当前位置:网站首页>Overview of convolutional neural network structure optimization
Overview of convolutional neural network structure optimization
2022-07-04 16:06:00 【mb617a04e6cdfd3】
Overview of convolutional neural network structure optimization
Artificial intelligence technology and consulting

source :《 Journal of Automation 》 , Author Lin Jingdong et al
pick want In recent years , Convolutional neural networks (Convolutional neural network,CNNs) In computer vision 、 natural language processing 、 Speech recognition and other fields have made rapid development , Its strong feature learning ability has attracted extensive attention of experts and scholars at home and abroad . However , Due to the large scale of deep Convolutional Neural Networks 、 Computational complexity , It limits its application in the environment with high real-time requirements and resource constraints . Optimizing the structure of convolutional neural network to compress and accelerate the existing network is conducive to the promotion and application of deep learning in a wider range , At present, it has become a research hotspot of deep learning community . This paper sorts out the development history of convolutional neural network structure optimization technology 、 Research status and typical methods , These works are summarized as network pruning and thinning 、 Tensor decomposition 、 Knowledge transfer and fine module design 4 And has carried on a more comprehensive discussion . Last , This paper analyzes and summarizes the hot spots and difficulties of current research , The future development direction and application prospect of network structure optimization are prospected .
key word Convolutional neural networks , Structural optimization , Network pruning , Tensor decomposition , Knowledge transfer
Convolutional neural networks (Convolutional neural network,CNNs) As one of the most important depth models , Because it has good feature extraction ability and generalization ability , In image processing 、 Target tracking and detection 、 natural language processing 、 Scene classification 、 Face recognition 、 Audio Retrieval 、 Many fields of medical diagnosis have achieved great success . On the one hand, the rapid development of convolutional neural network benefits from the substantial improvement of computer performance , So that the construction and training of a larger network is no longer limited by the level of hardware ; On the other hand, it benefits from the growth of large-scale annotation data , Enhanced the generalization ability of the network . In a large-scale visual recognition competition (ImageNet large scale visual recognition competition,ILSVRC) Take the previous excellent models of ,AlexNet[1] stay ILSVRC 2012 Upper Top-5 The recognition accuracy reaches 83.6%, In the following years, the performance of convolutional neural network continued to improve [2−4],ResNet-50[5] stay ILSVRC 2015 Upper Top-5 The recognition accuracy reaches 96.4%, Has exceeded the human average . After that , Convolutional neural network is further applied to other fields , For example, Google DeepMind The artificial intelligence Go program developed by the company AlphaGo stay 2016 In, he defeated world go champion Li Shishi .
The overall architecture of convolutional neural network generally follows a fixed paradigm , That is, the first half of the network is stacked with convolution , Occasionally, several pooling layers are inserted to form a feature extractor , Finally, connect the full connection layer as a classifier , Form an end-to-end network model , Pictured 1 in LeNet-5[6] Shown . Convolution neural network generally increases the network depth by increasing the number of convolution layers , The depth model obtained in this way has better performance in classification tasks [7]. From the table 1 It can be seen that , The performance of convolutional neural networks is growing , Its presence ImageNet The recognition error rate of data sets continues to decrease , At the same time, its time complexity and space complexity also rise correspondingly . In particular , The number of network layers of convolutional neural network continues to increase , The number of training parameters and the number of multiplication and addition operations also remain at a high level , for example VGGNet-16 With as much as 138 M Parameter quantity , Its overall model scale exceeds 500 M, need 155 Only 100 million floating-point operations can classify a picture .
Deep convolutional neural networks usually contain dozens or even hundreds of convolutional layers , The amount of training parameters is often millions , stay GPU It still takes days or weeks to complete the training with accelerated support ( Such as ResNet need 8 individual GPU Training 2 ∼3 weeks ), It restricts its application in mobile devices 、 Applications in resource constrained scenarios such as embedded systems . As shown in the table 1 Shown , In the past, a large number of floating-point calculation operations were involved in the forward derivation of convolution layer in the network training stage and prediction stage , The neurons in the full connection layer adopt the full connection mode , Have the vast majority of training parameters , Therefore, the time complexity of convolutional neural network is mainly determined by convolution layer , The spatial complexity is mainly determined by the full connection layer . As convolutional neural network gradually develops to a deeper level , The number of convolution layers increases dramatically , The intermediate variables generated in the forward derivation process will occupy a lot of memory space , At this time, the convolution layer determines the time complexity and space complexity of the network . therefore , Reducing the complexity of convolution layer and full connection layer is helpful to optimize the structure of convolution neural network , It also plays an important role in the compression and acceleration of the network .
Research on network structure optimization is in 90 The age has been proposed [8−9], However, at that time, neural networks were mostly shallow networks , The demand for structural optimization is not strong , Therefore, it failed to attract widespread attention . Nowadays, the scale of convolutional neural network is becoming larger and larger , And a large number of application scenarios cannot provide the corresponding necessary resources , Therefore, it is a hot topic in the field of network structure optimization to explore the compression and acceleration model on the premise of ensuring the accuracy of the network . With the gradual deepening of the research on the structural optimization of Convolutional Neural Networks , A large number of achievements continue to emerge , Some scholars have summarized the relevant work in this field , Such as Literature [10] The advantages and disadvantages of various methods of model compression and acceleration are discussed emphatically , The literature [11] The research progress of network acceleration is summarized from two aspects of hardware and software , The literature [12] This paper briefly introduces the typical methods of deep network compression . Based on these works , Combined with the latest research progress and achievements , This paper comprehensively combs and summarizes the research work of convolutional neural network structure optimization . Among them the first 1 Section to section 4 Section from network pruning and thinning 、 Tensor decomposition 、 Knowledge transfer and refined structure design 4 It summarizes the relevant research ideas and methods from three aspects , The first 5 Section synthesis convolution neural network structure optimization research status , The future research trends and application directions are prospected .
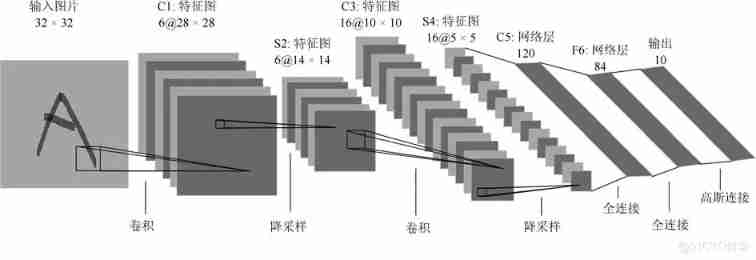
chart 1 LeNet-5 Network structure [6]
Fig.1 Structure of LeNet-5[6]
surface 1 Performance and related parameters of classical convolutional neural network
Table 1 Classic convolutional neural networks and corresponding parameters

1 Network pruning and thinning
The literature [13] According to the study , Convolutional neural network has a large number of redundant parameters from convolution layer to full connection layer , The output value of most neurons after being activated tends to 0, Even if these neurons are removed, the model features can be expressed , This phenomenon is called over parameterization . for example ResNet-50 Have 50 Convolution layer , The whole model needs 95 MB Storage space , In the elimination of 75% The parameter of still works normally , And the running time is reduced by up to 50%[14]. therefore , In the process of network training, we can seek a kind of evaluation mechanism , Eliminate unimportant connections 、 Nodes and even convolution kernels , In order to simplify the network structure . A concrete manifestation of the simplification of the network structure is the sparseness of the network , This brings three benefits to model training : The first is due to the reduction of network parameters , Effectively alleviate the occurrence of over fitting phenomenon [15]; secondly , Sparse network in CSR (Compressed sparse row format,CSR) and CSC(Compressed sparse column format) Such sparse matrix storage format stored in the computer can greatly reduce memory overhead ; Last , The reduction of training parameters makes the network training phase and prediction phase take less time . Because network pruning has the advantages of easy implementation and remarkable effect , At present, it has become the most important structural optimization technology in the field of model compression and acceleration .
