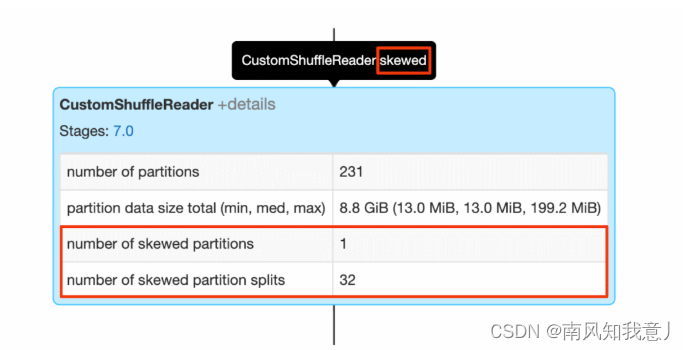
Of course, the above two optimization effects can be superimposed :
Detecting Join Strategy Change
Compare the execution plan , You can see it's in AQE The difference between the implementation plan before and after optimization , In the execution plan , Will show the initial Implementation plan , and Final Implementation plan , In the following example , It can be seen that , Initial SortMergeJoin Optimized for BroadcastHashJoin.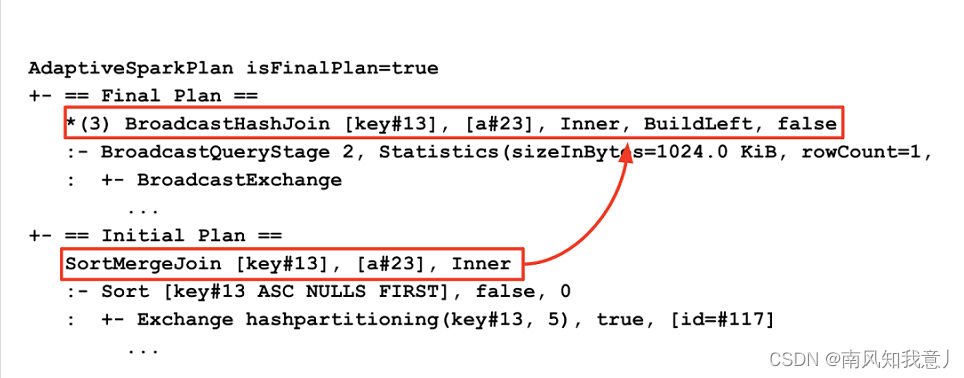
stay Spark UI The optimization effect can be seen more clearly above , Of course spark ui Only the current execution plan chart will be displayed on , You can query At the beginning , and query When it's done , Compare the difference between the execution plan at that time .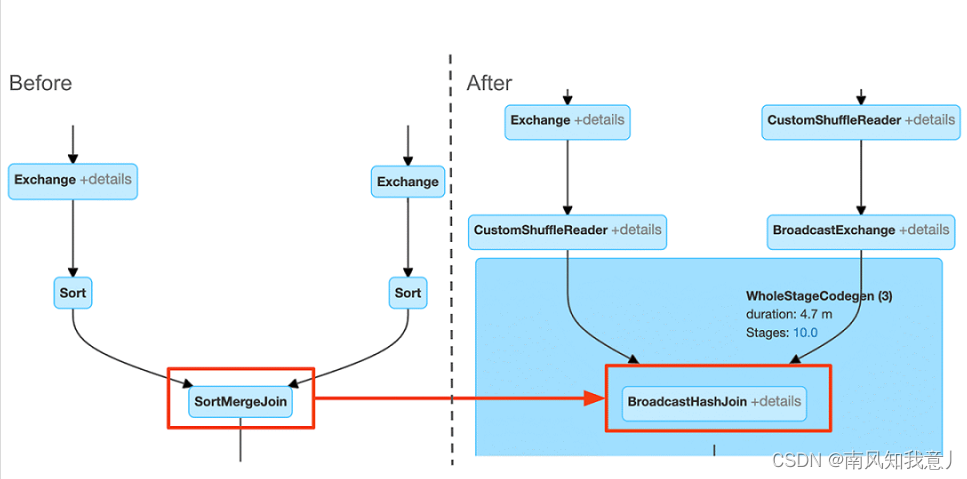
Detecting Skew Join
The following legend can be based on skew=true To judge Does the engine perform data skew optimization :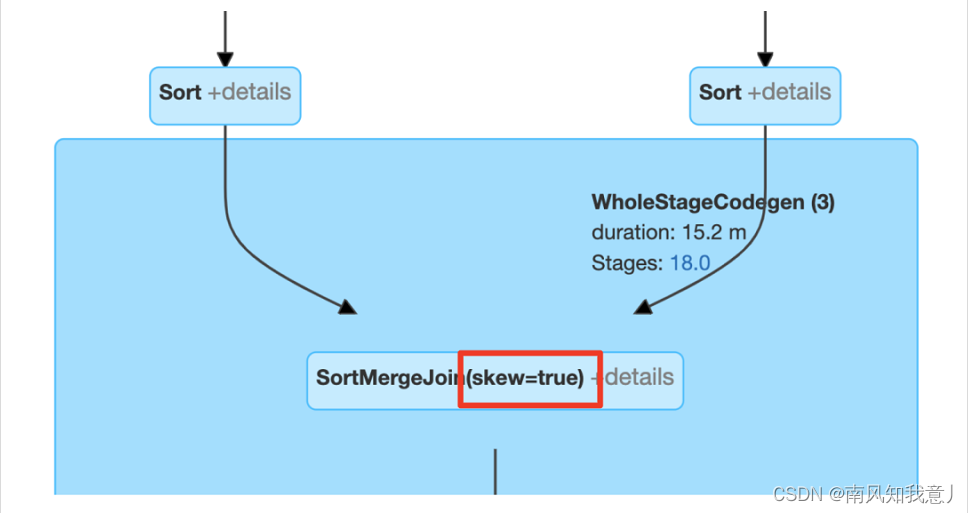
AQE It's still very powerful , Because it is based on the statistical information of real data ,AQE You can accurately choose the most suitable reducer number , conversion join Strategy , And processing data skew .
边栏推荐
- Wechat applet -- wxml template syntax (with notes)
- Knowledge about the memory size occupied by the structure
- Intranet Security Learning (V) -- domain horizontal: SPN & RDP & Cobalt strike
- How to use the flutter framework to develop and run small programs
- Global and Chinese markets for pressure and temperature sensors 2022-2028: Research Report on technology, participants, trends, market size and share
