当前位置:网站首页>【全网首发】Redis系列3:高可用之主从架构的
【全网首发】Redis系列3:高可用之主从架构的
2022-07-06 15:36:00 【HeapDump性能社区】
1 、主从复制介绍
上一篇《Redis系列2:数据持久化提高可用性》中,我们介绍了Redis中的数据持久化技术,包括 RDB快照 和 AOF日志 。有了这两个利器,我们再也不用担心机器宕机,数据丢失了。
但是持久化技术只是解决了Redis服务故障之后,快速数据恢复的问题。并没有从根本上提升Redis的可用性,我们需要的是保障Redis的高可用,减少甚至避免Redis服务发生宕机的可能。
目前实现Redis高可用的模式主要有三种: 主从模式、哨兵模式、集群模式。这些我们后面会分成三篇介绍,今天我们先来聊一下主从模式。
Redis 提供的主从模式,是通过复制的方式,将主服务器上的Redis的数据同步复制一份到从 Redis 服务器,这种做法很常见,MySQL的主从也是这么做的。
主节点的Redis我们称之为master,从节点的Redis我们称之为slave,主从复制为单向复制,只能由主到从,不能由从到主。可以有多个从节点,比如1主3从甚至n从,从节点的多少根据实际的业务需求来判断。
2、主从数据一致性保证
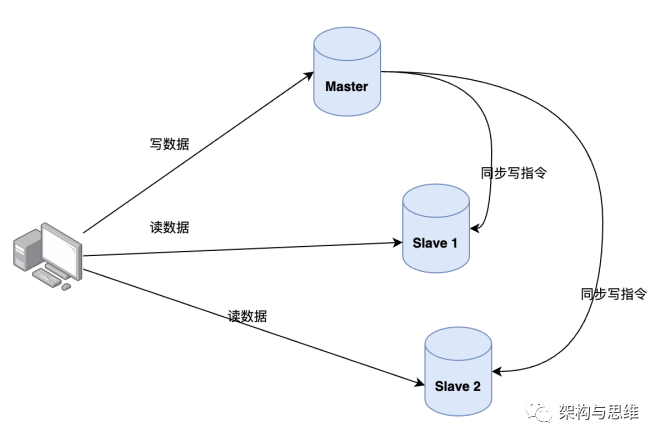
为了保证主服务器Redis的数据和从服务器Redis的数据的一致性,也为了分担访问压力,均衡负载,应用层面一般采取读写分离的模式。
- 读操作:主、从库都可以执行,一般是在从库上读数据,对实时性和准确性有100%高真要求的部分业务,可以谨慎评估之后读主库;
- 写操作:只在主库上写数据,写完之后将写操作指令同步到从库。
如下图:
2.1 为何采用读写分离模式?
读写分离模式的使用跟MySQL做读写分离的初衷是一样的。因为我们已经划分了主从库,而且从库的数据是由主库单向复制的。如果主从库都可以执行写指令,那么在高频并发场景下对不同的副本数据做修改,操作会具有无序性,极易导致各副本产生数据不一致,这是分布式模式的弊病。 如果非要保证数据的强一致性,Redis 需要加锁处理,或者使用队列顺序执行,这样势必降低Redis的性能,降低服务的吞吐能力,这就不是高性能Redis所能接受的。
2.2 主从复制还有其他作用么?