According to the different training stages of convolutional neural network , Network pruning and thinning methods mainly include two categories: sparse constraints in training and pruning after training [16]. For the former , By adding a sparsity constraint to the optimization function , Induce the network structure to become sparse , This end-to-end processing method does not need to train the model in advance , It simplifies the optimization process of the network . For the latter , By eliminating the relative redundancy in the network 、 The unimportant part , It can also make the network sparse 、 Simplify . in fact , Whether it is the introduction of sparse constraints in training or the pruning network after training , The ultimate goal is to make the weight matrix of the network sparse , This is also to speed up network training 、 An important way to prevent network over fitting .
For the sparse constraint in the network loss function , Mainly through the introduction of l0 or l1 Implementation of regularization term . Suppose the training dataset D contain N Data pairs (x1,y1),(x2,y2),···,(xN,yN), The training parameters are θ, Then the objective optimization function of network training is generally expressed as :
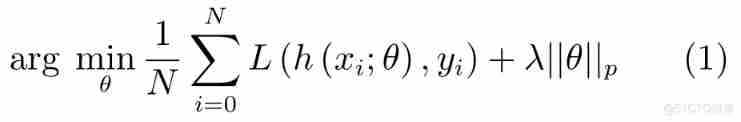
among ,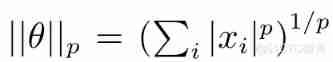 ,p=0,1. The first term of the optimization function is empirical risk , The second term is the regularization term , The optimization function with regularization constraint drives the value of unimportant weight to zero during back propagation , The trained network has certain sparsity and better generalization performance .Collins etc. [17] The hidden layer that needs to be sparse is determined by greedy search in the parameter space , It can greatly reduce the weight connection in the network , The storage requirements of the model are reduced 3 times , And overcome OBS And OBD Deal with the problem of accuracy degradation faced by large networks .Jin etc. [18] Proposed iterative hard threshold (Iterative hard thresholding,IHT) Methods prune the network in two steps , In the first step, eliminate the connections with small weights between hidden nodes , And then fine tune (Fine-tune) Other important convolution kernels , Activate the disconnected connection in the second step , Retrain the entire network for more useful features . Compared with the traditional training network , adopt IHT The trained network has better generalization ability and extremely low memory size .Zeiler etc. [19] Using the forward – Backward segmentation (Forwardbackward splitting method) Deal with loss functions with sparse constraints , It avoids the high computational complexity of computing the second derivative in the back propagation , Speed up network training .Wen etc. [20] It is considered that the network structure from convolution kernel to convolution channel is full of redundant and useless information , Their proposed structured sparse learning (Structured sparsity learning,SSL) The hardware friendly sparse network learned directly not only has a more compact structure , And the running speed can be improved 3 Times to 5 times .Lebedv etc. [21] Prune convolution kernel input in grouping form , Get the best receptive field in a data-driven way (Receptive field), stay AlexNet gain 8.5 Times the speed and the loss of accuracy is less than 1%.Louizos etc. [22] Using a series of optimization measures will be non differentiable l0 Norm regular term added to objective function , The learned sparse network not only has good generalization performance , And it greatly accelerates the process of model training and derivation .
,p=0,1. The first term of the optimization function is empirical risk , The second term is the regularization term , The optimization function with regularization constraint drives the value of unimportant weight to zero during back propagation , The trained network has certain sparsity and better generalization performance .Collins etc. [17] The hidden layer that needs to be sparse is determined by greedy search in the parameter space , It can greatly reduce the weight connection in the network , The storage requirements of the model are reduced 3 times , And overcome OBS And OBD Deal with the problem of accuracy degradation faced by large networks .Jin etc. [18] Proposed iterative hard threshold (Iterative hard thresholding,IHT) Methods prune the network in two steps , In the first step, eliminate the connections with small weights between hidden nodes , And then fine tune (Fine-tune) Other important convolution kernels , Activate the disconnected connection in the second step , Retrain the entire network for more useful features . Compared with the traditional training network , adopt IHT The trained network has better generalization ability and extremely low memory size .Zeiler etc. [19] Using the forward – Backward segmentation (Forwardbackward splitting method) Deal with loss functions with sparse constraints , It avoids the high computational complexity of computing the second derivative in the back propagation , Speed up network training .Wen etc. [20] It is considered that the network structure from convolution kernel to convolution channel is full of redundant and useless information , Their proposed structured sparse learning (Structured sparsity learning,SSL) The hardware friendly sparse network learned directly not only has a more compact structure , And the running speed can be improved 3 Times to 5 times .Lebedv etc. [21] Prune convolution kernel input in grouping form , Get the best receptive field in a data-driven way (Receptive field), stay AlexNet gain 8.5 Times the speed and the loss of accuracy is less than 1%.Louizos etc. [22] Using a series of optimization measures will be non differentiable l0 Norm regular term added to objective function , The learned sparse network not only has good generalization performance , And it greatly accelerates the process of model training and derivation .
Dropout As a powerful network optimization method , It can be regarded as a special regularization method , It is widely used to prevent network training from over fitting [23−24].Dropout Temporarily inactivate half of the neurons at random during each training , It is equivalent to training multiple different networks and combining them in a certain time , It avoids the complex phenomenon of coadaptation (Co-adaptation) happen , In image classification 、 speech recognition 、 Document classification and biological computing have good performance . However , because Dropout Try to train different networks during each training , This will lead to a substantial increase in training time . therefore , At present, there are also some works aimed at Dropout Accelerating research , Such as Li etc. [25] Proposed adaptive Dropout Different polynomial sampling methods are used according to the characteristics and the distribution of neurons , Its convergence rate is relative to the standard Dropout Improve 50%.
Network pruning after training starts from the existing model , Eliminate redundant information in the network , This avoids the high resource cost of retraining the network . According to the different pruning granularity , At present, there are mainly interlayer pruning 、 Feature map pruning 、k×k Nuclear pruning and intranuclear pruning 4 Ways of planting [26], Pictured 2 Shown . A direct consequence of layer pruning is to reduce the depth of the network , Feature graph pruning reduces the width of the network . These two coarse-grained pruning methods are effective in reducing network parameters , But facing the serious problem of network performance degradation .k×k Two fine-grained methods, kernel pruning and intra kernel pruning, have achieved a certain balance between the amount of parameters and the performance of the model , But it increases the complexity of the method .
