当前位置:网站首页>如何对Pandas DataFrame进行自定义排序
如何对Pandas DataFrame进行自定义排序
2020-11-06 01:28:00 【人工智能遇见磐创】

作者|B. Chen 编译|VK 来源|Towards Data Science

Pandas DataFrame有一个内置方法sort_values(),可以根据给定的变量对值进行排序。该方法本身使用起来相当简单,但是它不适用于自定义排序,例如,
-
t恤尺寸:XS、S、M、L和XL
-
月份:一月、二月、三月、四月等
-
星期几:周一、周二、周三、周四、周五、周六和周日。
在本文中,我们将了解如何对Pandas DataFrame进行自定义排序。
请查看我的Github repo以获取源代码:https://github.com/BindiChen/machine-learning/blob/master/data-analysis/017-pandas-custom-sort/pandas-custom-sort.ipynb
问题
假设我们有一个关于服装店的数据集:
df = pd.DataFrame({
'cloth_id': [1001, 1002, 1003, 1004, 1005, 1006],
'size': ['S', 'XL', 'M', 'XS', 'L', 'S'],
})
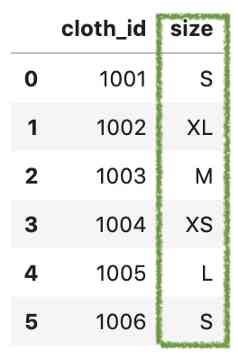
我们可以看到,每一块布料都有一个尺寸值,数据应该按以下顺序排序:
-
XS代表特大号
-
S代表小号
-
M代表中号
-
L代表大号
-
XL为特大号
但是,当调用sort_values('size')时,将得到以下输出。

输出不是我们想要的,但它在技术上是正确的。实际上,sort_values()是按数字顺序对数值数据排序,对对象数据按字母顺序排序。
以下是两种常见的解决方案:
-
为自定义排序创建新列
-
使用CategoricalDtype将数据强制转换为具有有序性的类别类型
为自定义排序创建新列
在这个解决方案中,需要一个映射数据帧来表示一个自定义排序,然后根据映射创建一个新的列,最后我们可以按新列对数据进行排序。让我们通过一个例子来看看这是如何工作的。
首先,让我们创建一个映射数据帧来表示自定义排序。
df_mapping = pd.DataFrame({
'size': ['XS', 'S', 'M', 'L', 'XL'],
})
sort_mapping = df_mapping.reset_index().set_index('size')

