> Java 與 C++ 之間有一堵由記憶體動態分配和垃圾收集技術所圍成的高牆 ---《深入理解Java虛擬機器》 我們知道手動管理記憶體意味著自由、精細化地掌控,但是卻極度依賴於開發人員的水平和細心程度。 如果使用完了忘記釋放記憶體空間就會發生記憶體洩露,再如釋放錯了記憶體空間或者使用了懸垂指標則會發生無法預知的問題。 這時候 Java 帶著 GC 來了(GC,Garbage Collection 垃圾收集,早於 Java 提出),將記憶體的管理交給 GC 來做,減輕了程式設計師程式設計的負擔,提升了開發效率。 所以並不是用 Java 就不需要記憶體管理了,只是因為 GC 在替我們負重前行。 但是 GC 並不是那麼萬能的,不同場景適用不同的 GC 演算法,需要設定不同的引數,所以我們不能就這樣撒手不管了,只有深入地理解它才能用好它。 關於 GC 內容相信很多人都有所瞭解。我最早得知有關 GC 的知識是來自《深入理解Java虛擬機器》,**但是有關 GC 的內容單看這本書是不夠的。** 當時我以為我懂很多了,後來經過了一番教育之後才知道啥叫無知者無畏。  而且過了一段時間很多有關 GC 的內容都說不上來了,其實也有很多同學反映有些知識學了就忘,有些內容當時是理解的,過一段時間啥都不記得了。 大部分情況是因為這塊內容在腦海中**沒有形成體系,沒有搞懂前因後果,沒有把一些知識串起來**。 近期我整理了下 GC 相關的知識點,想由點及面展開有關 GC 的內容,順帶理一理自己的思路,所以輸出了這篇文章,希望對你有所幫助。 有關 GC 的內容其實有很多,但是對於我們這種一般開發而言是不需要太深入的,所以我就挑選了一些我認為重要的整理出來,本來還有一些原始碼的我也刪了,感覺沒必要,重要的是在概念上理清。 本來還打算分析有關 JVM 的各垃圾回收器,但是文章太長了,所以分兩篇寫,下篇再發。 本篇整理的 GC 內容不限於 JVM 但大體上還是偏 JVM,如果講具體的實現預設指的是 HotSpot。 ## 正文 首先我們知道根據 「Java虛擬機器規範」,Java 虛擬機器執行時資料區分為程式計數器、虛擬機器棧、本地方法棧、堆、方法區。 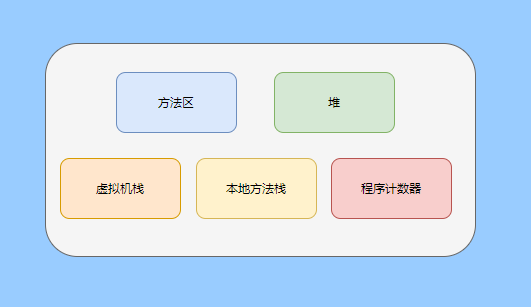 而程式計數器、虛擬機器棧、本地方法棧這 3 個區域是執行緒私有的,會隨執行緒消亡而自動回收,所以不需要管理。 因此**垃圾收集只需要關注堆和方法區。** 而方法區的回收,往往價效比較低,因為判斷可以回收的條件比較苛刻。 比如類的解除安裝需要此類的所有例項都已經被回收,包括子類。然後需要載入的類載入器也被回收,對應的類物件沒有被引用這才允許被回收。 就類載入器這一條來說,除非像特意設計過的 OSGI 等可以替換類載入器的場景,不然基本上回收不了。 而垃圾收集回報率高的是堆中記憶體的回收,因此我們重點關注**堆的垃圾收集**。 ## 如何判斷物件已成垃圾? 既然是垃圾收集,我們得先判斷哪些物件是垃圾,然後再看看何時清理,如何清理。 常見的垃圾回收策略分為兩種:一種是直接回收,即引用計數;另一種是間接回收,即追蹤式回收(可達性分析)。 大家也都知道引用計數有個致命的缺陷-**迴圈引用**,所以 Java 用了可達性分析。 **那為什麼有明顯缺陷的計數引用還是有很多語言採用了呢?** 比如 CPython ,由此看來引用計數還是有點用的,所以咱們就先來盤一下引用計數。 ## 引用計數 引用計數其實就是為每一個記憶體單元設定一個計數器,當被引用的時候計數器加一,當計數器減少為 0 的時候就意味著這個單元再也無法被引用了,所以可以立即釋放記憶體。 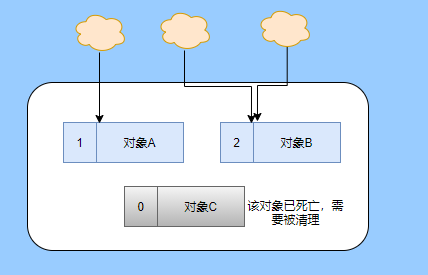 如上圖所示,雲朵代表引用,此時物件 A 有 1 個引用,因此計數器的值為 1。 