当前位置:网站首页>Spark AQE
Spark AQE
2022-07-06 00:23:00 【南风知我意丿】
Spark AQE
cbo缺点
我们都知道,之前的 CBO,都是基于静态信息来对 执行计划进行优化,静态统计信息大家都懂的,不一定准确,比如hive中的catalog中记录的统计信息可以认为是不可信的,在一个不准确的统计信息的基础上优化出来的执行计划必然不是最优的。AQE 就是为了解决这个问题而诞生的,随着spark 官方对AQE持续的优化,下面举一些用户使用场景来展示AQE是如何用的
优化 Shuffles 过程
Spark shuffles 可以认为是影响查询性能最重要的影响因素,在 shuffle 的时候, 配置多少个 reducer 从来都是spark 用户的老大难问题,相信很多使用spark 的朋友在配置 spark.sql.shuffle.partitions 参数的时候,都是多少有些懵逼的,配置大了,会产生很多小的task 影响运行性能, 配置小了,就会导致task数目很少,单个task 拉取大量的数据,从而带来GC,spill磁盘,甚至OOM的问题,相信很多朋友都碰到过 executor lost, fetch failure等等错误,这里的本质问题是我们并不是很清楚真实的数据量到底有多大, 即使知道了,因为这个参数是全局的,我们一个application 里面不同的query 之间,甚至同一个query 同一个job 不同的stage 之间的shuffle read 的数据量并不是相同的,所以很难使用一个固定的值来统一。
现在 AQE 的实现了动态调整 shuffler partition number 的机制,在跑不同的query 不同的stage的时候,会根据 map 端 shuffle write 的实际数据量,来决定启动多少个 reducer 来处理,这样无论数据量怎么变换,都可以通过不同的 reducer 个数来均衡数据,从而保证单个 reducer 拉取的数据量不至于太大。
这里需要说明的是,AQE 并不是万能的,AQE 并不晓得 map 端需要对数据分出来多少份,所以实际使用的时候,可以把 spark.sql.shuffle.partitions 参数往大了设。
调整 Join 策略
在成本优化中,选择 join 的类型是比较重要的一块,因为在合适的时候选择 broadcast join,就直接避免了 shuffle, 会大大提升执行的效率,但是如果静态数据是错误的,对一个比较大的(统计数据看起来比较小)的 relation 进行了broadcast,就会直接把 driver 内存给搞爆。
