当前位置:网站首页>ICML 2022 | 探索语言模型的最佳架构和训练方法
ICML 2022 | 探索语言模型的最佳架构和训练方法
2022-07-07 01:44:00 【PaperWeekly】

作者 | 朱耀明
单位 | 字节跳动人工智能实验室
研究方向 | 机器翻译
本文介绍两篇发表于 ICML 2022 的论文,研究者都主要来自于 Google。两篇论文都是很实践性的分析论文。和常见的论文在模型做创新不一样,两篇论文都是针对现有 NLP 语言模型的架构和训练方法、探索其在不同场景下的优劣并总结出经验规律。
在这里笔者优先整理一下两篇论文的主要实验结论:
1. 第一篇论文发现了虽然 encoder-decoder 占据了机器翻译的绝对主流,但在模型参数量较大时,合理地设计语言模型 LM 可以使其与传统的 encoder-decoder 架构做机器翻译任务的性能不相上下;且 LM 在 zero-shot 场景下、在小语种机器翻译上性能更好、在大语种机器翻译上也具有 off-target 更少的优点。
2. 第二篇论文发现在不做 finetuning 的情况下,Causal decoder LM 架构+full language modeling 训练在 zero-shot 任务上表现最好;而在有多任务 prompt finetuning 时,则是 encoder-decoder 架构+masked language modeling 训练有最好的 zero-shot 性能。

论文一
第一篇主要探索语言模型在机器翻译任务上传统语言模型(language model)能有多好的表现,是否可以与主流的 encoder-decoder 匹敌。

论文标题:
Examining Scaling and Transfer of Language Model Architectures for Machine Translation
论文链接:
https://arxiv.org/abs/2202.00528
收录会议:
ICML 2022
作者机构:
爱丁堡大学、Google
1.1 引言
作者认为目前 encoder-decoder 架构在机器翻译界占据了绝对的主流,然而大家对更纯粹的语言模型(Language Model)在机器翻译上的研究不多,也很少分析它的性能与优劣。作者探索了多种用于机器翻译的语言模型配置,并做了一个系统性的性能分析。
1.2 方法简介
作者用于机器翻译的 LM 见下图,X 和 Y 分别表示源语言输入和目标语言输入,两者做拼接输入 LM。为了防止翻译时信息泄露,作者将 LM 的原始的注意力掩码调整为 prefix-LM 掩码或 casual-LM 掩码,其中黑色部分为掩码 mask(左上角)。右下角为和主流 encoder-decoder 的掩码对比。
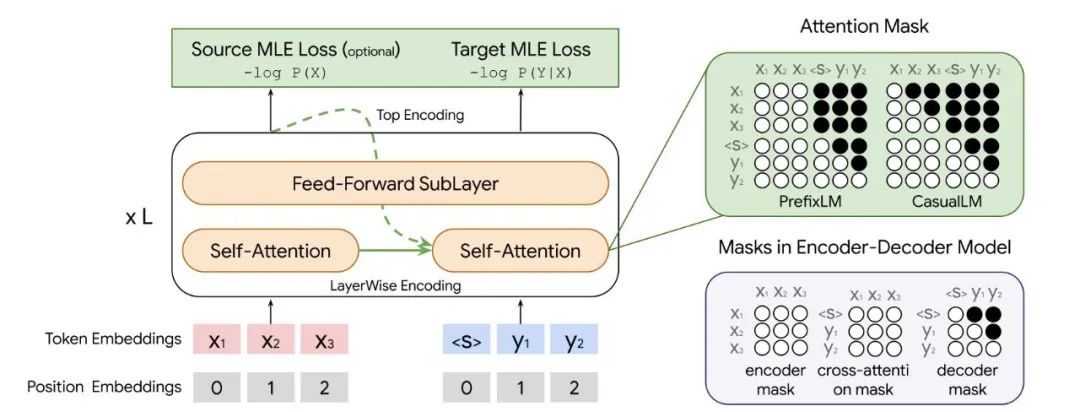
▲ 作者用于翻译的LM。主要做法是源语言+目标语言做拼接,并在Attention上做mask掩码防止信息泄露。
除了两种掩码机制外,作者在还比较了 TopOnly 和 layer-wise [1] 两种表征,其中前者是最常见的只使用神经网络顶层表征来作为输出层的输入,而后者则会对每一层的表征做协调学习 [1]。
作者还比较了 TrgOnly 形式的 LM,这种 LM 的损失函数只建模目标端语种的生成,而不建模源端语言生成。
1.3 实验探索
作者的基线模型使用了类似 Transformer-base 的架构,在 WMT14 英法、英德,WMT19 英中,以及自有英德数据集上做了主实验。作者也探索了加大参数量对 LM 在机器翻译上的影响。
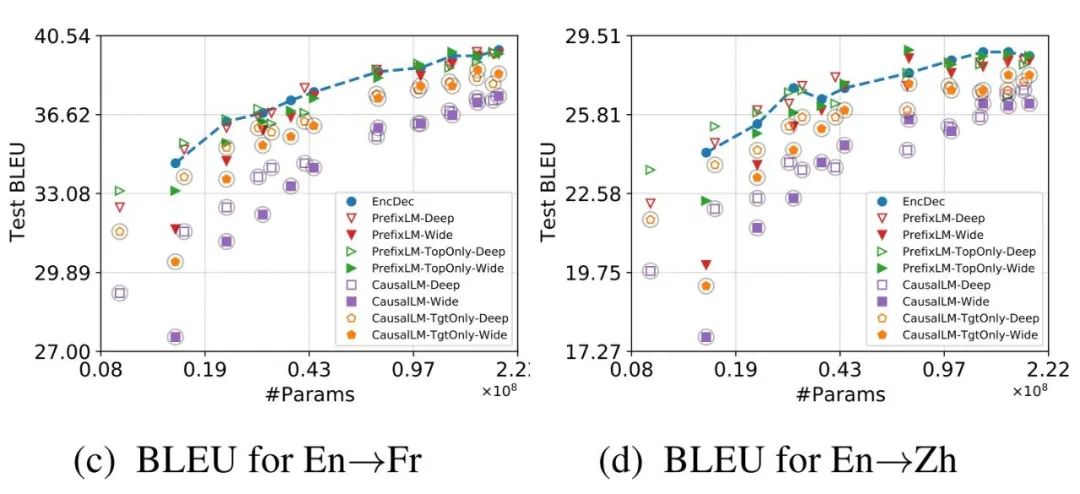
▲ 这里列出本文最重要的实验图:在两个数据集上,各种LM变体以及encoder-decoder的BLEU分数-参数量曲线图。
下面列出作者的主要结论:
1. 在模型参数量较小时,架构对性能的影响最大。此时,具有 inductive biases 的模型翻译质量最好。作者所言的 inductive biases 主要有四类:1)类似 prefix-LM 掩码这种源语言端信息完全可见的;2)使用 TopOnly 做输出层表征而不是用 layer-wise;3)优先使用 Deep LM 而不是 Wide LM;4)Loss 指建模目标端语言生成,而不建模源端语言生成。
2. 不同的模型显示出不同的参数量特性,但这种差距在都使用大规模参数时缩小了。
3. 句子序列长度对LM参数量特征的影响较小。
4. Encoder-decoder 架构在计算效率上(以 FLOPs 衡量)优于所有的 LM 架构(这也侧面说明了为啥前者是机器翻译界的绝对主流)。
作者还在 zero-shot 场景测试了 LM 在机器翻译上的性能,作者发现:
1. PrefixLM 掩码在 zero-shot 场景有较好的表现。CausalLM 掩码不适合 zero-shot 场景。
2. 在低资源语种上,LM 的机器翻译语种迁移性能优于 encoder-decoder 架构。
3. 在大语种翻译的表现上,LM 和 decoder-encoder 架构各有千秋。总体来讲,LM 有更好的 zero-shot 表现,翻译时 off-target(即翻错语种)情况更少。