物件 B 有兩個外部引用,所以計數器的值為 2,而物件 C 沒有被引用,所以說明這個物件是垃圾,因此可以立即釋放記憶體。 由此可以知曉引用計數需要**佔據額外的儲存空間**,如果本身的記憶體單元較小則計數器佔用的空間就會變得明顯。 其次引用計數的記憶體釋放等於把這個**開銷平攤到應用的日常執行中**,因為在計數為 0 的那一刻,就是釋放的記憶體的時刻,這其實對於記憶體敏感的場景很適用。 如果是可達性分析的回收,那些成為垃圾的物件不會立馬清除,需要等待下一次 GC 才會被清除。 引用計數相對而言概念比較簡單,不過缺陷就是上面提到的迴圈引用。 ## 那像 CPython 是如何解決迴圈引用的問題呢? 首先我們知道像整型、字串內部是不會引用其他物件的,所以不存在迴圈引用的問題,因此使用引用計數並沒有問題。 那像 List、dictionaries、instances 這類容器物件就有可能產生迴圈依賴的問題,因此 Python 在引用計數的基礎之上又引入了標記-清除來做備份處理。 但是具體的做法又和傳統的標記-清除不一樣,**它採取的是找不可達的物件,而不是可達的物件。** Python 使用雙向連結串列來連結容器物件,當一個容器物件被建立時,它被插入到這個連結串列中,當它被刪除時則移除。 然後在容器物件上還會新增一個欄位 gc_refs,現在咱們再來看看是如何處理迴圈引用的: 1. 對每個容器物件,將 gc_refs 設定為該物件的引用計數。 2. 對每個容器物件,查詢它所引用的容器物件,並減少找到的被引用的容器物件的 gc_refs 欄位。 3. 將此時 gc_refs 大於 0 的容器物件移動到不同的集合中,因為 gc_refs 大於 0 說明有物件外部引用它,因此不能釋放這些物件。 4. 然後找出 gc_refs 大於 0 的容器物件所引用的物件,它們也不能被清除。 5. 最後剩下的物件說明僅由該連結串列中的物件引用,沒有外部引用,所以是垃圾可以清除。 具體如下圖示例,A 和 B 物件迴圈引用, C 物件引用了 D 物件。 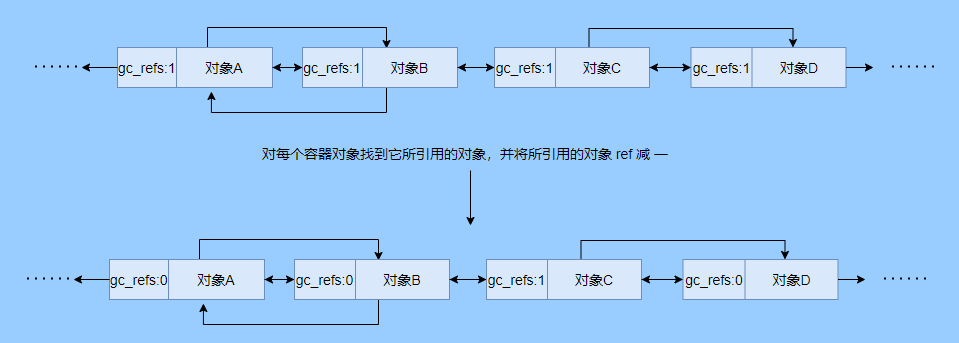 為了讓圖片更加清晰,我把步驟分開截圖了,上圖是 1-2 步驟,下圖是 3-4 步驟。 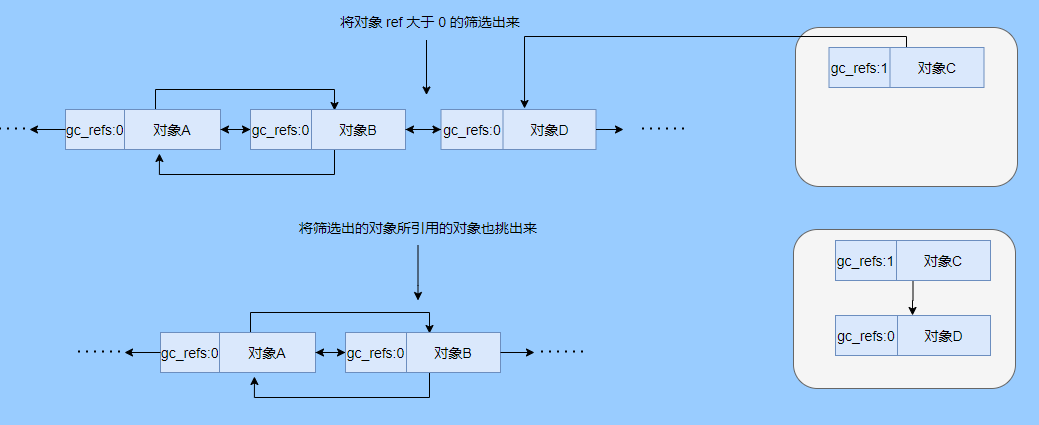 最終迴圈引用的 A 和 B 都能被清理,但是天下沒有免費的午餐,最大的開銷之一是**每個容器物件需要額外欄位。** 還有**維護容器連結串列的開銷**。根據 pybench,這個開銷佔了**大約 4% 的減速**。 至此我們知曉了引用計數的優點就是實現簡單,並且記憶體清理及時,缺點就是無法處理迴圈引用,不過可以結合標記-清除等方案來兜底,保證垃圾回收的完整性。 **所以 Python 沒有解決引用計數的迴圈引用問題,只是結合了非傳統的標記-清除方案來兜底,算是曲線救國。**  其實**極端情況下引用計數也不會那麼及時**,你想假如現在有一個物件引用了另一個物件,而另一個物件又引用了另一個,依次引用下去。 那麼當第一個物件要被回收的時候,就會引發連鎖回收反應,物件很多的話這個延時就凸顯出來了。 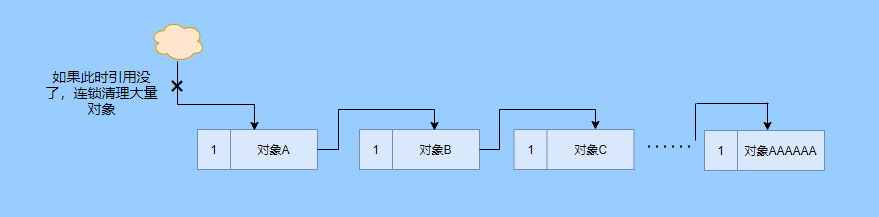 ## 可達性分析 可達性分析其實就是利用標記-清除(mark-sweep),就是**標記可達物件,清除不可達物件**。至於用什麼方式清,清了之後要不要整理這都是後話。 標記-清除具體的做法是定期或者記憶體不足時進行垃圾回收,從根引用(GC Roots)開始遍歷掃描,將所有掃描到的物件標記為可達,然後將所有不可達的物件回收了。 所謂的根引用包括全域性變數、棧上引用、暫存器上的等。 