当前位置:网站首页>SqlServer函数,存储过程的创建和使用
SqlServer函数,存储过程的创建和使用
2022-07-04 12:52:00 【罗马苏丹默罕默德】
1.函数
在SQLserer中,函数是经常要用到的,不过大多数时候只是使用一些系统函数。
函数的分类:
MS将函数类型分为三类
- 标量函数
- 表值函数
- 系统函数
标量函数的解释为
用户定义标量函数返回在 RETURNS 子句中定义的类型的单个数据值。 对于内联标量函数,返回的标量值是单个语句的结果。 对于多统计信息标量函数,函数正文可以包含返回单个值的一系列 Transact-SQL 语句。 返回类型可以是除 text、 ntext、 image、 cursor和 timestamp外的任何数据类型。(大致可以理解为返回一个具体的值)
表值函数的介绍为
用户定义表值函数 (TVF) 返回 表 数据类型。 对于内联表值函数,没有函数主体;表是单个 SELECT 语句的结果集(就是返回一张表了)
系统函数则是SQLServer提供的可以直接使用的函数。
自定义函数
标量函数
自定义标量函数的公式为
-- Transact-SQL Scalar Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
)
RETURNS return_data_type
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
[ ; ]
标量函数的定义比较简单。主要分为两个部分,第一部分
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
) //定义函数名和参数,例如
// Create function CountRectangleSize(@len int,@wid int) //当然你也可以设置默认值和readonly属性
// return int
RETURNS return_data_type
第二部分则比较灵活
[ WITH <function_option> [ ,...n ] ]
//函数选项------在BEGIN开始之前,可以做一些设置,像开启事务什么的,下面是MS的解释
// NATIVE COMPILATION
//| SCHEMABINDING
//| [ EXECUTE AS Clause ]
//| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
[ AS ]
//BEGIN 和 END 中是函数的主体,在其中执行相关的操作(定义变量,赋值,判断。。。。)
BEGIN
function_body
RETURN scalar_expression
END
一个完整的标值函数
CREATE FUNCTION GetReactangleSize(@len int,@wid int)
returns int
BEGIN
DECLARE @Res int;
SET @Res = ( SELECT @len * @wid )
RETURN @Res
END
执行: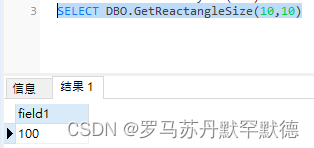
表值函数
表值函数的公式为
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ = default ] [READONLY] }
[ ,...n ]
]
)
RETURNS @return_variable TABLE <table_type_definition>
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
[ ; ]
只是在声明返回值上和标量函数不一样,因为返回的表结构需要自定义
这里直接用例子来演示
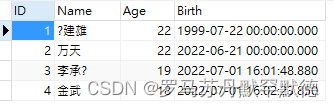
不愿自己定义表的可以使用下面的导出sql文件
-- ----------------------------
-- Table structure for Student
-- ----------------------------
IF EXISTS (SELECT * FROM sys.all_objects WHERE object_id = OBJECT_ID(N'[dbo].[Student]') AND type IN ('U'))
DROP TABLE [dbo].[Student]
GO
CREATE TABLE [dbo].[Student] (
[ID] int IDENTITY(1,1) NOT NULL,
[Name] varchar(200) COLLATE Chinese_Taiwan_Stroke_CI_AS NOT NULL,
[Age] int NOT NULL,
[Birth] datetime NOT NULL
)
GO
ALTER TABLE [dbo].[Student] SET (LOCK_ESCALATION = TABLE)
GO
-- ----------------------------
-- Records of Student
-- ----------------------------
SET IDENTITY_INSERT [dbo].[Student] ON
