当前位置:网站首页>Station B Liu Erden softmx classifier and MNIST implementation -structure 9
Station B Liu Erden softmx classifier and MNIST implementation -structure 9
2022-07-06 05:42:00 【Ning Ranye】
Series articles :
List of articles
softmax classifier
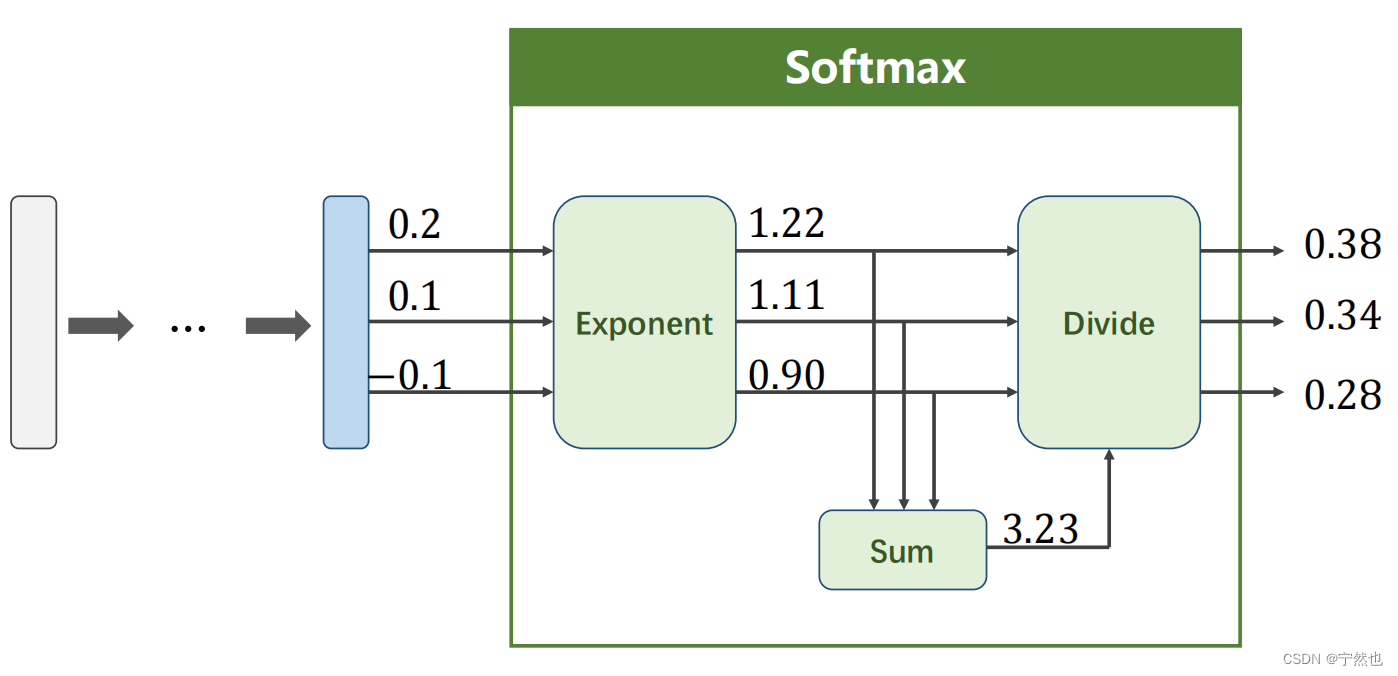
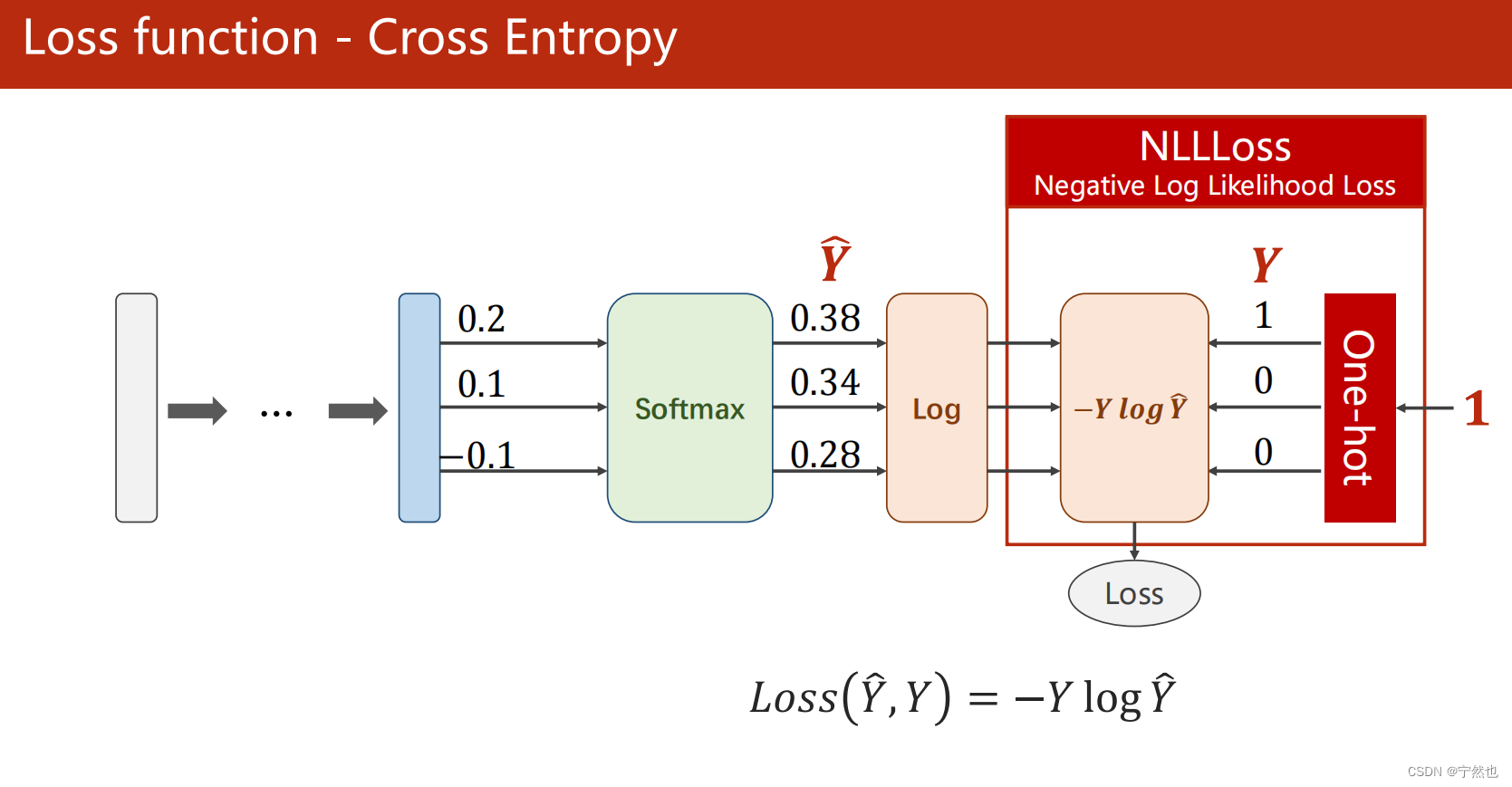
Loss function : Cross entropy
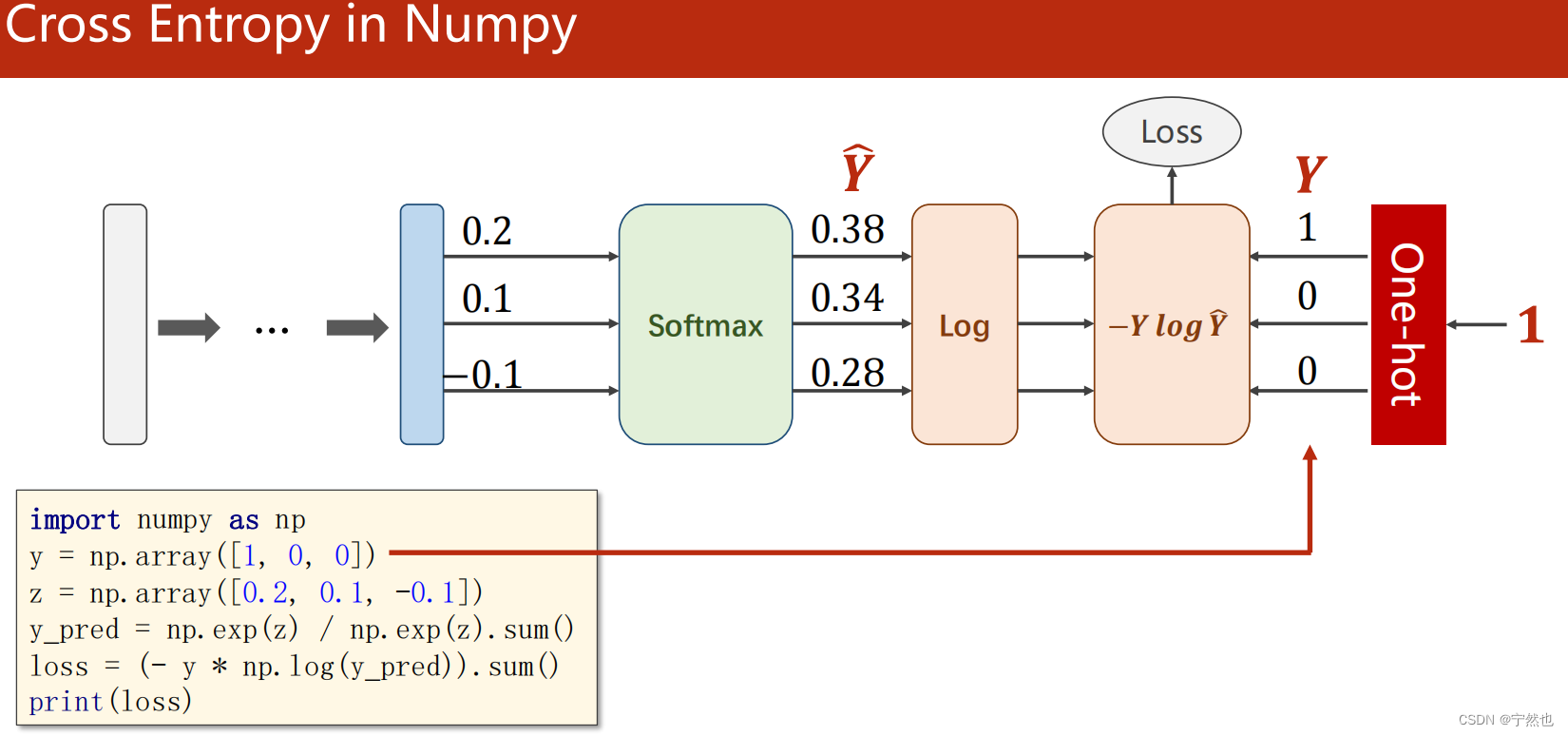
Numpty Realize the cross entropy loss function
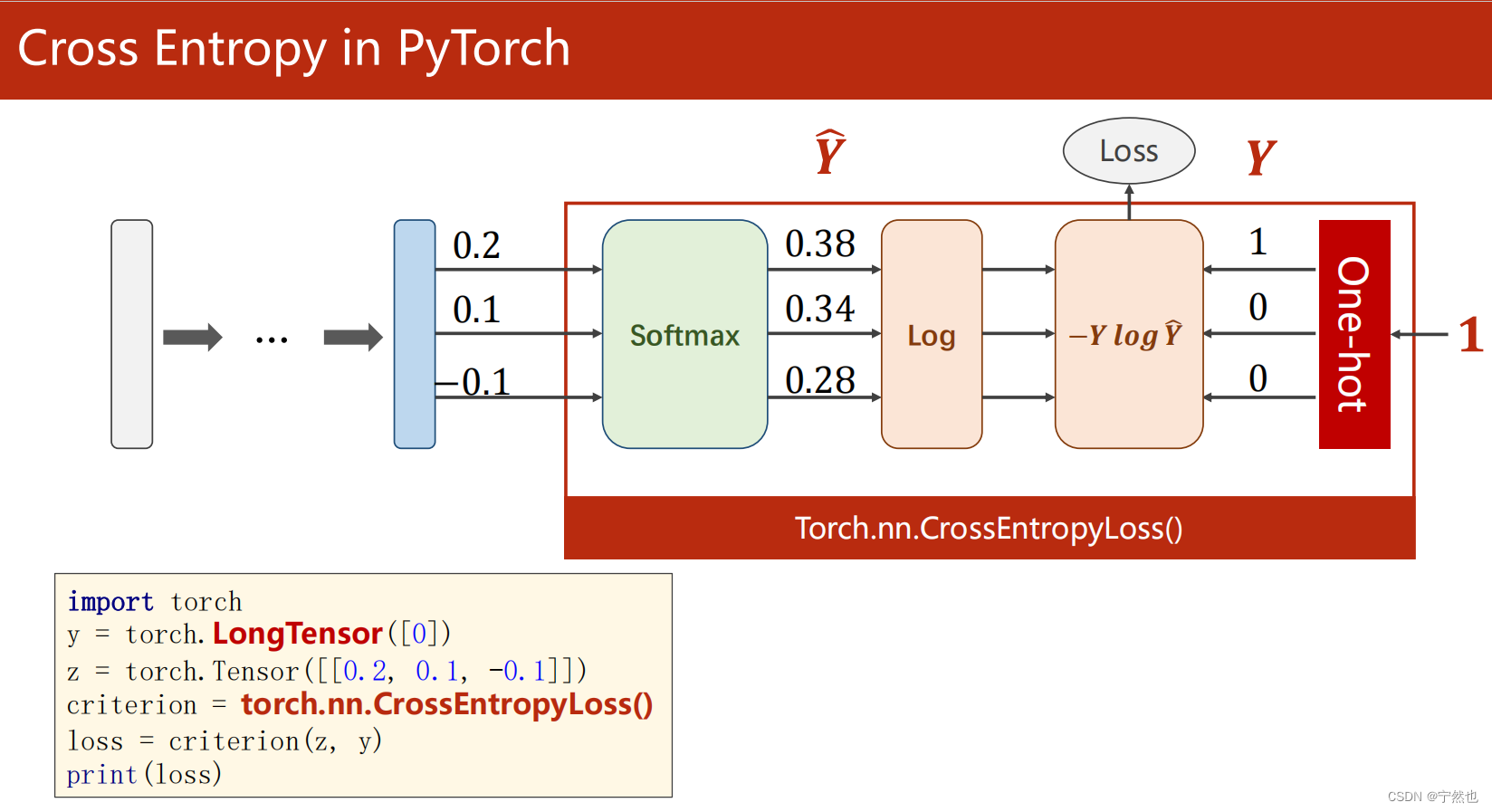
Pytorch Realized cross entropy loss 
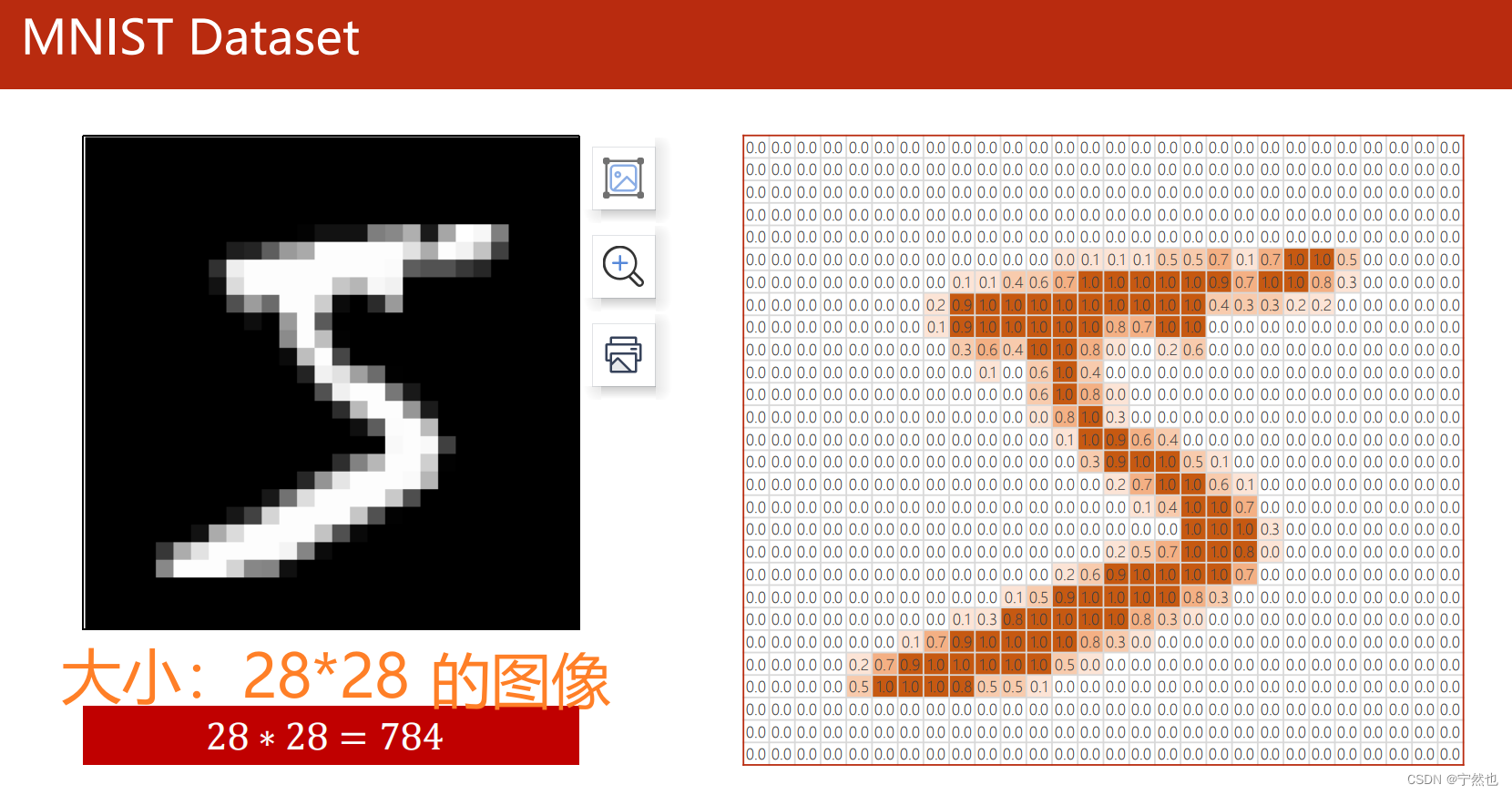
MNIST Realization



Guide pack
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# Use relu()
import torch.nn.functional as F
# Construct optimizer
import torch.optim as optim
1- Prepare the data
# 1- Prepare the data
batch_size = 64