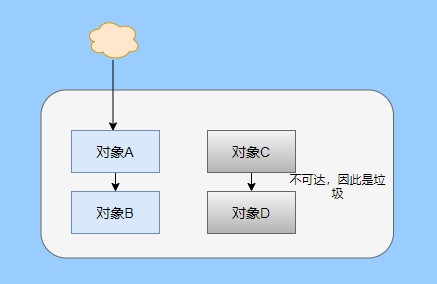 看到這裡大家不知道是否有點感覺,我們會在記憶體不足的時候進行 GC,而記憶體不足時也是物件最多時,物件最多因此需要掃描標記的時間也長。 所以標記-清除等於把垃圾積累起來,然後再一次性清除,這樣就會在垃圾回收時消耗大量資源,影響應用的正常執行。 **所以才會有分代式垃圾回收和僅先標記根節點直達的物件再併發 tracing 的手段。** 但這也只能減輕無法根除。 我認為這是標記-清除和引用計數的思想上最大的差別,**一個攢著處理,一個把這種消耗平攤在應用的日常執行中。** 而不論標記-清楚還是引用計數,其實都只關心引用型別,像一些整型啥的就不需要管。 所以 JVM 還需要判斷**棧上的資料是什麼型別**,這裡又可以分為保守式 GC、半保守式 GC、和準確式 GC。 ### 保守式 GC 保守式 GC 指的是 JVM 不會記錄資料的型別,**也就是無法區分記憶體上的某個位置的資料到底是引用型別還是非引用型別。** 因此只能靠一些條件來猜測是否有指標指向。比如在棧上掃描的時候根據所在地址是否在 GC 堆的上下界之內,是否位元組對齊等手段來判斷這個是不是指向 GC 堆中的指標。 之所以稱之為保守式 GC 是因為不符合猜測條件的肯定不是指向 GC 堆中的指標,因此那塊記憶體沒有被引用,而符合的卻不一定是指標,所以是保守的猜測。 我再畫一張圖來解釋一下,看了圖之後應該就很清晰了。 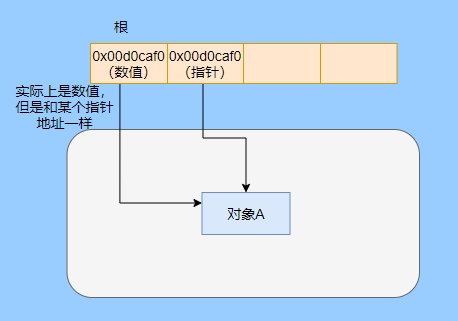 前面我們知道可以根據指標指向地址來判斷,比如是否位元組對齊,是否在堆的範圍之內,但是就有可能出現恰好有數值的值就是地址的值。 這就混亂了,所以就不能確定這是指標,只能保守認為就是指標。 因此肯定不會有誤殺物件的情況。只會有物件已經死了,但是有疑似指標的存在指向它,誤以為它還活著而放過了它的情況發生。 所以**保守式 GC 會有放過一些“垃圾”,對記憶體不太友好。** 並且因為疑似指標的情況,導致我們無法確認它是否是真的指標,所以也就**無法移動物件,因為移動物件就需要改指標**。 有一個方法就是加個中間層,也就是控制代碼層,引用會先指到控制代碼,然後再從控制代碼表找到實際物件。 所以直接引用不需要改變,如果要移動物件只需要修改控制代碼表即可。不過這樣訪問就多了一層,**效率就變低了。** ### 半保守式GC 半保守式GC,**在物件上會記錄型別資訊**而其他地方還是沒有記錄,因此從根掃描的話還是一樣,得靠猜測。 但是得到堆內物件了之後,就能準確知曉物件所包含的資訊了,因此之後 tracing 都是準確的,所以稱為半保守式 GC。 現在可以得知半保守式 GC 只有根直接掃描的物件無法移動,從直接物件再追溯出去的物件可以移動,所以半保守式 GC 可以使用移動部分物件的演算法,也可以使用標記-清除這種不移動物件的演算法。 而保守式 GC 只能使用標記-清除演算法。 ### 準確式 GC 相信大家看下來已經知道準確意味 JVM 需要清晰的知曉物件的型別,包括在棧上的引用也能得知型別等。 能想到的可以在指標上打標記,來表明型別,或者在外部記錄型別資訊形成一張對映表。 **HotSpot 用的就是對映表,這個表叫 OopMap。** 在 HotSpot 中,物件的型別資訊裡會記錄自己的 OopMap,記錄了在該型別的物件內什麼偏移量上是什麼型別的資料,而在直譯器中執行的方法可以通過直譯器裡的功能自動生成出 OopMap 出來給 GC 用。 被 JIT 編譯過的方法,也會在特定的位置生成 OopMap,記錄了執行到該方法的某條指令時棧上和暫存器裡哪些位置是引用。 這些特定的位置主要在: 1. 迴圈的末尾(**非 counted 迴圈**) 2. 方法臨返回前 / 呼叫方法的call指令後 3. 可能拋異常的位置 這些位置就叫作**安全點(safepoint)**。 那為什麼要選擇這些位置插入呢?