论文二
第二篇则探索大规模预训练 LM 在 Zero-shot 场景的性能,并讨论用什么架构、什么预训练目标最有效。
论文标题:
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
论文链接:
https://arxiv.org/abs/2204.05832
代码链接:
https://github.com/bigscience-workshop/architecture-objective
收录会议:
ICML 2022
作者机构:
Google Brain, HuggingFace, LightOn, Allen NLP, LPENS
2.1 研究目的
作者对比了三种架构 (causal decoder-only, non-causal decoder-only, encoder-decoder)、两种预训练目标 (autoregressive、masked language modeling) 训练出来的语言模型在 zero-shot 在 zero-shot NLP 任务上的性能。作者还按照有无 multitask prompted finetuning 步骤把测试也分为了两种场景。
2.2 方法简介
这篇论文的研究方法非常简单,就是把 causal decoder LM, non-causal decoder LM, encoder-decoder 三种基本架构和 full language modeling(即最普通的 LM 训练),masked language modeling(即带 mask 机制的 LM 训练)两种训练方法做排列组合测试性能。
同时,在评测阶段,除了直接测试 zero-shot 性能外,作者还额外测试了加入 multitask prompted finetuning 后,各个模型+训练方式在新任务上的性能。多任务 tune 可以参考这篇论文 (T0) [2]。
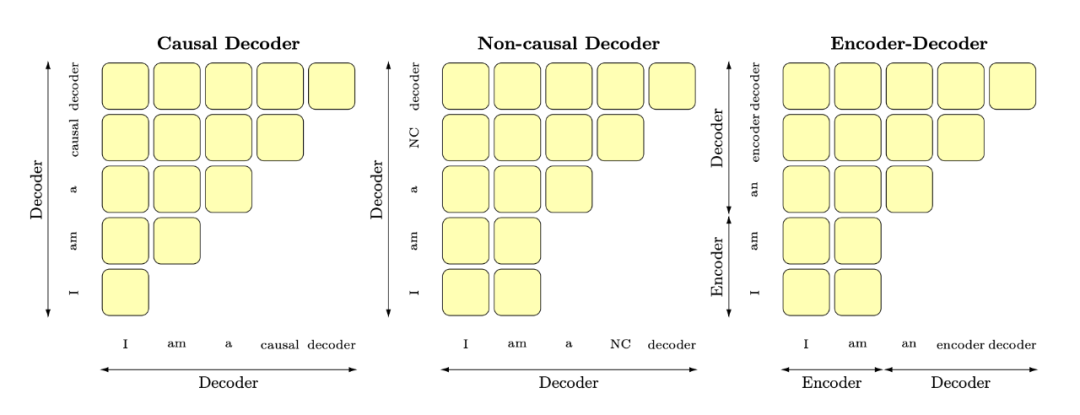
▲ 作者三种基本架构的注意力机制图 (attention map)。简言之,causal decoder LM只允许source sentence中每个token对前面token做attention,后两者是双向attention的。
2.3 实验探索
作者的评测任务也是参考了 T0 论文 [2] 和 EleutherAI LM Evaluation Harness [3]。(笔者注:这两个 benchmark 一共给类似 T5 和 GPT-3 这样的大语言模型提供了数百种评测任务)。
评测任务非常多,这里仅说一下作者的结论:
1. 在不做 finetuning 的情况下,Causal decoder LM 架构+full language modeling 训练可以让模型具有最好的 zero-shot 泛化性能。这个结论也和目前 GPT-3 这类模型在 zero-shot NLG 上的惊艳表现一致。
2. 在有 multitask finetuning 的情况下,encoder-decoder 架构+masked language modeling 训练则是具有最好的 zero-shot 泛化性能。作者还发现在单个任务 finetune 表现好的架构往往在 multitask 场景下泛化行也好。
3. 仅使用 decoder 的 LM 在做 adaptation 或者 task transfer 时,比 encoder-decoder 需要的开销更小、即更容易任务迁移。