AQE 中,会在运行时根据真实的数据来进行判断,如果有一个表小于 broadcast join 配置的阈值,就会把执行计划中的 shuffle join 动态修改为 broadcast join。
处理Join 过程中的数据倾斜
数据倾斜历来都是老大难的问题,数据倾斜,顾名思义,就是指数据中某些 key 的数据量特别大,然后按照 hash 分区的时候,某个分区的数据量就特别大,这种数据分布会导致性能严重下降,特别是在 sort merge join 的情况下,在 spark ui 上可以看到,某几个 task 拉取的数据量远远大于其他的task,运行时间也远远超过其他task,从而这个短板拖慢了整体的运行时间。因为某些task 拉取了大多数的数据量,就会导致 spill 到磁盘,这样的话,就会更慢,更严重的话,直接就把executor 的内存搞爆了。
因为我们很难事先知道数据的特征,所以在join 的时候数据倾斜就很难通过静态统计信息来避免了,即使加上 hint, 在AQE中,通过收集运行时统计信息,我们就可以动态探测出倾斜的分区,从而对倾斜的分区,分裂出来子分区,每个子分区对应一个 reducer, 从而缓解数据倾斜对性能的影响。
从Spark UI 上观察AQE的运行情况
Understand AQE Query Plans
AQE 的执行计划是在运行过程中动态变化的,在 spark 3.0 中,针对 AQE 引入了几个特定的执行计划节点,AQE 会在Spark UI 上同时显示出初始的计划,和最终优化过的计划,下面我们通过图示的方式来展示一下。
The AdaptiveSparkPlan Node
开启了 AQE,查询中会添加一个或者多个 AdaptiveSparkPlan 节点作为query 或者子查询的根节点,在执行前和执行过程中,isFinalPlan 会被标记为false, query 执行完成后,isFinalPlan 会变为true, 一旦被标记为 true 在 AdaptiveSparkPlan 节点下面的计划也就不再变动。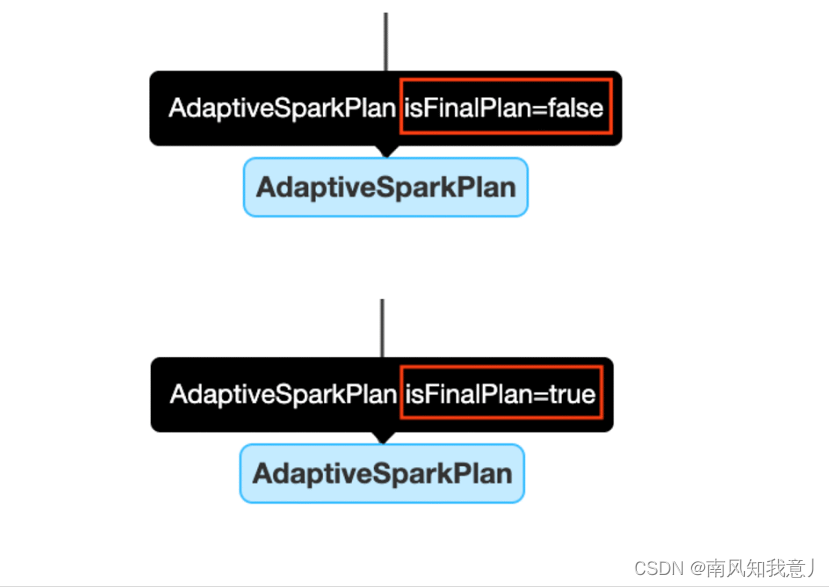
The CustomShuffleReader Node