因為如果對每條指令都記錄一個 OopMap 的話空間開銷就過大了,因此就選擇這些個關鍵位置來記錄即可。 **所以在 HotSpot 中 GC 不是在任何位置都能進入的,只能在安全點進入。** 至此我們知曉了可以在類載入時計算得到物件型別中的 OopMap,直譯器生成的 OopMap 和 JIT 生成的 OopMap ,所以 GC 的時候已經有充足的條件來準確判斷物件型別。 因此稱為準確式 GC。 其實還有個 JNI 呼叫,它們既不在直譯器執行,也不會經過 JIT 編譯生成,所以會缺少 OopMap。 在 HotSpot 是通過控制代碼包裝來解決準確性問題的,像 JNI 的入參和返回值引用都通過控制代碼包裝起來,也就是通過控制代碼再訪問真正的物件。 這樣在 GC 的時候就不用掃描 JNI 的棧幀,直接掃描控制代碼表就知道 JNI 引用了 GC 堆中哪些物件了。 ## 安全點 我們已經提到了安全點,安全點當然不是隻給記錄 OopMap 用的,因為 GC 需要一個一致性快照,所以應用執行緒需要暫停,而暫停點的選擇就是安全點。 我們來捋一遍思路。首先給個 GC 名詞,在垃圾收集場景下將應用程式稱為 mutator 。 一個能被 mutator 訪問的物件就是活著的,也就是說 mutator 的上下文包含了可以訪問存活物件的資料。 這個上下文其實指的就是棧、暫存器等上面的資料,對於 GC 而言它只關心棧上、暫存器等哪個位置是引用,因為它只需要關注引用。 但是上下文在 mutator 執行過程中是一直在變化的,所以 GC 需要獲取一個**一致性**上下文快照來列舉所有的根物件。 而快照的獲取需要停止 mutator 所有執行緒,不然就得不到一致的資料,導致一些活著物件丟失,這裡說的一致性其實就像事務的一致性。 而 mutator 所有執行緒中這些有機會成為暫停位置的點就叫 safepoint 即安全點。 openjdk 官網對安全點的定義是: > A point during program execution at which all GC roots are known and all heap object contents are consistent. From a global point of view, all threads must block at a safepoint before the GC can run. 不過 safepoint 不僅僅只有 GC 有用,比如 deoptimization、Class redefinition 都有,只是 GC safepoint 比較知名。 我們再來想一下可以在哪些位置放置這個安全點。 對於直譯器來說其實每個位元組碼邊界都可以成為一個安全點,對於 JIT 編譯的程式碼也能在很多位置插入安全點,但是實現上只會在一些特定的位置插入安全點。 因為安全點是需要 check 的,而 check 需要開銷,如果安全點過多那麼開銷就大了,等於每執行幾步就需要檢查一下是否需要進入安全點。 其次也就是我們上面提到的會記錄 OopMap ,所以有額外的空間開銷。 **那 mutator 是如何得知此時需要在安全點暫停呢?** 其實上面已經提到了是 check,再具體一些還分解釋執行和編譯執行時不同的 check。 在解釋執行的時候的 check 就是在安全點 polling 一個標誌位,如果此時要進入 GC 就會設定這個標誌位。 而編譯執行是 polling page 不可讀,在需要進入 safepoint 時就把這個記憶體頁設為不可訪問,然後編譯程式碼訪問就會發生異常,然後捕獲這個異常掛起即暫停。 這裡可能會有同學問,那此時阻塞住的執行緒咋辦?它到不了安全點啊,總不能等著它吧? 這裡就要引入**安全區域**的概念,在這種引用關係不會發生變化的程式碼段中的區域稱為安全區域。 