当前位置:网站首页>【StoneDB Class】Introduction Lesson 2: Analysis of the Overall Architecture of StoneDB
【StoneDB Class】Introduction Lesson 2: Analysis of the Overall Architecture of StoneDB
2022-08-01 12:41:00 【StoneDB】

Today's class is mainly to explain to you StoneDB 的整体架构,Let's first look at the architecture diagram:
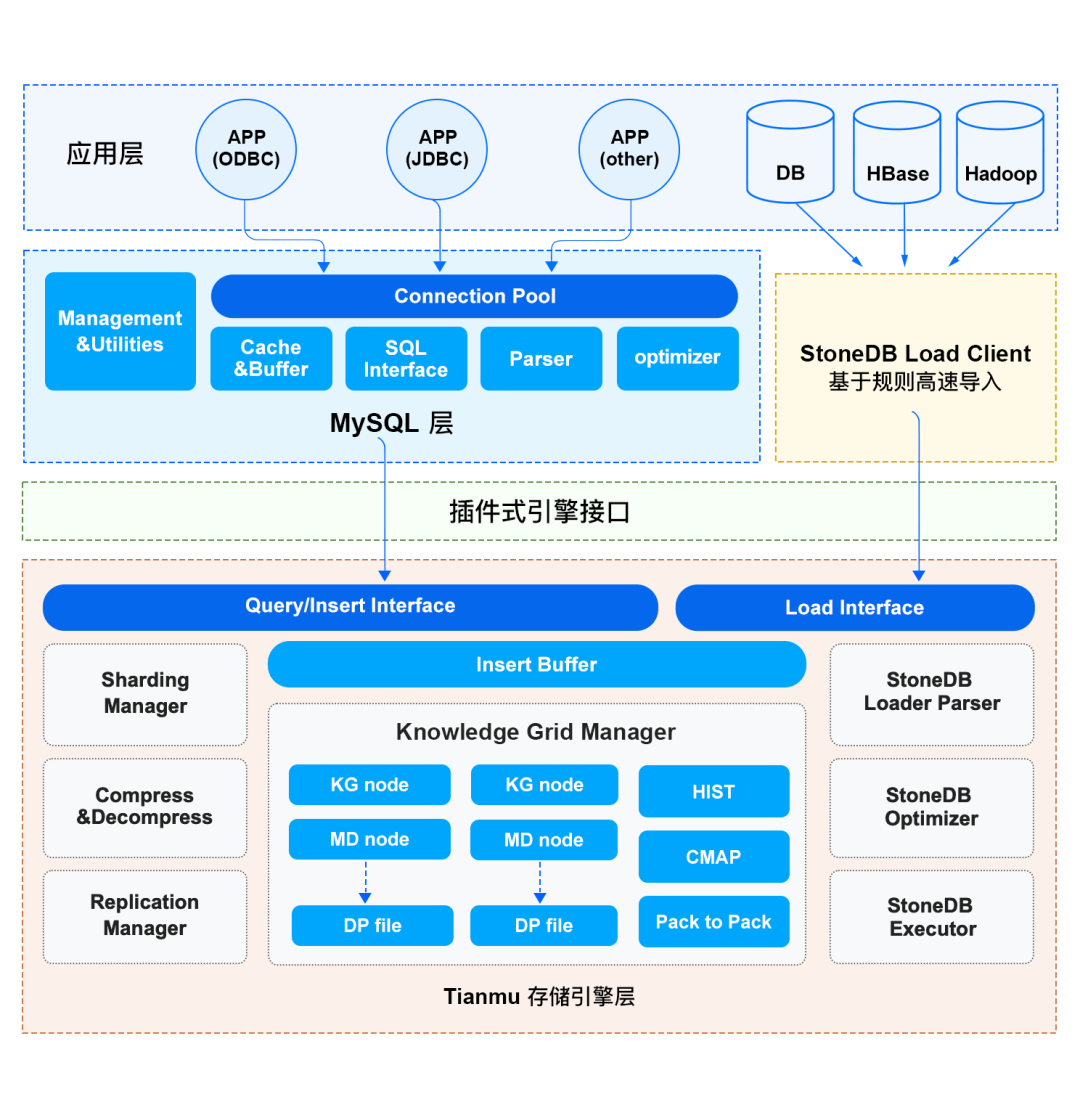 如上图所示,StoneDB 的整体架构分为三层,分别是应用层、服务层和存储引擎层.The application layer is mainly responsible for client connection management and permission verification;The service layer provides SQL 接口、查询缓存、解析器、优化器、执行器等组件;Tianmu The storage engine layer where the engine is located is StoneDB 的核心,Data organization and compression、And knowledge grid-based query optimization is in Tianmu 引擎实现.下面为大家详细介绍 StoneDB Main features in the overall architecture.
如上图所示,StoneDB 的整体架构分为三层,分别是应用层、服务层和存储引擎层.The application layer is mainly responsible for client connection management and permission verification;The service layer provides SQL 接口、查询缓存、解析器、优化器、执行器等组件;Tianmu The storage engine layer where the engine is located is StoneDB 的核心,Data organization and compression、And knowledge grid-based query optimization is in Tianmu 引擎实现.下面为大家详细介绍 StoneDB Main features in the overall architecture.

