当前位置:网站首页>Cvpr2022 | knowledge distillation through target aware transformer
Cvpr2022 | knowledge distillation through target aware transformer
2022-06-29 13:09:00 【CV technical guide (official account)】
Preface This article is from readers , We will post the latest top conference papers published in recent days in the group , You can read these top meetings in time , And write an interpretation for us to contribute , Press conference fee . Please scan the QR code at the end of the text to add a group .
Welcome to the official account CV Technical guide , Focus on computer vision technology summary 、 The latest technology tracking 、 Interpretation of classic papers 、CV Recruitment information .

The paper :Knowledge Distillation via the Target-aware Transformer
Code : Not released yet
background
Distillation learning is the de facto standard for improving the performance of small neural networks , Most of the previous work suggested that teachers' representative characteristics should be returned to students in a one-to-one spatial matching way .
However , People tend to overlook the fact that , Due to differences in structure , The semantic information in the same space is usually variable , This greatly weakens the basic assumption of the one-to-one distillation method . They overestimate the transcendentality of spatial order , The problem of semantic mismatch is ignored , That is, in the same spatial position , The pixels of teacher's feature map often contain richer semantics than those of students .
So , This paper presents a new one-to-one spatial matching knowledge distillation method . To be specific , This paper allows each pixel of teacher features to be extracted into all spatial positions of student features and given by a target perceived transformer Resulting similarity .

chart 1 Semantically mismatched diagrams
From the picture 1 It can be seen that the teacher model has more convolution operations , The generated teacher characteristic map has a larger feeling field , And contain more semantic information , It may not be ideal to directly return the feature matching of students and teachers in one-to-one space , Therefore, this paper proposes one to many target perception transformer Distillation of knowledge , The spatial components of the teacher model can be extracted into the feature map of the whole student model .
A basic assumption is that the spatial information of each pixel is the same . In practice , This assumption is usually invalid , Because the student model usually has fewer convolution layers than the teacher model .
chart 1 (a) Shows an example , Even in the same spatial location , The acceptance domain of students' characteristics is often significantly smaller than that of teachers , Therefore, it contains less semantic information . The method of calculating distillation loss generally needs to select the source characteristic map, teacher and student's target characteristic map , The two characteristic graphs must have the same spatial aspect .
Pictured 1 (b) Shown , Calculate the loss in a one-to-one spatial matching way .
chart 1 (c) in , Our method extracts the teacher's feature at each spatial position, parameterizes all components of the student's feature, and parameterizes all components of the student's feature . This paper uses parameter correlation to measure the semantic distance between the representation components of student characteristics and teacher characteristics , Used to control the intensity of feature aggregation , This solves the problem of one-to-one matching of knowledge distillation .
contribution
1、 This paper proposes the method of target perception transformer Distillation of knowledge , It enables the whole student to imitate each spatial component of the teacher . In this way , This paper can improve the matching ability and the performance of knowledge distillation .
2、 This paper proposes the method of stratified distillation , Transfer local features with global dependencies , Instead of the original feature map . This makes it possible to apply the proposed method to the applications that bear heavy computational burden due to the large size of the feature graph .
3、 By applying the distillation framework of the paper , Compared with the relevant alternatives , This paper has achieved the most advanced performance on several computer vision tasks .
Method
1、 Planning

A pair of spatial matching knowledge distillation approaches are proposed to allow teachers to dynamically teach the characteristics of the whole student at each feature position . In order to make the whole student imitate the teacher's spatial component , This paper puts forward the concept of target perception Transformer(TaT), Reconfigure the semantics of student features at specific locations in pixel mode . Given the component of the teacher's space ( Align target ), Paper utilization TaT Guide the whole student to reconstruct the feature in the corresponding position . This paper uses a linear operator to avoid changing the distribution of students' semantics , Conversion operations can be defined as :

By aggregating these related semantics into all components , The paper got :

In target perception Transformer Under the guidance of , The reconfigured student characteristics can be expressed as :

TaT The goal of knowledge distillation can be given in the following ways :

The total loss of the proposed method is :


chart 2(a) Target aware transformer. Based on the characteristics of teachers and students , Calculate transformation mapping , Then use the corresponding teacher characteristics to minimize L2 Loss .
2、 Stratified distillation
In this paper, a method of stratified distillation is proposed to solve the limitation of large characteristic graph , There are two steps :1)patch-group distillation , The whole feature map is divided into smaller patchs, In order to distill the local information from teachers to students ;2) Further, local patchs Sum it up as a vector and refine it into global information .
2.1 patch-group distillation