在這個區域內的任意地方開始 GC 都是安全的,這些執行到安全區域的執行緒也會標識自己進入了安全區域, 所以會 GC 就不用等著了,並且這些執行緒如果要出安全區域的時候也會檢視此時是否在 GC ,如果在就阻塞等著,如果 GC 結束了那就繼續執行。 可能有些同學對**counted 迴圈**有點疑問,像`for (int i...)` 這種就是 counted 迴圈,這裡不會埋安全點。 所以說假設你有一個 counted loop 然後裡面做了一些很慢的操作,所以**很有可能其他執行緒都進入安全點阻塞就等這個 loop 的執行緒完畢**,這就卡頓了。 ## 分代收集 前面我們提到標記-清除方式的 GC 其實就是攢著垃圾收,這樣集中式回收會給應用的正常執行帶來影響,所以就採取了**分代收集**的思想。 因為**研究發現有些物件基本上不會消亡,存在的時間很長,而有些物件出來沒多久就會被咔嚓了**。這其實就是弱分代假說和強分代假說。 所以**將堆分為新生代和老年代**,這樣對不同的區域可以根據不同的回收策略來處理,提升回收效率。  比如新生代的物件有朝生夕死的特性,因此垃圾收集的回報率很高,需要追溯標記的存活物件也很少,因此收集的也快,可以將垃圾收集安排地頻繁一些。 新生代每次垃圾收集存活的物件很少的話,如果**用標記-清除演算法每次需要清除的物件很多**,因此可以採用標記-複製演算法,每次將存活的物件複製到一個區域,剩下了直接全部清除即可。 但是樸素的標記-複製演算法是將堆對半分,但是這樣記憶體利用率太低了,只有 50%。 所以 HotSpot 虛擬機器分了一個 Eden 區和兩個Survivor,預設大小比例是8∶1:1,這樣利用率有 90%。 每次回收就將存活的物件拷貝至一個 Survivor 區,然後清空其他區域即可,如果 Survivor 區放不下就放到 老年代去,這就是**分配擔保機制。**  而老年代的物件基本上都不是垃圾,所以**追溯標記的時間比較長**,收集的回報率也比較低,所以收集頻率安排的低一些。 這個區域由於每次清除的物件很少,因此可以用標記-清除演算法,但是單單清除不移動物件的話會有很多記憶體碎片的產生,所以還有一種叫標記-整理的演算法,等於每次清除了之後需要將記憶體規整規整,需要移動物件,比較耗時。 所以可以利用標記-清除和標記-整理兩者結合起來收集老年代,比如平日都用標記-清除,當察覺記憶體碎片實在太多了就用標記-整理來配合使用。 可能還有很多同學對的標記-清除,標記-整理,標記-複製演算法不太清晰,沒事,咱們來盤一下。 ## 標記-清除 分為兩個階段: 標記階段:tracing 階段,從根(棧、暫存器、全域性變數等)開始遍歷物件圖,標記所遇到的每個物件。 清除階段:掃描堆中的物件,將為標記的物件作為垃圾回收。 基本上就是下圖所示這個過程: 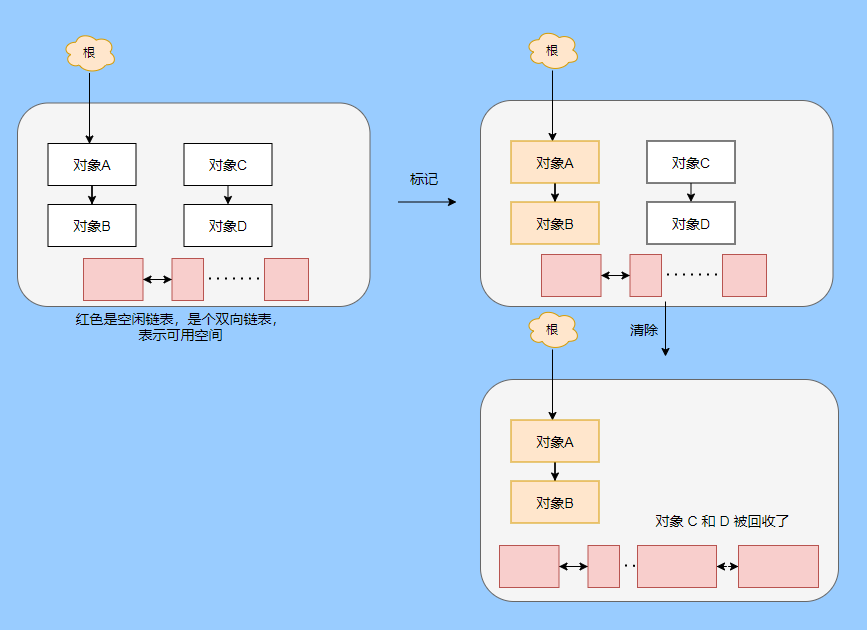 **清除不會移動和整理記憶體空間**,一般都是通過空閒連結串列(雙向連結串列)來標記哪一塊記憶體空閒可用,因此會導致一個情況:**空間碎片**。 這會使得明明總的記憶體是夠的,但是申請記憶體就是不足。 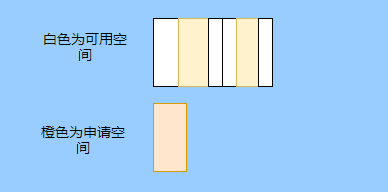 而且在申請記憶體的時候也有點麻煩,需要遍歷連結串列查詢合適的記憶體塊,會比較耗時。 所以會有**多個空閒連結串列的實現**,也就是根據記憶體分塊大小組成不同的連結串列,比如分為大分塊連結串列和小分塊連結串列,這樣根據申請的記憶體分塊大小遍歷不同的連結串列,加快申請的效率。 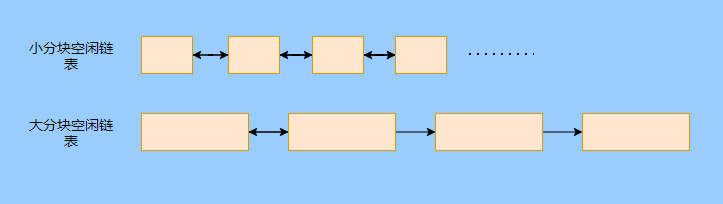 當然還可以分更多個連結串列。 還有標記,標記的話一般我們會覺得應該是標記在物件身上,比如標記位放在物件頭中,但是這對寫時複製不相容。 