列式存储
StoneDB Created tables are stored on disk in columnar mode,Since each column in a relational database has the same data type,So this kind of continuous space storage compared with line storage,More able to achieve high data compression ratio.在读取数据方面,If you only want to query the results of one field,in row storage,The engine layer returns a whole row of data to the service layer,need to consume more network bandwidth and IO.Columnar storage only needs to return one field,And greatly reduce the network bandwidth IO 的消耗.另外,Columnar storage eliminates the need to create and maintain indexes for columns.
id | name | age |
1 | Jack | 37 |
2 | Rose | 18 |
3 | Jason | 26 |


数据压缩
The above mentioned the same data type columns are stored together,Able to achieve high compression ratio of data.StoneDB Different compression algorithms will be selected according to different data types,Currently supported compression algorithms are: PPM、LZ4、B2、Delta 等.数据被压缩后,The amount of data becomes smaller,在读取数据时,对网络带宽和磁盘 IO 的压力也就越小.Because columnar storage has ten times or even higher compression ratio than row storage,StoneDB 可以节省大量的存储空间,降低存储成本.

Knowledge Grid Management
When the amount of data in the table reaches 10 million、亿级,When doing statistical analysis queries,使用 MySQL 的 InnoDB The storage engine or row-based storage engine of other relational databases may take several minutes to tens of minutes to get the result set.This is because the cost-based optimizer needs to generate an execution plan based on table or index statistics,然后再去读取数据,Intermediate process will take place IO,If the statistics are not accurate,An incorrect execution plan was generated,then there may be more IO.而 StoneDB 的 Tianmu Engine under the same amount of data,比 MySQL 的 InnoDB 存储引擎或or other relational database row storage engine要快数十倍.Tianmu Engine in addition to columnar storage、In addition to data compression features,And knowledge grid technology.Before understanding the knowledge grid,Need to understand the following basic concepts.
Data Pack
Packets are used to store actual data,is the lowest data storage unit,Each column in accordance with the65536Lines are split into a packet.Each packet is smaller than a column,具有更高的压缩比,And each packet is bigger than each line,Has better query performance.A packet is the decompression unit of the Knowledge Grid.
Rough sets are a mathematical discipline,Used to study incomplete data,imprecise representation of knowledge、学习、A theory of induction etc..在 StoneDB 中,Rough set is used to the division of the packet,根据 SQL The confirmation range of the data of the query condition in the data packet,Packets are divided into the following categories:
1)irrelevant packets:Indicates packets that do not meet the query conditions,Such packets are simply ignored.
2)相关的数据包:Indicates data packets that meet the query conditions,If you want to query packets inside concrete data,Packets need to be decompressed,If you can get the data according to the metadata node of the packet,So do not need to unzip the packet.
3)suspicious packets:Indicates that the data part of the data packet satisfies the query condition,Need to further decompress the packet to get the data that meets the conditions.