Teacher and student features were sliced and reorganized into distillation groups . By connecting... In a group patches, The paper clearly introduces patches Spatial correlation between ,patches The spatial correlation between them goes beyond themselves . In distillation , Students can not only learn about a single pixel , And we can learn the correlation between them . In the experiment, the paper studied the effect of different size groups .
2.2 Anchor-point Distillation

A color represents an area . In this paper, average pooling is used to extract local anchors in a given feature map , Form a new feature map with smaller size . The resulting anchor characteristics will participate in the distillation process . Because the new feature graph is composed of the sum of the original features , It can approximately replace the original features to obtain global dependencies .
The goal of semantic segmentation design in this paper can be expressed as :

experiment
Picture classification experiment , This paper uses data sets widely used in the field of knowledge distillation, such as Cifar-100 and ImageNet, And it shows that the model of this paper is compared with many of the most advanced benchmarks , It can significantly improve students' performance . Besides , The paper also does the experiment of semantic segmentation to further verify the generalization of the method .
1、 Experimental data sets :
Cifar-100、ImageNet、Pascal VOC、COCOStuff10k
2、 Image classification :
stay Cifar-100 The result on

stay Cifar-100 On dataset Top-1 Accuracy rate
The method of the thesis is in seven teachers - Six of the student settings exceeded all baselines , And it usually has a significant advantage . This proves the effectiveness and generalization ability of the method .
stay ImageNet The result on

stay ImageNet On dataset Top-1 Accuracy rate
The method of this paper also surpasses the most advanced method with significant advantages .
3、 Semantic segmentation

stay Pascal VOC Semantic segmentation results compared with different methods

stay COCOStuff10k Semantic segmentation results compared with different methods
The method of the paper is obviously more than all baseline.
Conclusion
This work is done through goal perception transformer Developed a framework for knowledge distillation , Enable students to gather useful semantics on themselves to improve the expressiveness of each pixel . This enables students to imitate teachers as a whole , Instead of minimizing the divergence of each part in parallel .
The method of the thesis is adopted by patch-group Distillation and anchor-point A stratified distillation consisting of distillation , It has been successfully extended to semantic segmentation , It aims to focus on local characteristics and long-term dependence . A comprehensive experiment is carried out in this paper , To verify the effectiveness of this method , And improved the most advanced level .
We built a Knowledge of the planet , Some homework is assigned every day on the planet , These assignments will lead you to learn something . If someone feels that they have no motivation to study , Or want to develop a good study habit , It is a good practice to finish the homework in the knowledge planet every day .
in addition , We built a Communication group , The group will often publish the latest top conference papers published in recent days , You can download these papers to read , If you write an interpretation after reading , You can contribute to us , We will pay for the contribution . It can keep reading the latest top meeting 、 The habit of continuous output , It can also improve the writing ability , In the future, you can also write it on your resume in your official account CV Dozens of contributions have been made to the technical guide 、 More than 100 articles , For improving ability 、 Keep learning attitude 、 Personal history and other aspects will play a big role .
Add groups and planets : Official account CV Technical guide , Get and edit wechat , Invite to join .
Welcome to the official account CV Technical guide , Focus on computer vision technology summary 、 The latest technology tracking 、 Interpretation of classic papers 、CV Recruitment information .

Other articles
Introduction to computer vision
YOLO Series carding ( One )YOLOv1-YOLOv3
YOLO Series carding ( Two )YOLOv4
YOLO Series carding ( 3、 ... and )YOLOv5
Attention Mechanism in Computer Vision
Build from scratch Pytorch Model tutorial ( Four ) Write the training process -- Argument parsing
Build from scratch Pytorch Model tutorial ( 3、 ... and ) build Transformer The Internet
Build from scratch Pytorch Model tutorial ( Two ) Build network
Build from scratch Pytorch Model tutorial ( One ) data fetch
StyleGAN Grand summary | Comprehensive understanding SOTA Method 、 New progress in architecture
A thermal map visualization code tutorial
Summary of industrial image anomaly detection research (2019-2020)
Some personal thinking habits and thought summary about learning a new technology or field quickly
边栏推荐
- Don't build the wheel again. It is recommended to use Google guava open source tool class library. It is really powerful!
- AcWing 234 放弃测试
- Qt的信号与槽
- Proteus软件初学笔记
- Adjacency matrix and adjacency table structure of C # realization graph
- 中职网络安全技能竞赛之应用服务漏洞扫描与利用(SSH私钥泄露)
- Cocos star meetings at Hangzhou station in 2022
- ZALSM_ EXCEL_ TO_ INTERNAL_ Solving the big problem of importing data from table
- 如何計算win/tai/loss in paired t-test
- YOLO系列梳理(九)初尝新鲜出炉的YOLOv6
猜你喜欢