GO
INSERT INTO [dbo].[Student] ([ID], [Name], [Age], [Birth]) VALUES (N'1', N'?建雄', N'22', N'1999-07-22 00:00:00.000')
GO
INSERT INTO [dbo].[Student] ([ID], [Name], [Age], [Birth]) VALUES (N'2', N'万天', N'22', N'2022-06-21 00:00:00.000')
GO
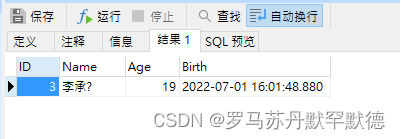
INSERT INTO [dbo].[Student] ([ID], [Name], [Age], [Birth]) VALUES (N'3', N'李承?', N'19', N'2022-07-01 16:01:48.880')
GO
INSERT INTO [dbo].[Student] ([ID], [Name], [Age], [Birth]) VALUES (N'4', N'金武', N'18', N'2022-07-01 16:02:23.850')
GO
SET IDENTITY_INSERT [dbo].[Student] OFF
GO
-- ----------------------------
-- Auto increment value for Student
-- ----------------------------
DBCC CHECKIDENT ('[dbo].[Student]', RESEED, 4)
GO
-- ----------------------------
-- Triggers structure for table Student
-- ----------------------------
CREATE TRIGGER [dbo].[T1]
ON [dbo].[Student]
WITH EXECUTE AS CALLER
FOR INSERT, UPDATE, DELETE
AS
BEGIN
SELECT * FROM Student
END
GO
-- ----------------------------
-- Primary Key structure for table Student
-- ----------------------------
ALTER TABLE [dbo].[Student] ADD CONSTRAINT [PK_Student_ID] PRIMARY KEY CLUSTERED ([ID])
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
GO
Create Function WhoAgeIsBelow(@limit int)
returns @tb TABLE(
Name varchar(20),
Birth datetime
) //表值函数需要自定义返回的表结构,当然还有一种简化的方式等下再说
AS
BEGIN
//然后把查询的表结构插入@tb即可
insert @tb SELECT Name,Birth from Student where Age < @limit
//这里的return是固定的,但不许有后面的值
return
END
测试,输入20,得到如下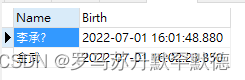
当然,如果你需要的返回表非常简单,那么也可以使用简化的方法。
这种简化的方法被称为内联表值函数
//内联表值函数不需要定义返回表结构,直接使用return返回查询到的表
Create Function FindAgeStudent(@limit int)
returns table
as
return (select * from Student where Student.Age = @limit)
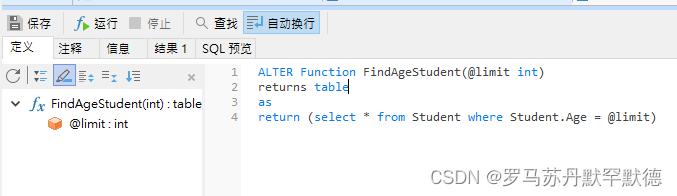
补充:
在自定义的函数中,不可以去修改表的记录,即不可以使用insert,update,delete语句。
同样,你也无法在自定义函数中去执行存储过程。
例:
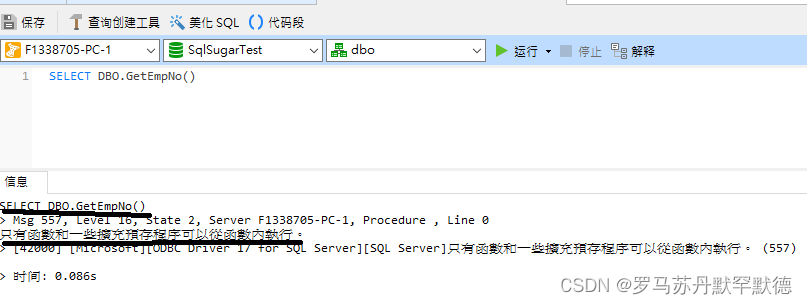
ALTER FUNCTION GetEmpNo()
returns int
BEGIN
DECLARE @wdnmd int,@result varchar(20);
set @wdnmd = (SELECT COUNT(*) FROM t_role_permission)
EXEC @result = plusplus //在函数中定义执行存储过程不会报错,但在使用函数时会报错
return @wdnmd
END
2.存储过程
相比于函数,存储过程友更灵活。它在微软文档里的定义如下
- 接受输入参数并以输出参数的格式向调用过程或批处理返回多个值。
- 包含用于在数据库中执行操作(包括调用其他过程)的编程语句。
- 向调用过程或批处理返回状态值,以指明成功或失败(以及失败的原因)。
相比于函数,它可以说是标量函数的一个超集,可以实现函数的功能,也能够完成编程,修改记录等操作。
它的语法如下
-- Transact-SQL Syntax for Stored Procedures in SQL Server and Azure SQL Database