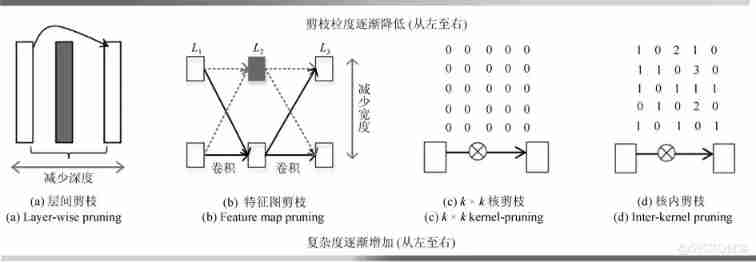
chart 2 Four ways of pruning granularity [26]
Fig.2 Four pruning granularities[26]
in fact , Network pruning method has been proposed since it became popular in deep learning , As early as the 1990s, it was widely used in network optimization problems .Hanson etc. [27] The weight attenuation term is introduced into the error function to make the network tend to be sparse , That is to reduce the number of hidden nodes to reduce the network complexity .LeCun etc. [8] Proposed optimal brain injury (Optimal brain damage,OBD) By removing unimportant connections from the network , Achieve an optimal balance between network complexity and training error , It greatly accelerates the training process of the network .Hassibi etc. [9] Proposed optimal brain surgery (Optimal brain surgeon,OBS) And OBD The biggest difference is in the loss function Hessian The matrix has no constraints , This makes OBS In other networks, it has more advantages than OBD More general generalization ability . Even though OBD And OBS Good results were achieved at first , But because of the need to find the second derivative in its loss function , When dealing with large and complex network structures, the amount of computation is huge , And face the problem of serious loss of network accuracy , Therefore, exploring network pruning and thinning methods suitable for deep convolution neural networks has important research value for network structure optimization .
Network pruning method makes the simplified small network inherit the useful knowledge of the original network , At the same time, it has equivalent performance , At present, a series of fruitful results have been achieved .Han etc. [28] Proposed deep compression (Deep compression) Comprehensive application of pruning 、 quantitative 、 Coding and other methods , Compressible network without affecting accuracy 35 ∼49 times , It makes it possible to transplant the deep convolution network to mobile devices .Srinivas etc. [29] Prune neurons in the full connection layer instead of network connections , The proposed method gets rid of the dependence on training data , Because it avoids repeated training for many times , It greatly reduces the demand for computing resources and time consumption .Guo etc. [30] It is believed that the importance of parameters will change with the beginning of network training , Therefore, restoring the pruned important connections plays an important role in improving network performance . They proposed dynamic network surgery (Dynamic network surgery) A repair operation was added during pruning , When the pruned network connection becomes important, it can be reactivated , These two operations are performed alternately after each training , It greatly improves the efficiency of online learning .Liu etc. [31] in the light of Winograd The problem that the minimum filtering algorithm and network pruning method cannot be combined and applied directly , Propose to first ReLU The activation function moves to Winograd Domain , Then on Winograd Prune the weight after transformation , stay CIFAR-10、CIFAR-100 and ImageNet The multiplication operands on the dataset are reduced 10.4 times 、6.8 Times and 10.8 times .
In recent years, pruning methods for higher-level network structures have emerged in endlessly , It strongly promotes the development of model compression and acceleration , It also plays an important role in the structural optimization of Convolutional Neural Networks .He etc. [32] be based on LASSO Regularization eliminates redundant convolution kernels and their corresponding characteristic graphs , Then reconstruct the remaining network , It also has a good effect on multi branch networks .Li etc. [33] Discovery is based on importance (Magnitudebased) Although the pruning method can achieve better results in the full connection layer , But there is nothing for convolution layer . They directly remove convolution kernels and corresponding characteristic graphs that have little impact on output accuracy , The computational complexity is reduced by 30% in a non sparse connection way .Anwar etc. [26] The pruning method is divided into hierarchical pruning according to the particle size 、 Feature map pruning 、 Convolution kernel pruning 、 Convolution kernel internal pruning 4 A hierarchy , Combining feature graph pruning and convolution kernel pruning, a one-time (One-shot) The optimization method can obtain 60%∼70% The sparsity of . Also for convolution kernel pruning ,Luo etc. [34] Proposed ThiNet The convolutional neural network is compressed and accelerated simultaneously in the training and prediction stages , The importance of obtaining convolution kernel from the probability information of the next convolution layer rather than the current convolution layer , And decide whether to prune the current convolution kernel , It also has a good compression effect for compact Networks . surface 2 The compression effects of different network pruning methods on convolutional neural networks are compared , It can be found that these methods can greatly reduce the training parameters without significantly affecting the network accuracy , It shows that network pruning and thinning is a powerful method of network structure optimization .
2 Tensor decomposition
As the scale of convolutional neural network gradually goes deeper 、 Greater development , The computing resources required in the convolution operation and the storage resources required after each convolution have become the constraints of the miniaturization of the model 、 The bottleneck of rapid development . for instance ,ResNet-152 The number of parameters of the network from the convolution layer is 92%, The amount of calculation from the convolution layer accounts for... Of the total amount of calculation 97%. Existing research results show that [35], Convolutional neural network can accurately predict the results with only a few parameters , This shows that there is a lot of redundant information in convolution kernel . Tensor decomposition is important for removing redundant information 、 Accelerating convolution computation is a very effective method , It can effectively compress the network scale and improve the network running speed , It is beneficial to the efficient operation of deep neural network in mobile embedded environment .