QT signal and slot

Matlab简单入门

1. opencv realizes simple color recognition
Comment calculer Win / Tai / Loss in paired t - test
Simple introduction to matlab

CVPR2022 | 通过目标感知Transformer进行知识蒸馏
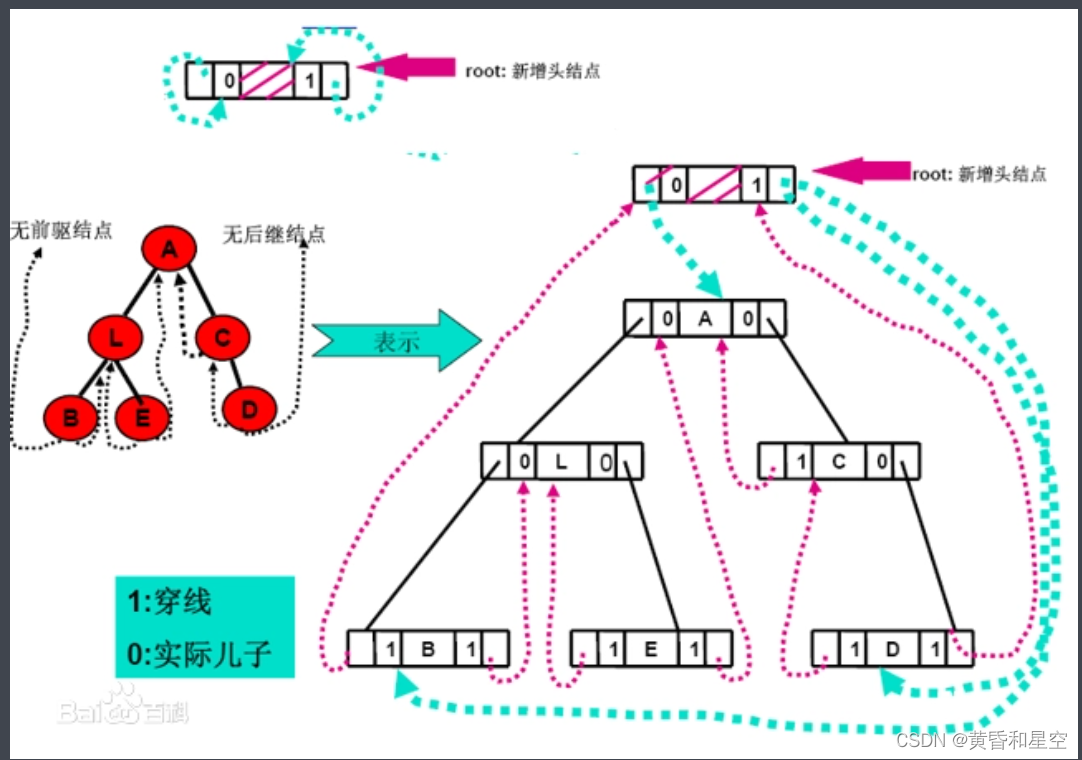
C#通過中序遍曆對二叉樹進行線索化
【云原生】2.4 Kubernetes 核心实战(中)

Recurrence of recommended models (III): recall models youtubednn and DSSM

墨菲安全入选中关村科学城24个重点项目签约
随机推荐
Testing -- automated testing: about the unittest framework
huffman编码
Matlab简单入门
AES-128-CBC-Pkcs7Padding加密PHP实例
1. opencv realizes simple color recognition
STK_GLTF模型
安装typescript环境并开启VSCode自动监视编译ts文件为js文件
C#通过中序遍历对二叉树进行线索化
Async principle implementation
Problem solving: modulenotfounderror: no module named 'pip‘
LR、CR纽扣电池对照表
STK_ Gltf model
360数科新能源专项产品规模突破60亿
从Mpx资源构建优化看splitChunks代码分割
C # implementation of binary tree non recursive middle order traversal program
If I am in Shenzhen, where can I open an account? In addition, is it safe to open an account online now?
Unexpected ‘debugger‘ statement no-debugger
在印度与软件相关的发明可不可以申请专利?
Recommended model reproduction (II): fine arrangement model deepfm, DIN
QT signal and slot