CREATE [ OR ALTER ] { PROC | PROCEDURE }
[schema_name.] procedure_name [ ; number ]
[ { @parameter_name [ type_schema_name. ] data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT | [READONLY]
] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
[ FOR REPLICATION ]
AS { [ BEGIN ] sql_statement [;] [ ...n ] [ END ] }
[;]
<procedure_option> ::=
[ ENCRYPTION ]
[ RECOMPILE ]
[ EXECUTE AS Clause ]
存储过程的也可以带返回值,返回值必须为int,
当然可以设置OUT/OUTPUT实现多个返回值
create proc SetStuAge(@age int)
AS
BEGIN
Update Student set Age = @age
SELECT * from Student
END
执行: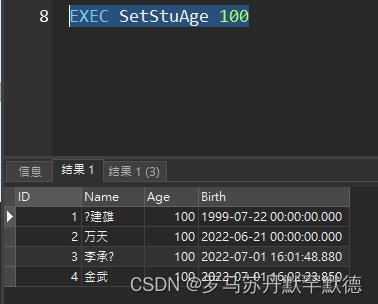
存储过程的流程控制
流程控制在自定义函数也是能使用的,但是因为在自定义函数中无法做到改变记录,所以在用到不多。而在存储过程中则经常使用。
1.判断
语法:
IF search_condition
BEGIN
statement_list
END
ELSE
BEGIN
statement_list
END
判断的结构比较简单,只需要在IF/ELSE下各用BEGIN和END声明区域即可
例
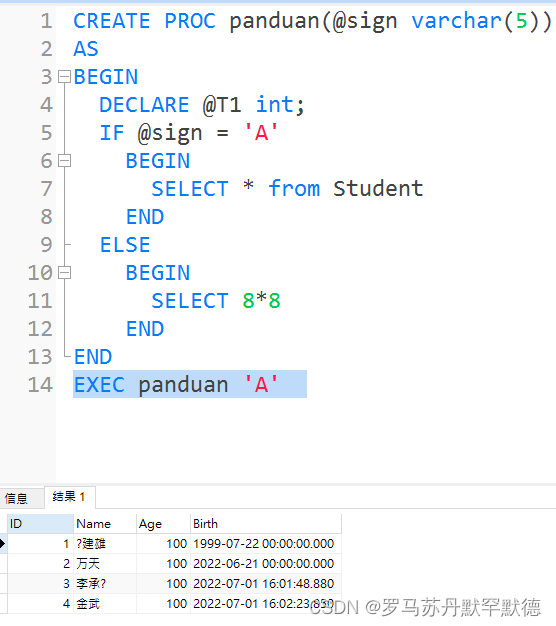
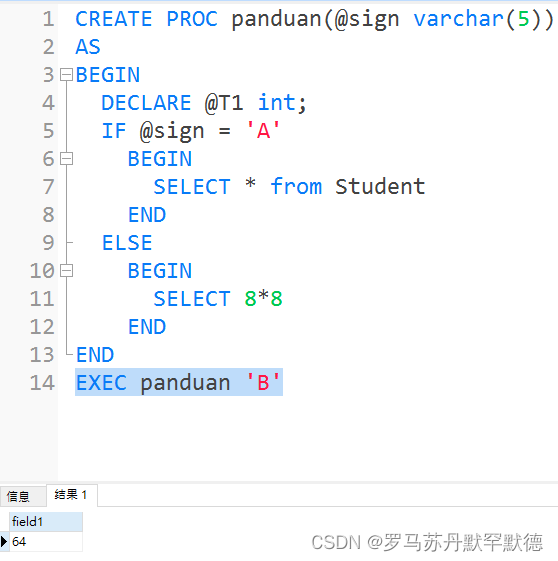
CREATE PROC panduan(@sign varchar(5))
AS
BEGIN
IF @sign = 'A'
BEGIN
SELECT * from Student
END
ELSE
BEGIN
SELECT 8*8
END
END
EXEC panduan 'A'
2.循环
存储过程的循环控制比较复杂
一般来说,SqlServer的循环也和编程语言一样使用While关键字
WHILE loop_condition BEGIN
statement_list
END
WHILE关键字单独使用的用法比较简单,但是一般都和Cursor游标结合使用
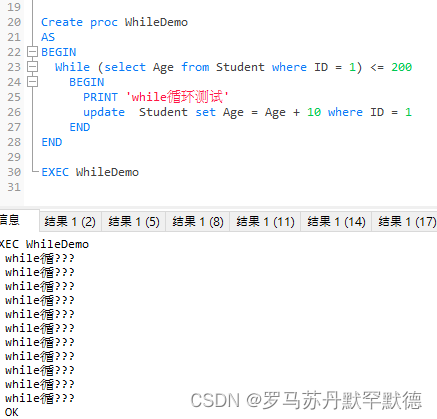
Create proc WhileDemo
AS
BEGIN
While (select Age from Student where ID = 1) <= 200
BEGIN
PRINT 'while循环测试'
update Student set Age = Age + 10 where ID = 1
END
END
CURSOR游标循环
cursor是存储过程的游标类型,用来遍历查询到的记录,类似于编程语言中的foreach循环
cursor的使用方法非常的灵活,语法大致如下
--声明游标
ISO Syntax
DECLARE cursor_name [ INSENSITIVE ] [ SCROLL ] CURSOR
FOR select_statement
[ FOR { READ ONLY | UPDATE [ OF column_name [ ,...n ] ] } ]
[;]
Transact-SQL Extended Syntax
DECLARE cursor_name CURSOR [ LOCAL | GLOBAL ]
[ FORWARD_ONLY | SCROLL ]
[ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ]
[ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ]
[ TYPE_WARNING ]
FOR select_statement
[ FOR UPDATE [ OF column_name [ ,...n ] ] ]
[;]
--打开游标
OPEN { { [ GLOBAL ] cursor_name } | cursor_variable_name }
--读取游标
FETCH
[ [ NEXT | PRIOR | FIRST | LAST
| ABSOLUTE { n | @nvar }
| RELATIVE { n | @nvar }
]
FROM
]
{ { [ GLOBAL ] cursor_name } | @cursor_variable_name }
[ INTO @variable_name [ ,...n ] ]
--关闭游标
CLOSE { { [ GLOBAL ] cursor_name } | cursor_variable_name }
--删除游标
DEALLOCATE { { [ GLOBAL ] cursor_name } | @cursor_variable_name }