surface 2 The compression effect of network pruning on different networks
Table 2 Comparison of different pruned networks

Generally speaking , A vector is called a one-dimensional tensor , A matrix is called a two-dimensional tensor , The convolution kernel in convolution neural network can be regarded as four-dimensional tensor , Expressed as K∈Rd×d×I×O, among ,I,d,O Respectively represents the input channel , Convolution kernel size and output channel . The idea of tensor decomposition is to decompose the original tensor into several low rank tensors , It helps to reduce the number of convolution operations , Accelerate the network operation process . The previous common tensor decomposition methods are CP decompose 、Tucker Decomposition, etc ,Tucker Decomposition can decompose the convolution kernel into a kernel tensor and several factor matrices , It is a high-order principal component analysis method , It is expressed in the form of :
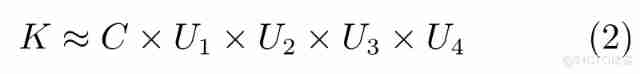
among ,K∈Rd×d×I×O Is the decomposed kernel tensor ,U1∈Rd×r1、U2∈Rd×r2、U3∈RI×r3、U4∈RO×r4 Is the factor matrix .CP The expression form of decomposition is :
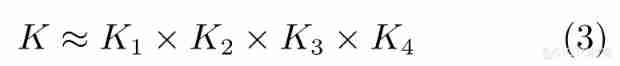
among ,K1∈Rd×r、K2∈Rd×r、K3∈RI×r、K4∈RO×r.CP Decomposition belongs to Tucker A special form of decomposition , Its decomposition process is simpler , However, the rank of the decomposition matrix r Is a NP Difficult problem , And it may involve the problem of decomposition stability . It is worth noting that , Because the fully connected layer can also be regarded as a two-dimensional tensor , Therefore, matrix singular value decomposition can be used (Singular value decomposition,SVD) Remove redundant information in the full connection layer , The decomposition expression is :

among ,W∈Rm×n Is the tensor to be decomposed ,U∈Rm×m and V∈Rn×n It's an orthogonal matrix ,S∈Rm×n It's a diagonal matrix . chart 3 It shows a W∈Rd×d×I×O The tensor is decomposed into a P∈RO×K Tensor and a 


Tensor decomposition has been used to accelerate the convolution process for a long time , The most typical example is the high-dimensional discrete cosine transform (Discrete cosine transform,DCT) Decompose into a series of one dimensions DCT Transform multiply , And decompose the wavelet system into the product of a series of one-dimensional wavelets [10].Rigamonti etc. [36] Based on the idea of dictionary learning , The proposed learning method of separated convolution kernel (Learning separable filters) The original convolution kernel can be represented by a low rank convolution kernel , Reduce the number of convolution cores required to reduce the computational burden . meanwhile , The author believes that there is no need to carefully design the convolution kernel structure when building the network , The optimal convolution kernel combination can be obtained by separating convolution kernel learning .Jaderberg etc. [37] A layer by layer decomposition method is proposed , Whenever a convolution kernel is decomposed into several first-order tensors , Then fix this convolution kernel and fine tune the remaining convolution kernels based on a reconstruction error standard , The results show that it can speed up the network in scene text recognition 4.5 Times and accuracy is only reduced 1%.Denton etc. [38] It is considered that most of the redundant parameters of convolutional neural network are located in the full connection layer , Therefore, singular value decomposition is mainly carried out for the fully connected layer , After decomposition, the network parameters can be reduced at most 13 times , At the same time, its running speed can be improved 2 ∼3 times .Lebedev etc. [39] Based on CP Decomposition of convolution kernel tensor decomposition method , The convolution kernel is decomposed into 4 A first-order convolution kernel tensor . about 36 Class ILSVRC Classified experiments , The method in CPU You can get 8.5 Double acceleration , Experimental results also show that tensor decomposition has regularization effect .Tai etc. [40] A new tensor decomposition algorithm with low rank constraint is proposed , The tensor decomposition of nonconvex optimization is transformed into convex optimization problem , Compared with similar methods, the speed is significantly increased .
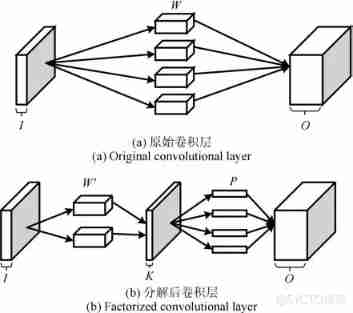
chart 3 Tensor decomposition process
Fig.3 Process of tensor factorization
Although the above method based on tensor decomposition can achieve certain results , However, they only compress and accelerate one or more layers of Networks , Lack of consideration for the whole network .Zhang etc. [41] An asymmetric tensor decomposition method is proposed to speed up the operation of the whole network , For example, one D×D The convolution kernel can be decomposed into 1×D、D×1 and 1×1 Isotensor . Besides , The literature [41] It is also proposed based on PCA Low rank selection method of cumulative energy and reconstruction error optimization method with nonlinearity , stay ImagNet Large networks trained on can be accelerated as a whole 4 times . And the literature [41] Different ,Kim etc. [42] A low rank selection method based on variable Bayesian and a method based on Tucker Global compression method of tensor decomposition . Due to the size of the model 、 The running time and energy consumption are greatly reduced , The network compressed by this method can be transplanted to mobile devices to run .Wang etc. [43] It is considered that network compression cannot only consider convolution kernel , At the same time, we should consider the huge characteristic map mapped by convolution kernel in the process of network operation . The literature [43] The redundant information in the characteristic graph is eliminated by using the cyclic matrix , Get the most essential features in the feature map , The convolution kernel is further reconstructed to match the compressed characteristic graph . The experimental results show that the literature [43] Although the method in has few parameters , But it has the same performance as the original network .Astrid etc. [44] A method based on Optimization CP Network compression method of decomposing all convolution layers , Fine tune the whole network after each decomposition of the single-layer network , Overcome due to CP The problem of network accuracy degradation caused by decomposition instability .
Tensor decomposition has a direct effect on the compression and acceleration of deep Networks , It can be used as an important supplement to the optimization design method of network structure . However, at present, most tensor decomposition methods decompose the network layer by layer , Lack of holistic consideration , It may lead to the loss of information between different hidden layers . Besides , Because it involves matrix decomposition operation , It will cause high cost of computing resources in the process of network training . Last , Because the network needs to be retrained to converge after each tensor decomposition , This further aggravates the complexity of network training .
3 Knowledge transfer
Knowledge transfer is a network structure optimization method belonging to transfer learning , Teacher network (Teacher networks) Knowledge of related fields is transferred to the student network (Student networks) To guide students' network training , Complete the compression and acceleration of the network . In a general way , Teacher network is often a single complex network or a collection of several networks , It has good performance and generalization ability , The student network has a smaller network size , Not fully trained yet . Consider using the knowledge of teachers' network itself or the knowledge learned through teachers' network to guide students' network training , Make the student network have the same performance as the teacher network , But the number of parameters is greatly reduced , It can also achieve the effect of network compression and acceleration .
Knowledge transfer is mainly composed of teachers' network acquisition and students' network training , In Teachers' network access , Due to the large scale of teacher network , It needs to be trained with a large number of tag data to obtain a high prediction accuracy . In the process of students' network training , First, input the unlabeled data into the teacher network for prediction , Then the predicted results and input data are synthesized into label data , Finally, these synthetic tag data are used as domain knowledge to guide students' network training . Because the student network is small , Therefore, only a small amount of tag data is needed to complete the training . The overall process of knowledge transfer is shown in the figure 4 Shown .
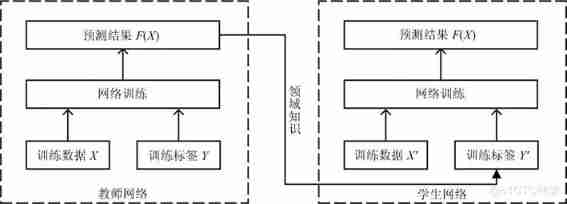
chart 4 Knowledge transfer process
Fig.4 Process of knowledge transfer
Bucila etc. [45] Firstly, a model compression method based on knowledge transfer is proposed , Train student networks through synthetic data to complete compression and acceleration . The specific steps are as follows: first, input the large unlabeled data set into the teacher network to obtain the corresponding labels , Obtain synthetic label data , Then train the student network on the artificial label data set , The experimental results show that the student network size is reduced 1 000 times , At the same time, the running speed is improved 1 000 times . The knowledge initially obtained from large complex networks can be based on softmax The function calculates the class probability label to represent , Compared with one-hot label , The category probability label contains the relevant approximation degree in the training sample , It can train students' network more effectively . However, most probability values of category probability labels pass softmax After the function, it tends to 0, Lost a lot of effective information .Ba etc. [46] Proposed by logits ( adopt softmax Input value before function , The mean for 0) To express the knowledge learned , It reveals the relative relationship between labels and the approximation between samples . And the literature [45] similar ,Ba etc. [46] Get the data set from the teacher network logits Labels as knowledge guide students' network training , stay TIMIT and CIFAR-10 The database can achieve the recognition accuracy equivalent to the depth network .Hinton etc. [47] Consider category probability labels and logits The labels are softmax Extreme output of layer , among T Respectively 1 Sum is infinite . Their proposed knowledge distillation (Knowledge distilling,KD) Use the right T value , It can produce an output with moderate category probability distribution ( It is called soft probability label (Soft probability labels)). Soft probability labels reveal the similarity between data structures , Contains a lot of useful information , Soft probability labels can be used to train student networks to simulate complex network sets .Romero etc. [48] Proposed FitNet It not only utilizes the output of the teacher network , At the same time, the hidden layer output of the teacher network is also transferred to the student network as knowledge . The student network trained in this way is deeper and narrower than the teacher network , Therefore, it has better nonlinear transformation ability .