故障隔离和恢复:无论主节点或者从节点宕机,其他节点依然可以保证服务的正常运行,并可以手动切换主从。
读写隔离:Master 节点提供写服务,Slave 节点提供读服务,分摊流量压力,均衡流量的负载。
提供高可用保障:主从模式是高可用的最基础版本,也是哨兵模式和 cluster模式实施的前置条件。
3、搭建主从复制
主从复制的开启,完全是在从节点配置和发起的,不需要我们在主节点做任何事情。
可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系。在从节点开启主从复制,有 3 种方式:
说明:masterip:主机IP,masterport:主机端口号
3.1 配置文件方式
在从服务器的配置文件中加入
replicaof <masterip> <masterport>3.2 启动命令方式
redis-server 启动命令后面加入
--replicaof <masterip> <masterport>3.3 通过在客户端使用命令
启动多个 Redis 实例后,直接通过客户端执行命令:
replicaof <masterip> <masterport>则该 Redis 实例成为从节点。
假设现在有主实例 (192.168.0.1:6379)、从实例 A(192.168.0.2:6380)和 从实例 B (192.168.0.3:6381),在从实例上分别执行以下命令,就成为了Slave,主实例成为 Master。
redis 5.0之前slaveof 192.168.0.1 6379# redis 5.0之后replicaof 192.168.0.1 6379
4、主从复制原理
主从库模式开启之后,应用层面采用读写分离,所有数据的写操作只会在主库上进行,而读操作基本会在从库上面进行(特殊情况下部分读业务允许走主库)。
主从会保持最终一致性:主库有了数据更新之后,会立即同步给从库,来保证主从库的数据的一致的。
4.1 主从库的同步步骤
那主从库同步是如何完成的呢?一次性传输么,那样数据会不会太大?分批传递么,那样时效性会不会有问题?故障时候数据会不会丢失?重新连接之后中间产生的差额数据怎么补充才能保证一致性?带着这些疑问我们继续来分析下。
综合上面的问题来看同步,会有三种重要场景:
首次配置完成主从库之后的全量复制
主从正常运行期间,准实时同步
主从库间网络断开重连,Append增量数据 + 准实时同步
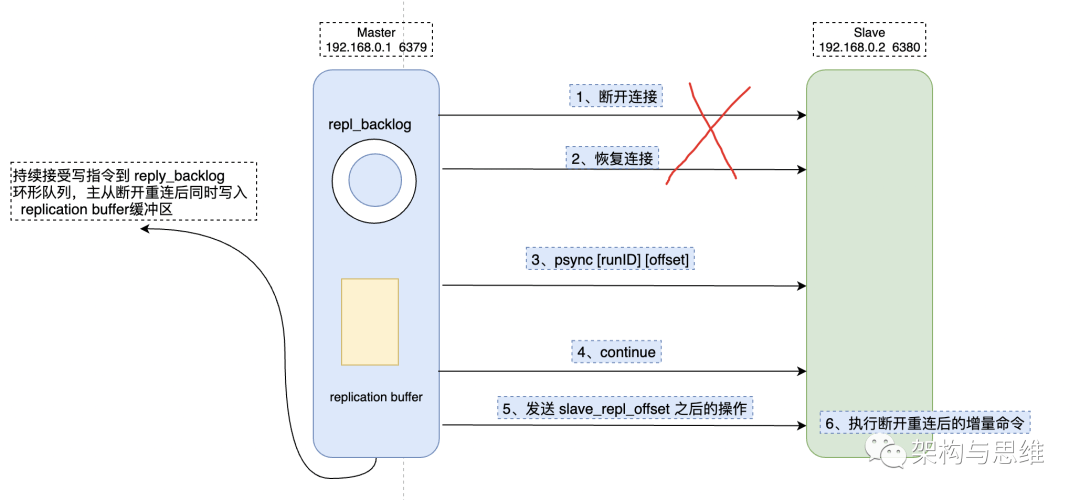
4.1.1 主从库第一次全量复制
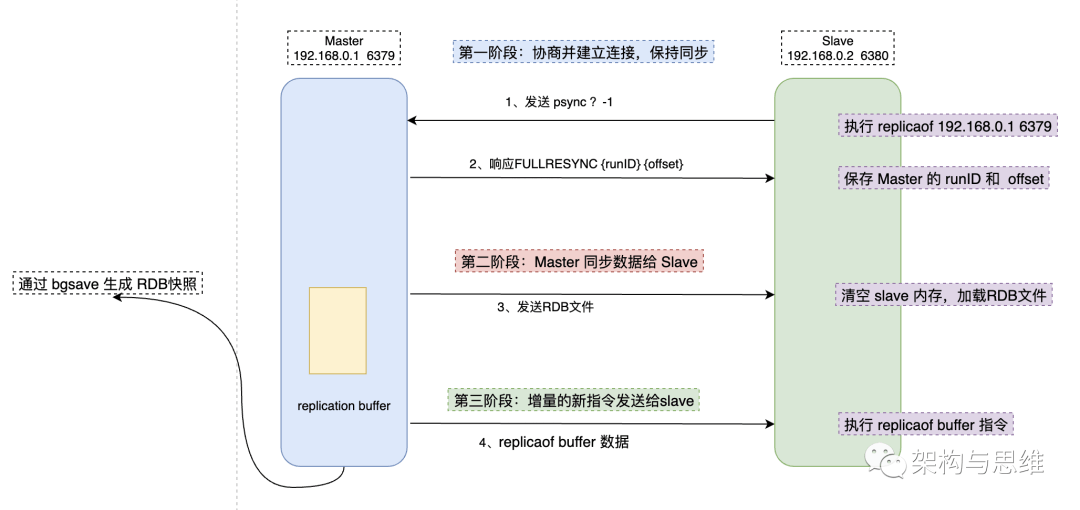
主从库第一次复制过程大体可以分为 3 个阶段:准备阶段(即建立连接准备)、主库同步数据到从库阶段、发送同步期间增量指令到从库的阶段。