这里推荐查看微软的文档
微软的文档
这里也推荐一篇文章
SQL游标详解
例:
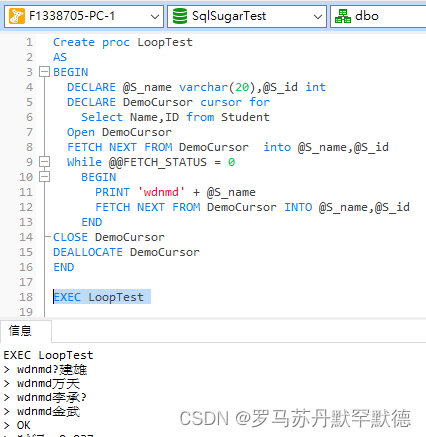
Create proc LoopTest
AS
BEGIN
DECLARE @S_name varchar(20),@S_id int
--定义游标
DECLARE DemoCursor cursor for
Select Name,ID from Student
--打开游标
Open DemoCursor
--读取游标
FETCH NEXT FROM DemoCursor into @S_name,@S_id
While @@FETCH_STATUS = 0
BEGIN
PRINT 'wdnmd' + @S_name
FETCH NEXT FROM DemoCursor INTO @S_name,@S_id
END
--关闭游标
CLOSE DemoCursor
--删除游标
DEALLOCATE DemoCursor
END
边栏推荐
- 基于51单片机的超声波测距仪
- The font of markdown grammar is marked in red
- 软件测试之测试评估
- 实时数据仓库
- 去除重複字母[貪心+單調棧(用數組+len來維持單調序列)]
- R语言dplyr包summarise_if函数计算dataframe数据中所有数值数据列的均值和中位数、基于条件进行数据汇总分析(Summarize all Numeric Variables)
- 游戏出海,全球化运营
- 实战解惑 | OpenCV中如何提取不规则ROI区域
- AI与生命科学
- Understand chisel language thoroughly 09. Chisel project construction, operation and testing (I) -- build and run chisel project with SBT
猜你喜欢
Real time data warehouse

10.(地图数据篇)离线地形数据处理(供Cesium使用)

C# wpf 实现截屏框实时截屏功能

The font of markdown grammar is marked in red
vscode 常用插件汇总
RK1126平台OSD的实现支持颜色半透明度多通道支持中文
Map of mL: Based on Boston house price regression prediction data set, an interpretable case of xgboost model using map value
商業智能BI財務分析,狹義的財務分析和廣義的財務分析有何不同?
Mask wearing detection based on yolov1

codeforce:C. Sum of Substrings【边界处理 + 贡献思维 + 灵光一现】
随机推荐
Opencv3.2 and opencv2.4 installation
富文本编辑:wangEditor使用教程
聊聊保证线程安全的 10 个小技巧
Leetcode T48:旋转图像
R language uses bwplot function in lattice package to visualize box plot and par Settings parameter custom theme mode
Mask wearing detection based on yolov1
Use of arouter
Introducing testfixture into unittest framework
golang fmt. Printf() (turn)
R语言ggplot2可视化:gganimate包创建动态折线图动画(gif)、使用transition_reveal函数在动画中沿给定维度逐步显示数据
Xcode 异常图片导致ipa包增大问题
Abnormal value detection using shap value
Intelligence d'affaires bi analyse financière, analyse financière au sens étroit et analyse financière au sens large sont - ils différents?
【云原生】我怎么会和这个数据库杠上了?
第十六章 字符串本地化和消息字典(二)
R language ggplot2 visualization: gganimate package creates dynamic line graph animation (GIF) and uses transition_ The reveal function displays data step by step along a given dimension in the animat
2022 game going to sea practical release strategy
gin集成支付宝支付
Data warehouse interview question preparation
How to operate and invest games on behalf of others at sea