Different from the previous knowledge transfer based on category probability labels ,Luo etc. [49] Use the high-level neuron output of the teacher network to express the domain knowledge that needs to be transferred . This method will not lose any information , But the student network can get a higher compression rate .Chen etc. [50] Preserve transformations based on functions (Function-preserving transformation) Proposed Net2Net It is an effective tool to accelerate the process of knowledge transfer , It can quickly migrate the useful information of the teacher network to a deeper ( Or wider ) Student network .Zagoruyko etc. [51] Learn from the idea of knowledge rectification , A method of knowledge transfer based on attention is proposed . They use the attention feature map that can provide visual related location information in the teacher's network to monitor the learning of students' Network , And from low 、 in 、 High three levels of attention transfer , It greatly improves the performance of deep convolutional neural networks such as residual Networks .Lucas etc. [52] A combination of Fisher The optimization method of pruning and knowledge transfer , First, a large number of saliency graphs are generated by using the pre trained high-performance network as domain knowledge , Then use the saliency map to train the network and use Fisher Pruning method eliminates redundant feature graphs , In the prediction of image saliency, the network operation can be accelerated up to 10 times .Yim etc. [53] Take the inner product matrix between the hidden layers of the teacher network as domain knowledge , It can not only guide students' network training faster and better , And it can also get better results in tasks different from the teacher network .Chen etc. [54] Combined with literature [47−48] Related methods , An end-to-end multi-target detection framework based on knowledge migration is proposed for the first time , It solves the problem of under fitting in the task of target detection , The accuracy and speed have been greatly improved .
The knowledge transfer method can directly accelerate the network operation without high hardware requirements , It greatly reduces the proportion of students learning unimportant information online , It is an effective method of network structure optimization . However, knowledge transfer requires researchers to determine the specific structure of student Networks , It puts forward higher requirements for the level of researchers . Besides , Current knowledge transfer methods only transfer the network output probability value as a kind of domain knowledge , The influence of teachers' network structure on students' network structure is not considered . Extract the internal structure knowledge of teacher network ( Like neurons ) And guide students' network training , It is possible to make the student network obtain higher performance .
4 Fine module design
Network pruning and thinning 、 Tensor decomposition 、 Methods such as knowledge migration are based on existing high-performance models , Reduce the time complexity and space complexity on the premise of ensuring the performance of the model . At present, there is still some work focused on designing efficient and fine modules , It can also achieve the purpose of optimizing the network structure . The network constructed based on these fine modules has the advantages of fast running 、 Less memory 、 Advantages of low energy consumption , Besides , Due to the modular network structure optimization method , The design and construction process of the network is greatly shortened . At present, the representative fine modules are Inception modular 、 Network in network and residual module , It is discussed and analyzed in detail in this section .
4.1 Inception modular
For how to design convolutional neural network with better performance , The current mainstream view is to expand the scale of the model by increasing the depth and width of the network . But this brings two unavoidable problems :1) As the network size increases , The training parameters of the network will also increase significantly , This will inevitably lead to fitting problems when the training data is insufficient ;2) The increase of network size and training parameters aggravates the problem that the network model occupies too much computing resources and memory resources , It will reduce the training speed , It is difficult to apply to practical engineering problems .
To solve the above problems ,Szegedy etc. [4] From net to net (Network in network,NiN)[55] To be inspired by , Put forward as shown in the figure 5 Shown Inception-v1 Network structure . Compared with traditional convolutional neural network 11×11、9×9 Convolution kernels of equal size are different ,Inception-v1 Massive parallel use 5×5、3×3 Convolution kernel , Effectively improve the width of the network , And introduce 1×1 The convolution kernel reduces the dimension of the obtained features .Inception-v1 The structure increases the depth and width of convolutional neural network , No additional training parameters are added . Besides , Connecting convolution kernels of different sizes in parallel can increase the diversity of feature extraction , And the introduction of 1×1 Convolution kernel accelerates the network operation .
Ioffe etc. [56] Think , The input distribution of each layer of convolutional neural network will change during training , This will reduce the training speed of the model . therefore , They are Inception-v1 On the basis of that, the paper puts forward Inception-v2 structure , Batch standardization is introduced (Batch normalization,BN). Batch standardization is generally used before activating functions , Its most important role is to solve the gradient problem in back propagation ( Including gradient disappearance and gradient explosion ). Besides , Batch standardization not only allows for greater learning rates , It also simplifies the initialization process of network parameters , Liberate people from the heavy work of adjusting participation . Last , Because batch standardization has regularization effect , In some cases, it can also reduce Dropout The needs of .
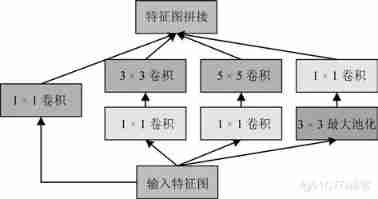
chart 5 Inception-v1 structure [4]
Fig.5 Inception-v1 module[4]
To further increase the network depth ,Szegedy etc. [57] Proposed Inception-v3 The Internet draws on VGGNet Convolution kernel decomposition idea , In addition to 7×7、5×5 The larger convolution kernel is decomposed into several continuous 3×3 Convolution kernel , Will also n×n The convolution kernel is asymmetrically decomposed into 1×n and n×1 Two continuous convolution kernels ( When n=7 when , The best effect ).Inception-v3 Auxiliary classifiers are also introduced (Auxiliary classifiers) To accelerate the convergence process of convolutional neural network training , Support Inception-v2 The view that batch standardization in has regularization effect . Through convolution kernel decomposition ,Inception-v3 It can not only improve the depth and width of the network , And effectively reduce the time complexity and space complexity . Besides ,Inception-v3 Speed up the training process and reduce over fitting , At the same time, it also strengthens the adaptability and nonlinear expression ability of the network to different dimensional characteristics . chart 6(a) It shows a 5×5 The convolution kernel of is decomposed into two continuous 3×3 Calculation process after convolution kernel of , Due to a 5×5 The convolution kernel has 5×5=25 Parameters , And two 3×3 The convolution kernel has only 3×3+3×3=18 Parameters , Therefore, the parameter quantity is reduced 28% The convolution effect is the same ; chart 6(b) It shows a 3×3 The convolution kernel is decomposed into a 1×3 Convolution kernel and a 3×1 Calculation process after convolution kernel , One 3×3 The convolution kernel has 3×3=9 Parameters , And the two decomposed convolution kernels have 1×3+3×1=6 Parameters , The number of parameters is reduced 33% The convolution effect is the same .