我们来看这张完整的流转图,从整体上有个认识。
4.1.1.1 建立连接
这个阶段的主要作用是建立主从之间的连接,连接成立之后,才能够做数据全量同步。主要包含如下步骤:
从节点的配置文件中的 replicaof 配置项中配置了主节点的 IP 和 port ,配置完成之后,从节点就知道要跟哪个主节点进行连接。
当连接成功之后,从库开启replicaof 操作,同时发送psync指令告诉主库,我准备开始同步了。命令包含了主库的 runID 和 复制进度 offset 两个参数。
- runID:每个 Redis 实例启动都会自动生成一个 唯一标识 ID,第一次主从复制,还不知道主库 runID,所以参数会默认设置为:?。
- offset:因为第一次复制,没有偏移量,所以默认设置为 -1,这样就默认从第1条指令开始复制。
主库收到 psync 命令后根据参数启动复制,使用 FULLRESYNC 响应命令,同时带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。
从库收到响应后,记录下这两个参数。
4.1.1.2 主库同步数据给从库
第二阶段
master 执行 bgsave命令生成 RDB 文件,并将文件发送给从库,从库收到 RDB 文件后保存到磁盘,清空当前Redis库中的数据,再将 RDB 文件数据加载到内存中。
同时主库为每一个 slave 开辟一块 replication buffer 缓冲区记录,用于记录主库生成 RDB 文件后那段时间(那段时间的产生的写命令没有被记录到RDB文件中,但是主库又会源源不断的接收到新的请求指令,记录缓冲区是为了保证数据不丢失)产生的所有写指令。
4.1.1.3 发送新写命令到从库
第三阶段
从第二阶段我们可以知道,生成 RDB 文件之后,后续的操作指令并没有被记录,为了保证Redis主从库数据的一致性,主库会在内存中创建 replication buffer ,记录 RDB 文件生成后的所有操作指令。
而从库在接收完RDB主数据,先清空当前从库数据,然后完成数据初始化。整个初始化工作完成之后,继续执行从replication buffer 缓冲区发送过来的数据,避免数据断层。
* 主数据同步到从库的过程中,主库不会被阻塞,可以正常处理其他任意操作,这也是Redis保证高性能的必备条件。
replication buffer 缓冲区创建在 master 主库上,存放的数据是下面三个时间内 master 数据的所有写操作。
master 执行 bgsave 生产 rdb 的期间的写操作;
master 传输 rdb 文件到 slave 期间的写操作;