# take PIL Image capture and change to Tensor
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist', train=True,
transform=transforms,
download=False)
test_dataset = datasets.MNIST(root='./datasets/mnist', train=False,
transform=transforms,
download=False)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size,
shuffle=False)
2- Design the network model
# 2- Design the network model
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.lay1 = torch.nn.Linear(784,512)
self.lay2 = torch.nn.Linear(512,256)
self.lay3 = torch.nn.Linear(256,128)
self.lay4 = torch.nn.Linear(128,64)
self.lay5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.lay1(x))
x = F.relu(self.lay2(x))
x = F.relu(self.lay3(x))
x = F.relu(self.lay4(x))
x = F.relu(self.lay5(x))
return x
3- Build a model 、 Loss function 、 Optimizer
# 3- Construct loss function and optimizer
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005,momentum=0.5)
4- Training 、 test
# 4- Training test
def train(epoch):
running_loss = 0.0
# enumerate(train_loader, 0): batch_idx from 0 Count
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(batch_idx % 300 == 299):
print('[%d, %5d] loss: %.3f'%(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
# The test does not need to generate a calculation diagram , No gradient update is required 、 Back propagation
with torch.no_grad():
# data yes len =2 Of list
# input yes data[0], target yes data[1]
for data in test_loader:
images, label = data
outputs = model(images)
# _ Is the maximum value returned , predicted Is the subscript corresponding to the maximum
_, predicted = torch.max(outputs.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accutacy on test set : %d %%'%(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
