当前位置:网站首页>python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库
python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库
2020-11-06 01:22:00 【IT界的小小小学生】
转载请注明出处
欢迎加入Python快速进阶QQ群:867300100
“结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库。
jieba的分词,提取关键词,自定义词语。
结巴分词的原理
这里写链接内容
#一、 基于结巴分词进行分词与关键词提取
##1、jieba.cut分词三种模式
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用
HMM 模型
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
#coding=utf-8
import jieba,math
import jieba.analyse
'''
jieba.cut主要有三种模式
#随便对一个动物园的评论进行分析
str_text="真是好久好久没来哈皮娜拉野生动物园了,记忆里还是小时候三四年级学校组织春游去的银河系"
#全模式cut_all=True
str_quan1=jieba.cut(str_text,cut_all=True)
print('全模式分词:{ %d}' % len(list(str_quan1)))
str_quan2=jieba.cut(str_text,cut_all=True)
print("/".join(str_quan2))
# print(str(str_1)) #为一个generator 用for循环可以得到分词的结果
# str_1_len=len(list(str_1)) #为什么?这里执行后后面.join 就不执行,求告知
#精准模式cut_all=False,默认即是
str_jing1=jieba.cut(str_text,cut_all=False)
print('精准模式分词:{ %d}' % len(list(str_jing1)))
str_jing2=jieba.cut(str_text,cut_all=False)
print("/".join(str_jing2))
#搜索引擎模式 cut_for_search
str_soso1=jieba.cut_for_search(str_text)
print('搜索引擎分词:{ %d}' % len(list(str_soso1)))
str_soso2=jieba.cut_for_search(str_text)
print("/".join(str_soso))
结果
全模式分词:{ 32}
Prefix dict has been built succesfully.
真是/TMD/好久/好久好久/好久/好久没/没来/哈/皮/娜拉/野生/野生动物/生动/动物/动物园/了///记忆/记忆里/还是/小时/小时候/时候/学校/组织/春游/游去/的/银河/银河系/河系
精准模式分词:{ 19}
真是/TMD/好久好久/没来/哈皮/娜拉/野生/动物园/了/,/记忆里/还是/小时候/学校/组织/春游/去/的/银河系
搜索引擎分词:{ 27}
真是/TMD/好久/好久/好久好久/没来/哈皮/娜拉/野生/动物/动物园/了/,/记忆/记忆里/还是/小时/时候/小时候/学校/组织/春游/去/的/银河/河系/银河系、
##2、关键词提取、关键词提取**
import jieba.analyse
’analyse.extract.tags‘
'''
keywords1=jieba.analyse.extract_tags(str_text)
print('关键词提取'+"/".join(keywords1))
keywords_top=jieba.analyse.extract_tags(str_text,topK=3)
print('关键词topk'+"/".join(keywords_to#有时不确定提取多少关键词,可利用总词的百分比
print('总词数{}'.format(len(list(jieba.cut(str_text)))))
total=len(list(jieba.cut(str_text)))
get_cnt=math.ceil(total*0.1) #向上取整
print('从%d 中取出%d 个词'% (total,get_cnt))
keywords_top1=jieba.analyse.extract_tags(str_text,topK=get_cnt)
print('关键词topk'+"/".join(keywords_top1))''
结果:
关键词提取TMD/哈皮/春游/好久好久/记忆里/娜拉/银河系/没来/动物园/小时候/野生/学校/真是/组织/还是
关键词topkTMD/哈皮/春游
总词数19
从19 中取出2 个词topkTMD/哈皮、
##3、加自定义词与加载自定义词库**
添加自定义词
================# 处理时,jieba.add_word
# add_word(word,freq=None,tag=None) 和del_word可在程序中动态修改词典
# suggest_freq(segment,tune=Ture)可调节单词词频,时期能或不能显示
# 注:自动计算的词频在使用HMM新词发现功能时可能无效
# '''
# str_jing2=jieba.cut(str_text,cut_all=False)
# print('add_word前:'+"/".join(str_jing2))
# #添加自定义词
# jieba.add_word('哈皮娜拉')
# str_jing3=jieba.cut(str_text,cut_all=False)
# print('add_word后:'+"/".join(str_jing3))
# #修正词频
# jieba.suggest_freq('野生动物园',tune=True)
# str_jing4=jieba.cut(str_text,cut_all=False)
# print('suggest_freq后:'+"/".join(str_jing4))
#
结果:
**add_word前:**真是/TMD/好久好久/没来/哈皮/娜拉/野生/动物园/了/,/记忆里/还是/小时候/学校/组织/春游/去/的/银河系
add_word后:真是/TMD/好久好久/没/来/哈皮娜拉/野生/动物园/了/,/记忆里/还是/小时候/学校/组织/春游/去/的/银河系
suggest_freq后:真是/TMD/好久好久/没/来/哈皮娜拉/野生动物园/了/,/记忆里/还是/小时候/学校/组织/春游/去/的/银河系
加载自定义词库
jieba.load_userdict(filename)#filename为文件路径
词典格式和dict.txt一样,一词一行,每行分三个部分(用空格隔开),词语 词频(可省) 词性(可省)
顺序不可颠倒,若filename为路径或二进制方式打开,则需为UTF-8
'''
#定义:三四年级 在文件内
jieba.load_userdict('C:\\Users\\lenovo\\Desktop\\自定义词库.txt')
str_load=jieba.cut(str_text,cut_all=False)