Szegedy etc. [58] take Inception Combination of structure and residual structure , It is found that the residual structure can greatly accelerate the training speed of the network , Proposed Inception-Resnet-v1 and Inception-Resnet-v2 Model in ImageNet On dataset Top-5 The error rate is reduced to 4.3% and 3.7%. They also proposed Stem、Inception-A、Inception-B、Inception-C、Reduction-A、Reduction-B And a series of network local structures , And with this structure Inception-v4 A network model , It greatly increases the network depth , Improved network performance , At the same time, it ensures that the number of network training parameters is within an acceptable range .
Chollet etc. [59] It is considered that the traditional convolution process can extract three-dimensional features from two-dimensional space and one-dimensional channel at the same time , and Inceptionv3 Partially separate space operation from channel operation , Make the training process easier and efficient . from Inception-v3 To be inspired by ,Chollet It is considered that the correlation between spatial dimension and channel dimension of characteristic graph in convolutional neural network can be completely decoupled , Based on this, they proposed a method different from general convolution (Regular convolution) Of Xception(Extremely inception) modular , And with this structure Xception Network structure .Xception The module is shown in the figure 7 Shown , First, the convolution operation is carried out by using the convolution check input characteristic graph , For each channel of the output characteristic graph, a convolution kernel is used for convolution , Finally, all the outputs are spliced together to get a new feature map .Xception The training parameter ratio of the network Inception-v3 Fewer networks , But with Inception-v3 The network has considerable recognition accuracy and training speed , And it has better performance on larger data sets .
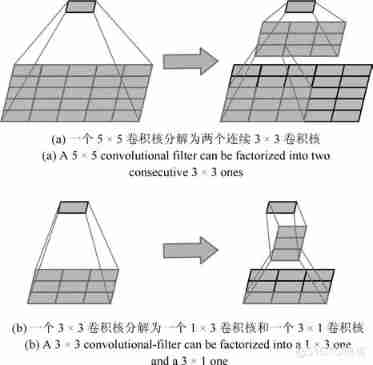
chart 6 Convolution kernel decomposition diagram [57]
Fig.6 Process of convolutional filter factorization[57]
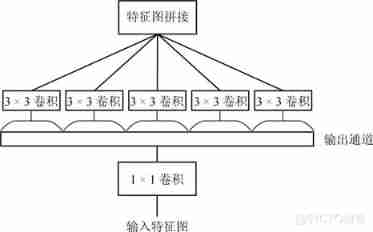
chart 7 Xception modular [59]
Fig.7 Xception module[59]
Inception Structure from Inception-v1 Develop to Xception, Always strive to increase the size of Convolutional Neural Networks ( Including depth and width ) To improve the nonlinear expression ability of the model . In order to avoid the decrease of model training speed caused by the increase of training parameters 、 Easy to fit and other problems ,Inception Structure proposed batch standardization 、 Convolution kernel decomposition and other methods to optimize the deeper network structure , Compared with the original network, the deepened network parameters remain unchanged or even less , The trained network model has achieved leading results in various test data sets .Inception The success of has further proved that increasing network size is a reliable way to improve network performance , This is also a development direction of convolutional neural network in the future .
4.2 Net in the net (Network in network)
The convolution kernel of traditional convolution neural network is a generalized linear model (Generalized linear model,GLM), When the potential feature of the training sample is linear separability, it can obtain high-dimensional abstract features with strong expression ability . But in many mission scenarios , The obtained sample features are highly nonlinear , Using traditional convolution kernel can not effectively extract abstract features closer to the essence .Lin etc. [55] A nonlinear structure different from the generalized linear model is proposed —Mlpconv, That is to add a multilayer perceptron behind the convolution kernel (Multilayer perceptron,MLP). Because multilayer perceptron can fit any function , therefore Mlpconv The structure enhances the feature recognition ability and nonlinear expression ability of the network to the local perception field . By stacking Mlpconv The network built by layer is vividly called network in Network (Network in network,NiN), Pictured 8 Shown .
Net in net is not only used Mlpconv The structure replaces the generalized linear model to deal with more complex nonlinear problems , And the global mean pooling is used to replace the full connection layer to reduce the training parameters , Avoid the fitting problem in the training process . It is worth noting that ,Mlpconv The fully connected layer in the layer can be regarded as a 1×1 Convolution kernel , Later, it was widely used, including Inception In various networks including 1×1 Convolution kernels are inspired by the net in the net . On this basis , A large number of improvement measures for the network structure in the network have emerged .Chang etc. [60] Think Mlpconv Layer. ReLU Activating the function will cause the gradient to disappear , Therefore, it is proposed to use Maxout replace ReLU To solve this problem , This network structure is called Maxout network in network (MIN).Pang etc. [61] Think because MLP It also includes a fully connected network , This will inevitably lead to a significant increase in training parameters , Therefore, a sparse connection is proposed MLP Replace the original MLP, And use separate convolution in the channel dimension (Unshared convolution) And use shared convolution in the spatial dimension (Shared convolution), This network structure is called convolution in convolution (Convolution in convolution,CiC).Han etc. [62] Proposed MPNIN (Mlpconv-wise supervised pre-training network in network) The training parameters of each layer of the network model are initialized by the supervised preprocessing method , Combined with batch standardization and network in network structure, a deeper convolutional neural network can be trained .
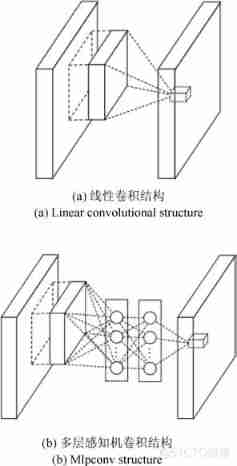
chart 8 Linear convolution structure and multilayer perceptron convolution structure [55]
Fig.8 Linear convolutional structure and Mlpconv structure[55]
Network in network structure has been widely concerned and studied since it was proposed , Include GoogLeNet、ResNet Many convolutional neural networks, including, have learned from this structure . With the traditional GLM Compared with convolution kernel , Net in net Mlpconv Layer can realize cross channel feature interaction and integration , Developed from this 1×1 Convolution kernel can also realize the function of feature dimension reduction and dimension increase , The network model can extract more abstract features to solve complex nonlinear problems , It can also train deeper networks and keep the training parameters in an acceptable range . It is worth noting that , because Mlpconv The structure introduces an additional multi-layer perceptron , It may reduce the running speed of the network , Improving this will be a direction of future research .