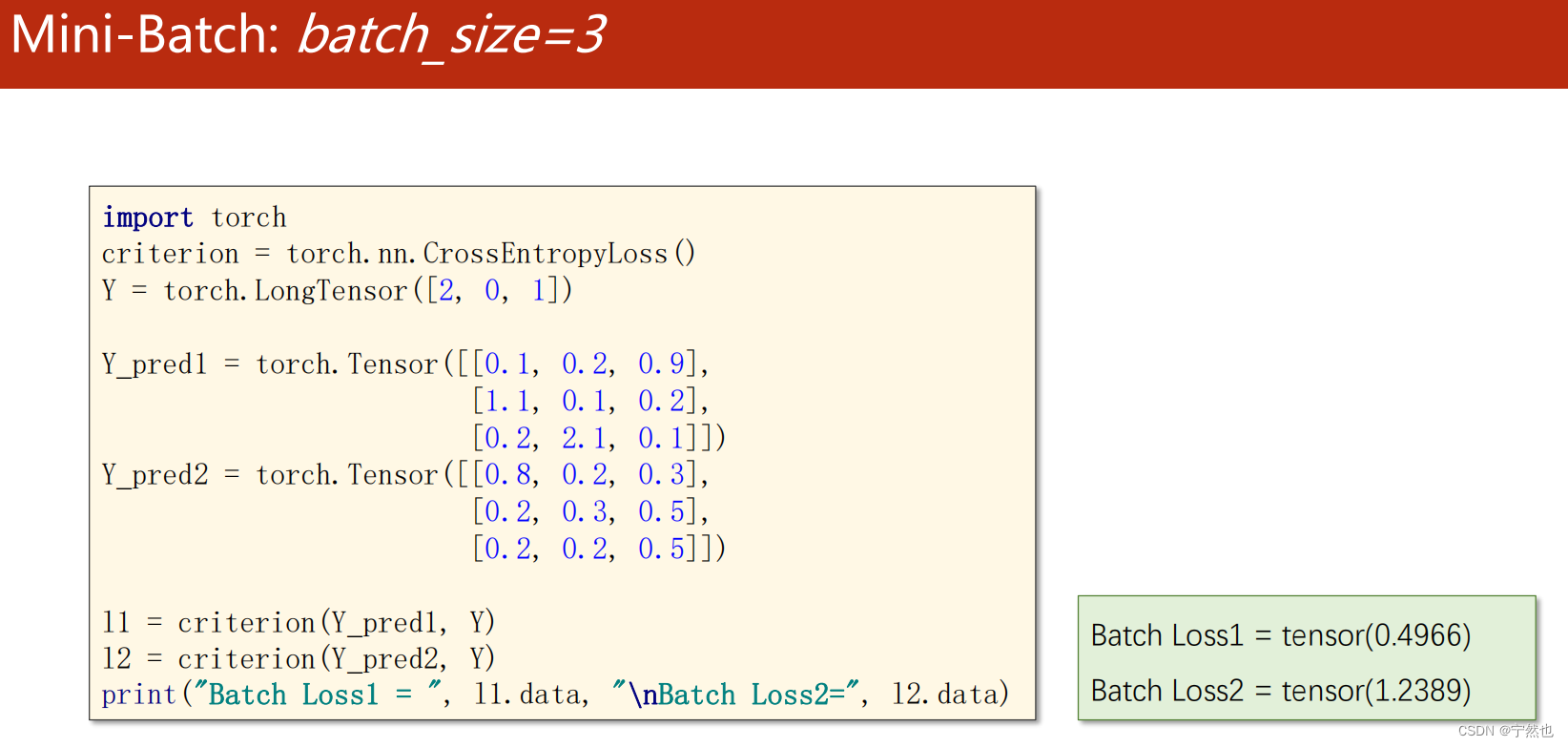
About :(predicted == label).sum()
Will predicted Each element in is associated with the corresponding position label Opposite edge , Same back True, Different back False. .sum Seeking True The number of 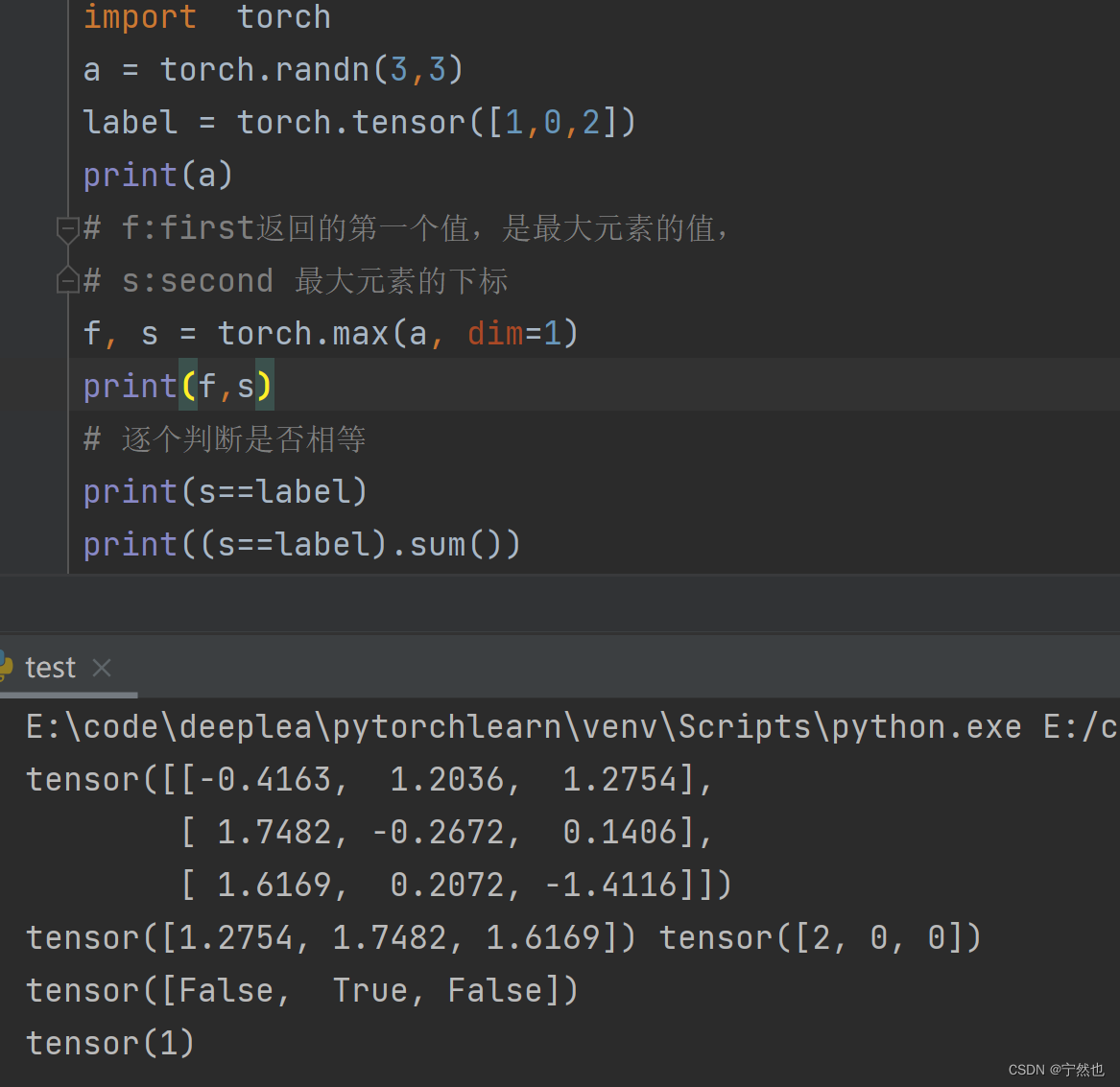
inputs, target = data Explain the assignment 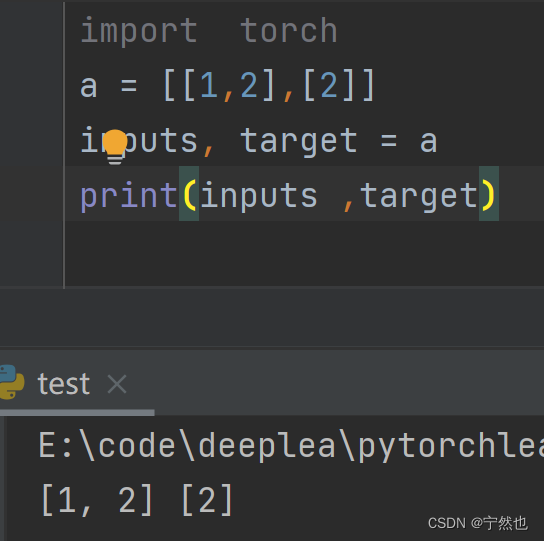
Complete code
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# Use relu()
import torch.nn.functional as F
# Construct optimizer
import torch.optim as optim
# 1- Prepare the data
batch_size = 64
# take PIL Image capture and change to Tensor
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist', train=True,
transform=transforms,
download=False)