CustomShuffleReader 是AQE优化中关键的一环,这个算子节点会根据上一个stage 运行后的真实统计数据,动态的调整后一个 stage 分区的数目,在 spark UI 上,鼠标放在上面,如果你看到 coalesced 标记的话,就说明AQE 已经探测出了大量的小分区,根据配置的比较合适的分区数据量,把他们合并在了一起,可以点开 details, 里面可以看到原始的分区数据,已经合并后的分区数目。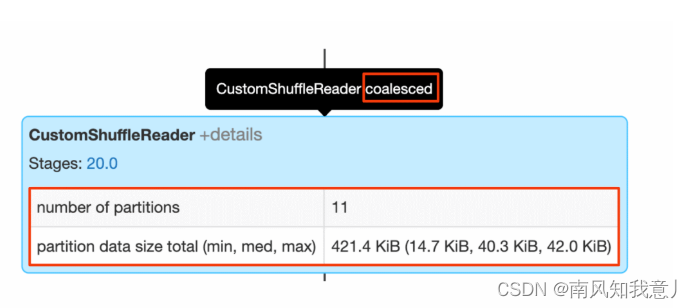
当出现 skewed 标记的时候,说明 AQE在 sort-merge 的计算过程中, 探测出了倾斜的分区,details 里面可以看到,有多少个倾斜的分区,已经从这些倾斜分区中分裂出的分区数目。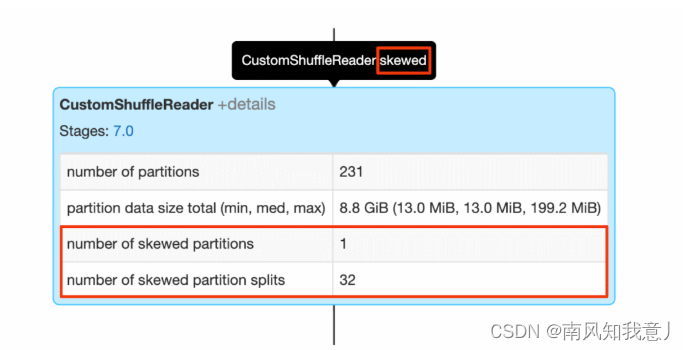
当然上面两种优化效果是可以叠加的:
Detecting Join Strategy Change
对比执行计划,可以看出来在AQE优化前后的执行计划的区别,执行计划中,会展示出来初始 执行计划,和 Final 执行计划,下面的例子中,可以看出,初始的 SortMergeJoin 被优化为了 BroadcastHashJoin。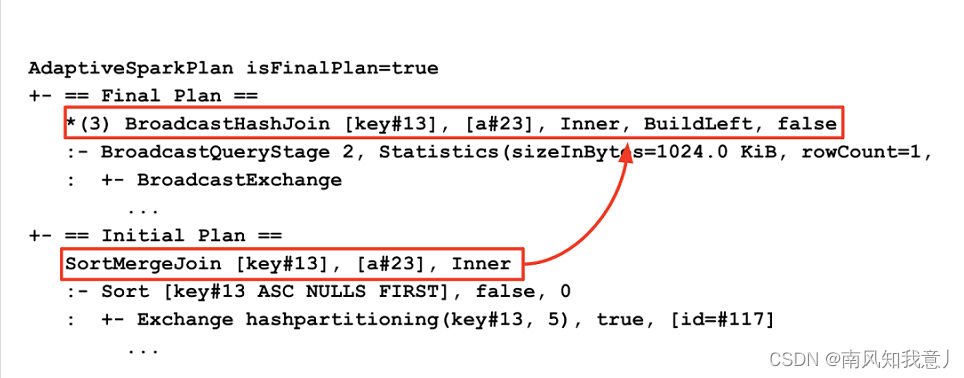
在 Spark UI 上面可以更加清楚的看到优化效果,当然spark ui 上只会展示当前的执行计划图,你可以在 query 开始的时候,和query 完成的时候,对比当时的执行计划图的区别。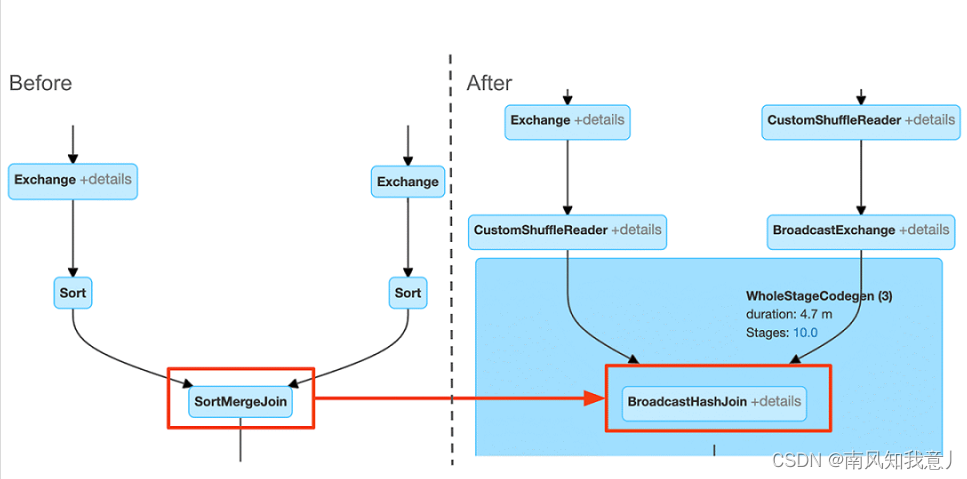
Detecting Skew Join
下面的图例中可以根据 skew=true 的标记来判断 引擎有没有执行数据倾斜优化: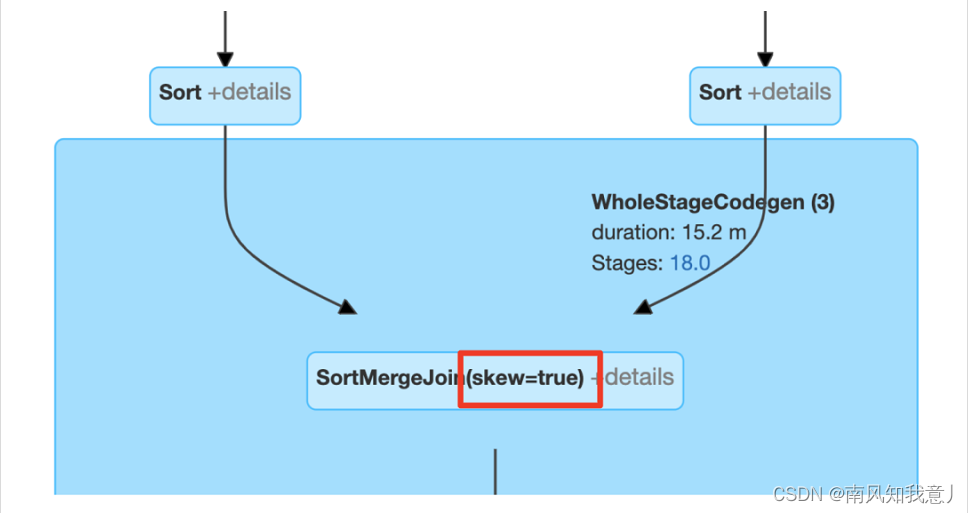
AQE 还是很强大的,因为依据的是真实数据的统计信息,AQE 可以很准确的选择最合适的 reducer 数目,转化join 策略,以及处理数据倾斜。
边栏推荐
- Recognize the small experiment of extracting and displaying Mel spectrum (observe the difference between different y_axis and x_axis)
- What is information security? What is included? What is the difference with network security?