Metadata Node
The metadata node records the maximum value of the column in each packet、最小值、平均值、总和、总记录数、null 值的数量、压缩方式、占用的字节数.Each metadata node corresponds to a data packet.
Knowledge Node
The upper layer of the metadata node is the knowledge node,In addition to record data packets between the relationship between the columns or collection of metadata,For example, the minimum and maximum range of the packet、Outside the relationship between the columns,Data characteristics are also recorded along with more in-depth statistics.Most of the knowledge node data is generated when the data is loaded,The other part is generated when querying.
knowledge node3种基本类型:
1)Histogram
数据类型为整型、日期型、The statistical value of the column of float type exists in the form of a histogram.Divide the minimum and maximum values of a packet into1024段,Each segment occupies one bit,If the actual value in the packet is in the range in the segment,则标记为1,否则标记为0.Histogam Automatically created when data is loaded.
如下的例子中,Indicates that the value in the data packet falls in0~100和102301~102400两个区间.
0‒100 | 101‒200 | 201‒300 | ... | 102301‒102400 |
1 | 0 | 0 | ... | 1 |
If you want to do the following SQL:
select * from table where id>199 and id<299;
It can be seen from the histogram,This query did not hit on this packet,The current data packets don't satisfy the query conditions,This packet is directly discarded.
2)Character Map
Character map for columns whose data type is string.Statistics in the current packet 1~64 长度中 ASCII 字符是否存在.如果存在,则标记为1,否则标记为0.When searching for characters,Comparing the character identifier values in sequence according to the character order can know whether the data packet contains matching data.Character Map Automatically created when data is loaded.
如下的例子中,说明 A 在字符串的第1个和第64个位置.
Char/Char pos | 1 | 2 | ... | 64 |
A | 1 | 0 | ... | 1 |
B | 0 | 1 | ... | 0 |
C | 1 | 1 | ... | 1 |
... | ... | ... | ... | ... |
3)Pack to Pack
A package-to-package relationship represents an equivalence mapping table between two columns of different tables,and store it as a binary matrix,If eligible for a table,则标记为1,否则标记为0.The package-to-package relationship can help to quickly determine the data packages that meet the query conditions when the table is associated with the query.,Thereby improving the efficiency of table association query.table association query,Pack to Pack 被自动创建.
如下的例子中,The query condition associated with the table is"A.C=B.D",在 A.C1 这个数据包中,只有 B.D2 和 B.D5 There are values in both packets that match the table association criteria.
B.D1 | B.D2 | B.D3 | B.D4 | B.D5 | |
A.C1 | 0 | 1 | 0 | 0 | 1 |
A.C2 | 1 | 1 | 0 | 0 | 0 |
A.C3 | 1 | 1 | 0 | 1 | 1 |
Knowledge Grid
Knowledge grid consists of metadata nodes and knowledge nodes,When doing statistical analysis queries,StoneDB Filter out irrelevant packets based on knowledge grid technology,If only relevant packets remain,Then you only need to read the metadata to return the query results.This eliminates the process of decompressing packets and reduces IO 消耗,Improved query response time and network utilization.
接下来,We use an example to understand the query optimization process of a query statement using knowledge grid technology at the storage engine layer.
There are the following query statements and the data value distribution range of the packet node:
select min(t2.D) from t1,t2 where t1.B=t2.C and t1.A>15;
Min. | Max. | |
t1.A1 | 1 | 9 |
t1.A2 | 10 | 30 |
t1.A3 | 40 | 100 |
根据列 A 的 DPN 可知,t1.A1 Belong to the packet,t1.A2 are suspicious packets,t1.A3 belonging to the relevant package,This step filters out packets t1.A1.
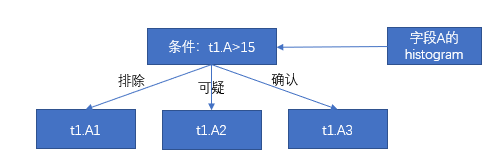
t2.C1 | t2.C2 | t2.C3 | t2.C4 | t2.C5 | |
t1.B1 | 1 | 1 | 1 | 0 | 1 |
t1.B2 | 0 | 1 | 0 | 0 | 0 |
t1.B3 | 1 | 1 | 0 | 0 | 1 |
The first step is to filter out the packet t1.A1,This step does not require t1.B1 和 t2.C1 Do a correlation comparison,According to the mapping table of package-to-package relationship, we can see that,This step filters out packets t2.C3 和 t2.C4.So packets have associated conditions t2.C2 和 t2.C5.

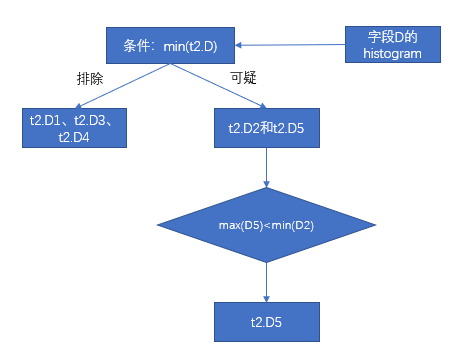
Min. | Max. | |
t2.D1 | 0 | 500 |
t2.D2 | 101 | 440 |
t2.D3 | 300 | 6879 |
t2.D4 | 1 | 432 |
t2.D5 | 3 | 100 |
The first and second steps have been filtered out D1、D3、D4,那么只剩下 D2 和D5,根据列 D 的 DPN 可知,D5 的最大值100小于 D2 的最小值101,This step filters out packets D2.In the end, only packets remain D5,get from metadata D5 的最小值3.