slave 加载 rdb 文件将数据初始化到内存期间的写操作。
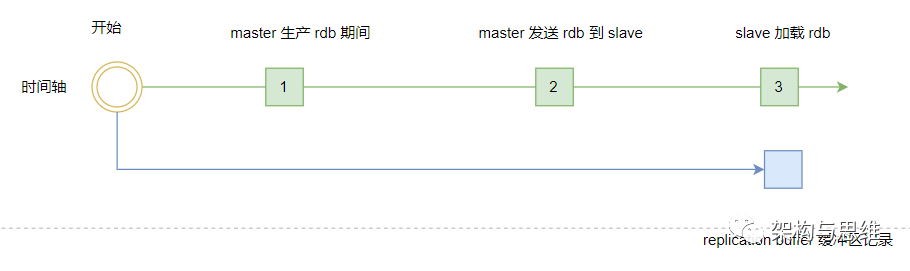
三个步骤完成了Redis主从的全量复制。这边需要注意的是,Redis中的通信,无论是主库跟从库之间,还是与客户端之间的数据交互。本质上都是通过分配内存buffer来进行的,Master 会先把数据写到 buffer 中,再通过网络发送出去,从而完成数据交互。
RDB 文件作为二进制文件,无论是网络传输还是写入时的磁盘IO,效率都要比 AOF 高很多。同样的,从库进行数据恢复的时候,效率也会高一些。所以我们会选择RDB文件做同步而不是AOF模式。
4.1.2 增量复制
4.1.2.1 主从网络断开之后的同步方式
高版本的Redis,在网络断开之后或者从实例服务故障恢复之后,主从库会采用增量复制的方式继续同步,而不是全量同步的模式,这样会大大降低开销,提升效率。
增量复制: 就是指网络中断或者从库重启等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。
repl_backlog_buffer
主从库重新连接之后可以实现增量复制。关键就在 repl_backlog_buffer 缓冲区 上面。
因为 master 会将写指令操作记录在 repl_backlog_buffer 缓冲区中,并使用 master_repl_offset 记录master写入的位置偏移量,slave 则使用 slave_repl_offset 记录读的偏移量。master 新增写操作的时候,偏移量则会增加。从库持续执行同步的写指令后,slave_repl_offset 也会不断增加。一般情况下,这两个偏移量会保持同步,如下图左。
但是网络断开或者从库故障期间,主实例Redis一般会收到新的写操作命令,但从实例则暂停执行,所以 master_repl_offset 会大于 slave_repl_offset。如下图右。
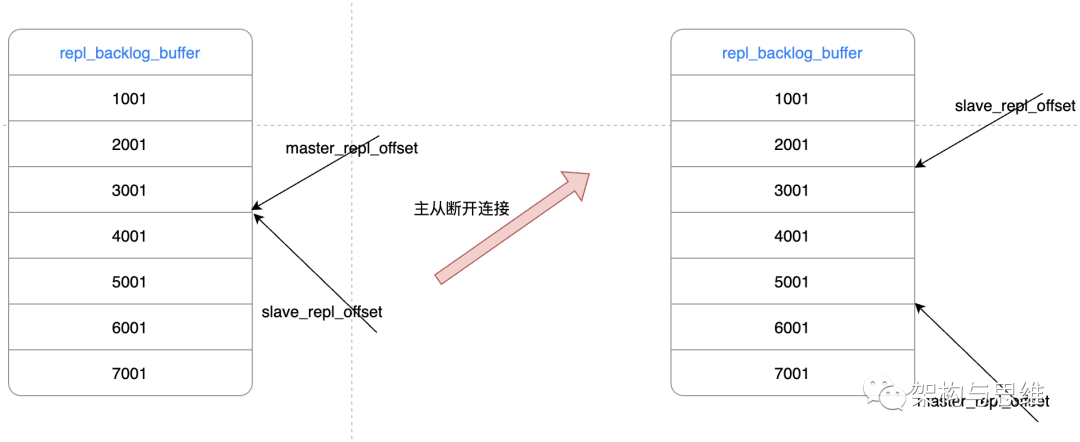
需要注意的是, repl_backlog_buffer 并不是如图中显示的貌似无限队列的模式,而是一个类似环形数组,如果数组内容满了,就会从头开始覆盖前面的内容,因为给到的内存空间是有限的。
在主从之间重新连接之后,slave 会先发送 psync 命令给 master,同时将自己的 {runID,slave_repl_offset} 两个参数发送给 master。master 只需要把 master_repl_offset 与 slave_repl_offset 之间的命令同步给从库即可。增量复制的流程类似如下:
在配置repl_backlog_buffer 的时候,需要综合考虑各种因素,太大了会导致增量执行周期比较长,还不如RDB全量覆盖。太小了,有可能从库还没读取到就被 Master 的新写操作覆盖了,那样也只能执行全量复制。
所以我们需要给出一个合理 缓冲区Size。一般有如下的计算公式供参考:
repl_backlog_buffer_size = seconds * write_size_per_second
seconds:正常情况下从库断开,到重连主库所需的平均时间,秒为单位。
write_size_per_second:主库平均每秒产生的写命令数据量大小。
如主服务器大约每秒产生 0.5 MB 的写指令数据,而断开到重连一般需要30s,那么缓冲区的大小就是 0.5 * 30s = 15 MB。
但是我们一般会保留一点buffer,比如 预留 0.5 倍,那就是 : 1.5 * 15 MB = 22.5 MB 。
4.1.2.2 基于长连接的命令传播
上面的工作都是为了完成完整复制,那在完成全量复制之后,主从开始进入正常有序的同步了,具体应该怎么做呢?
主从完成全量复制之后,他们之间需要保持连接。当主库收到操作指令的时候,通过这个连接同步给从库,这个过程称之为 基于长连接的命令传播。
为了保证传播的有效性和稳定性,从节点采用心跳机制进行侦测,发送命令:PING 和 REPLCONF ACK。
- 主->从:PING
每隔指定的时间(比如 1 分钟,可配置),主节点会向从节点发送 PING 命令,侦测从节点有无超时来判断从节点的健康情况。
- 从->主:REPLCONF ACK
命令执行传播的阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令,将复制的偏移量发送过去。
REPLCONF ACK <replication_offset>
replication_offset 的属性指的是当前从实例服务器的复制偏移量。
从实例发送 REPLCONF ACK 命令对于主要实例,主要有以下作用:
检测主从服务器的网络通路是否正常。
辅助实现 min-slaves 选项,使用Redis的 min-slaves-to-write(少于n个从实例时,拒绝执行写命令) 和 min-slaves-max-lag(主从延迟大于等于n秒时,拒绝执行写命令)两个选项可以防止主服务器在不安全的情况下执行写命令。
检测命令丢失, 从节点发送了 slave_replication_offset,主节点会对比 master_replication_offset ,如果不一致,说明从节点数据缺失,主节点会从 repl_backlog_buffer缓冲区中找到并推送缺失的数据。
4.1.2.3 如何确定执行全量同步还是部分同步?