- MySQL functions
- 硬件及接口学习总结
- Room cannot create an SQLite connection to verify the queries
- Power Query数据格式的转换、拆分合并提取、删除重复项、删除错误、转置与反转、透视和逆透视
- Configuring OSPF load sharing for Huawei devices
- Ffmpeg captures RTSP images for image analysis
- How to solve the problems caused by the import process of ecology9.0
- [binary search tree] add, delete, modify and query function code implementation
猜你喜欢
MySql——CRUD
Problems and solutions of converting date into specified string in date class
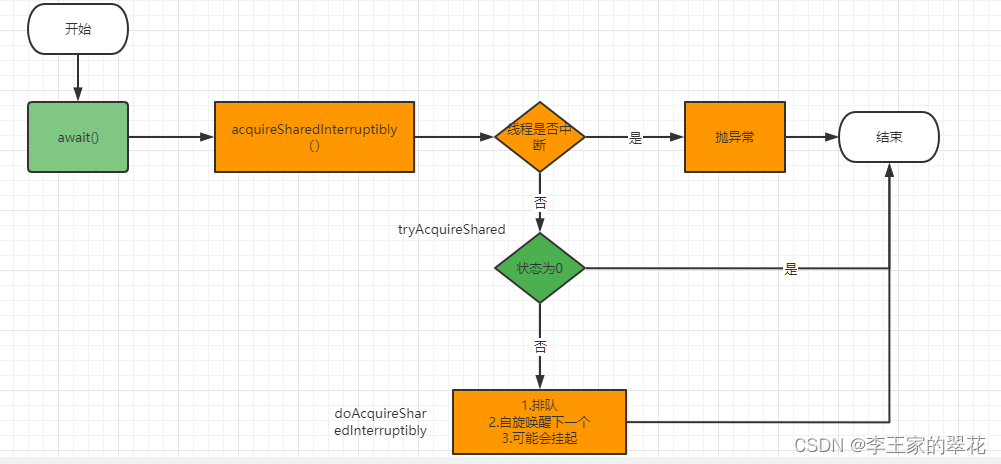
多线程与高并发(8)—— 从CountDownLatch总结AQS共享锁(三周年打卡)
notepad++正則錶達式替換字符串

2022-02-13 work record -- PHP parsing rich text
![Atcoder beginer contest 254 [VP record]](/img/13/656468eb76bb8b6ea3b6465a56031d.png)
Atcoder beginer contest 254 [VP record]
Configuring OSPF GR features for Huawei devices
Intranet Security Learning (V) -- domain horizontal: SPN & RDP & Cobalt strike
Data analysis thinking analysis methods and business knowledge -- analysis methods (II)
About the slmgr command
随机推荐
STM32 configuration after chip replacement and possible errors
LeetCode 斐波那契序列
Doppler effect (Doppler shift)
uniapp开发,打包成H5部署到服务器
Configuring OSPF GR features for Huawei devices
[EI conference sharing] the Third International Conference on intelligent manufacturing and automation frontier in 2022 (cfima 2022)
多线程与高并发(8)—— 从CountDownLatch总结AQS共享锁(三周年打卡)
Global and Chinese markets of POM plastic gears 2022-2028: Research Report on technology, participants, trends, market size and share
剖面测量之提取剖面数据
OS i/o devices and device controllers
【线上小工具】开发过程中会用到的线上小工具合集
Data analysis thinking analysis methods and business knowledge -- analysis methods (II)
FFT learning notes (I think it is detailed)
Atcoder beginer contest 254 [VP record]
Global and Chinese markets of universal milling machines 2022-2028: Research Report on technology, participants, trends, market size and share
Determinant learning notes (I)
Yunna | what are the main operating processes of the fixed assets management system
[designmode] composite mode
Intranet Security Learning (V) -- domain horizontal: SPN & RDP & Cobalt strike
MySQL functions