print('load_userdict后:'+"/".join(str_load))
'''
注jieba.load_userdict加载自定义词库和jieba初始化词库一同使用,
但是,默认的初始词库放在安装目录ixia,如果确定长期加载词库,就替换他
使用词库的切换功能set_dictionary()
可将jieba默认词库copy到自己的目录下,在添加,或者找到更全的词库
'''
#一般在python都为site-packages\jieba\dict.txt
#模拟演示
jieba.set_dictionary('filename')
#之后进行分词,如果我们切换了词库,此时程序就会初始化
我们制定的词库,而不加载默认路径词库
使用:
-安装或者将jieba目录放在当前目录或者site-packages目录
算法:
-基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
-采用动态规划查找最大概率路径,找出基于词频的最大切分组合
-对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
添加自定义词典
-开发者可以指定自己自定义的词典,以便包含jieba词库里没有的词。虽然jieba有新词识别能力,但是自行添加新词可以保证更高的正确率
-用法:jieba.load_userdict(file_name)#file_name为文件类对象 或自定义词典的路径
-词典格式:一个词一行:词语,词频(可省略),词性(可省略),用空格隔开,顺序不可颠倒。UTF-8编码。
关键词提取:
##4、基于TF-IDF算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
–sentence 为待提取的文本
–topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
–withWeight 为是否一并返回关键词权重值,默认值为 False
–allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
##5、基于TextRank算法的关键词提取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
–基本思想:
1,将待抽取关键词的文本进行分词
2,以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
3,计算图中节点的PageRank,注意是无向带权图
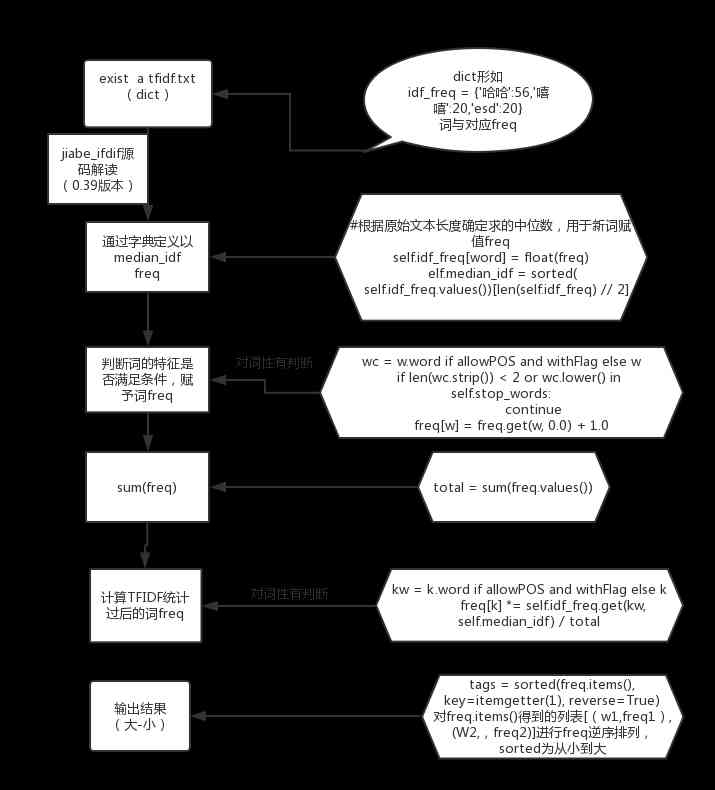
对于itemgetter()用法参照连接
#二、 常用NLP扩充知识点(python2.7)
##Part 1. 词频统计、降序排序
article = open("C:\\Users\\Luo Chen\\Desktop\\demo_long.txt", "r").read()
words = jieba.cut(article, cut_all = False)
word_freq = {}
for word in words:
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 1
freq_word = []
for word, freq in word_freq.items():
freq_word.append((word, freq))
freq_word.sort(key = lambda x: x[1], reverse = True)
max_number = int(raw_input(u"需要前多少位高频词? "))
for word, freq in freq_word[: max_number]:
print word, freq
##Part 2. 人工去停用词
标点符号、虚词、连词不在统计范围内。
stopwords = []
for word in open("C:\\Users\\Luo Chen\\Desktop\\stop_words.txt", "r"):
stopwords.append(word.strip())
article = open("C:\\Users\\Luo Chen\\Desktop\\demo_long.txt", "r").read()
words = jieba.cut(article, cut_all = False)
stayed_line = ""
for word in words:
if word.encode("utf-8") not in stopwords:
stayed_line += word + " "
print stayed_line
##Part 3. 合并同义词
将同义词列举出来,按下Tab键分隔,把第一个词作为需要显示的词语,后面的词语作为要替代的同义词,一系列同义词放在一行。
这里,“北京”、“首都”、“京城”、“北平城”、“故都”为同义词。
combine_dict = {}
for line in open("C:\\Users\\Luo Chen\\Desktop\\tongyici.txt", "r"):
seperate_word = line.strip().split("\t")
num = len(seperate_word)
for i in range(1, num):
combine_dict[seperate_word[i]] = seperate_word[0]
jieba.suggest_freq("北平城", tune = True)
seg_list = jieba.cut("北京是中国的首都,京城的景色非常优美,就像当年的北平城,我爱这故都的一草一木。", cut_all = False)
f = ",".join(seg_list)
result = open("C:\\Users\\Luo Chen\\Desktop\\output.txt", "w")
result.write(f.encode("utf-8"))
result.close()
for line in open("C:\\Users\\Luo Chen\\Desktop\\output.txt", "r"):
line_1 = line.split(",")
final_sentence = ""
for word in line_1:
if word in combine_dict:
word = combine_dict[word]
final_sentence += word
else:
final_sentence += word
print final_sentence
##Part 4. 词语提及率
主要步骤:分词——过滤停用词(略)——替代同义词——计算词语在文本中出现的概率。
origin = open("C:\\Users\\Luo Chen\\Desktop\\tijilv.txt", "r").read()
jieba.suggest_freq("晨妈妈", tune = True)
jieba.suggest_freq("大黑牛", tune = True)
jieba.suggest_freq("能力者", tune = True)
seg_list = jieba.cut(origin, cut_all = False)
f = ",".join(seg_list)