- Key structure of ffmpeg - avformatcontext
- About the slmgr command
- Determinant learning notes (I)
- STM32按键消抖——入门状态机思维
- [noi simulation] Anaid's tree (Mobius inversion, exponential generating function, Ehrlich sieve, virtual tree)
猜你喜欢
如何利用Flutter框架开发运行小程序
Set data real-time update during MDK debug

小程序技术优势与产业互联网相结合的分析
notepad++正則錶達式替換字符串
Basic introduction and source code analysis of webrtc threads

Go learning - dependency injection
MySQL functions
Room cannot create an SQLite connection to verify the queries
硬件及接口学习总结
多线程与高并发(8)—— 从CountDownLatch总结AQS共享锁(三周年打卡)
随机推荐
Hudi of data Lake (2): Hudi compilation
There is no network after configuring the agent by capturing packets with Fiddler mobile phones
Global and Chinese markets of POM plastic gears 2022-2028: Research Report on technology, participants, trends, market size and share
[Online gadgets] a collection of online gadgets that will be used in the development process
Date类中日期转成指定字符串出现的问题及解决方法
Wechat applet -- wxml template syntax (with notes)
Classic CTF topic about FTP protocol
从底层结构开始学习FPGA----FIFO IP核及其关键参数介绍
Mysql - CRUD
[EI conference sharing] the Third International Conference on intelligent manufacturing and automation frontier in 2022 (cfima 2022)
《编程之美》读书笔记
免费的聊天机器人API
MySQL存储引擎
notepad++正则表达式替换字符串
2022.7.5-----leetcode. seven hundred and twenty-nine
Tools to improve work efficiency: the idea of SQL batch generation tools
Pointer - character pointer
Ffmpeg learning - core module
Folding and sinking sand -- weekly record of ETF
AtCoder Beginner Contest 258【比赛记录】