从节点可以发送 psync 命令给主节点请求同步数据,主节点判断从节点的当前状态,看看具体同步是采用全量复制还是部分复制。核心的地方就是psync的参数,这个我们前面也已经提到过了:
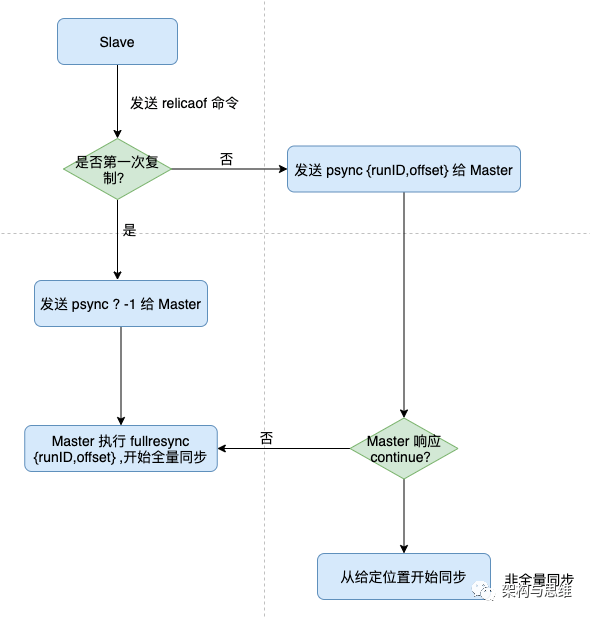
下面我们来拆解下步骤:
1、从节点根据自身状态,发送 psync命令给 master:
- 如果从实例从未执行过 replicaof ,则从节点发送 psync ? -1,代表全量,从 -1 处开始复制。
- 如果从节点之前执行过 replicaof,则取当前实例中记录下 runID和 offset,执行命令 psync <runID> <offset>, runID 是主节点 runID,offset 复制偏移量。
2、主节点根据接收到的psync命令及当前服务器状态,决定执行全量复制还是部分复制:
- 对比主、从节点的 runID 一致,且从节点发送 slave_repl_offset 之后的数据在 repl_backlog_buffer缓冲区中均存在(队列是环形的,有可能被擦除重写了),则回复 CONTINUE,代表以追加模式进行部分复制。
- runID 与从节点发送的 runID 不同,或者从节点发送的 slave_repl_offset 之后的数据已不在主节点的 repl_backlog_buffer缓冲区中 (因为队列是环形的,所以等待时间太长或者有断连的情况,有可能被擦除重写了),则回复从节点 FULLRESYNC <runid> <offset>,表示要进行全量复制,同时记下主节点的 runID 和offset。
4.2 1主n从同步的理解
从上面的内容,我们得到以下两点:
- 多个从库情况下,每个从库都会记录自己的 slave_repl_offset,各自复制的进度也不相同。
- 重连主库进行恢复时,从库会通过 psync 命令将 slave_repl_offset 告知主库,主库判断从库的状态,来决定进行增量复制,还是全量复制。
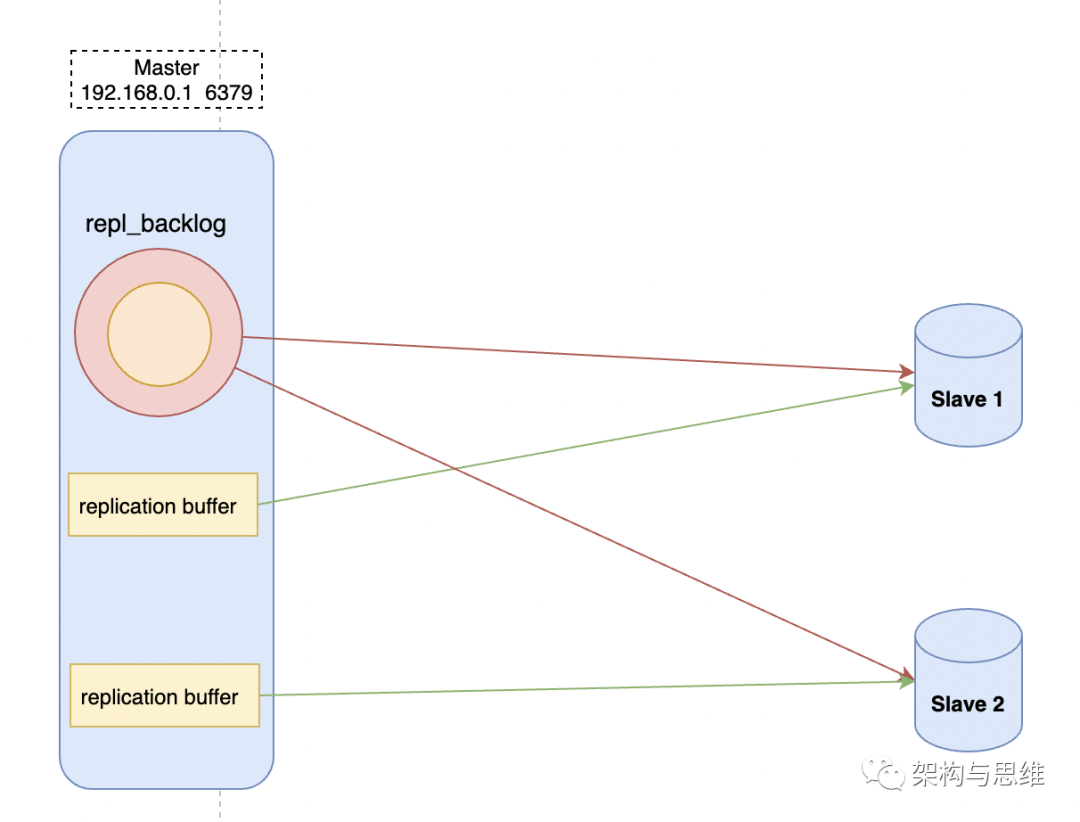
- replication buffer 和 repl_backlog 的说明
replication buffer 是主从库在进行全量复制时,主库上用于和从库连接的客户端的 buffer,而 repl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer,所有从库共享的。
主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,需要将自己的复制进度(slave_repl_offset)发给主库,主库才可以按照偏移量取数据跟它同步。
如图所示:
5、总结
- 主从复制的作用一个是为分担读写压力,均衡负载,另一个是为了保证部分实例宕机之后服务的持续可用性,所以Redis演变出主从架构和读写分离。
- 主从复制的步骤包括:建立连接的阶段、数据同步的阶段、基于长连接的命令传播阶段。
- 数据同步可以分为全量复制和部分复制,全量复制一般为第一次全量或者长时间主从连接断开。
- 命令传播阶段主从节点之间有 PING(主到从的的探测) 和 REPLCONF ACK(从到主的ack应答) 命令,这种互相确认心跳的模式保证数据同步的稳定性。
- 主从模式是比较低级的可用性优化,要做到故障自动转移,异常预警,高保活,还需要更为复杂的哨兵或者集群模式,这个后面我们会有专门的文章进行介绍。
看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言,会第一次时间给大家解答,谢谢!