output_1 = open("C:\\Users\\Luo Chen\\Desktop\\output_1.txt", "w")
output_1.write(f.encode("utf-8"))
output_1.close()
combine_dict = {}
for w in open("C:\\Users\\Luo Chen\\Desktop\\tongyici.txt", "r"):
w_1 = w.strip().split("\t")
num = len(w_1)
for i in range(0, num):
combine_dict[w_1[i]] = w_1[0]
seg_list_2 = ""
for i in open("C:\\Users\\Luo Chen\\Desktop\\output_1.txt", "r"):
i_1 = i.split(",")
for word in i_1:
if word in combine_dict:
word = combine_dict[word]
seg_list_2 += word
else:
seg_list_2 += word
print seg_list_2
freq_word = {}
seg_list_3 = jieba.cut(seg_list_2, cut_all = False)
for word in seg_list_3:
if word in freq_word:
freq_word[word] += 1
else:
freq_word[word] = 1
freq_word_1 = []
for word, freq in freq_word.items():
freq_word_1.append((word, freq))
freq_word_1.sort(key = lambda x: x[1], reverse = True)
for word, freq in freq_word_1:
print word, freq
total_freq = 0
for i in freq_word_1:
total_freq += i[1]
for word, freq in freq_word.items():
freq = float(freq) / float(total_freq)
print word, freq
##Part 5. 按词性提取
import jieba.posseg as pseg
word = pseg.cut("李晨好帅,又能力超强,是“大黑牛”,也是一个能力者,还是队里贴心的晨妈妈。")
for w in word:
if w.flag in ["n", "v", "x"]:
print w.word, w.flag
以下内容来源于网络收集
3. 关键词提取
基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
分词词性可参见博客:[词性参考](http://blog.csdn.net/HHTNAN/article/details/77650128)
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
代码示例 (关键词提取)
https://github.com/fxsjy/jieba/blob/master/test/extract_tags.py
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
关键词一并返回关键词权重值示例
用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_with_weight.py
基于 TextRank 算法的关键词抽取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
算法论文: TextRank: Bringing Order into Texts
基本思想:
将待抽取关键词的文本进行分词
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
计算图中节点的PageRank,注意是无向带权图
使用示例:
见 test/demo.py
4. 词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
用法示例
import jieba.posseg as pseg
words = pseg.cut(“我爱北京天安门”)
for word, flag in words:
… print(’%s %s’ % (word, flag))
…
我 r
爱 v
北京 ns
天安门 ns
-
并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式例子:https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
-
Tokenize:返回词语在原文的起止位置
注意,输入参数只接受 unicode
默认模式
result = jieba.tokenize(u’永和服装饰品有限公司’)
for tk in result:
print(“word %s\t\t start: %d \t\t end:%d” % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10
搜索模式
result = jieba.tokenize(u’永和服装饰品有限公司’, mode=‘search’)
for tk in result:
print(“word %s\t\t start: %d \t\t end:%d” % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
-
ChineseAnalyzer for Whoosh 搜索引擎
引用: from jieba.analyse import ChineseAnalyzer
用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py
-
命令行分词
使用示例:python -m jieba news.txt > cut_result.txt
命令行选项(翻译):
使用: python -m jieba [options] filename
结巴命令行界面。
固定参数:
filename 输入文件
可选参数:
-h, --help 显示此帮助信息并退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的’ / '。
若不指定 DELIM,则使用一个空格分隔。
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替默认词典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用
-a, --cut-all 全模式分词(不支持词性标注)
-n, --no-hmm 不使用隐含马尔可夫模型
-q, --quiet 不输出载入信息到 STDERR
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。
–help 选项输出:
$> python -m jieba --help
Jieba command line interface.