4.3 Residual module
As convolutional neural network gradually develops to a deeper level , The network will face the problem of degradation rather than over fitting , Specifically, the network performance is no longer improved with the increase of depth , Even when the network depth is further increased, the performance decreases rapidly , At this time, a method called bypass connection is introduced (Bypassing connection) Structural optimization technology can effectively solve this problem .Srivastava etc. [63] From the long-term and short-term memory model [64] (Long short-term memory,LSTM) To be inspired by , Introduce learnable threshold mechanism (Learned gating mechanism) To adjust the information transmission path in the network , Allow data to spread across multiple networks , This model is vividly called high-speed network (Highway network). The bypass connection enables the gradient in back propagation to propagate across one or more layers , It will not spread or even disappear in the layer by layer operation , In using the random gradient descent method (Stochastic gradient descent,SGD) When training the model, we avoid the flat network (Plain network) Gradient disappearance phenomenon that is easy to appear in . Introduction of bypass connection , Breaking through the depth, reaching 40 Layer time network will face the limitation of degradation problem , It further promotes the increase of network depth [65].
He etc. [5] Proposed residual network (Residual network,ResNet) And Highway network similar , It also allows input information to spread across multiple hidden layers . The difference is that the threshold mechanism of residual network is no longer learnable , That is, always keep the information unblocked , This greatly reduces the network complexity , It accelerates the network training process , At the same time, it breaks through the depth limit caused by network degradation . The residual module is shown in the figure 9 Shown , The input of the residual module is defined as X, Output is defined as H(X)= F(X)+X, The residual is defined as F(X), In the training process, network learning residual F(X), This is better than direct learning output H(X) It's easier .
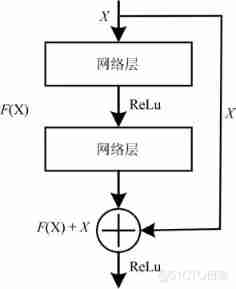
chart 9 Residual module [5]
Fig.9 Residual module[5]
The proposal of residual network marks the development of convolutional neural network to a new stage , Then there are a lot of studies to improve the residual structure .Huang etc. [66] Using random depth method (Stochastic depth) Randomly eliminate in the training process , Some hidden layers and connect the rest with residual structure , Train one 1 202 Very deep residual network of layer , At the same time, it shows that the original residual network contains a large number of redundant structures .He etc. [67] Found pre activation function (Preactivation) It not only makes model optimization easier , and , To some extent, it alleviates over fitting . The author trained a 1 001 Layer residual network , stay CIFAR-10 The error rate on the dataset is reduced to 4.62%.Larsson etc. [65] Proposed fractal network (Fractal-Net) Further expand the residual structure in width and depth , And use a method called Drop-path Methods to optimize network training , The accuracy of image classification test exceeds that of residual network .Xie etc. [68] Proposed ResNeXt Learn from it Inception The idea of modules , Further expand the network by increasing the number of bypass connections , Improve the recognition accuracy without increasing the complexity of the network , It also reduces the number of super parameters .
The literature [69] It is considered that the residual network is only a combination of several shallow Networks , Its width is more important than its depth , Train more than 50 Layer network is unnecessary , Therefore, there are a lot of research work to optimize the structure of residual network from the network width .Zagoruyko etc. [70] Think ResNet Features cannot be fully reused during training (Feature reuse), Specifically, gradient back propagation cannot flow through each residual module (Residual block), Only a few residual modules can learn useful feature representation . The wide residual network proposed by the author (Wide residual network,WRN) By increasing network width and reducing network depth , Compared with the residual network, the training speed is improved 2 times , But the number of network layers has decreased 50 times .Targ etc. [71] A generalized residual network is proposed, which combines residual network and standard convolutional neural network in parallel , While retaining the effective feature expression, the invalid information is eliminated , Improve the expression ability of the network , stay CIFAR-100 The effect is remarkable on the data set .Zhang etc. [72] Add additional bypass connections to the residual network , By increasing the width to improve the learning ability of the network , Proposed Residual networks of residual networks (RoR) It can be used as a general module for network construction .Abdi etc. [73] Experiments support the hypothesis that the residual network is the fusion of several shallow Networks , The model proposed by the author enhances the expression ability of the model by increasing the number of residual functions in the residual module , The obtained multi residual network is in CIFAR-10 and CIFAR-100 The accuracy of classification has been greatly improved .
4.4 Other fine modules
In the design space exploration of network structure , There is still a lot of work on fine module design , A series of achievements have been made . To reduce the training parameters of the whole connection layer , The literature [55] First, we propose to pool the global mean (Global average pooling,GAP) Replace the full connection layer , It is equivalent to regularizing the whole network structure to prevent over fitting . Global mean pooling establishes a connection between the characteristic graph and the output category label , It is more interpretable than the full connection layer , Then the network in the network and GoogLeNet The performance is improved by using this structure .
Huang etc. [74] It is believed that the success of very deep network comes from the introduction of bypass connection , They propose dense modules (Dense block) There is a direct connection between any two layers of network . For any network layer , Its input comes from the output of all the previous network layers , And its output should be used as the input of all subsequent network layers . This dense connection improves the flow of information and gradients in the network , It can regularize the network , Avoid the over fitting problem of training on small data sets . Another advantage of dense connections is that they allow feature reuse , Trained DenseNet It has a compact structure 、 The advantage of high precision . Zhang Ting et al [75] The proposed cross connected convolutional neural network allows the second pooling layer to be directly connected to the full connection layer across two layers , stay 10 The effect of gender classification on personal face data sets is no less than that of traditional networks . Li Yong et al [76] take LeNet-5 The two pooling layers of the network are combined with the full connection layer , The constructed classifier combines the low-level features and high-level features extracted from the network structure , It has achieved good results in facial expression recognition .
Howard etc. [77] Proposed MobileNet The traditional convolution process is decomposed into deeply separable convolution (Depthwise convolution) And point by point convolution (Pointwise convolution) Two steps , A lot of compression has been done in the size of the model and the amount of calculation , The lightweight network thus constructed can run on mobile embedded devices .Sandler etc. [78] Combine the residual module with the depth separable convolution , A reverse residual module with linear bottleneck is proposed (Inverted residual with linear bottleneck), Thus constructed MobileNet v2 Better than... In speed and accuracy MobileNet.Zhang etc. [79] stay MobileNet Based on point by point group convolution (Pointwise group convolution) Mix with the channel (Channel shuffle) Of ShuffleNet, In image classification and target detection tasks have been greatly accelerated .
5 Conclusion
With the rapid development of hardware conditions and the significant growth of data set size , Deep convolution neural network has become a computer vision 、 speech recognition 、 Mainstream methods in natural language processing and other research fields . In particular , The deeper network layers enhance the nonlinear fitting ability of the model , At the same time, large-scale data enhances the generalization ability of the model , The higher level of hardware facilities ensure the computing power and storage requirements required for the operation of the model . Deep convolution neural network has proved its strong ability of feature learning and expression in many fields , However, the high time complexity and space complexity restrict its implementation and application in a broader field . On the time dimension , Large complex networks have a huge amount of computation , In the graphic processing unit (Graphic processing unit,GPU) With the support of accelerated Computing , It still cannot meet the requirements of some strong real-time scenes such as autonomous vehicle . On the spatial dimension , With the increasing scale of the model, especially the sharp increase of network depth , It puts forward higher requirements for the storage of models , This restricts the application of deep convolutional neural networks in mobile phones 、 Applications in resource constrained environments such as embedded devices .