高性能导入
StoneDB Provide independent data import client,Support for different data source environment,Supports multilingual architecture.data before import,首先会进行预处理,such as data compression and construction of knowledge nodes.数据经过预处理后,Entering the storage engine does not need to perform parsing again、Operations such as data validation and transaction processing.
以上是本次课程的全部内容,In the next lesson we will take you to learn StoneDB Installation deployment and manual compilation of.如果您对 StoneDB 感兴趣,可以通过下方链接查看 StoneDB 源码、阅读文档,期待您的贡献!
StoneDB 开源仓库
https://github.com/stoneatom/stonedb






可扫码添加小助手
加入StoneDB开源社区用户群
讨论交流,共同进步

本文分享自微信公众号 - StoneDB(StoneDB2021).
如有侵权,请联系 [email protected] 删除.
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享.
边栏推荐
- Istio Meetup China: Full Stack Service Mesh - Aeraki Helps You Manage Any Layer 7 Traffic in an Istio Service Mesh
- 【公开课预告】:超分辨率技术在视频画质增强领域的研究与应用
- Favorites|Mechanical Engineer Interview Frequently Asked Questions
- CloudCompare&PCL ICP配准(点到面)
- STM32 CAN过滤器配置详解
- 并发编程10大坑,你踩过几个?
- The difference between undefined and null in JS
- 蔚来又一新品牌披露:产品价格低于20万
- 深入理解 Istio —— 云原生服务网格进阶实战
- R language ggplot2 visualization: use ggpubr package ggscatter function visualization scatterplot, use xscale wasn't entirely specified X axis measurement adjustment function, set the X coordinate for
猜你喜欢

重磅消息 | Authing 实现与西门子低代码平台的集成

Audio and Video Technology Development Weekly | 256
bpmn-process-designer基础上进行自定义样式(工具、元素、菜单)

STM32 CAN filter configuration details

Apex installation error

CAN通信标准帧和扩展帧介绍

英特尔全方位打造算力基础,助推“算”赋百业

ECCV22|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
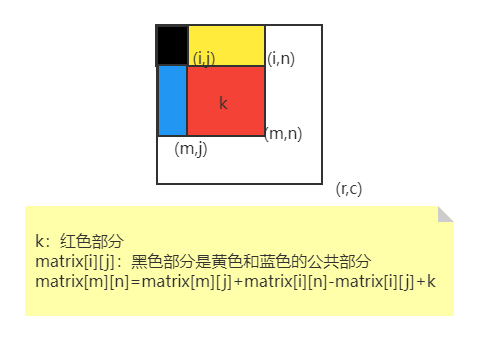
leetcode/submatrix element sum
故障007:dexp导数莫名中断
随机推荐
What is MNIST (what does plist mean)
.NET性能优化-使用SourceGenerator-Logger记录日志
(ES6以上以及TS) Map对象转数组
CAN通信的数据帧和远程帧
R语言诊断ARIMA模型:forecast包构建了一个ARIMA模型、使用checkresiduals函数诊断ARIMA模型、并进行结果解读(拟合较差的ARIMA模型具有的特点)
Envoy source code flow chart
深入理解 Istio —— 云原生服务网格进阶实战
CAN通信标准帧和扩展帧介绍
The difference between undefined and null in JS
Aeraki Mesh Joins CNCF Cloud Native Panorama
【讲座分享】“营收“看金融
MMF的初步介绍:一个规范化的视觉-语言多模态任务框架
CloudCompare & PCL ICP registration (point to face)
如何成功通过 CKA 考试?
sql中ddl和dml(数据库表与视图的区别)
[5 days countdown] to explore the secret behind the great quality promotion, gift waiting for you to take of $one thousand
快速幂---学习笔记
深入解析volatile关键字
【云享新鲜】社区周刊·Vol.73- DTSE Tech Talk:1小时深度解读SaaS应用系统设计
ddl and dml in sql (the difference between database table and view)