笔者简评
两篇论文都是实践性质的 emprical study。综合来讲,笔者认为前一篇的启发更大一点,作者说明了模型够大时,仅有 decorder 结构的 LM 也能很好地完成机器翻译任务。此外在 zero-shot 的机器翻译上,LM 表现非常出彩——考虑已经有大量工作证明了 LM 本身就有极高的泛化性,也许 LM 有成为极低资源语种或者小众语种翻译(譬如文言文翻译)主流模型的潜力。总之,LM 在机器翻译领域的上限还待诸君挖掘。
而后一篇则是 Google 大力出奇迹的典型,行文基调更偏向于“即插即用”,可以作为相关的研究者或者工程师按需挑选模型的指导手册。其实也有点好奇 Google 为什么选择在 ICML’22 上发表这篇论文,笔者愚见这篇论文似乎更契合 TACL 或 JAIR 一类的期刊。

参考文献
[1] https://proceedings.neurips.cc/paper/2018/hash/4fb8a7a22a82c80f2c26fe6c1e0dcbb3-Abstract.html
[2] https://arxiv.org/abs/2110.08207
[3] https://github.com/EleutherAI/lm-evaluation-harness
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

边栏推荐
- [InstallShield] Introduction
- Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
- CMD permanently delete specified folders and files
- 你不知道的互联网公司招聘黑话大全
- 对称的二叉树【树的遍历】
- 360织语发布7.0新品 为党政军、央国企打造专属“统一数字工作空间”
- Jinfo of JVM command: view and modify JVM configuration parameters in real time
- Chain storage of stack
- 进程间通信之共享内存
- CloudCompare-点对选取
猜你喜欢

When we talk about immutable infrastructure, what are we talking about
【FPGA教程案例13】基于vivado核的CIC滤波器设计与实现

Jstack of JVM command: print thread snapshots in JVM
window下面如何安装swoole

雷特智能家居龙海祁:从专业调光到全宅智能,20年专注成就专业
【GNN】图解GNN: A gentle introduction(含视频)
![[FPGA tutorial case 14] design and implementation of FIR filter based on vivado core](/img/fc/5162bbb0746f8af2d6c7d63ade571a.png)
[FPGA tutorial case 14] design and implementation of FIR filter based on vivado core
关于STC单片机“假死”状态的判别

Developers don't miss it! Oar hacker marathon phase III chain oar track registration opens
Financial risk control practice - decision tree rule mining template
随机推荐
693. 行程排序
一段程序让你明白什么静态内部类,局部内部类,匿名内部类
From "running distractor" to data platform, Master Lu started the road of evolution
C. colonne Swapping [tri + Simulation]
C language sorting (to be updated)
K8s running Oracle
Personal imitation SSM framework
JVM 全面深入
Implementation of VGA protocol based on FPGA
骑士战胜魔王(背包&dp)
c面试 加密程序:由键盘输入明文,通过加密程序转换成密文并输出到屏幕上。
Chain storage of stack
Financial risk control practice - decision tree rule mining template
JVM command - jmap: export memory image file & memory usage
可极大提升编程思想与能力的书有哪些?
安装mongodb数据库
为不同类型设备构建应用的三大更新 | 2022 I/O 重点回顾
力扣62 不同路径(从矩阵左上到右下的所有路径数量) (动态规划)
Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
「解析」FocalLoss 解决数据不平衡问题