等於每一次 GC 都需要修改物件,假設是 fork 出來的,其實是共享一塊記憶體,那修改必然導致複製。 所以有一種**點陣圖標記法**,其實就是將堆的記憶體某個塊用一個位來標記。就像我們的記憶體是一頁一頁的,堆中的記憶體可以分成一塊一塊,而物件就是在一塊,或者多塊記憶體上。 根據物件所在的地址和堆的起始地址就可以算出物件是在第幾塊上,然後用一個位圖中的第幾位在置為 1 ,表明這塊地址上的物件被標記了。 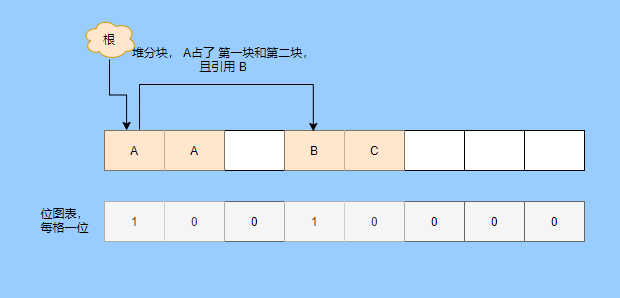 而且用位圖表格法不僅可以利用寫時複製,清除也更加高效,如果標記在物件頭上,那麼需要遍歷整個堆來掃描物件,現在有了點陣圖,可以快速遍歷清除物件。 但是不論是標記物件頭還是利用點陣圖,標記-清除的碎片問題還是處理不了。 因此就引出了標記-複製和標記-整理。 ## 標記-複製 首先這個演算法會把堆分為兩塊,一塊是 From、一塊是 To。 物件只會在 From 上生成,發生 GC 之後會找到所有存活物件,然後將其複製到 To 區,之後整體回收 From 區。 再將 To 區和 From 區身份對調,即 To 變成 From , From 變成 To,我再用圖來解釋一波。 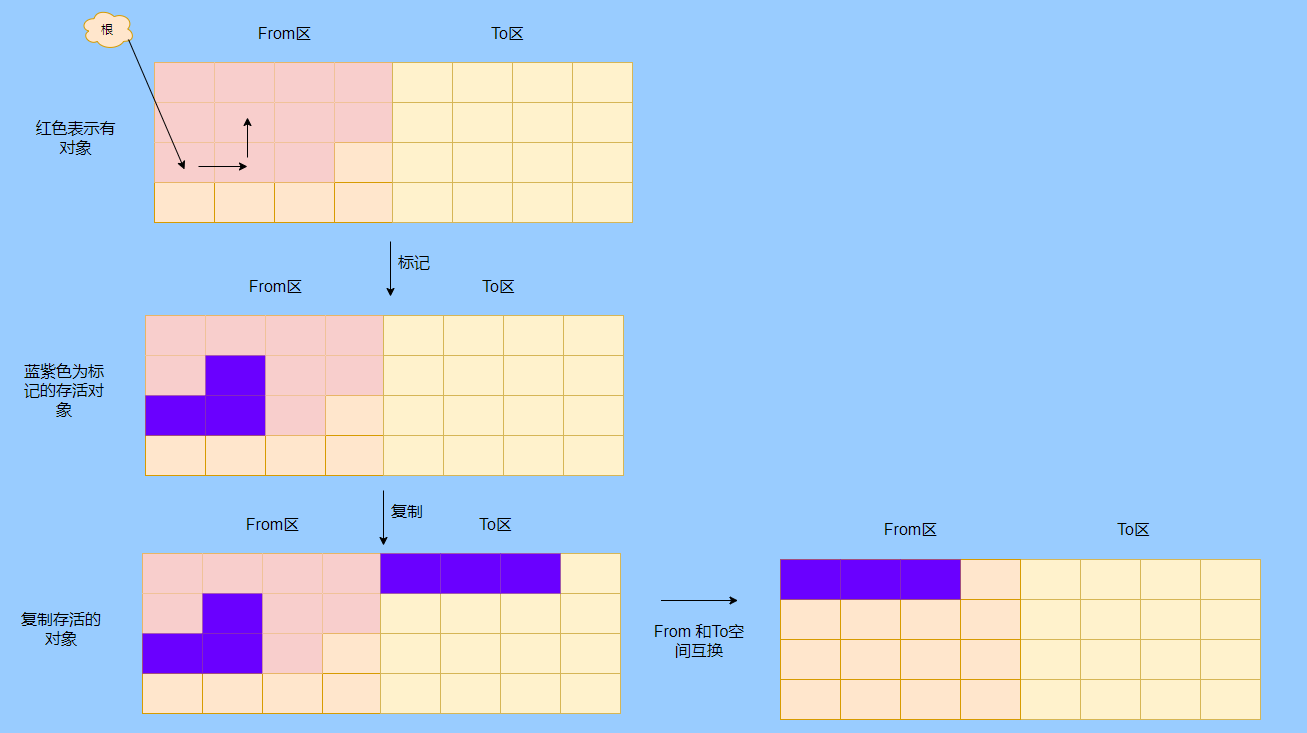 可以看到記憶體的分配是緊湊的,**不會有記憶體碎片的產生**。 不需要空閒連結串列的存在,**直接移動指標分配記憶體**,效率很高。 **對 CPU快取親和性高**,因為從根開始遍歷一個節點,是深度優先遍歷,把關聯的物件都找到,然後記憶體分配在相近的地方。 這樣根據區域性性原理,一個物件被載入了那它所引用的物件也同時被載入,因此訪問快取直接命中。、 當然它也是有缺點的,因為物件的分配只能在 From 區,而 From 區只有堆一半大小,因此**記憶體的利用率是 50%。** 其次如果**存活的物件很多,那麼複製的壓力還是很大的**,會比較慢。 然後由於需要移動物件,因此**不適用於上文提到的保守式 GC。** 當然我上面描述的是深度優先就是遞迴呼叫,有棧溢位風險,還有一種 Cheney 的 GC 複製演算法,是採用迭代的廣度優先遍歷,具體不做分析了,有興趣自行搜尋。 ## 標記-整理 標記-整理其實和標記-複製差不多,區別在於複製演算法是分為兩個區來回複製,而整理不分割槽,直接整理。 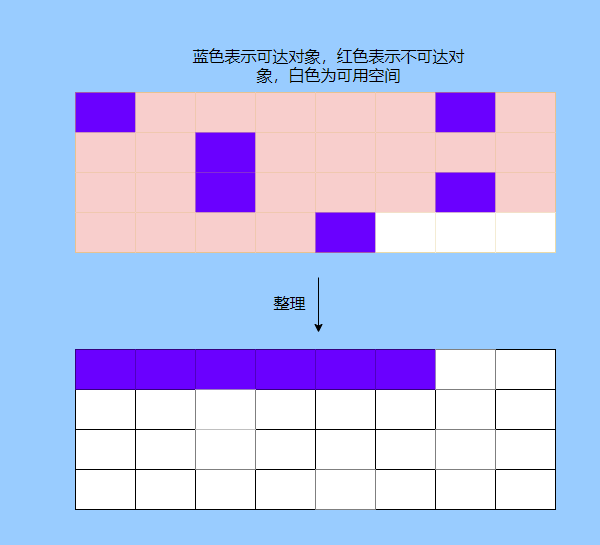 演算法思路還是很清晰的,將存活的物件往邊界整理,也沒有記憶體碎片,也不需要複製演算法那樣騰出一半的空間,所以記憶體利用率也高。 缺點就是需要對堆進行多次搜尋,畢竟是在一個空間內又標記,又移動的,所以整體而言花費的時間較多,而且如果堆很大的情況,那麼消耗的時間將更加突出。 至此相信你對標記-清除、標記-複製和標記-整理都清晰了,讓我們再回到剛才提到的分代收集。 ## 跨代引用 我們已經根據物件存活的特性進行了分代,提高了垃圾收集的效率,但是像在回收新生代的時候,有可能有老年代的物件引用了新生代物件,所以老年代也需要作為根,但是如果掃描整個老年代的話效率就又降低了。 所以就搞了個叫記憶集(Remembered Set)的東西,來**記錄跨代之間的引用而避免掃描整體非收集區域。** 因此記憶集就是一種用於記錄從非收集區域指向收集區域的指標集合的抽象資料結構。根據記錄的精度分為 - 字長精度,每條記錄精確到機器字長。 - 物件精度,每條記錄精確到物件。 - 卡精度,每條記錄精確到一塊記憶體區域。 **最常見的是用卡精度來實現記憶集,稱之為卡表。** 我來解釋下什麼叫卡。 拿物件精度來距離,假設新生代物件 A 被老年代物件 D 引用了,那麼就需要記錄老年代 D 所在的地址引用了新生代物件。 那卡的意思就是將記憶體空間分成很多卡片。