之后,使用sort_mapping中的映射值创建一个新的列 size_num。
df['size_num'] = df['size'].map(sort_mapping['index'])
最后,按新的列大小对值进行排序。
df.sort_values('size_num')
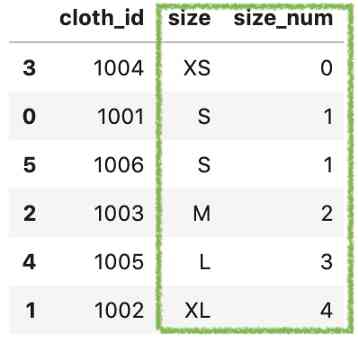
这当然是我们的工作。但它创建了一个备用列,在处理大型数据集时效率可能会降低。
我们可以使用CategoricalDtype更有效地解决这个问题。
使用CategoricalDtype将数据强制转换为具有有序性的类别类型
CategoricalDtype是具有类别和顺序的分类数据的类型[1]。它对于创建自定义排序非常有用[2]。让我们通过一个例子来看看这是如何工作的。
首先,让我们导入CategoricalDtype。
from pandas.api.types import CategoricalDtype
然后,创建一个自定义类别类型cat_size_order
-
第一个参数设置为['XS'、'S'、'M'、'L'、'XL']作为尺寸的唯一值。
-
第二个参数ordered=True,将此变量视为有序。
cat_size_order = CategoricalDtype(
['XS', 'S', 'M', 'L', 'XL'],
ordered=True
)
然后,调用astype(cat_size_order)将大小数据强制转换为自定义类别类型。通过运行df['size'],我们可以看到size列已经被转换为一个类别类型,其顺序为[XS<S<M<L<XL]。
>>> df['size'] = df['size'].astype(cat_size_order)
>>> df['size']
0 S
1 XL
2 M
3 XS
4 L
5 S
Name: size, dtype: category
Categories (5, object): [XS < S < M < L < XL]
最后,我们可以调用相同的方法对值进行排序。
df.sort_values('size')
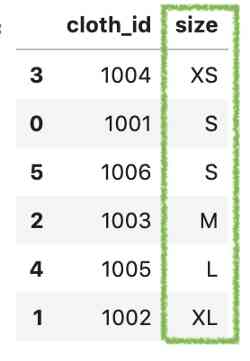
这样效果更好。让我们来看看原理是什么。
使用cat的codes属性访问
现在size列已经被转换为category类型,我们可以使用.cat访问器以查看分类属性。在幕后,它使用codes属性来表示有序变量的大小。
让我们创建一个新的列代码,这样我们可以并排比较大小和代码值。
df['codes'] = df['size'].cat.codes
df
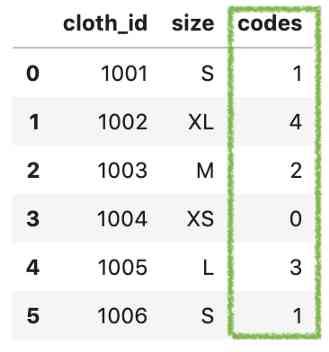
我们可以看到XS、S、M、L和XL的代码分别为0、1、2、3、4和5。codes是类别实际值。通过运行df.info(),我们可以看到实际上是int8。
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cloth_id 6 non-null int64
1 size 6 non-null category
2 codes 6 non-null int8
dtypes: category(1), int64(1), int8(1)
memory usage: 388.0 bytes
按多个变量排序
接下来,让我们把事情变得更复杂一点。这里,我们将按多个变量对数据帧进行排序。
df = pd.DataFrame({
'order_id': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'customer_id': [10, 12, 12, 12, 10, 10, 10],
'month': ['Feb', 'Jan', 'Jan', 'Feb', 'Feb', 'Jan', 'Feb'],
'day_of_week': ['Mon', 'Wed', 'Sun', 'Tue', 'Sat', 'Mon', 'Thu'],
})
类似地,让我们创建两个自定义类别类型cat_day_of_week和cat_month,并将它们传递给astype()。
cat_day_of_week = CategoricalDtype(
['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'],
ordered=True
)
cat_month = CategoricalDtype(
['Jan', 'Feb', 'Mar', 'Apr'],
ordered=True,
)
df['day_of_week'] = df['day_of_week'].astype(cat_day_of_week)
df['month'] = df['month'].astype(cat_month)
要按多个变量排序,我们只需要传递一个列表来代替sort_values()。例如,按month和day_of_week排序。
df.sort_values(['month', 'day_of_week'])
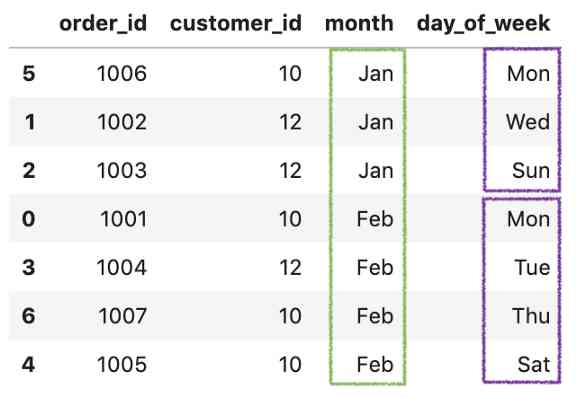
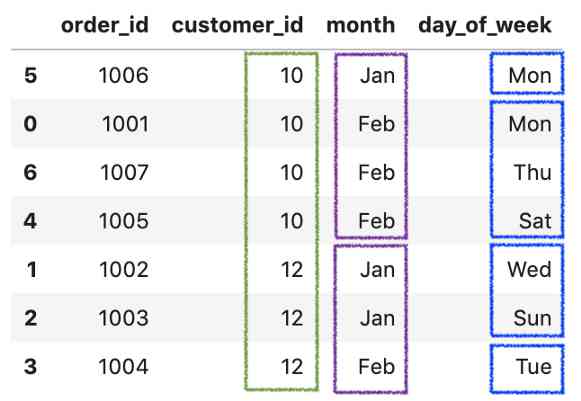
按ustomer_id,month 和day_of_week排序。
df.sort_values(['customer_id', 'month', 'day_of_week'])
就这样,谢谢你的阅读。
请在我的Github上导出笔记本以获取源代码:https://github.com/BindiChen/machine-learning/blob/master/data-analysis/017-pandas-custom-sort/pandas-custom-sort.ipynb
参考引用
- [1] Pandas.CategoricalDtype API(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.CategoricalDtype.html)
- [2] Pandas Categorical CategoricalDtype tutorial (https://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html#categorical-categoricaldtype)
原文链接:https://towardsdatascience.com/how-to-do-a-custom-sort-on-pandas-dataframe-ac18e7ea5320
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4697477
边栏推荐
猜你喜欢




随机推荐
python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库
【C/C++ 2】Clion配置与运行C语言
面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
【C/C++ 1】Clion配置与运行C语言
使用ES5实现ES6的Class
普通算法面试已经Out啦!机器学习算法面试出炉 - kdnuggets
如何选择分类模型的评价指标
被老程式設計師壓榨怎麼辦?我不想辭職
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
技术总监,送给刚毕业的程序员们一句话——做好小事,才能成就大事
keras model.compile损失函数与优化器
自然语言处理-搜索中常用的bm25
VUEJS开发规范
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
H5打造属于自己的视频播放器(JS篇2)
对pandas 数据进行数据打乱并选取训练机与测试机集
《Google软件测试之道》 第一章google软件测试介绍
Using tensorflow to forecast the rental price of airbnb in New York City
想要做读写分离,送你一些小经验
结构化数据中的从属判断问题