当前位置:网站首页>Data dimensionality reduction factor analysis
Data dimensionality reduction factor analysis
2022-07-02 19:19:00 【Lu 727】
1、 effect
Factor analysis is based on the idea of dimension reduction , In the case of no or less loss of original data information as far as possible , The complex variables are aggregated into a few independent common factors , These common factors can reflect the main information of many variables , While reducing the number of variables , It also reflects the internal relationship between variables . Generally, factor analysis has three functions : One is to reduce the dimension of factors , Second, calculate the factor weight , Third, calculate the weighted calculation factor to summarize the comprehensive score .
2、 Input / output description
Input :2 Two or more quantitative variables ( Assuming that N A variable ).
Output : The minimum dimension reduction is 1 dimension ( A variable , Generally used for comprehensive evaluation ), Maximum dimension reduction N A variable ( Generally used for data desensitization ), At the same time, the composition weight of each variable after dimension reduction can be obtained , Used to represent the data retention of the original variable .
3、 Case example
According to the region 2021 Per capita in GDP、 Per capita disposable income and other indicators , Quantitatively evaluate the ranking of economic development level of multiple provinces, cities and regions or the weight of each index

4、 Modeling steps
Factor analysis is a method of reducing multidimensional variables to a few common factors according to the correlation between variables , Then the multidimensional variable statistical analysis method is analyzed . The basic idea is to divide the original variables into two parts : One part is the linear combination of common factors , Condensing represents most of the information in the original variables ; The other part is the special factor which has nothing to do with the common factor , It reflects the linear combination of common factors and original variables The gap between .p Dimension variable ![x =[x_{1} ,...,x_{i},...,x_{p}]^{T}](http://img.inotgo.com/imagesLocal/202207/02/202207021754111386_6.gif) The factor analysis model is :
The factor analysis model is :

Or as

among f =[f 1 ,f 2 ,…,f m ]T namely by carry take Of Male common because Son towards The amount , generation surface 了 primary beginning change The amount in No can straight Pick up view measuring but customer view save stay Of m (m <p) Three mutually independent common influencing factors ;A=( ) Is the factor load matrix , matrix Elements aik by change The amount x i Yes Male common because Son fk The load of , It reflects the correlation coefficient between the two , The greater the absolute value , The more relevant ;
) Is the factor load matrix , matrix Elements aik by change The amount x i Yes Male common because Son fk The load of , It reflects the correlation coefficient between the two , The greater the absolute value , The more relevant ;
For multidimensional variables x The key to establish the factor analysis model is to solve the factor load matrix A And the common factor vector f , The steps are as follows :
1. In order to eliminate the influence of different dimensions of variables , To contain n individual p Samples of dimensional variables X=[x1 ,x2 ,…,xn ] Standardize . After standardization , The mean value of each variable is 0, The variance of 1. For the convenience of expression, the standardized variables are still used X Express , Its elements are :

2. Find the covariance matrix of the sample S, Its elements are :

3. For the sample covariance matrix S Do eigenvalue decomposition , obtain p Eigenvalues λ1 ≥λ2≥…≥λp ≥0, The corresponding eigenvalue vector is γ1 , γ2 ,…,γp , Before taking it m The eigenvector of the largest eigenvalue estimates the factor load matrix . At the same time, in order to ensure the variance of each component of the common factor vector by 1, Divide it by the corresponding standard deviation λj . The corresponding eigenvector in the factor load matrix γj Then multiply by λj . Therefore, the factor load matrix

The parameter m Determined by the cumulative variance contribution rate of common factors , namely

It is generally believed , At present m The cumulative variance contribution rate of common factors exceeds 90% when , It can be considered that before m The linear combination of common factors can basically restore the original variable information .
Common factor vector f , That is, the specific score of the original variable on the common factor can be estimated by regression method

Go through the above steps , After obtaining the factor load matrix and the common factor vector , Then we can get that the special factor vector of the original variable is :
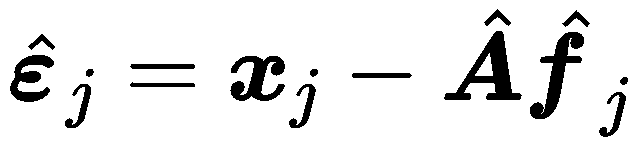
边栏推荐
- Thread application instance
- Gamefi链游系统开发(NFT链游开发功能)丨NFT链游系统开发(Gamefi链游开发源码)
- 【测试开发】软件测试—概念篇
- PyTorch函数中的__call__和forward函数
- Golang并发编程——goroutine、channel、sync
- Date tool class (updated from time to time)
- ORA-01455: converting column overflows integer datatype
- NPOI导出Excel2007
- "Patient's family, please come here" reading notes
- C file input operation
猜你喜欢

聊聊电商系统中红包活动设计

Stm32g0 USB DFU upgrade verification error -2

codeforces每日5题(均1700)-第四天

How can retail enterprises open the second growth curve under the full link digital transformation

How to play when you travel to Bangkok for the first time? Please keep this money saving strategy
![[0701] [paper reading] allowing data imbalance issue with perforated input during influence](/img/c7/9b7dc4b4bda4ecfe07aec1367fe059.png)
[0701] [paper reading] allowing data imbalance issue with perforated input during influence
使用CLion编译OGLPG-9th-Edition源码
![[test development] software testing - concept](/img/24/9ee885d46f7200ae7449957ca96b9d.png)
[test development] software testing - concept

juypter notebook 修改默认打开文件夹以及默认浏览器

Processing strategy of message queue message loss and repeated message sending
随机推荐
2022软件工程期末考试 回忆版
R language uses the lsnofunction function function of epidisplay package to list all objects in the current space, except user-defined function objects
拦截器与过滤器的区别
R语言使用epiDisplay包的lsNoFunction函数列出当前空间中的所有对象、除了用户自定义的函数对象
性能测试如何创造业务价值
Golang concurrent programming goroutine, channel, sync
【JVM调优实战100例】01——JVM的介绍与程序计数器
移动机器人路径规划:人工势场法[通俗易懂]
数据降维——因子分析
R语言ggplot2可视化分面图(facet):gganimate包基于transition_time函数创建动态散点图动画(gif)
Excel查找一列中的相同值,删除该行或替换为空值
为什么要做企业固定资产管理系统,企业如何加强固定资产管理
R language dplyr package filter function filters dataframe data. If the name of the data column (variable) to be filtered contains quotation marks, you need to use!! SYM syntax processing, otherwise n
R language uses lrtest function of epidisplay package to perform likelihood ratio test on multiple GLM models (logisti regression). Compare whether the performance of the two models is different, and
聊聊电商系统中红包活动设计
"Patient's family, please come here" reading notes
Excel如何进行隔行复制粘贴
Stm32g0 USB DFU upgrade verification error -2
metric_logger小解
Crypto usage in nodejs