假設新生代物件 A 被老年代 D 引用了,那麼就需要記錄老年代 D 所在的那一塊記憶體片有引用新生代物件。 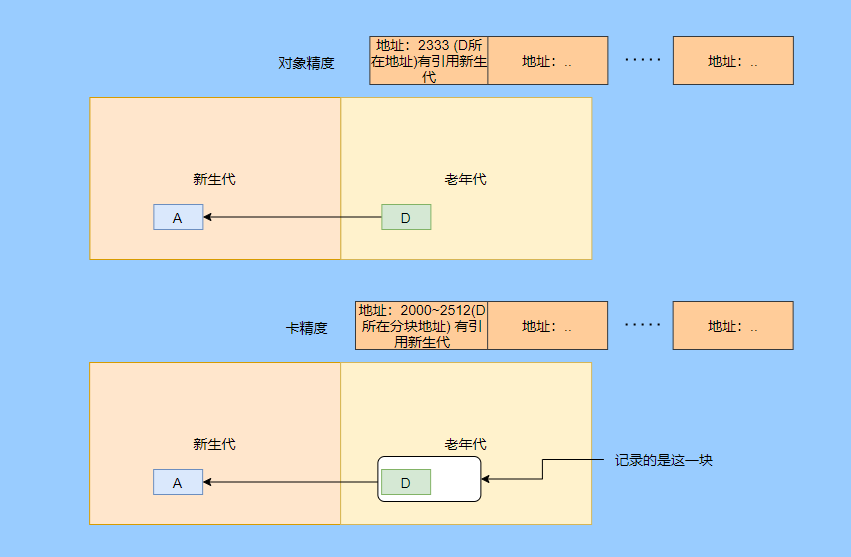 也就是說堆被卡切割了,假設卡的大小是 2,堆是 20,那麼堆一共可以劃分成 10 個卡。 因為卡的範圍大,如果此時 D 旁邊在同一個卡內的物件也有引用新生代物件的話,那麼就只需要一條記錄。 一般會用位元組陣列來實現卡表,卡的範圍也是設為 2 的 N 次冪大小。來看一下圖就很清晰了。 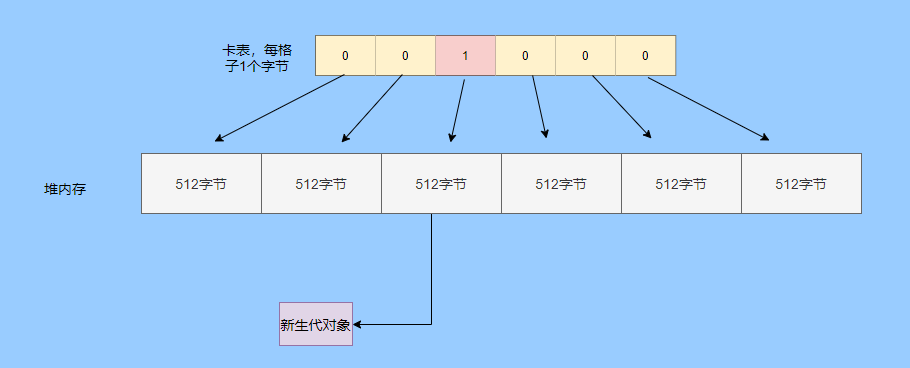 假設地址從 0x0000 開始,那麼位元組陣列的 0號元素代表 0x0000~0x01FF,1 號代表0x0200~0x03FF,依次類推即可。 然後到時候回收新生代的時候,只需要掃描卡表,把標識為 1 的髒表所在記憶體塊加入到 GC Roots 中掃描,這樣就不需要掃描整個老年代了。 用了卡表的話佔用記憶體比較少,但是相對字長、物件來說精度不準,需要掃描一片。所以也是一種取捨,到底要多大的卡。 還有一種**多卡表**,簡單的說就是有多張卡表,這裡我畫兩張卡表示意一下。 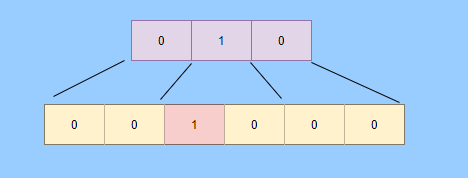 上面的卡表表示的地址範圍更大,這樣可以先掃描範圍大的表,發現中間一塊髒了,然後再通過下標計算直接得到更具體的地址範圍。 這種多卡表在堆記憶體比較大,且跨代引用較少的時候,掃描效率較高。 而卡表一般都是通過寫屏障來維護的,**寫屏障其實就相當於一個 AOP**,在物件引用欄位賦值的時候加入更新卡表的程式碼。 這其實很好理解,說白了就是當引用欄位賦值的時候判斷下當前物件是老年代物件,所引用物件是新生代物件,於是就在老年代物件所對應的卡表位置置為 1,表示髒,待會需要加入根掃描。 **不過這種將老年代作為根來掃描會有浮動垃圾的情況**,因為老年代的物件可能已經成為垃圾,所以拿垃圾來作為根掃描出來的新生代物件也很有可能是垃圾。 **不過這是分代收集必須做出的犧牲。** ## 增量式 GC 所謂的增量式 GC 其實就是在應用執行緒執行中,穿插著一點一點的完成 GC,來看個圖就很清晰了 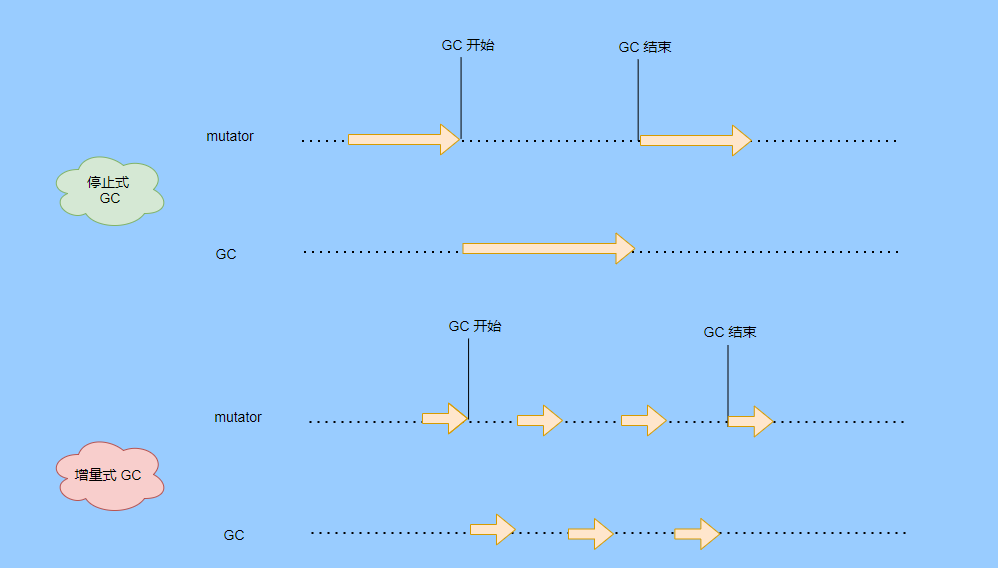 這樣看起來 GC 的時間跨度變大了,但是 mutator 暫停的時間變短了。 對於增量式 GC ,Dijkstra 等人抽象除了**三色標記演算法**,來表示 GC 中物件三種不同狀況。 ### 三色標記演算法 白色:表示還未搜尋到的物件。 灰色:表示正在搜尋還未搜尋完的物件。 黑色:表示搜尋完成的物件。 下面這圖從維基百科搞得,雖說顏色沒對上,但是意思是對的(black 畫成了藍色,grey畫成了黃色)。 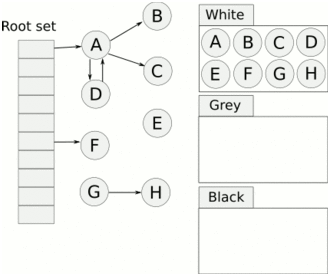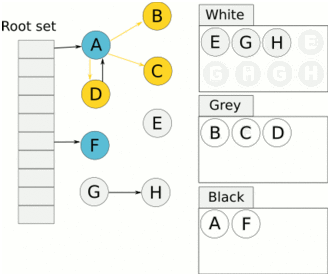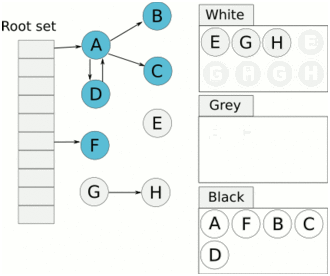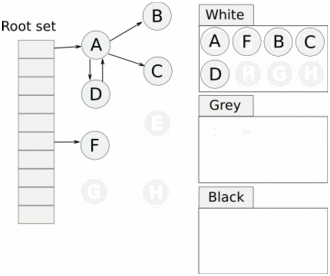 我再用文字概述一下三色的轉換。 GC 開始前所有物件都是白色,GC 一開始所有根能夠直達的物件被壓到棧中,待搜尋,此時顏色是灰色。 然後灰色物件依次從棧中取出搜尋子物件,子物件也會被塗為灰色,入棧。當其所有的子物件都塗為灰色之後該物件被塗為黑色。 當 GC 結束之後灰色物件將全部沒了,剩下黑色的為存活物件,白色的為垃圾。 一般增量式標記-清除會分為三個階段: 1. 根查詢,需要暫停應用執行緒,找到根直接引用的物件。 2. 標記階段,和應用執行緒併發執行。 3. 清除階段。 這裡解釋下 GC 中兩個名詞的含義。 併發:應用執行緒和 GC 執行緒一起執行。 