test_dataset = datasets.MNIST(root='./datasets/mnist', train=False,
transform=transforms,
download=False)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size,
shuffle=False)
# 2- Design the network model
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.lay1 = torch.nn.Linear(784,512)
self.lay2 = torch.nn.Linear(512,256)
self.lay3 = torch.nn.Linear(256,128)
self.lay4 = torch.nn.Linear(128,64)
self.lay5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.lay1(x))
x = F.relu(self.lay2(x))
x = F.relu(self.lay3(x))
x = F.relu(self.lay4(x))
x = F.relu(self.lay5(x))
return x
# 3- Construct loss function and optimizer
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005,momentum=0.5)
# 4- Training test
def train(epoch):
running_loss = 0.0
# enumerate(train_loader, 0): batch_idx from 0 Count
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(batch_idx % 300 == 299):
print('[%d, %5d] loss: %.3f'%(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
# The test does not need to generate a calculation diagram , No gradient update is required 、 Back propagation
with torch.no_grad():
for data in test_loader:
images, label = data
outputs = model(images)
# _ Is the maximum value returned , predicted Is the subscript corresponding to the maximum
_, predicted = torch.max(outputs.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accutacy on test set : %d %%'%(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
边栏推荐
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- 28io stream, byte output stream writes multiple bytes
- Vulhub vulnerability recurrence 69_ Tiki Wiki
- 无代码六月大事件|2022无代码探索者大会即将召开;AI增强型无代码工具推出...
- How to download GB files from Google cloud hard disk