In order to speed up the promotion and application of deep learning technology represented by convolutional neural network , Further strengthen security 、 Mobile devices 、 Advantages of autonomous driving and other industries , Academia and industry have carried out a lot of research on the optimization of its structure . At present, the commonly used network structure optimization techniques include network pruning and thinning 、 Tensor decomposition 、 Knowledge transfer and fine module design , The first three methods are usually improved and innovated on the basis of existing high-performance models , Reduce the complexity of the model and calculation as much as possible without damaging the accuracy or even improving it . The fine module design method starts from the perspective of network construction , Creatively design efficient modules to improve network performance , Fundamentally solve the problem of high time complexity and space complexity faced by deep convolution neural network . The author collated the research results in recent years , According to my own understanding, the following difficult problems and development trends in this field are summarized :
1) Network pruning and thinning can stably optimize and adjust the network structure , Compress the network size at the cost of small accuracy loss , It is the most widely used network structure optimization design method . At present, most methods are to eliminate redundant connections or neurons in the network , This low-level pruning is unstructured (Non-structural) risk , Non regularization during computer operation (Irregular) Instead, memory access will hinder the further acceleration of the network . Some special software and hardware measures can alleviate this problem , However, it will bring additional costs to the deployment of the model . On the other hand , Although some structured pruning methods for convolution kernel and convolution graph can obtain hardware friendly Networks , stay CPU and GPU The upper speed has increased significantly , However, due to the pruning convolution kernel and convolution channel, the input of the next hidden layer will be seriously affected , There may be a serious loss of network accuracy .
2) At present, the mainstream fine module design method still depends on the designer's engineering experience and theoretical basis , A large number of factors should be considered in the process of network construction , Such as convolution kernel size 、 Number of full connection layers 、 Super parameters such as the number of pooling layers (Hyper parameter). Different choices may have completely different effects on the final performance of the network , A large number of experiments are needed to demonstrate the advantages and disadvantages of different parameters , Making the network structure design cost a lot of manpower and material resources , It is not conducive to the rapid deployment and application of the depth model . therefore , Studying how to automatically design the network is helpful to the design space exploration of convolutional neural network (Design space exploration,DSE), It plays an important role in accelerating the process of network design and promoting deep learning to be applied in Engineering .
3) Evaluation index of network structure optimization design . At present, the structural optimization design of deep convolution neural network mainly focuses on the accuracy 、 The elapsed time 、 Evaluation of model size and other aspects , However, using more comprehensive evaluation indicators is of great benefit to discover the advantages and disadvantages of different networks . In addition to accuracy 、 The elapsed time 、 Traditional indicators such as model size , It is necessary to multiply and add (Multiply-and-accumulate) The amount of operation 、 Derivation time 、 Data throughput 、 Hardware energy consumption and other indicators are included in the evaluation system , This provides more complete information for evaluating the optimization model from different aspects , It also helps to solve the problem that different network performance evaluation indicators are not unified .
4) in the past , The structure optimization of deep convolution neural network focuses more on the design and implementation of Algorithm , The specific deployment platform and hardware facilities of the model are not considered . Considering that the hardware conditions still restrict the deployment of the depth model in mobile phones 、 robot 、 Main factors in resource constrained scenarios such as autonomous driving , If we take into account the optimization and design of network model and hardware facilities , Match the algorithm with the hardware , It can not only further improve data throughput and running speed , It can also reduce network size and energy consumption . therefore , Designing a hardware friendly depth model will help accelerate the engineering implementation of deep learning , It is also the key research direction of network structure optimization .
5) The network structure optimization methods summarized in this paper have different emphases and limitations , Among them, network pruning and thinning methods can obtain a larger compression ratio , At the same time, it has little impact on the accuracy of the network , It is more applicable in the scenario where the model needs to run stably . Tensor decomposition can greatly accelerate the running process of the model , And the end-to-end layer by layer optimization also makes it easy to implement , However, this method can not compress the scale of the model well , And when the convolution kernel size is small, the acceleration effect is not obvious . Knowledge transfer method can use the domain knowledge of teachers' network to guide the training of students' Network , It has high use value in small sample environment . meanwhile , Both knowledge transfer and fine module design face the problem of how to construct the network structure , The designer is required to have a high theoretical basis and engineering experience , Compared with other methods, its debugging cycle is longer . therefore , When using network structure optimization technology, we should consider the actual situation , Comprehensively apply the above methods to compress and accelerate the network .
6) Migration application of deep neural network structure optimization . This paper analyzes the current challenges and problems of Convolutional Neural Networks , And the main methods in the field of convolutional neural network structure optimization are discussed 、 Thought and Its Application . Due to other mainstream deep Networks ( Such as cyclic neural network 、 Generative antagonistic network ) It also faces the large scale of the model 、 The problem of slow running speed , Therefore, using the idea of convolutional neural network structure optimization to optimize its model is an effective solution . Besides , At present, many optimization methods are generally aimed at image classification , If it is applied to target detection 、 Semantic segmentation and other fields should also achieve better results .

Our service type Open Courses
Artificial intelligence 、 big data 、 The embedded
Internal training courses
General internal training 、 Customized in-house training
Project consultation
Technical route design 、 Algorithm design and implementation ( The image processing 、 natural language processing 、 speech recognition )

边栏推荐
- [tutorial] yolov5_ DeepSort_ The whole process of pytoch target tracking and detection
- Solve the error of JSON module in PHP compilation and installation under CentOS 6.3
- Force button brush question 01 (reverse linked list + sliding window +lru cache mechanism)
- Temperature control system based on max31865
- Shell 编程基础
- Book of night sky 53 "stone soup" of Apache open source community
- Rearrange array
- MySQL学习笔记——数据类型(2)
- Data Lake Governance: advantages, challenges and entry
- Unity script API - time class
猜你喜欢
Will the memory of ParticleSystem be affected by maxparticles

這幾年爆火的智能物聯網(AIoT),到底前景如何?
. Net applications consider x64 generation
What is the catalog of SAP commerce cloud

Unity animation day05

Live broadcast preview | PostgreSQL kernel Interpretation Series II: PostgreSQL architecture
lnx 高效搜索引擎、FastDeploy 推理部署工具箱、AI前沿论文 | ShowMeAI资讯日报 #07.04

Book of night sky 53 "stone soup" of Apache open source community

Force button brush question 01 (reverse linked list + sliding window +lru cache mechanism)
Redis' optimistic lock and pessimistic lock for solving transaction conflicts
随机推荐
Explore mongodb - mongodb compass installation, configuration and usage introduction | mongodb GUI
Logstash ~ detailed explanation of logstash configuration (logstash.yml)
Unity脚本API—Component组件
Go deep into the details of deconstruction and assignment of several data types in JS
Data Lake Governance: advantages, challenges and entry
MYSQL索引优化
Nine CIO trends and priorities in 2022
数据库函数的用法「建议收藏」
深入JS中几种数据类型的解构赋值细节
.Net 应用考虑x64生成
MySQL learning notes - data type (numeric type)
Solve the error of JSON module in PHP compilation and installation under CentOS 6.3
每周招聘|高级DBA年薪49+,机会越多,成功越近!
MySQL learning notes - data type (2)
Unity script API - time class
%F format character
Variable cannot have type 'void'
Summer Review, we must avoid stepping on these holes!
. Net applications consider x64 generation
.Net之延迟队列