並行:多個 GC 執行緒一起執行。 看起來好像三色標記沒啥問題?來看看下圖。 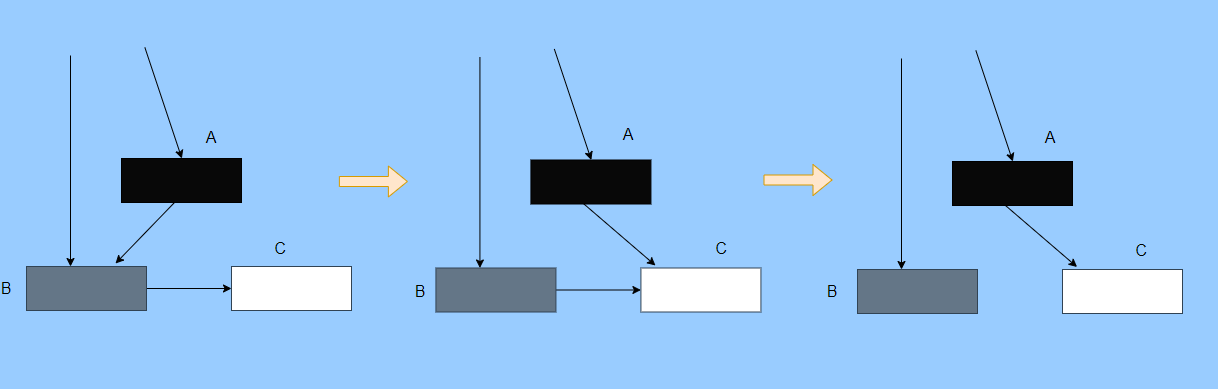 第一個階段搜尋到 A 的子物件 B了,因此 A 被染成了黑色,B 為灰色。此時需要搜尋 B。 但是在 B 開始搜尋時,A 的引用被 mutator 換給了 C,然後此時 B 到 C 的引用也被刪了。 接著開始搜尋 B ,此時 B 沒有引用因此搜尋結束,這時候 C 就被當垃圾了,因此 A 已經黑色了,所以不會再搜尋到 C 了。 這就是出現**漏標**的情況,把還在使用的物件當成垃圾清除了,非常嚴重,這是 GC 不允許的,**寧願放過,不能殺錯。** 還有一種情況**多標**,比如 A 變成黑色之後,根引用被 mutator 刪除了,那其實 A 就屬於垃圾,但是已經被標記為黑色了,那就得等下次 GC 清除了。 這其實就是標記過程中沒有暫停 mutator 而導致的,但這也是為了讓 GC 減少對應用程式執行的影響。 多標其實還能接受,漏標的話就必須處理了,我們可以總結一下為什麼會發生漏標: 1. mutator 插入黑色物件 A 到白色物件 C 的一個引用 2. mutator 刪除了灰色物件 B 到白色物件 C 的一個引用 只要打破這兩個條件任意一個就不會發生漏標的情況。 這時候可以通過以下手段來打破兩個條件: 利用寫屏障在黑色引用白色物件時候,將白色物件置為灰色,這叫**增量更新。** 利用寫屏障在灰色物件刪除對白色物件的引用時,將白色物件置為灰,其實就是儲存舊的引用關係。這叫**STAB(snapshot-at-the-beginning)**。 ## 總結 至此有關垃圾回收的關鍵點和思路都差不多了,具體有關 JVM 的垃圾回收器等我下篇再作分析。 現在我們再來**總結一下。** 關於垃圾回收首先得找出垃圾,而找出垃圾分為兩個流派,一個是引用計數,一個是可達性分析。 引用計數垃圾回收的及時,對記憶體較友好,但是迴圈引用無法處理。 可達性分析基本上是現代垃圾回收的核心選擇,但是由於需要統一回收比較耗時,容易影響應用的正常執行。 所以可達性分析的研究方向就是往如何減少對應用程式執行的影響即減少 STW(stop the world) 的時間。 因此根據物件分代假說研究出了分代收集,根據物件的特性劃分了新生代和老年代,採取不同的收集演算法,提升回收的效率。 想方設法的拆解 GC 的步驟使得可以與應用執行緒併發,並且採取並行收集,加快收集速度。 還有往評估的方向的延遲迴收或者說回收部分垃圾來減少 STW 的時間。 總的而言垃圾回收還是很複雜的,因為有很多細節,我這篇就是淺顯的紙上談兵,不要被我的標題騙了哈哈哈哈。 ## 最後 這篇文章寫了挺久的,主要是內容很多如何編排有點難,我也選擇性的剪了很多了,但還是近 1W 字。 期間也查閱了很多資料,不過個人能力有限,如果有紕漏的地方請抓緊聯絡我。 ## 巨人的肩膀 http://arctrix.com/nas/python/gc/ https://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html 《The Garbage Collection Handbook 》 https://www.iteye.com/blog/user/rednaxelafx R大的部落格 https://www.jianshu.com/u/90ab66c248e6 佔小狼的部落格 --- >微信搜尋【yes的練級攻略】,關注 yes,從一點點到億點點,我們下
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
https://www.itread01.com/content/1604632085.html