- Qt TCP 分包粘包的解决方法
- Vulhub vulnerability recurrence 72_ uWSGI
- What preparations should be made for website server migration?
- PDK工藝庫安裝-CSMC
- PDK工艺库安装-CSMC
猜你喜欢
Check the useful photo lossless magnification software on Apple computer
![[cloud native] 3.1 kubernetes platform installation kubespher](/img/86/137a65a5b58bc32e596d2a330ca9fc.png)
[cloud native] 3.1 kubernetes platform installation kubespher
Migrate Infones to stm32
Deep learning -yolov5 introduction to actual combat click data set training
Redis消息队列
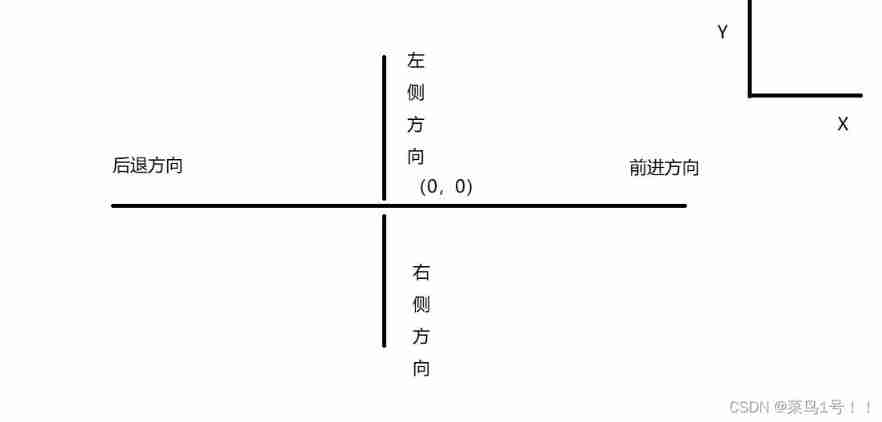
Analysis of grammar elements in turtle Library
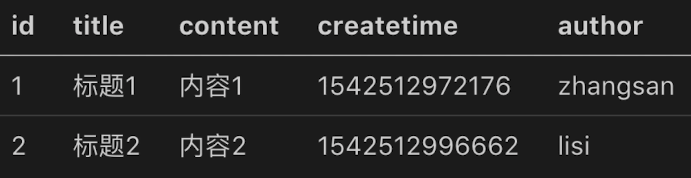
02. Develop data storage of blog project

The digital economy has broken through the waves. Is Ltd a Web3.0 website with independent rights and interests?