边栏推荐
- Detailed explanation of ThreadLocal
- UE4 blueprint learning chapter (IV) -- process control forloop and whileloop
- 做国外LEAD2022年下半年几点建议
- General implementation and encapsulation of go diversified timing tasks
- 机试刷题1
- case 关键字后面的值有什么要求吗?
- POJ 1258 Agri-Net
- 金融人士必读书籍系列之六:权益投资(基于cfa考试内容大纲和框架)
- 【雅思口语】安娜口语学习记录part1
- MATLAB小技巧(27)灰色预测
猜你喜欢

Should novice programmers memorize code?
![pytorch_ Yolox pruning [with code]](/img/98/31d6258635ce48ac53819d0ca12d1d.jpg)
pytorch_ Yolox pruning [with code]
Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
Aardio - does not declare the method of directly passing float values
Clip +json parsing converts the sound in the video into text

(18) LCD1602 experiment
Aardio - integrate variable values into a string of text through variable names
Config:invalid signature solution and troubleshooting details

cuda 探索
MATLAB小技巧(27)灰色预测
随机推荐
QT signal and slot
Custom swap function
2014 Alibaba web pre intern project analysis (1)
config:invalid signature 解决办法和问题排查详解
return 关键字
Sizeof keyword
金融人士必读书籍系列之六:权益投资(基于cfa考试内容大纲和框架)
Aardio - construct a multi button component with customplus library +plus
View
Jafka来源分析——Processor
POJ 1094 sorting it all out
HDU 5077 NAND (violent tabulation)
Rust knowledge mind map XMIND
Traversal of a tree in first order, middle order, and then order
MySQL ---- first acquaintance with MySQL
Bipartite graph determination
CUDA exploration
[compilation principle] LR (0) analyzer half done
[leetcode] 19. Delete the penultimate node of the linked list
BasicVSR_PlusPlus-master测试视频、图片