positional arguments:
filename input file
optional arguments:
-h, --help show this help message and exit
-d [DELIM], --delimiter [DELIM]
use DELIM instead of ’ / ’ for word delimiter; or a
space if it is used without DELIM
-p [DELIM], --pos [DELIM]
enable POS tagging; if DELIM is specified, use DELIM
instead of ‘_’ for POS delimiter
-D DICT, --dict DICT use DICT as dictionary
-u USER_DICT, --user-dict USER_DICT
use USER_DICT together with the default dictionary or
DICT (if specified)
-a, --cut-all full pattern cutting (ignored with POS tagging)
-n, --no-hmm don’t use the Hidden Markov Model
-q, --quiet don’t print loading messages to stderr
-V, --version show program’s version number and exit
If no filename specified, use STDIN instead.
延迟加载机制
jieba 采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。如果你想手工初始 jieba,也可以手动初始化。
import jieba
jieba.initialize() # 手动初始化(可选)
在 0.28 之前的版本是不能指定主词典的路径的,有了延迟加载机制后,你可以改变主词典的路径:
jieba.set_dictionary(‘data/dict.txt.big’)
例子: https://github.com/fxsjy/jieba/blob/master/test/test_change_dictpath.py
原理参考:https://blog.csdn.net/u012558945/article/details/79918771
参考文献:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931
#关于结巴安装失败问题
首先尝试pip install jieba 与conda install jieba来解决问题。如果多次尝试仍然失败,那么由于结巴不是python的官方库,https://www.lfd.uci.edu/~gohlke/pythonlibs/目前无whl 文件、需要下载https://pypi.org/project/jieba/#files。jie.zip文件,之后将其解压,
解压后进到解压文件的目录,
点击电脑桌面的左下角的【开始】—》运行 —》输入: cmd —》切换到Jieba所在的目录,比如,D:\Download\Jieba,依次使用如下命令:
C:\Users\Administrator>D:
D:>cd D:\Download\jieba-0.35
观察结巴目录下是否是jieba路径了,如果确认则执行,有的时候还需要在进入一个目录,之后执行
D:\Download\jieba-0.35>python setup.py install
即安装成功。

版权声明
本文为[IT界的小小小学生]所创,转载请带上原文链接,感谢
https://vip01.blog.csdn.net/article/details/76586693
边栏推荐
- 2018个人年度工作总结与2019工作计划(互联网)
- vite + ts 快速搭建 vue3 專案 以及介紹相關特性
- xmppmini 專案詳解:一步一步從原理跟我學實用 xmpp 技術開發 4.字串解碼祕笈與訊息包
- 数字城市响应相关国家政策大力发展数字孪生平台的建设
- nlp模型-bert从入门到精通(一)
- Introduction to Google software testing
- Anomaly detection method based on SVM
- 03_ Detailed explanation and test of installation and configuration of Ubuntu Samba
- iptables基礎原理和使用簡介
- 如何在Windows Server 2012及更高版本中將域控制器降級
猜你喜欢



随机推荐
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
mac 下常用快捷键,mac启动ftp
Introduction to Google software testing
接口压力测试:Siege压测安装、使用和说明
Probabilistic linear regression with uncertain weights
(2)ASP.NET Core3.1 Ocelot路由
3分钟读懂Wi-Fi 6于Wi-Fi 5的优势
TF flags的简介
10 easy to use automated testing tools
基于深度学习的推荐系统
keras model.compile损失函数与优化器
Serilog原始碼解析——使用方法
Analysis of ThreadLocal principle
Every day we say we need to do performance optimization. What are we optimizing?
GBDT与xgb区别,以及梯度下降法和牛顿法的数学推导
Kitty中的动态线程池支持Nacos,Apollo多配置中心了
用Python构建和可视化决策树
容联完成1.25亿美元F轮融资
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
2018个人年度工作总结与2019工作计划(互联网)