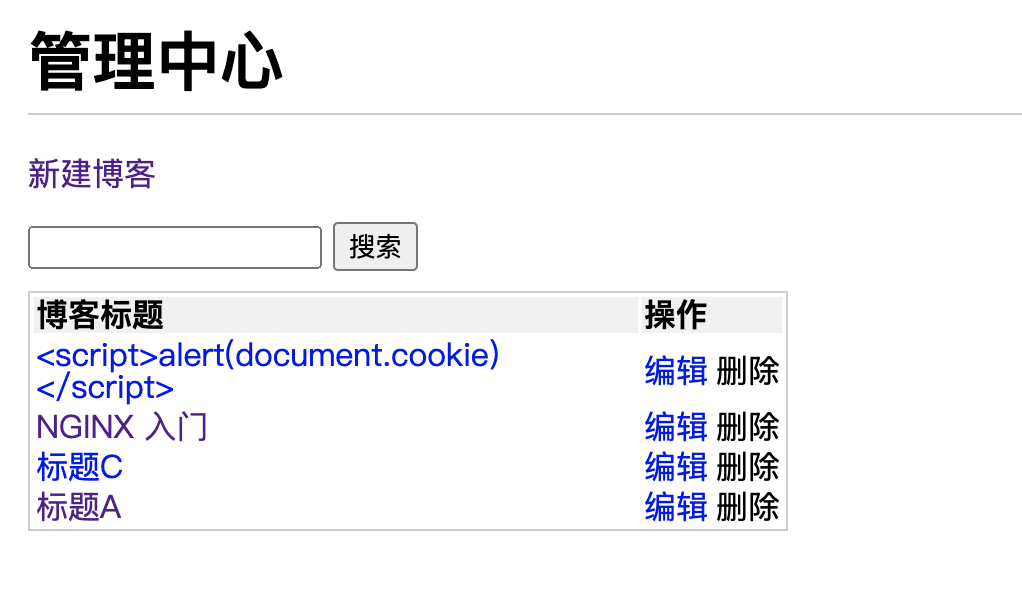
05. 博客项目之安全
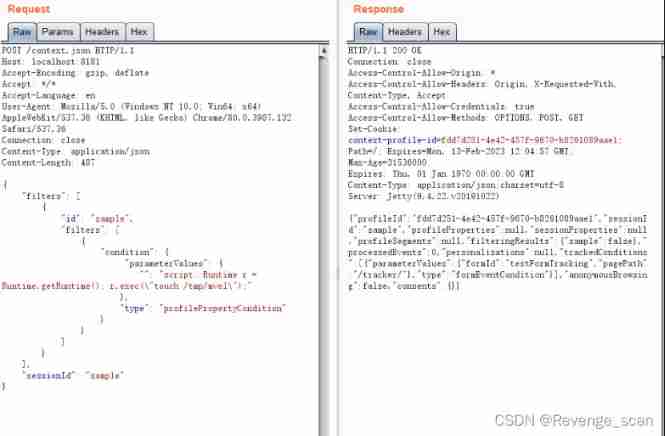
Vulhub vulnerability recurrence 71_ Unomi
随机推荐
Easy to understand IIC protocol explanation
UCF(2022暑期团队赛一)
Pointer classic written test questions
清除浮动的方式
Remember an error in MySQL: the user specified as a definer ('mysql.infoschema '@' localhost ') does not exist
Safe mode on Windows
Unity gets the width and height of Sprite
Algorithm -- climbing stairs (kotlin)
01. Project introduction of blog development project
[JVM] [Chapter 17] [garbage collector]
jdbc使用call调用存储过程报错
How to use PHP string query function
2022 half year summary
Jvxetable用slot植入j-popup
【torch】|torch. nn. utils. clip_ grad_ norm_
通讯录管理系统链表实现
What impact will frequent job hopping have on your career?
Vulhub vulnerability recurrence 68_ ThinkPHP
Sword finger offer II 039 Maximum rectangular area of histogram
Deep learning -yolov5 introduction to actual combat click data set training